ABCD.HOST: бесплатная установка выделенных серверов SYS и RISE на время акции

Всем привет, дата центр OVH запустили краткосрочную акцию на установку выделенных серверов из линеек SYS, SYS-GAME, RISE, Rise-Game и RISE-STOR.
На время акции установка этих конфигураций — бесплатно.
Обычная стоимость установки — от €30 до €230 в зависимости от сервера.
Акция действует ориентировочно до 2 недель.
Конфигурации, участвующие в акции
SYS- Intel Xeon-E 2136 [6c-12t] (4.5GHz) / 32GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe / 500Mbps — €48/месяц
- Intel Xeon-E 2136 [6c-12t] (4.5GHz) / 64GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe / 500Mbps — €64/месяц
- Intel Xeon-E 2136 [6c-12t] (4.5GHz) / 128GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe / 500Mbps — €96/месяц
- Intel Xeon-E 2136 [6c-12t] (4.5GHz) / 64GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe Enterprise + 2x4TB HDD SATA Enterprise / 500Mbps — €103/месяц
- Intel Xeon-E 2136 [6c-12t] (4.5GHz) / 32GB DDR4 ECC 2666MHz / 2x1.92TB SSD NVMe Datacenter / 500Mbps — €105/месяц
- Intel Xeon-E 2288G [8c-16t] (5.0GHz) / 32GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 500Mbps — €68/месяц
- Intel Xeon-E 2288G [8c-16t] (5.0GHz) / 64GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 500Mbps — €84/месяц
- Intel Xeon-E 2288G [8c-16t] (5.0GHz) / 128GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 500Mbps — €116/месяц
- AMD Ryzen 5 3600X [6c-12t] (4.4GHz) / 32GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe / 500Mbps — €80/месяц
- AMD Ryzen 5 3600X [6c-12t] (4.4GHz) / 64GB DDR4 ECC 2666MHz / 2x512GB SSD NVMe / 500Mbps — €96/месяц
- AMD Ryzen 7 3800X [8c-16t] (4.5GHz) / 64GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 500Mbps — €104/месяц
- AMD Ryzen 7 3800X [8c-16t] (4.5GHz) / 128GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 500Mbps — €136/месяц
- AMD EPYC 7371 [16c-32t] (3.8GHz) / 128GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €144/месяц
- AMD EPYC 7371 [16c-32t] (3.8GHz) / 256GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €208/месяц
- AMD EPYC 7371 [16c-32t] (3.8GHz) / 512GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €336/месяц
- Dual Intel Xeon Silver 4214R [24c-48t] (3.5GHz) / 96GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €160/месяц
- Dual Intel Xeon Silver 4214R [24c-48t] (3.5GHz) / 192GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €208/месяц
- Dual Intel Xeon Silver 4214R [24c-48t] (3.5GHz) / 384GB DDR4 ECC 2400MHz / 2x960GB SSD NVMe / 1Gbps — €304/месяц
RISE / Game / Storage
- Intel Xeon-E 2386G [6c-12t] (4.7GHz) / 32GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €92/месяц
- Intel Xeon-E 2386G [6c-12t] (4.7GHz) / 64GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €104/месяц
- Intel Xeon-E 2388G [8c-16t] (5.1GHz) / 32GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €104/месяц
- Intel Xeon-E 2388G [8c-16t] (5.1GHz) / 64GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €117/месяц
- AMD Ryzen 5 5600X [6c-12t] (4.6GHz) / 32GB DDR4 ECC 2666MHz / 2x500GB SSD NVMe / 1Gbps — €104/месяц
- AMD Ryzen 5 5600X [6c-12t] (4.6GHz) / 64GB DDR4 ECC 2666MHz / 2x500GB SSD NVMe / 1Gbps — €130/месяц
- AMD Ryzen 7 5800X [8c-16t] (4.7GHz) / 64GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 1Gbps — €144/месяц
- AMD Ryzen 7 5800X [8c-16t] (4.7GHz) / 128GB DDR4 ECC 2666MHz / 2x960GB SSD NVMe / 1Gbps — €196/месяц
- AMD Ryzen 9 5900X [12c-24t] (4.8GHz) / 64GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €160/месяц
- AMD Ryzen 9 5900X [12c-24t] (4.8GHz) / 64GB DDR4 ECC 3200MHz / 3x1.92TB SSD NVMe / 1Gbps — €208/месяц
- AMD Ryzen 9 5900X [12c-24t] (4.8GHz) / 128GB DDR4 ECC 3200MHz / 2x512GB SSD NVMe / 1Gbps — €199/месяц
- AMD EPYC 7313 [16c-32t] (3.7GHz) / 64GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €256/месяц
- AMD EPYC 7313 [16c-32t] (3.7GHz) / 128GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €308/месяц
- AMD EPYC 7313 [16c-32t] (3.7GHz) / 256GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €410/месяц
- AMD EPYC 7313 [16c-32t] (3.7GHz) / 512GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €615/месяц
- AMD Ryzen 7 Pro 3700 [8c-16t] (4.4GHz) / 32GB DDR4 ECC 2933MHz / 2x480GB SSD + 4x14TB HDD SAS / 1Gbps — €264/месяц
- AMD Ryzen 7 Pro 3700 [8c-16t] (4.4GHz) / 32GB DDR4 ECC 2933MHz / 2x480GB SSD + 6x14TB HDD SAS / 1Gbps — €344/месяц
- AMD Ryzen 7 Pro 3700 [8c-16t] (4.4GHz) / 32GB DDR4 ECC 2933MHz / 2x480GB SSD + 8x14TB HDD SAS / 1Gbps — €384/месяц
- AMD EPYC 7413 [24c-48t] (3.6GHz) / 128GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €288/месяц
- AMD EPYC 7413 [24c-48t] (3.6GHz) / 256GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €391/месяц
- AMD EPYC 7413 [24c-48t] (3.6GHz) / 512GB DDR4 ECC 3200MHz / 2x3.84TB SSD NVMe / 1Gbps — €724/месяц
- Intel Xeon Gold 6312U [24c-48t] (3.6GHz) / 128GB DDR4 ECC 3200MHz / 2x960GB SSD NVMe / 1Gbps — €336/месяц
- Intel Xeon Gold 6312U [24c-48t] (3.6GHz) / 256GB DDR4 ECC 3200MHz / 3x1.92TB SSD NVMe / 1Gbps — €487/месяц
- AMD EPYC 7402 [24c-48t] (3.3GHz) / 256GB DDR4 ECC 2933MHz / 2x480GB SSD + 2x1.92TB SSD NVMe / 1Gbps — €439/месяц
- AMD EPYC 7532 [32c-64t] (3.3GHz) / 256GB DDR4 ECC 2933MHz / 2x480GB SSD + 2x1.92TB SSD NVMe / 1Gbps — €368/месяц
- AMD EPYC 7642 [48c-96t] (3.3GHz) / 256GB DDR4 ECC 2933MHz / 2x480GB SSD + 2x1.92TB SSD NVMe / 1Gbps — €405/месяц
- AMD EPYC 7642 [48c-96t] (3.3GHz) / 256GB DDR4 ECC 2933MHz / 2x480GB SSD + 2x3.84TB SSD NVMe / 1Gbps — €465/месяц
- AMD EPYC 7642 [48c-96t] (3.3GHz) / 512GB DDR4 ECC 2933MHz / 2x480GB SSD + 2x1.92TB SSD NVMe / 1Gbps — €637/месяц
Условия
- Установка на время акции: €0
- Обычная стоимость установки: от €30 до €230
- Срок акции: до 2 недель
- Локации: Франция, Великобритания, Польша, Германия, Канада
- Наличие конкретных конфигураций и локаций может меняться
- Устанавливаем OS Linux,Windows Server 2019/2022/2025
- Безлимитный трафик
- Надежная защита OVHcloud Anti-DDoS
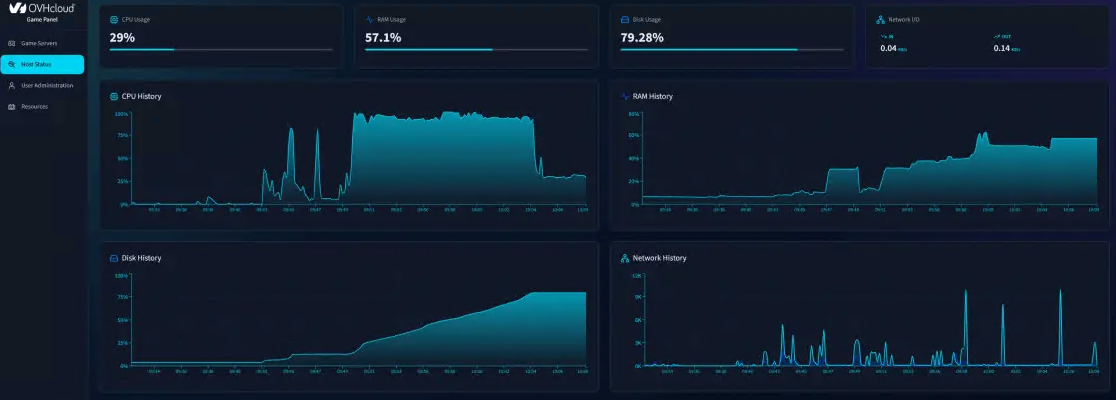
- Панель управления сервером
Подробнее и заказ:
abcd.host/dedicated