В 2013 году Scaleway стала одним из первых облачных провайдеров, предложивших экземпляры ARM на физическом оборудовании — физические серверы, доступные напрямую без виртуализации. Одиннадцать лет спустя мы повторили свой успех, запустив первое в мире выделенное серверное решение на базе архитектуры RISC-V.
Но как превратить архитектуру ISA в полностью функциональный облачный сервер? Давайте заглянем за кулисы этого новаторского проекта: от самого набора инструкций до решений в области аппаратного проектирования, которые сделали это возможным.
Возникновение архитектуры RISC-V
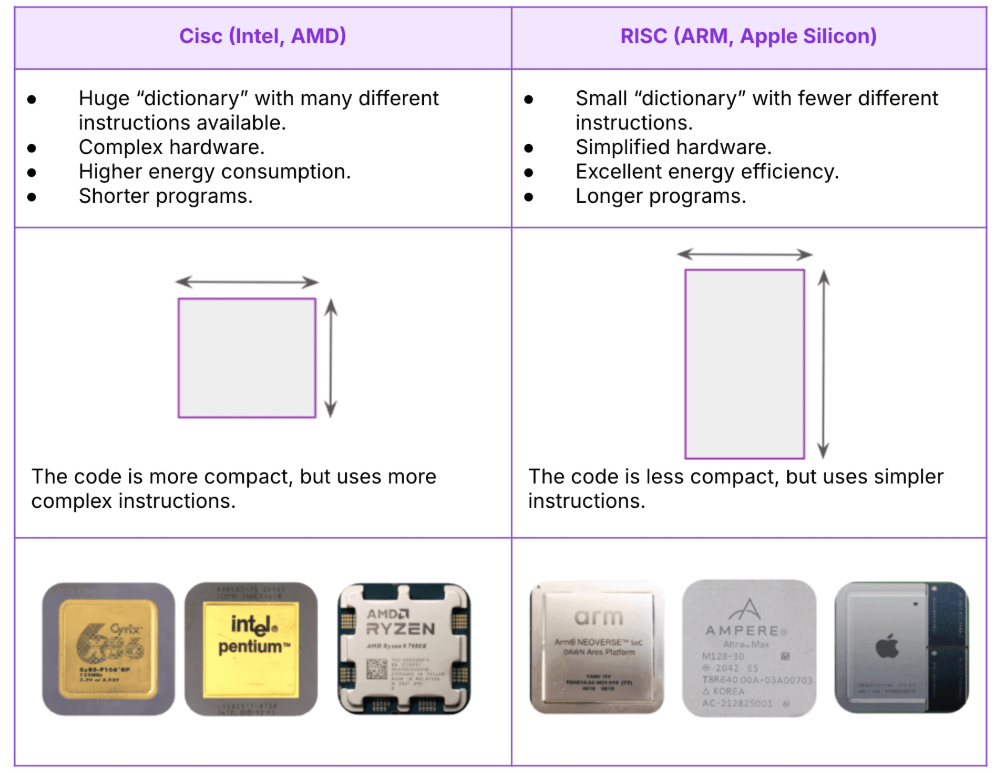
На протяжении десятилетий в мире процессоров доминировали архитектуры CISC (Complex Instruction Set Computing), а такие гиганты, как Intel и AMD, формировали современную вычислительную технику.
Эти архитектуры, разработанные для выполнения сложных инструкций с минимальным количеством строк кода, стали движущей силой развития ноутбуков и серверов. Однако с появлением мобильных телефонов в 2000-х годах они оказались менее подходящими, поскольку потребляли больше энергии и предлагали меньшую гибкость для новых сценариев использования.
В ответ на эти ограничения архитектуры RISC (Reduced Instruction Set Computing), впервые появившиеся в 1980-х годах, пережили мощное возрождение. Благодаря более простым инструкциям, которые процессоры могут выполнять быстрее, они позволяют разработчикам оптимизировать как энергопотребление, так и производительность.
В частности, компания ARM помогла вернуть архитектуру RISC в мейнстрим для потребительских приложений, создав более легкие и энергоэффективные процессоры, подходящие для смартфонов и подключенных устройств.
Сегодня RISC-V делает еще один шаг вперед, предлагая набор инструкций с открытым исходным кодом — машинный язык, понятный процессору. В отличие от проприетарных архитектур, таких как x86 или ARM, эта архитектура набора инструкций (ISA) является свободной и открытой для всех, не требует лицензирования и может свободно расширяться или модифицироваться.
 Революция RISC-V и её влияние
Революция RISC-V и её влияние
Архитектура RISC-V, разработанная в 2010 году в Калифорнийском университете в Беркли, продолжает традиции более ранних RISC-архитектур.
Основной принцип — модульность набора инструкций. В то время как предыдущие поколения (RISC I–IV) были ориентированы в первую очередь на производительность, RISC-V делает акцент на гибкости. Разработчики могут добавлять расширения, чтобы адаптировать свои процессоры к конкретным задачам: векторным вычислениям, обработке данных в рамках искусственного интеллекта, шифрованию и многому другому.
Хотя такой подход позволяет разрабатывать более специализированное оборудование, он также имеет свои недостатки: каждая комбинация расширений создает новый вариант машинного языка. Другими словами, программа, скомпилированная для одной конфигурации, может не работать на другой. Эта фрагментация сейчас вызывает беспокойство у части сообщества: Линус Торвальдс, например, критикует растущее число вариантов RISC-V.
Для решения этой проблемы Фонд RISC-V представил стандартизированные профили, такие как RVA23, которые определяют общий базовый набор обязательных инструкций и расширений, которые производители должны внедрить. Эти профили обеспечивают разработчикам стабильную основу и гарантируют, что одно и то же программное обеспечение может работать на разных процессорах без перекомпиляции.
Когда мы говорим, что RISC-V — это открытый исходный код, важно различать саму архитектуру набора команд (ISA) — стандарт, который является открытым, — и её физическую реализацию, которая не всегда таковой является. В большинстве случаев внутренняя архитектура процессора и его код разработки (HDL) остаются собственностью компании. Таким образом, производители сохраняют свои коммерческие секреты и бизнес-модели, при этом соблюдая общедоступные «правила», установленные профилем.
Без этой общей базовой конфигурации системе пришлось бы либо эмулировать отсутствующие инструкции — ценой крайне низкой производительности — либо просто не иметь возможности выполнять определенные задачи, требующие специальной аппаратной поддержки, такие как виртуализация.
Таким образом, RISC-V находится на переломном этапе: необходимо найти баланс между перспективой открытой, настраиваемой архитектуры набора команд и задачей поддержания целостной и совместимой экосистемы.

Приведенная выше диаграмма дает представление о «рецепте», используемом для составления архитектуры набора команд RISC-V: каждая буква соответствует стандарту или специализированному расширению, которое делает данную архитектуру уникальной. Возьмем, к примеру, SiFive U74, используемый в отладочной плате HiFive Unmatched.
За этой архитектурой ISA скрывается «RV64GC (RV64IMAFDC)», что указывает на 64-битную архитектуру (RV64) с расширениями для умножения (M), атомарных инструкций (A), операций с плавающей запятой (F и D) и сжатых инструкций ©. Кто бы мог подумать, что выбор процессора может быть настолько сложным?
Какие трудности пришлось преодолеть компании Scaleway для запуска первого продукта на базе архитектуры RISC-V Bare Metal?
За последние несколько лет экосистема RISC-V продолжала расти и все чаще используется промышленными компаниями. RISC-V теперь поддерживается такими крупными проектами, как Android и ядро Linux, и даже ожидается, что она будет использоваться в будущих миссиях NASA. RISC-V Summit, флагманское мероприятие экосистемы, теперь объединяет не только исторических основателей и сообщество открытого исходного кода, но и гигантов облачных технологий и полупроводниковой промышленности. Это сильно отличается от ранних, малоизвестных конференций.
В отделе исследований и разработок Scaleway мы предвидели этот импульс и приступили к разработке первого облачного решения на базе экземпляров RISC-V. Однако адаптация доступного на тот момент оборудования RISC-V к ограничениям облачных вычислений оказалась настоящей проблемой.
Зарождение проекта
Наша цель была ясна: запустить первое в мире решение на базе RISC-V Bare Metal. Задача? Использовать платы, не предназначенные для центров обработки данных, и превратить их в серверы, способные обеспечить работу первого облачного решения на базе RISC-V.
К счастью, у Scaleway уже была полностью налажена инфраструктура для развертывания серверов без операционной системы. Оставалось лишь интегрировать эту новую архитектуру в нашу существующую программную среду.
Вот как началось это путешествие и как компания Scaleway вносит свой вклад в революцию RISC-V.
Выбор подходящих SoC и производителей
Первым шагом была оценка того, какое оборудование действительно можно использовать. Мы начали с определения ключевых игроков, поставщиков и производителей. На тот момент выбор был ограничен, но две системы на кристалле (SoC) выделялись среди остальных:
- TH1520, разработанный компанией T-Head (полупроводниковое подразделение Alibaba Group), работает на процессоре Xuantie C910.
- JH7110, разработанный компанией StarFive Technology, работает на процессоре SiFive U74.
В целях повышения производительности мы выбрали TH1520. Наши тесты на плате VisionFive 2 показали, что TH1520 обеспечивает большую вычислительную мощность, чем SoC JH7110, что крайне важно для сценариев использования в производственных условиях.
Первая задача: запустить платы.
На момент нашего исследования не существовало материнских плат серверного типа, совместимых с загрузкой UEFI для плат RISC-V, в отличие от мира x86. Нам пришлось работать с процессом загрузки, унаследованным от встроенных систем, — что было крайне нетрадиционно для центра обработки данных.
Задача оказалась далеко не тривиальной: нам нужно было добиться полной загрузки плат в пользовательское пространство Linux. Приведенная ниже диаграмма иллюстрирует различия и сходства между процессом загрузки стандартных серверов центров обработки данных и наших машин на базе RISC-V.

Тем не менее, по мере развития экосистемы RISC-V, предложение становится все богаче. Например, Milk-V Titan поддерживает как UEFI, так и виртуализацию, но пока не доступен для коммерческой продажи. Аналогичная ситуация наблюдается и с ARM, которая поддерживает как серверные процессы загрузки (UEFI, GPT), так и более легкие процессы загрузки (ROM + U-Boot) для встраиваемых систем.
Загрузка операционной системы с образов, предоставленных производителем, относительно проста, но этого недостаточно для интеграции с облаком: в облачной среде машины также должны уметь загружаться по сети. Нам было доступно несколько вариантов — PXE, iPXE и UEFI HTTP Boot — но мы быстро обнаружили, что фактически работал только PXE. На тот момент ни iPXE, ни UEFI не были портированы на эту архитектуру.
Таким образом, нам удалось загрузить минимальную систему Linux (BusyBox), а затем запустить дистрибутив Debian. Это подтвердило, что платы достаточно зрелые для использования в реальном продукте.
Мы используем два связанных между собой этапа U-Boot: первый, минимальный, зафиксированный в eMMC, который обеспечивает стабильную и неизменяемую загрузку, за которым следует заключительный этап загрузки U-Boot, который мы можем обновлять со временем. Такое разделение предотвращает любые непреднамеренные изменения на стороне клиента, при этом позволяя нам обновлять загрузчик.
В итоге, полный процесс загрузки (который клиент не может изменить) выглядит следующим образом:
- Запуск сервера
- Выполнение минимального проприетарного кода, загружающего загрузчик первого этапа.
- Выполнение загрузчика первого этапа (U-Boot SPL), отвечающего, в частности, за загрузку загрузчика второго этапа.
- Выполнение загрузчика второго этапа (U-Boot Proper) и загрузка окончательного загрузчика.
- До этого момента процесс является стандартным для встроенных систем. Однако следующая часть может быть изменена заказчиком:
- Запуск финального загрузчика (снова U-Boot Proper, но с другой конфигурацией), который загружает OpenSBI и ядро Linux.
- Инициализация OpenSBI, эталонной реализации спецификации SBI для архитектуры RISC-V, выступающей в качестве уровня абстракции встроенного ПО между оборудованием и операционной системой. Она позволяет ядру взаимодействовать с оборудованием через стандартизированный интерфейс для выполнения привилегированных операций.
- запуск ядра Linux
На этом этапе мы смогли загрузить серверы RISC-V. Следующим шагом стала их интеграция в наши центры обработки данных.
Разработка аппаратного обеспечения: от прототипа до шасси для монтажа в стойку.
Чтобы понять сложность нашей интеграции, полезно вспомнить, как физически устроен центр обработки данных:
- Стойка: стандартизированный металлический шкаф, разделенный на стандартные по размеру блоки (часто высотой 52U, где 1U = 1,75 дюйма, или около 4,45 см), позволяющий размещать серверы, коммутаторы и силовое оборудование в оптимизированном пространстве с централизованным воздушным потоком и электропитанием.
- Шасси: металлический корпус, устанавливаемый в стойку, в котором непосредственно размещается оборудование (процессор, оперативная память, диски) или который позволяет вставлять съемные компоненты (накопители или даже серверы в формате блейд-серверов).
- Блейд-серверы: съемные лотки, вставляемые в корпус, позволяющие заменить сервер без остановки всего оборудования.
Мы выбрали блейд-серверы, каждый из которых содержал кластерную плату — материнскую плату, объединяющую мини-серверы в виде съемных модулей, — с 7 выделенными серверами RISC-V.
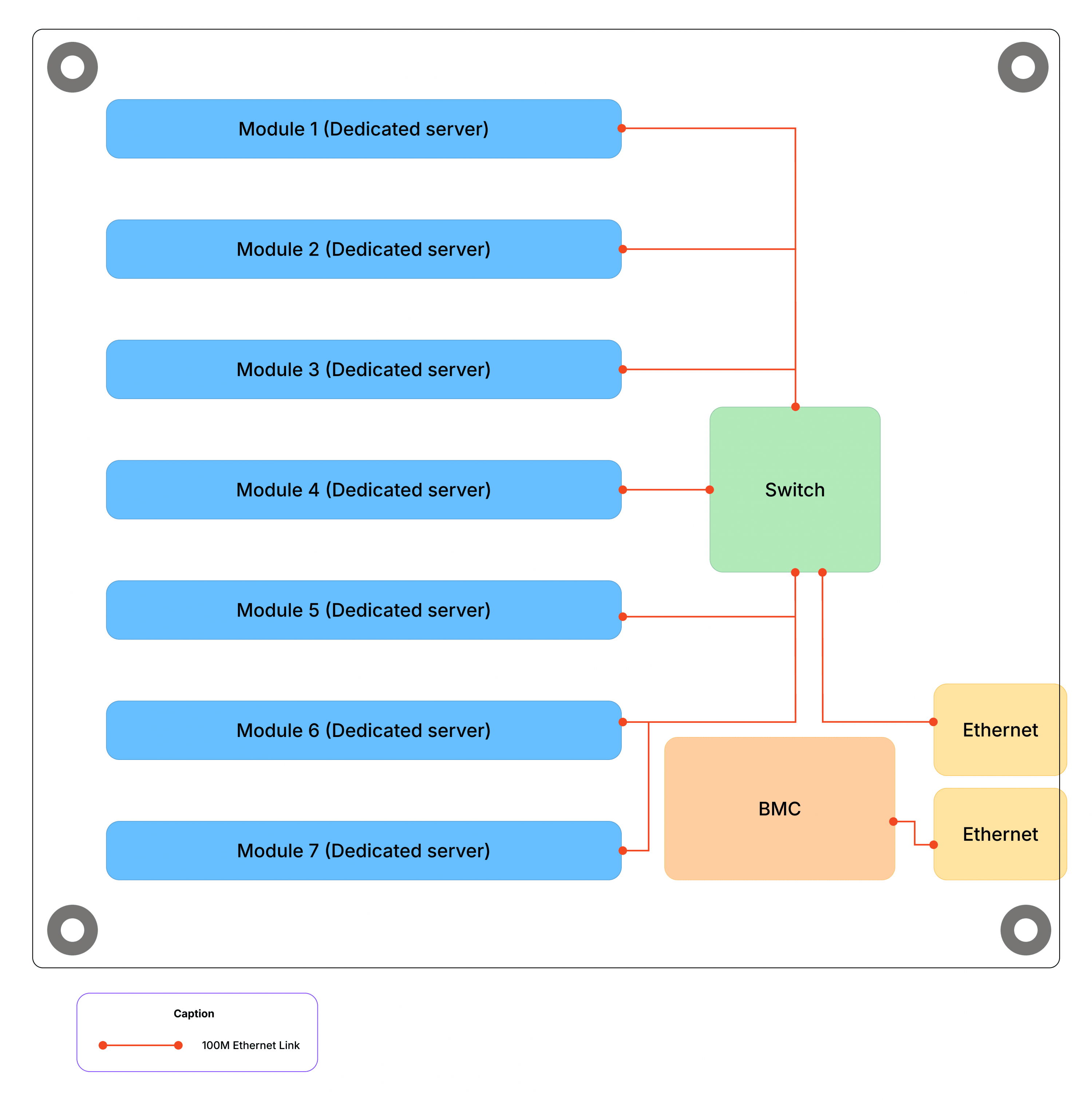
Такой подход обеспечивает высокую плотность размещения серверов. В шасси высотой 5U можно разместить 12 блейд-серверов по 7 серверов в каждом, плюс 1U для блока питания.
 Проектирование лопастей и 3D-моделирование
Проектирование лопастей и 3D-моделирование
В кластерных платах используется формат mini-ITX. Несмотря на компактность и практичность для разработки, этот формат не подходит для прямой интеграции в центры обработки данных, поскольку его нельзя установить в стандартную стойку. Для подготовки этих кластерных плат к серийному производству нам пришлось провести полную разработку механического решения. Цель заключалась в объединении следующих элементов:
- большое количество серверов на единицу высоты,
- контролируемое управление питанием,
- и эффективное воздушное охлаждение.
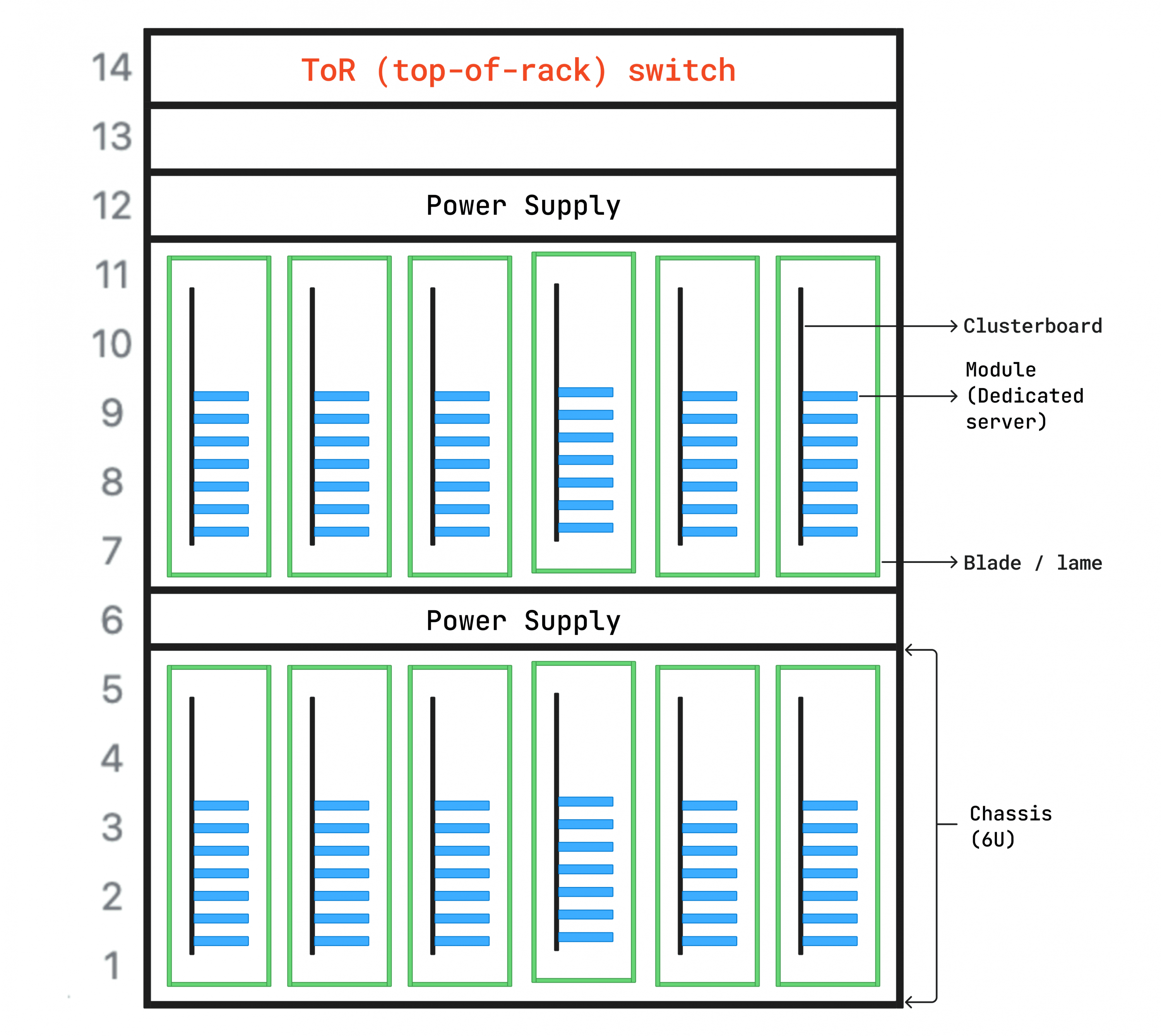
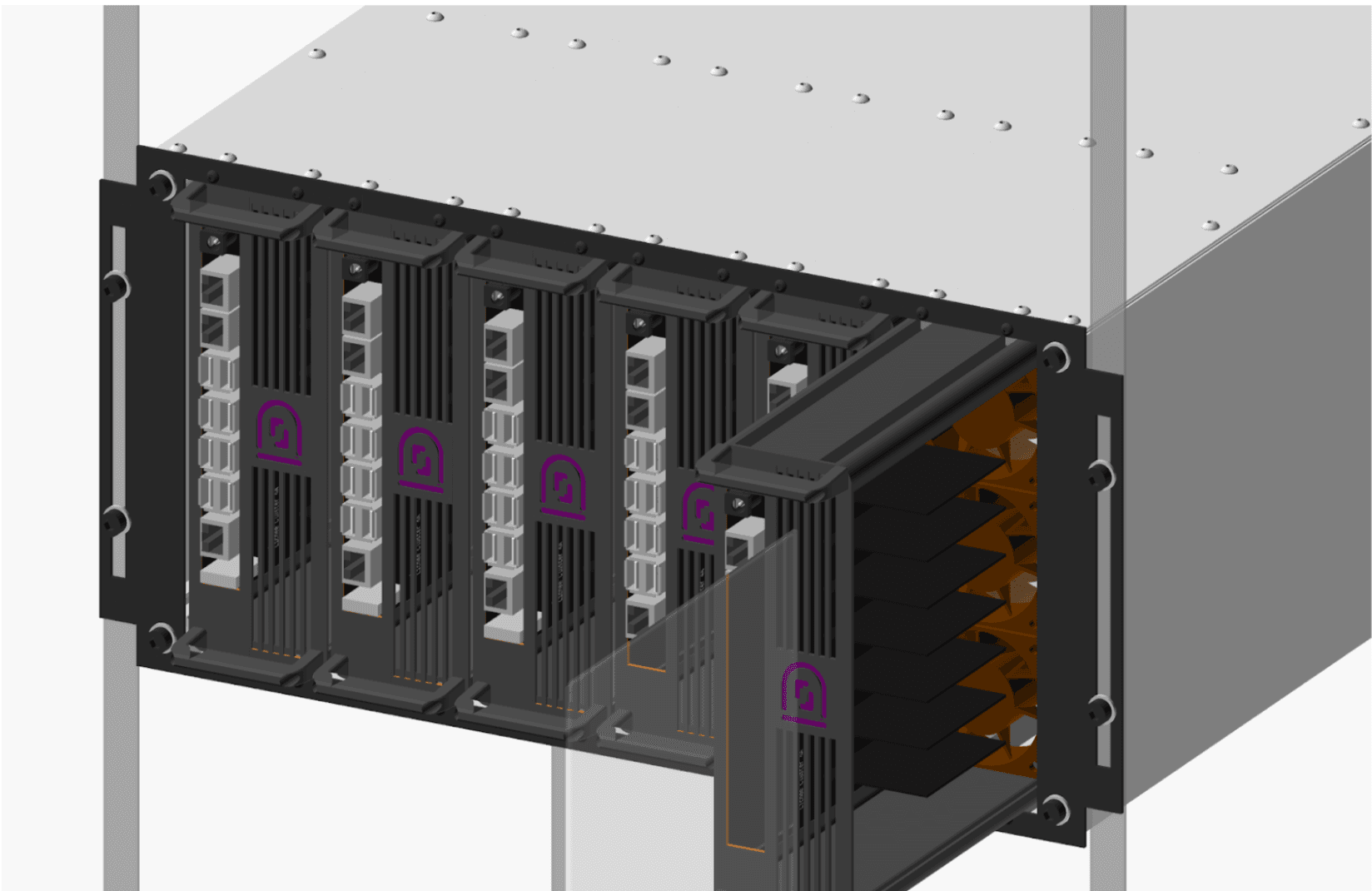
Для достижения этой цели мы разработали и напечатали на 3D-принтере специальные блейд-серверы, способные вмещать наши кластерные платы. Мы создали шасси высотой 5U, которое может одновременно вмещать двенадцать блейд-серверов — шесть спереди и шесть сзади. Такой подход позволяет нам интегрировать наши серверы RISC-V в стандартные стойки центров обработки данных, максимально увеличивая плотность размещения — до 84 выделенных серверов на шасси.
Энергоэффективность
Что касается энергопотребления, то кластерная плата потребляет в среднем около 55 Вт, или примерно 660 Вт на весь корпус. Для сравнения, типичный сервер Dell x86 (Dell R660) потребляет около 350 Вт на 1U, что составит 1750 Вт для 5U серверов Dell — при гораздо меньшем количестве серверов, чем мы размещаем в наших корпусах RISC-V. Конечно, вычислительная мощность процессоров x86 последнего поколения сегодня значительно выше.
Но дело не в этом. Здесь важна эффективность — соотношение между производительностью и энергопотреблением.
Эта конструкция на базе RISC-V в сочетании с компактной механической структурой и низким энергопотреблением обеспечивает превосходную плотность размещения серверов в стойке.
Все блейд-серверы на базе RISC-V были полностью напечатаны на 3D-принтере в нашем офисе в Париже, а шасси были вырезаны лазером из металлических листов. Каждый этап производства осуществлялся собственными силами, что позволило нам совершенствовать и улучшать конструкцию на каждой итерации. Выбор материалов также имел важное значение, поскольку они должны были соответствовать требованиям центров обработки данных.


 Интеграция в облачную инфраструктуру
Интеграция в облачную инфраструктуру
Проблемы программного обеспечения: сети, BMC и U-Boot.
После того, как аппаратная часть была настроена, интеграция этих серверов RISC-V в наше решение Elastic Metal вызвала программные проблемы, особенно на сетевом уровне. Каждый модуль необходимо было изолировать, чтобы исключить любую связь между модулями на одной и той же плате кластера.
Нам также пришлось интегрировать BMC (Board Management Controller) — систему, позволяющую удаленно управлять сервером — включать его, осуществлять мониторинг, перезагружать — независимо от операционной системы. Обычно это отдельный компонент, расположенный рядом с контролируемым оборудованием. Для наших нужд нам пришлось адаптировать
OpenBMC, проект прошивки с открытым исходным кодом, первоначально продвигаемый компанией Meta, и интегрировать контроллер IPMI, адаптированный к оборудованию.
Этот протокол служит интерфейсом аварийного управления, позволяя нам контролировать электропитание сервера.
Система обеспечения ресурсами и развертывание в производственной среде
Последней проблемой стало масштабирование всех этих этапов развертывания. В дополнение к серийному производству шасси и модулей, мы создали систему обеспечения, способную обрабатывать прошивку микропрограммы, контроль качества каждого устройства, регистрацию и декларирование в производственной системе Scaleway.
Как только этот процесс был полностью налажен, серверы могли покинуть мастерскую и быть установлены в наших центрах обработки данных, превратив научно-исследовательский эксперимент в реальное облачное решение.
 Выпуск предложения EM-RV1 Bare Metal
Выпуск предложения EM-RV1 Bare Metal
Технические характеристики EM-RV1
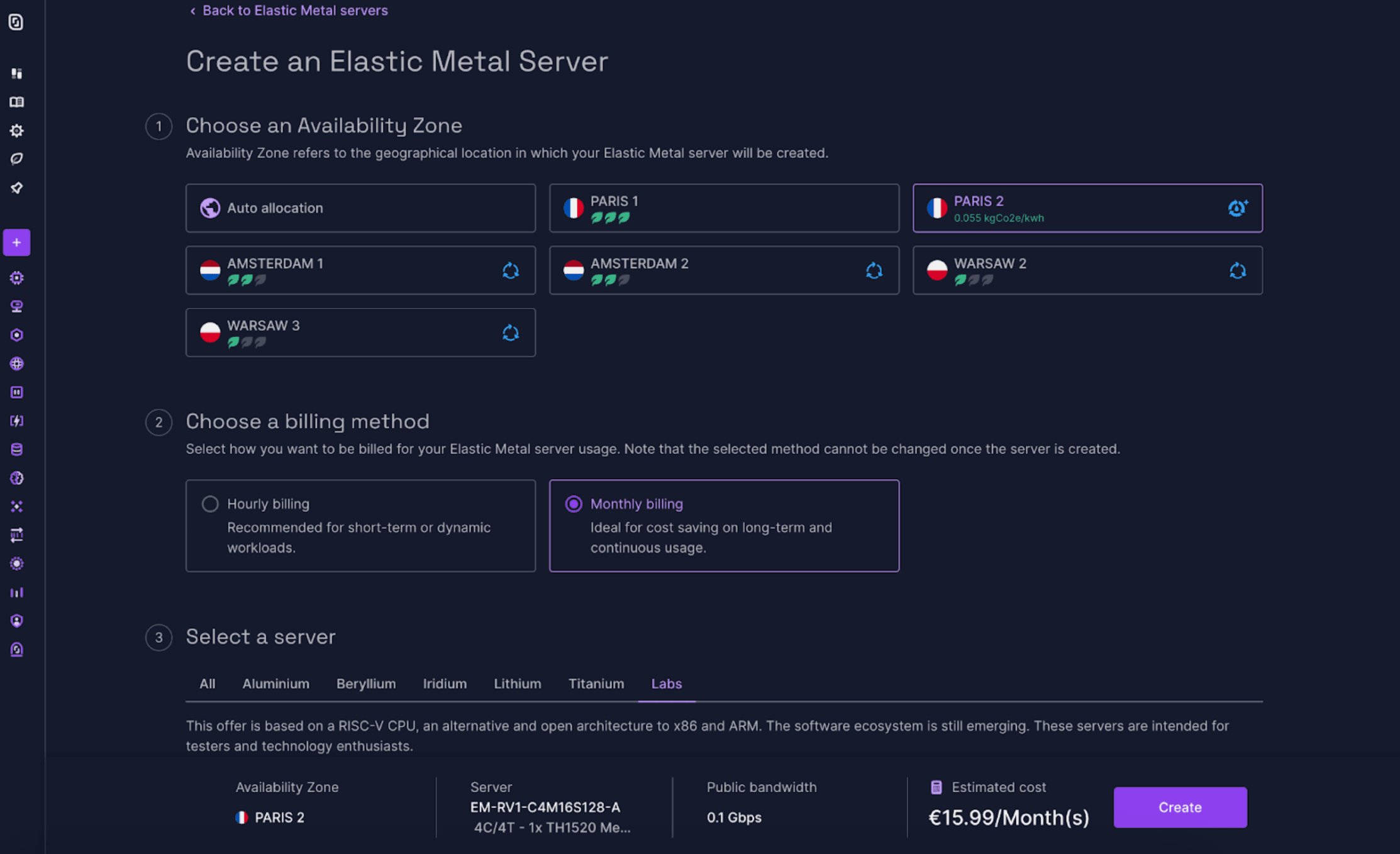
После интеграции первых серверов RISC-V в нашу производственную инфраструктуру, то, что начиналось как проверка концепции в научно-исследовательской лаборатории, превратилось в реальный продукт для наших клиентов. 29 февраля 2024 года мы официально запустили наше предложение RISC-V Bare Metal с моделью EM-RV1, обладающей следующими характеристиками:
Система на базе SoC T-Head 1520, включающая в себя:
- 4-ядерный процессор RISC-V с частотой 1,85 ГГц (C910)
- графический процессор, совместимый с OpenCL/Vulkan
- 4-точечный нейронный процессор для искусственного интеллекта
- 16 ГБ оперативной памяти LPDDR4
- 128 ГБ памяти eMMC
- Сетевое соединение со скоростью 100 Мбит/с
- Стандартные образы ОС для облачных сред: Debian, Ubuntu и Alpine.
Доступно на консоли Scaleway:
- Изделие: Эластичный металл
- Зона: Париж 2
- Вкладка: Лаборатории
 Оглядываясь назад: успехи и улучшения
Оглядываясь назад: успехи и улучшения
Успех был мгновенным, и серверы быстро распродались, что вынудило нас запустить в производство большее количество.
Но на этом мы не остановились. Мы продолжили расширять предложение, добавив Fedora, Kosmos и даже Android 12 благодаря команде Damo Academy — подразделению Alibaba, специализирующемуся на процессорах RISC-V, которое внесло значительный вклад в разработку SoC на базе RISC-V. Для самых смелых мы даже сделали доступной последовательную консоль серверов — и вместе с ней доступ к загрузчику — что позволило устанавливать самые экзотические операционные системы.
Ищете вызов? Почему бы не попробовать установить Arch Linux прямо из последовательной консоли?
А поскольку мы любим делать все как следует, мы также добавили такие функции, как гибкие IP-адреса и частные сети, предоставляя клиентам еще больше возможностей для настройки конфигурации с полным контролем над своей сетью и IP-адресами.
Уязвимость «GhostWrite» в микросхемах C910 RISC-V
Но инновации редко обходятся без препятствий. Исследователи из Центра информационной безопасности им. Гельмгольца при CISPA обратили наше внимание на уязвимость под названием « GhostWrite » в микросхемах C910 RISC-V, развернутых в нашем облаке.
Эта уязвимость позволяла злоумышленникам без привилегий выполнять произвольные операции записи в память с помощью инструкции, vse1024.vявляющейся частью векторного расширения (V), что потенциально могло привести к повышению привилегий до уровня Ring 0.
Однако важно отметить, что данная инструкция не является частью официальной версии проекта расширения векторной графики RVV 0.7.1, используемой в настоящее время на наших серверах. Эта версия представляет собой промежуточный стандарт, несовместимый с финальной версией RVV 1.0. Поскольку RVV 0.7.1 практически не используется в производственной среде, отключение этого расширения векторной графики не оказывает существенного влияния на производительность сервера.
В ответ на это мы отключили расширение V vector по умолчанию на наших серверах посредством обновления ядра, еще до того, как информация об уязвимости стала достоянием общественности. Инструкции по повторному включению расширения доступны в нашей документации.
Что можно делать на практике с сервером на базе RISC-V?
Всё то, что вы делали бы на традиционной архитектуре. На момент запуска нашего продукта чуть более 96% пакетов Linux (Debian, Fedora, Ubuntu) были совместимы с RISC-V; сегодня этот показатель составляет около 98%. Поэтому веб-серверы, базы данных, кластеры Kubernetes — всё работает.
Компиляторы, такие как GCC и LLVM, продолжают развиваться и совершенствоваться для RISC-V, и хотя поддержка образов Docker всё ещё находится в стадии разработки, уже сейчас возможно создавать и тестировать программное обеспечение на разных архитектурах с помощью многоархитектурных конвейеров CI/CD. Вкратце, RISC-V предоставляет вам возможность развертывать, тестировать и внедрять инновации в рамках быстро развивающейся открытой экосистемы.
Почему, несмотря на свои преимущества, архитектура RISC-V до сих пор не получила широкого распространения?
Несмотря на свои преимущества, RISC-V остается молодой технологией по сравнению с x86 и ARM, которые прочно утвердились на рынке на протяжении десятилетий. Ее внедрение по-прежнему сталкивается с двумя основными препятствиями:
- Риск фрагментации: как объяснено выше, это главная проблема. Если стандарт слишком гибкий, программное обеспечение может стать несовместимым с различными процессорами.
- Зрелость экосистемы: оборудование существует, но программное обеспечение еще должно соответствовать современным требованиям. Миграция критически важных приложений занимает время и требует значительных инвестиций для устранения пробелов в оптимизации. Чтобы помочь разделить эти затраты на разработку, крупные игроки, включая Google, Samsung и Nvidia, объединили усилия в проекте RISE (RISC-V Software Ecosystem).
Будущее RISC-V в Scaleway
Выпуск первого решения на базе RISC-V Bare Metal был лишь началом.
Экосистема стремительно развивается, появляются высокопроизводительные серверы, такие как
Sophgo SRA3-40, Ubuntu обеспечивает встроенную поддержку стандарта
RVA23, а также создаются рабочие группы, например,
Data Center SIG в рамках RISC-V International.
В мае 2024 года компания Scaleway присоединилась к
фонду RISC-V, подтвердив свою приверженность этой архитектуре и намерение продолжать разработку и предоставление инновационных услуг на основе RISC-V. Мы также регулярно выступаем на крупных мероприятиях, таких как
RISC-V Summit.
Началась эра RISC-V в центрах обработки данных, и мы гордимся тем, что принимаем в ней полноценное участие.