Инцидент с охлаждением в дата-центре локации «Амстердам» (Qupra DC2). Постмортем и наши обязательства

Статус на момент публикации (3.07.2026). Все серверы локации «Амстердам» работают в штатном режиме. Дата-центр функционирует на внешнем (резервном) чиллере; работы по восстановлению основной системы охлаждения продолжаются. Мы держим ситуацию под усиленным контролем. Пока основная система охлаждения не восстановлена и не подтверждён резерв, мы считаем ситуацию незакрытой.
Это подробный разбор того, что произошло с локацией «Амстердам» в мае–июле 2026 года, почему это случилось, что мы сделали не так и что делаем дальше. Мы понимаем, что подвели вас, и приносим извинения. Ниже — по существу
Коротко о главном
- В мае–июле 2026 года в дата-центре нашей локации «Амстердам» (Qupra DC2) произошла серия отказов системы охлаждения. Оборудование уходило в аппаратную защиту от перегрева, из-за чего серверы были недоступны.
- Первопричина — отказы системы охлаждения на стороне дата-центра. Аномальная жара стала триггером, но не единственной причиной: цепочка инженерных и эксплуатационных отказов на площадке превратила единичный сбой в каскад (подробно — ниже).
- Данные клиентов сохранены. Аварии касались доступности, а не целостности данных.
- Компенсация и бонусы для пострадавших клиентов локации «Амстердам»: возврат за фактический простой на баланс (тикет в техподдержку, по SLA) плюс бонусы-промокоды на продление — QUPRA100 (100% на 14 дней) и следом QUPRA15 (15% на 3 месяца). Для уже ушедших клиентов — отдельный порядок. Подробнее — в разделе «Компенсации и бонусы».
- Мы не рассматриваем гарантии или доработки со стороны Qupra — только переезд локации на новый дата-центр.
- Повышение цен, о котором вы получили уведомление, — не связано с инцидентом: это совпадение по времени, и мы это учли (см. раздел «О ценах»).
Что произошло
В дата-центре Qupra DC2 (Амстердам), где размещена наша локация «Амстердам», несколько раз выходила из строя система охлаждения. Когда охлаждение останавливается, оборудование в стойках быстро перегревается, и включается защита. Часть её срабатывает автоматически, на уровне железа: процессоры снижают частоты (троттлинг), а при достижении критической температуры сервер аппаратно выключается сам. Часть — управляемо, по нашему решению: чтобы не ронять машины жёстко и сохранить ваши данные, мы штатно и контролируемо выключаем серверы (graceful shutdown), а дата-центр при необходимости обесточивает перегретые стойки со своей стороны. Результат в любом случае один: сервер временно недоступен.
Каждый такой отказ приводил к многочасовому простою локации. Самая длительная авария в конце июня — начале июля растянулась почти на двое суток.
Хронология
Ниже — все известные нам эпизоды недоступности локации «Амстердам», связанные с охлаждением. Время указано по МСК.
- 27.05.2026, 12:33 → 19:42 (≈5 часов). Отказ системы охлаждения: вышел из строя основной чиллер на крыше. Вечером дата-центр привёз и установил резервный чиллер.
- 26.06.2026, 16:51 → 21:55 (≈5 часов). Снова отказ охлаждения. Инцидент пришёлся на ночь выходного дня. Мы не опубликовали о нём информацию своевременно — это была ошибка (см. раздел «Что мы сделали неправильно»).
- 29.06.2026, 13:10 → 16:58 (≈4 часа). Очередной отказ охлаждения.
- 29.06 (поздний вечер) → 01.07.2026, 22:24 — самая длительная авария (≈44 часа). Отказавший чиллер запустить не удалось. Дата-центр организовал доставку и подключение внешнего чиллера, но подключение затянулось из-за отсутствия на площадке нужных силовых кабелей — их привезли только 1 июля. Внешний чиллер подключили около 14:00, серверы начали подниматься примерно с 15:30, восстановление шло поэтапно.
Почему это произошло
Триггером отказов стала аномальная жара в Западной Европе летом 2026 года: система охлаждения площадки не удержала тепловую нагрузку при высокой наружной температуре. Но жара — не единственная причина. За затяжным простоем конца июня стоит цепочка инженерных и эксплуатационных отказов на самой площадке.
Что именно отказало
Приводим восстановленную картину работы инженерных систем дата-центра — по информации, которой мы располагаем.
- До конца мая охлаждение обеспечивал основной чиллер на крыше здания. 27 мая он вышел из строя.
- Дата-центр привёз резервный чиллер, разместил его за зданием и запитал от внешнего дизель-генератора, подключив к системе охлаждения. Нам сообщили, что основной (крышный) чиллер также восстановлен.
- В конце июня внешний дизель-генератор, питавший резервный чиллер, был убран с площадки — и резервный чиллер обесточился.
- Дата-центр переключился на основной чиллер, но тот, вопреки сообщению о восстановлении, к вечеру отказал окончательно — запустить его не удалось даже с привлечённым сервисным инженером.
- Оперативно найти замену дизель-генератору не получилось. Для подключения резервного чиллера напрямую к электрощиту площадки пришлось заказывать силовые кабели (около 60 метров), доставка заняла порядка суток. На это время охлаждение держали на фрикулинге, без компрессора.
- После доставки кабелей резервный чиллер подключили штатно, и охлаждение вышло на рабочий режим. На сегодня локацию охлаждает один исправный чиллер; второй (на крыше) остаётся в восстановлении.
Наша ответственность
Мы не будем прятаться за формулировкой «виноват дата-центр». За питание и охлаждение физически отвечает площадка, а не хостинг-провайдер, — но выбор площадки это наша ответственность. Мы разместили вашу инфраструктуру в Qupra DC2, мы на ней оставались, и перед вами за результат отвечаем мы. Именно поэтому наше решение — уходить с площадки, а не ждать её доработок (см. «Что мы меняем»).
Мы переехали в Qupra DC2 в конце 2025 года, когда прежняя площадка (euNetworks) закрывалась и просила арендаторов освободить помещение. Новый дата-центр оказался не готов держать нашу нагрузку. Это в том числе наш урок по выбору и аудиту площадки.
О слухах: это НЕ история с изъятием серверов
Этим летом в Амстердаме случилось несколько разных инцидентов у разных операторов, и в сети их смешивают. Уточним прямо: наш инцидент — технический, связан только с охлаждением. Он не имеет отношения к истории с принудительным обесточиванием и изъятием серверов у другого оператора в другом дата-центре, которая обсуждалась в те же недели. Ваши серверы никто не изымал и не опечатывал, доступ к ним не блокировался по чьему-либо требованию.
Что с вашими данными
Данные клиентов локации «Амстердам» сохранены. Аварии касались доступности: серверы уходили в защиту и обесточивались контролируемо именно для того, чтобы сохранить оборудование и данные. Потери данных по причине инцидента с охлаждением не зафиксировано. Если у вас есть основания подозревать проблему с целостностью данных на конкретной услуге — напишите тикет, разберём индивидуально и в приоритете.
Что мы сделали неправильно
Отдельно и без смягчений — о наших собственных ошибках.
Мы не остановили приём заказов в проблемной локации. Во время аварии заказ новых серверов в локации «Амстердам» оставался доступен. Из-за этого часть клиентов оформили серверы, которые невозможно было развернуть сразу, пока инфраструктура была недоступна. Это наша ошибка. Все такие серверы были развёрнуты после восстановления работы кластера.
Мы своевременно не сообщили об инциденте 26 июня. Авария пришлась на ночь выходного дня, и мы не опубликовали информацию ни в тот день, ни на следующий. Молчание — худшее, что можно сделать в такой ситуации: оно оставляет вас без информации и разрушает доверие сильнее самого сбоя. Так делать нельзя, и мы это исправляем.
Как работали поддержка и связь во время аварии
Во время массовой аварии поток обращений возрастает кратно и превышает пропускную способность поддержки и телефонной линии. В такой ситуации операторы физически не могут ответить всем, а попытки разбирать каждое обращение индивидуально только замедляют работу над самой аварией. Поэтому на время инцидента мы концентрируем ресурсы на восстановлении и на регулярных публичных апдейтах по статусу. Это стандартная практика при инцидентах такого масштаба, и рабочей альтернативы ей нет.
Компенсации и бонусы
Разделяем две вещи: компенсацию за фактический простой и бонус сверх неё. Оба доступны клиентам локации «Амстердам», чьи затронутые услуги были активны в период инцидента.
Компенсация за простой (по SLA)
Возврат средств за фактическое время недоступности — на баланс, по SLA. Чтобы её получить, напишите тикет в техподдержку: мы рассчитаем простой по вашей услуге и вернём его стоимость на баланс.
Бонусы (промокоды)
Сверх компенсации — два промокода на продление серверов локации NL (все тарифы). Тикет для них не нужен, они применяются вами самостоятельно в личном кабинете. Действуют только для услуг, заказанных до 1 июля 2026; скидка распространяется и на сам сервер, и на дополнительные услуги.
Промокоды применяются последовательно, именно в таком порядке:
- QUPRA100 — скидка 100% на 14 дней. Активировать с 3 июля по 3 августа. После активации сервер будет работать две недели бесплатно.
- QUPRA15 — скидка 15% на 3 месяца. Активировать с 18 июля по 31 августа, после того как отработают 14 дней по QUPRA100.
Если вы уже отказались от услуги из-за инцидента
- Компенсация — в общем порядке: напишите тикет в техподдержку, мы вернём стоимость простоя на баланс (с последующим выводом на вашу карту или счёт).
- Бонус — в ручном режиме: напишите тикет в отдел продаж и опишите ситуацию. Мы вручную назначим скидку на новую услугу с аналогичными условиями (100% на 14 дней, далее 15% на 3 месяца).
Почему мы не компенсируем упущенную выгоду
Отдельно и честно — о том, что многие ждут, но чего мы сделать не можем.
Мы понимаем, что для многих из вас простой — это не «минус несколько часов аренды», а остановленные заказы, недоступные кассы, сорванные процессы и потерянные клиенты. Это реальный ущерб, и мы его не обесцениваем.
Но важно проговорить границы прямо: услуга хостинга — это не страховой полис на ваш бизнес. Как и у любого инфраструктурного провайдера, наша ответственность по договору-оферте ограничена стоимостью самой услуги за период недоступности и не включает косвенные убытки — упущенную выгоду, потерю клиентов, издержки простоя вашего бизнеса. Это не попытка уйти от ответственности, а фундаментальное отличие инфраструктурной услуги от страхования: стоимость сервера в месяц несопоставима с оборотом бизнеса, который на нём работает, и провайдер не может брать на себя эти риски — иначе услуга стоила бы кратно дороже для всех клиентов сразу. Ни один хостинг-провайдер на рынке так не работает, и экономически иначе быть не может.
При этом мы не перекладываем ответственность за базовый аптайм на вас — обеспечивать доступность площадки наша работа, а не ваша. Но для критичных нагрузок есть дополнительный контур защиты, который снимает зависимость от одной площадки: резервное копирование и вторая локация. Для критичных данных мы рекомендуем подключить бэкапы.
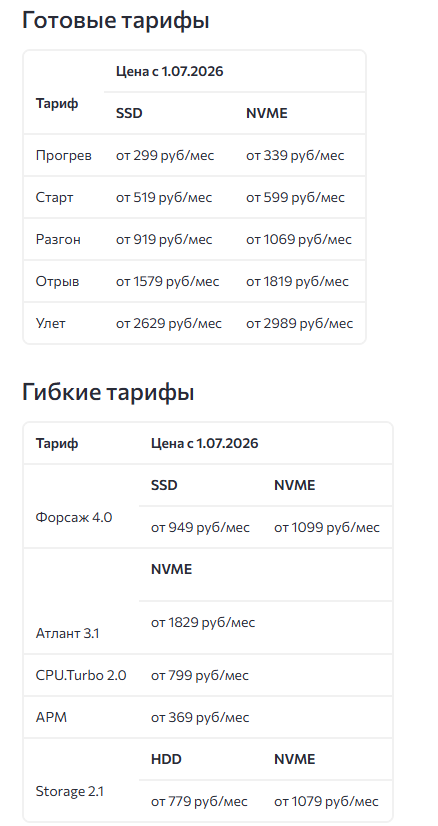
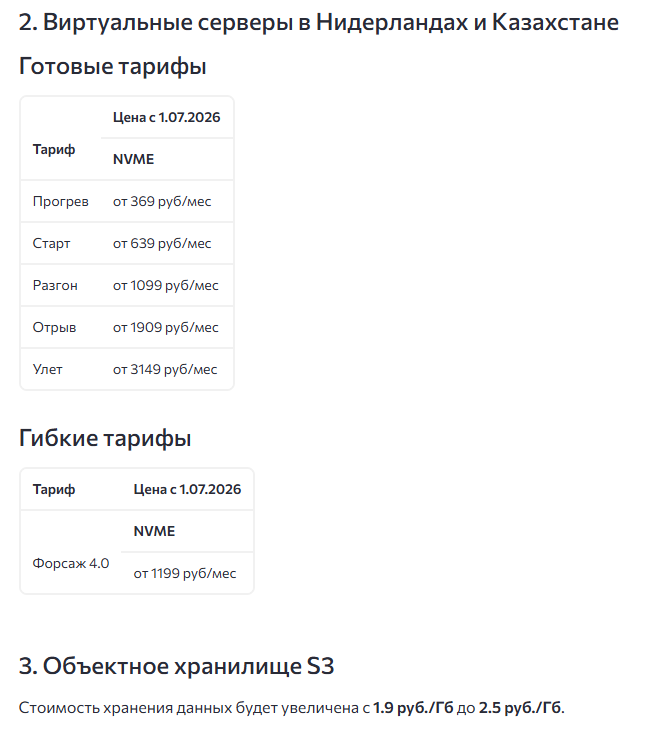
О ценах
Понимаем, как это выглядит со стороны: сервис падал — а вы получили уведомление о повышении цен. Это совпадение по времени: плановое изменение тарифов готовилось заранее и не связано с инцидентом. Тем не менее момент вышел болезненным, и та же скидка 15% на продление затронутых услуг (см. «Компенсации и бонусы») смягчает для вас это повышение.
Что мы меняем
Площадка. Принято решение уходить из Qupra DC2. Сейчас мы выбираем новый дата-центр. Основной кандидат, которого мы оцениваем, — площадка в Амстердаме уровня Tier 3 с сертификацией управления непрерывностью бизнеса (ISO 22301) и точкой присутствия AMS-IX; параллельно рассматриваем ещё несколько вариантов. Решение принимаем на этой неделе. Конкретную площадку, график переезда и порядок переноса объявим отдельным анонсом. Сам переезд спланируем так, чтобы исключить или свести простой к минимуму и заранее предупредить вас по каждой затронутой услуге. Текущие IP-адреса на услугах будут сохранены.
Текущее состояние. До восстановления основной системы охлаждения и подтверждения резерва локация остаётся под усиленным мониторингом. Сейчас она работает на внешнем чиллере.
Коммуникация. Мы работаем по принципу, который в этом инциденте показал себя как единственно
- правильный, — говорить честно и по делу:
- регулярные апдейты по расписанию во время аварии, с указанием времени следующего обновления;
- дежурный специалист на связи во время инцидента;
- никакой цензуры в чатах — мы не удаляем критику, не баним пользователей за неудобные вопросы, модераторы следят только за порядком.
Извинения
Мы подвели вас — и техническим сбоем, и тем, как повели себя в его первые часы. Спасибо тем, кто разбирал ситуацию публично и задавал неудобные вопросы: это помогло нам увидеть свои ошибки без прикрас. Доверие возвращается не заявлениями, а делами, и мы намерены его вернуть.