Кампания по выпуску патчей для CVE-2026-53359 (Januscape): Уроки, извлеченные из устранения уязвимости KVM на десятках тысяч машин

 Уязвимость в подсистеме виртуализации.
Уязвимость в подсистеме виртуализации.
Во вторник, 7 июля, в начале дня было выпущено предупреждение о безопасности, касающееся уязвимости CVE-2026-53359, связанной с использованием памяти после освобождения (use-after-free), затрагивающей подсистему теневой подкачки KVM x86 в ядре Linux. Уязвимость, обнаруженная несколько лет назад, была обнародована 6 июля; сообщения в блогах других облачных провайдеров появились еще 7 июля.
KVM — это механизм виртуализации, используемый в подавляющем большинстве экземпляров, размещенных в OVHcloud. Механизм работает следующим образом: при внешнем изменении записи каталога страниц (PDE) запись RMAP может сохранить ссылку на уже освобожденную страницу памяти. Затем ядро разыменовывает эту устаревшую страницу, что может привести к сбою гипервизора или, в худшем случае, к повышению привилегий на стороне хоста. Эксплойт воспроизводим: внутренний тест на незащищенном хосте вызывает сбой примерно через две минуты.
Все ядра x86 Linux, выпущенные до внесения изменений в патч, затронуты независимо от дистрибутива. Официальный патч был перенесен в наши производственные ядра Debian.
Необходимо учитывать три основных риска:
- Клиент VPS использует эту уязвимость для того, чтобы вызвать сбой на хосте, где работает его виртуальная машина: происходит сбой и неконтролируемая перезагрузка нескольких сотен виртуальных машин клиента.
- Аналогичная ситуация наблюдается и на экземплярах публичного облака; влияние схожее, но количество виртуальных машин на хост более ограничено, а сами виртуальные машины более мощные и используются для более важных систем (базы данных, менеджеры очередей, балансировщики нагрузки и т. д.). Эти системы часто используются в сложных архитектурах приложений со сложными зависимостями.
- Вероятность скорой публикации эксплойта для захвата хоста, что немедленно повысит уровень риска до неприемлемого уровня из-за воздействия на конфиденциальность данных клиентов и целостность инфраструктуры.
Для OVHcloud масштаб проблемы охватывает
десятки тысяч серверов гипервизоров, на которых размещено около миллиона виртуальных машин. Поэтому вопрос не в том, нужно ли устанавливать патчи, а в том, как выполнить эту операцию в таком масштабе, понимая, что полное отсутствие негативного воздействия на клиентов невозможно.
Предлагаемые варианты снижения риска
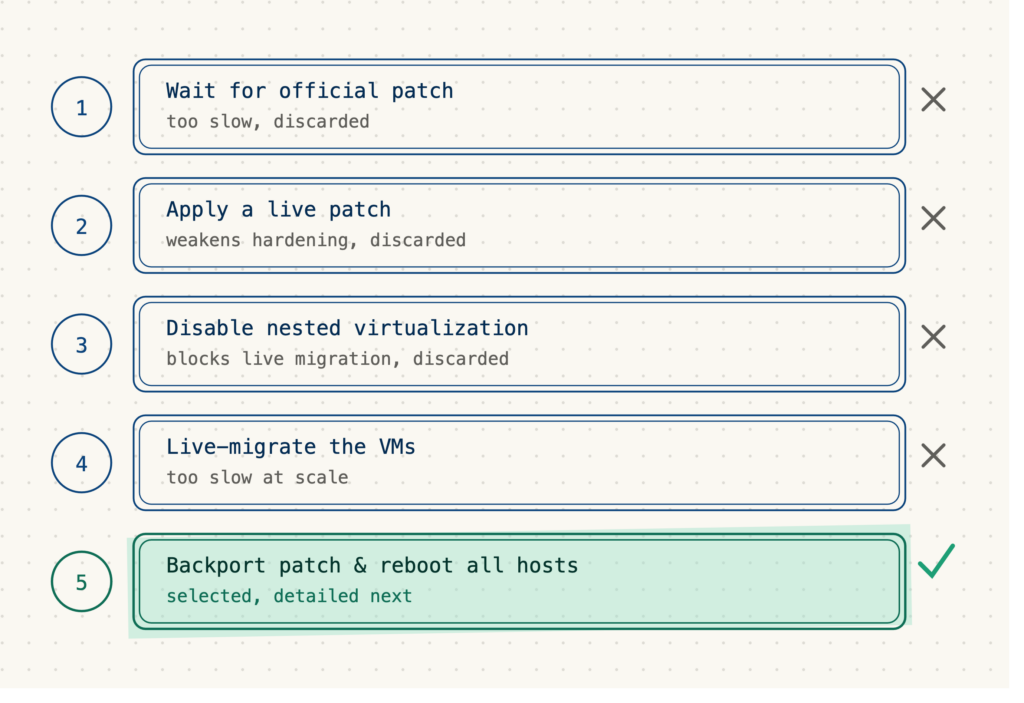
1: Дождитесь выхода официальных исправленных ядер.
Этот вариант делал нас зависимыми от графика работы сторонней компании, что создавало риск неконтролируемого развития событий. Мы быстро отказались от него из-за связанных с ним рисков.
2: Обновление для текущей версии игры
Для применения «живого» патча необходимо включить соответствующую опцию в конфигурации ядра. По своей сути, это позволяет изменять его поведение «на лету», тем самым снижая уровень защиты и ограничивая возможности обнаружения в случае компрометации. Кроме того, применение «живого» патча — это по своей сути деликатная процедура, которая может привести к нестабильности всей системы. Это вариант, позволяющий выиграть время в ожидании окончательного решения. Мы отказались от этого компромисса, который значительно увеличил бы риск захвата хоста в случае публикации эксплойта.
3: Снижение рисков путем отключения вложенной виртуализации.
Отключение вложенной виртуализации на хостах делает эксплойт неработоспособным. У нас нет информации об использовании этой функции нашими клиентами, поэтому невозможно определить влияние на работу служб поддержки клиентов, а эта функция необходима для сохранения возможности миграции экземпляра в рабочем режиме с одного физического хоста на другой. Мы быстро исключаем эту возможность.
4: Миграция в реальном времени
Организация миграции виртуальных машин в режиме реального времени с уязвимых хостов на пустые хосты, которые были обновлены за это время, является очень удовлетворительным вариантом с точки зрения непрерывности обслуживания, поскольку миграция происходит без влияния на виртуальные машины, за исключением снижения производительности во время миграции. Однако этот вариант очень трудоемкий из-за копирования виртуальных машин с хоста на хост; он нереалистично применим ко всей инфраструктуре, а мы хотим защитить наших клиентов за считанные дни, а не месяцы. Мы решили зарезервировать этот вариант только для некоторых критически важных виртуальных машин, поскольку каждая миграция в режиме реального времени вызывает значительную задержку в пакетной обработке.
5: Перенести патч в наши ядра и перезагрузить все хосты.
В конечном итоге будет выбран именно этот вариант, и он будет подробно описан далее в статье.
Вторник после обеда: активация и организация работы кризисного штаба.
Как только уязвимость подтверждается, приоритетной задачей становится разработка структурированного и скоординированного ответа; аналитики, ответственные за этот первоначальный анализ, быстро понимают последствия на ближайшие дни. Информация распространяется внутри компании в начале дня. Создается несколько каналов координации: один для технической координации, один для координации в кризисных ситуациях, один для операций в США и один для связи с клиентами и поддержки. Одновременно команды разработчиков ядра готовят и переносят патч; первый исправленный патч ядра выпускается вечером.
Вечером того же дня в тестовой среде были проведены проверочные тесты. Эффективность патча была подтверждена, эксплойт больше не вызывал сбоев в работе пропатченных гипервизоров, а тесты контроля качества прошли успешно с пропатченным ядром.
Группа по управлению кризисными ситуациями переключается на мониторинг развертывания, после чего ее возглавляет Центр сетевых операций (NOC), который берет на себя роль оперативного координатора: отслеживает общий прогресс, расставляет приоритеты задач между регионами и сервисами и поддерживает всесторонний обзор. Выполнением занимаются эксперты по публичным облакам и VPS, которые управляют перезагрузками, миграцией в режиме реального времени и ограничениями антиаффинности. Разделение между координацией и выполнением является преднамеренным: NOC координирует, а оперативные группы действуют и сообщают метрики и технические события, необходимые для координации.
Обеспечивается непрерывная синхронизация со службой поддержки клиентов (обновления о ходе работ в режиме реального времени для реагирования на запросы затронутых клиентов) и группами безопасности (мониторинг уязвимостей, проверка масштаба и критериев завершения операций).
Работа осуществляется по принципу «следуй за солнцем», при этом ячейка работает круглосуточно и без выходных, поочередно меняя географические зоны. Ежедневно проводятся три точки синхронизации, охватывающие переходы между зонами. В этих точках собираются представители центра управления сетью (NOC), оперативные эксперты, служба поддержки и служба безопасности для: обмена информацией о ходе работ по регионам, передачи информации между зонами (что сработало, корректировки процедур на основе отзывов с мест) и определения приоритетов следующего этапа.
В состав этого комплексного подразделения круглосуточно и без выходных входят: команды по разработке ядра и виртуализации (анализ патчей, обратная совместимость, проверка), VPS и публичное облако (развертывание), NOC (управление), Run & SRE (оркестрация, антиаффинность, миграция в реальном времени), операционная деятельность центров обработки данных (ремонт оборудования), служба поддержки клиентов (запросы клиентов), служба безопасности (мониторинг, периметр, завершение работы) и коммуникационная служба (прозрачность, целевые уведомления).
Поставленная задача ясна: как можно быстрее установить исправления и перезагрузить затронутые хосты, чтобы сократить период уязвимости и минимизировать влияние на работу сервисов. Главное ограничение заключается в масштабе: необходимо обработать десятки тысяч машин на всех континентах, при этом физически невозможно обрабатывать каждый случай по отдельности в таком объеме.
Основной риск на данном этапе — это использование уязвимости, что может привести к сбою незащищенного хоста. Кризисная группа решила применить патч глобально перед этапом перезапуска. В случае использования уязвимости сбой хоста вызовет перезапуск и автоматическое применение патча. Кроме того, существует риск того, что CVE может быть использован для получения несанкционированного контроля над хостом. Код эксплойта не находится в открытом доступе, но мы знаем, что это лишь вопрос времени, когда исследователь сможет использовать уязвимость для получения контроля над хостом. Учитывая катастрофический характер этого сценария, мы понимаем, что каждая минута на счету.
Обдуманное решение: одностороннее вмешательство с контролируемым воздействием.
Вечером Исполнительный комитет утверждает решение о продолжении/отмене проекта: первый регион будет рассмотрен на следующее утро. Для такого количества машин не существует сценария, исключающего негативные последствия. Согласование временных рамок технического обслуживания с каждым клиентом, проверка каждой зависимости, организация каждой индивидуальной перезагрузки — все эти шаги существенно несовместимы с приемлемыми сроками, учитывая риски безопасности.
Поэтому кризисная команда приняла обдуманное решение: одностороннее внедрение временных решений с контролируемым воздействием, проведенное без ожидания согласия отдельных клиентов, зная, что некоторые услуги будут прерваны. Обоснование основывалось на трех моментах:
- Неустранение неисправности подвергает весь парк серьезному риску;
- Индивидуальный подход к каждому случаю приведет к задержкам и оставит большинство носителей вируса уязвимыми на несколько недель;
- Быстрые и всеобъемлющие действия защищают наибольшее число людей, даже если это временно затрагивает меньшинство.
Приоритетом теперь является не предотвращение последствий, а их минимизация, смягчение и обеспечение предсказуемости. Этот принцип лежит в основе всей операции: следовать за солнцем, расстановка приоритетов в регионах и планирование, направленное на предотвращение предвзятости.
Среда, 8 июля: вылет из Сиднея.
Выбор Сиднея для тестирования развертывания не представляет сложности: количество хостов ограничено, а локальное окно развертывания HNO (ночная смена) совпадает с рабочим временем команд в Европе. Начало работы с самого восточного региона позволяет:
- работать в наименее загруженном районе;
- проверить процедуру в реальных условиях, в уменьшенном масштабе, перед внедрением в промышленность;
- для сбора первоначальных отзывов перед запуском в Европе и Северной Америке.
Первые волны обновлений и перезагрузок были применены к VPS- хостингам в Австралии. В регионе SYD2 установка прошла без происшествий в начале дня (по парижскому времени). Процедуры корректируются на основе отзывов с мест.
Как только ситуация стабилизируется, применяется подход « следуй за солнцем»: каждый регион по очереди принимает управление, сообщая о местной ситуации следующему региону утром. Первая европейская волна (RBX, GRA6, WAW, DE, SBG, MIL, UK) запускается в тот же вечер, в 18:30 по парижскому времени.
Две среды, два варианта использования: сначала VPS, затем публичное облако.
Развертывание не является единообразным. VPS и публичное облако различаются как по своей архитектуре, так и по возможностям взаимодействия с клиентами. Количество виртуальных машин на VPS-хостингах больше, и многие предприятия и частные лица используют VPS для создания тестовой инфраструктуры; вероятность того, что клиент будет тестировать код операционной системы на своей виртуальной машине, очень высока, и влияние также значительно из-за количества виртуальных машин на каждом хосте.
На VPS область действия для каждого хоста ограничена, а влияние перезагрузки на клиентов остается контролируемым. Пакеты можно быстро объединять в цепочки, что позволяет обеспечить безопасность значительной части инфраструктуры в течение первых 24 часов.
Публичное облако представляет собой иной тип уязвимости. В регионе сосредоточены тысячи клиентов, и на одном хосте могут размещаться критически важные экземпляры. В крупнейших регионах находятся сотни или даже тысячи хостов со сложной виртуальной инфраструктурой клиентов. Мы решили расставить приоритеты:
- По размеру региона: сначала обрабатываются регионы с меньшей плотностью, чтобы проверить надежность процедуры в больших масштабах;
- по количеству подверженных риску клиентов: регионы с большим объемом операций координируются с более высокой степенью детализации, партия за партией, чтобы снизить риск.
Пороги остановки и управление темпом
Каждая волна перезагрузки подчиняется пороговому значению для завершения процесса: если количество одновременно вышедших из строя хостов превышает заданный порог, волна приостанавливается. Этот порог установлен на уровне 15 хостов для регионов с высокой плотностью (GRA, RBX, BHS) и на уровне 5 хостов для остальных. Завершение процесса также запускается в 6:00 утра или по запросу из местного центра обработки данных.
Этот механизм предотвращает усугубление аппаратных сбоев, избегая необходимости перезагрузки хостов, с которыми специалисты центров обработки данных еще не справлялись. Он создает точку равновесия между программной автоматизацией и физической реальностью на местах.
Не перезапускайте одновременно два экземпляра одного и того же проекта: антиаффинность как мера предосторожности.
Основной риск для наших клиентов во время такой операции заключается не в самой перезагрузке, а в одновременном прерывании работы нескольких экземпляров одного и того же проекта, что обеспечивает отказоустойчивость приложения, способного справиться со сбоем поставщика услуг. Клиент, распределивший свои рабочие нагрузки по нескольким хостам для обеспечения высокой доступности, не должен столкнуться с одновременным переключением всех своих экземпляров. Было принято решение выйти за рамки простого соблюдения правил антиаффинности, которые могли быть определены в развертываниях клиентов.
Таким образом, для каждого клиентского проекта с экземплярами, распределенными по нескольким хостам, наши оркестраторы вычисляют граф совместного размещения. Ни в коем случае два хоста, на которых запущены экземпляры одного и того же проекта, не перезагружаются в одно и то же окно: определены взаимоисключающие циклы, и хост должен быть снова в сети до того, как будет запущен следующий хост в том же классе антиаффинности.
Этот подход, исключающий привязку к конкретному серверу, применяется по мере возможности: он соблюдается в большинстве случаев, но не может быть гарантирован на 100% по всей сети. Цель остается неизменной — распределить воздействие таким образом, чтобы оно было управляемым на стороне приложения. Клиенты, чьи экземпляры зависят от одного хоста, испытывают временный сбой, время которого объявляется заранее.
Приоритетная миграция конфиденциальных сервисов и рабочих нагрузок в режиме реального времени.
За каждым экземпляром клиента находятся контроллеры, API, плоскости данных и внутренние базы данных. Неконтролируемая перезагрузка хостов, на которых работают эти сервисы, приведет к взаимоблокировкам: недоступность внутреннего сервиса блокирует последующие перезагрузки, что, в свою очередь, препятствует установке обновлений. Кроме того, некоторые сервисы OVHcloud используют виртуальные машины, размещенные на экземплярах публичного облака. Учет этих сценариев крайне важен для минимизации воздействия на клиентов.
Чтобы избежать подобной каскадной ошибки, приоритеты меняются местами: перед каждой перезагрузкой региона выполняется тщательный анализ внутренних зависимостей сервисов. Некоторые внутренние сервисы переносятся в режиме реального времени. Их виртуальные машины перемещаются на лету на предварительно обновленные хосты, цепочка зависимостей остается доступной, после чего хост освобождается для перезагрузки.
Эта процедура длительная и требует значительных материальных и человеческих ресурсов. Для достижения цели миграции в установленные сроки её необходимо ограничить небольшим количеством виртуальных машин.
Некоторые рабочие нагрузки требуют особого внимания: в частности, сервисы облачных баз данных (DBaaS), внутреннее хранилище данных и функции мониторинга переносятся по одной виртуальной машине за раз, без одновременного выключения более чем одной машины и с отсрочкой обновлений на хостах на максимально возможный срок. Такая плавная миграция помогает предотвратить каскадные сбои в работе сервисов и гарантирует доступность инструментов, поддерживающих операции.
Технические неполадки и корректировки во время эксплуатации
Операция такого масштаба не обходится без происшествий. В ходе кампании было выявлено и решено несколько технических проблем.
Виртуальные машины не перезапускаются после перезагрузки хоста.
Первый крупный инцидент произошёл во время начальной европейской волны: виртуальные машины не перезапускались после перезагрузки гипервизора. Nova Compute сообщала о «самостоятельном завершении работы экземпляра» без синхронизации. Первопричина была выявлена на второй день: служба libvirt-guests конфликтовала с Nova Compute и останавливала экземпляры при перезагрузке без синхронизации API. Решение заключалось в отключении и скрытии службы libvirt-guests.service на хостах перед перезагрузкой. После этого исправления автоматический перезапуск виртуальных машин заработал.
Повреждение данных в синхронных сервисах
Вечером второго дня внутренняя система мониторинга сообщила о поврежденных данных на нескольких виртуальных машинах, распределенных по трем кластерам. Вероятная причина: принудительная перезагрузка произошла в середине операции записи на диск. Затем время корректного завершения работы было увеличено до 60 секунд перед принудительным завершением процесса, чтобы дать время завершить запись. Был реализован скрипт для автоматического перезапуска виртуальных машин, которые оставались выключенными.
API в случае взаимоблокировки в Париже
В ночь со второго на третий день API Nova и Neutron в Париже оказались в тупиковой ситуации: API Neutron (с ограничением в 10 процессов) был перегружен резким увеличением запросов Nova, в результате чего в течение примерно двух часов возвращались ошибки HTTP 503. Решение заключалось в увеличении количества рабочих процессов Neutron с 10 до 30 и количества процессов Apache с 10 до 32. Работа зоны B в Париже и Милане была отложена до стабилизации ситуации.
Поддержка насыщения в BHS
На площадке BHS (Канада)
трафик API превысил обычный пик в 10 раз, что перегрузило менеджера и службы поддержки. Некоторые клиенты обнаружили последствия еще до получения официального уведомления. Этот случай наглядно иллюстрирует цепную реакцию внутри инфраструктуры.
Все выявленные ошибки и проблемы были устранены в ходе оперативной деятельности, но будут учтены при внедрении соответствующих улучшений на устойчивой основе.
Восстановление после перезагрузки и аппаратные вмешательства
Перезагрузка десятков тысяч машин также включает в себя аппаратный аспект. Любая перезагрузка сервера сопряжена с определенным уровнем отказов.
В первую ночь примерно 20-30 хостов из 6000 не восстановились самостоятельно: неисправные модули памяти, проблемы с конфигурацией BIOS, неактивные сетевые интерфейсы. В Соединенных Штатах для восстановления работы нескольких хостов потребовалось извлечение батареи CMOS и разрядка батареи — это повторяющаяся аппаратная проблема.
На каждом объекте в качестве подкрепления на время кампании задействованы технические специалисты центров обработки данных. Их роль:
- срочно вмешаться в работу хостов, которые, по сообщениям оркестраторов, не перезагрузились;
- заменить неисправные детали (диски, флеш-накопители, блоки питания);
- Выполнять действия, требующие высокой точности и автоматизации с помощью любого инструмента: физическую перезагрузку, проверку освещения, вмешательство в бокс.
Технические специалисты центров обработки данных работают в режиме приоритетного реагирования на сбои на хостах, координируя свои действия с группами эксплуатации и SRE, которые определяют приоритеты в зависимости от нагрузки на хост со стороны клиентов. Хост, на котором размещены критически важные экземпляры и который не может восстановиться, имеет приоритет над свободным хостом. Такая перекрестная приоритизация — как программная, так и физическая — поддерживает темп работы.
Коммуникация и поддержка: информирование пострадавших клиентов.
Одностороннее вмешательство с контролируемым воздействием невозможно без соразмерных усилий по информированию.
Целенаправленная и прогрессивная коммуникация
В условиях динамики «следуй за солнцем» глобальная и недифференцированная коммуникационная стратегия была бы бессмысленной. Выбранная стратегия заключалась в целенаправленной и поэтапной коммуникации: она адресована только клиентам, чьи экземпляры размещены на хостах, запланированных к перезагрузке, и запускается по мере выполнения операции, регион за регионом, волна за волной.
Изначально было принято решение
не создавать публичную страницу состояния, чтобы избежать раскрытия последовательности развертывания. Коммуникация осуществляется через целевые каналы на нашем портале поддержки, электронные письма отправляются клиентам с уровнями поддержки Business и Enterprise.
Наблюдение: некоторые сообщения не доставляются.
Инструменты коммуникации имеют технические ограничения. Для регионов с большим объемом обращений, таких как GRA6 (почти 90 000 клиентов, с которыми не удалось связаться), массовая рассылка электронных писем исключена во избежание увеличения количества обращений в службу поддержки.
В связи с этой ситуацией на второй день было принято решение изменить подход: внедрить в Менеджере условный баннер с помощью переключения функций — если авторизованный пользователь находится в списке затронутых учетных записей клиентов (NIC), отображается информационное сообщение. Разработка была завершена в тот же день, а баннер был развернут на третий день. В это же время была создана страница состояния публичного облака.
Несмотря на принятые меры, некоторые сообщения не дошли до получателей: устаревшие контактные адреса, отфильтрованные уведомления и несоответствия между запланированным временем перезагрузки и временем отправки. Некоторые клиенты обнаружили последствия без предварительного уведомления. Эти сбои были определены как приоритетные области для улучшения после разработки первоначального плана по устранению проблем.
Поддержка как крайняя мера
Для клиентов, не обладающих необходимой информацией или нуждающихся в разъяснениях, усилена и подготовлена служба поддержки: предварительный инструктаж по контексту операции, доступ в режиме реального времени к информации о ходе выполнения по регионам и организаторам, ускоренная обработка заявок, связанных с кампанией, через специальный канал.
Поддержка компенсирует то, чего не смогли обеспечить автоматические уведомления. Она не заменяет общение, но восполняет некоторые его недостатки.

 Перспективы
Перспективы
Уязвимость CVE-2026-53359 поставила под угрозу наших клиентов и инфраструктуру. План по смягчению последствий привел к негативному влиянию на клиентов — локальному, последовательному и объявленному, но реальному. Более подробное информирование в ходе выполнения плана по смягчению последствий, пока инфраструктура оставалась без обновлений, значительно увеличило бы риск для наших клиентов, потенциально побудив некоторых из них «протестировать» общедоступную уязвимость.
Восстановление парка мирового класса без какого-либо воздействия на окружающую среду было недостижимой целью. Поэтому задачей было минимизировать воздействие, совместимое с безопасностью всего парка.
Ранее обновление и перезапуск всех хостов публичного облака и VPS никогда не проводились в условиях столь ограниченного времени. Эта экстренная процедура была внедрена из-за риска, связанного с уязвимостью. В предыдущих случаях всегда применялась поэтапная перезагрузка с использованием естественной скорости обновления виртуальных машин в инфраструктуре в сочетании с плановыми миграциями в режиме реального времени, запланированными на более длительный период.
Команды, участвовавшие в этой операции, добились выдающихся результатов, справившись с весьма умеренным количеством сбоев и негативным воздействием на клиентов относительно масштаба проекта. Однако, учитывая возможность новых раскрытий уязвимостей ядра в ближайшие месяцы, очевидно, что эту процедуру реагирования на чрезвычайные ситуации необходимо повторить. В следующий раз нам нужно будет лучше справиться как с управлением последствиями перезапусков, так и с предоставлением клиентам предварительного уведомления и поддержки во время операций. Поэтому в ближайшие дни и недели мы определим основные последствия для наших клиентов, столкнувшихся со сложными сбоями, и проведем внутренний анализ после завершения работ, чтобы улучшить наши процедуры в будущем.