Онлайн-переезд EVPN-VXLAN-фабрики между дата-центрами: euNetworks → QupraDC без остановки сервиса

Меня зовут Рене, я сетевой инженер в FirstVDS. В первой части я рассказывал, как мы запускали небольшую европейскую площадку в Амстердаме: один Leaf, один Spine, routed host networking для гипервизоров, EVPN-VXLAN как сервисная плоскость, DDoS в отдельном VRF, OOBM и Flow-коллектор.
Эта часть — уже не про стартовый дизайн, а про его проверку реальностью. Дата-центр euNetworks закрывается, оборудование нужно перевозить, клиентскую нагрузку останавливать нельзя, адресацию менять нельзя, продажи новых услуг останавливать тоже нельзя.
Хорошая новость в том, что стартовая схема была построена не вокруг одной большой god-box, а как маленькая, но нормальная фабрика. Именно это позволило нам не делать одно рискованное переключение «всё сразу», а провести переезд через несколько контролируемых промежуточных состояний.
Вводная: ЦОД закрывается, сервис должен жить
Некоторое время площадка проработала штатно. Мы запустили сервисы, подключили обычный транзит, добавили DDoS-защиту и начали жить обычной эксплуатационной жизнью.
А потом пришла вводная: дата-центр euNetworks закрывается, оборудование нужно перевозить.
Для бизнеса вопрос звучал просто: что нужно купить, чтобы переехать? Следом появился второй, более интересный вопрос: можно ли не покупать ничего лишнего или взять это временно в аренду и переехать без остановки клиентского сервиса?
Требования получились такими:
- по возможности не покупать дополнительное сетевое оборудование;
- не останавливать продажи и не останавливать клиентский сервис;
- переносить серверы постепенно;
- сохранить старую клиентскую IP-адресацию;
- не сводить переезд к одному большому окну работ, в котором нужно переключить всё и сразу.
Переводя это на сетевой язык, я понял, что нам просто нужен ещё один Leaf в QupraDC, который можно временно включить в существующую фабрику. Старый Spine оставляем в euNetworks, новый Leaf физически ставим в QupraDC, а между площадками поднимаем временный IP-транспорт.
Изначально была идея взять этот Leaf как временное оборудование только на период миграции. Но поставщик сообщил, что после переезда забрать его обратно не сможет. Тогда я предложил не считать покупку вынужденной потерей, а использовать ситуацию как возможность улучшить архитектуру: оставить второй Leaf в новой локации и после переезда разнести серверные подключения по двум коммутаторам.
Так вынужденный переезд превратился ещё и в проект по повышению отказоустойчивости.
Временный DCI и первые серверы в QupraDC
Чтобы подключить новый Leaf в QupraDC к существующей фабрике, нам понадобился канал между дата-центрами.
На самом деле нам было почти всё равно, как именно поставщик реализует этот канал внутри своей сети: тёмная оптика, лямбда, проброс VLAN по коммутационной фабрике оператора, L2VPN, L3VPN или какой-то иной транспорт. Для нашей задачи была важна не технология, а конкретные технические свойства:
- пропускная способность не меньше 40G;
- возможность передавать IP-пакеты между старой и новой площадкой и желательно одним p2p-линком с /31-адресацией;
- MTU 9216;
- возможность быстро разобрать канал после завершения миграции;
- недорого.
Dot1q теги нам были не нужны, потому что мы не тащили пользовательские VLAN между дата-центрами, а даже если бы такая потребность была, то мы бы cделали это силами EVPN-VXLAN. Underlay-интерфейсы на Leaf и Spine были обычными L3-портами с IP-адресацией. По временному каналу должны были ходить IP-пакеты underlay и поверх них — VXLAN-инкапсулированный трафик overlay.
MTU был критичен. Внутри underlay передаются не только обычные IP-пакеты, но и трафик виртуальных машин в VXLAN-инкапсуляции. Если клиентская VM отправляет стандартный 1500-байтный пакет, к нему добавляется накладной расход VXLAN/UDP/IP. Если забыть про это на междатацентровом канале, можно получить неприятные проблемы с фрагментацией или чёрными дырами для части трафика. Отдельная практическая причина — сервисная потребность использовать jumbo frames для сетевых хранилищ: такие сценарии тоже требуют нормального запаса MTU в фабрике.
На underlay-интерфейсах мы используем MTU 9216 байт. Это максимальный размер передаваемого пакета для наших коммутаторов, поэтому нет практического смысла задавать меньшее значение внутри управляемой нами фабрики. Такой MTU даёт достаточный запас под VXLAN-инкапсуляцию, упрощает эксплуатацию и используется как единый стандарт во всех наших IP-фабриках.
Важно подчеркнуть: мы не строили stretched-L2 между дата-центрами. Временный L2-канал от поставщика использовался как транспорт для нашей L3-связности underlay. Для фабрики новый Leaf выглядел как ещё один Leaf, который просто находится чуть дальше, чем ожидалось ранее.
Никаких растянутых клиентских VLAN через xSTP, никаких попыток склеить две площадки в один большой L2-домен. Только IP-связность underlay и EVPN-VXLAN поверх неё.
Новый Leaf должен был быть точно такой же модели, чтобы сетевые чипы и версии программного обеспечения были максимально идентичны. В миграции под давлением и в условиях дефицита времени это важно. Теоретически EVPN должен нормально работать между разными платформами, но на практике смешивание разных чипов, разных версий ПО и разных профилей поведения control plane может превратить переезд в отладку ещё неразрешенных багов.
После физической установки нового Leaf в QupraDC последовательность работ была такой:
- Подключили новый Leaf через временный 40G-канал к существующему Spine.
- Настроили базовую IP-связность underlay.
- Проверили reachability между участниками фабрики.
- Подняли BGP-сессии underlay и overlay.
- Отмониторили стабильность BGP-сессий и качество канала.
- Проверили, что новый Leaf участвует в EVPN control plane и корректно получает необходимые маршруты.
На этом этапе важно было не торопиться с клиентской нагрузкой. Сначала должна стабильно заработать управляющая плоскость: reachability VTEP-адресов, MP-EBGP EVPN, передача маршрутной, MAC/IP-информации и EVPN Type 5 routes, а также программирование EVPN database. Только после этого можно перевозить первые серверы.
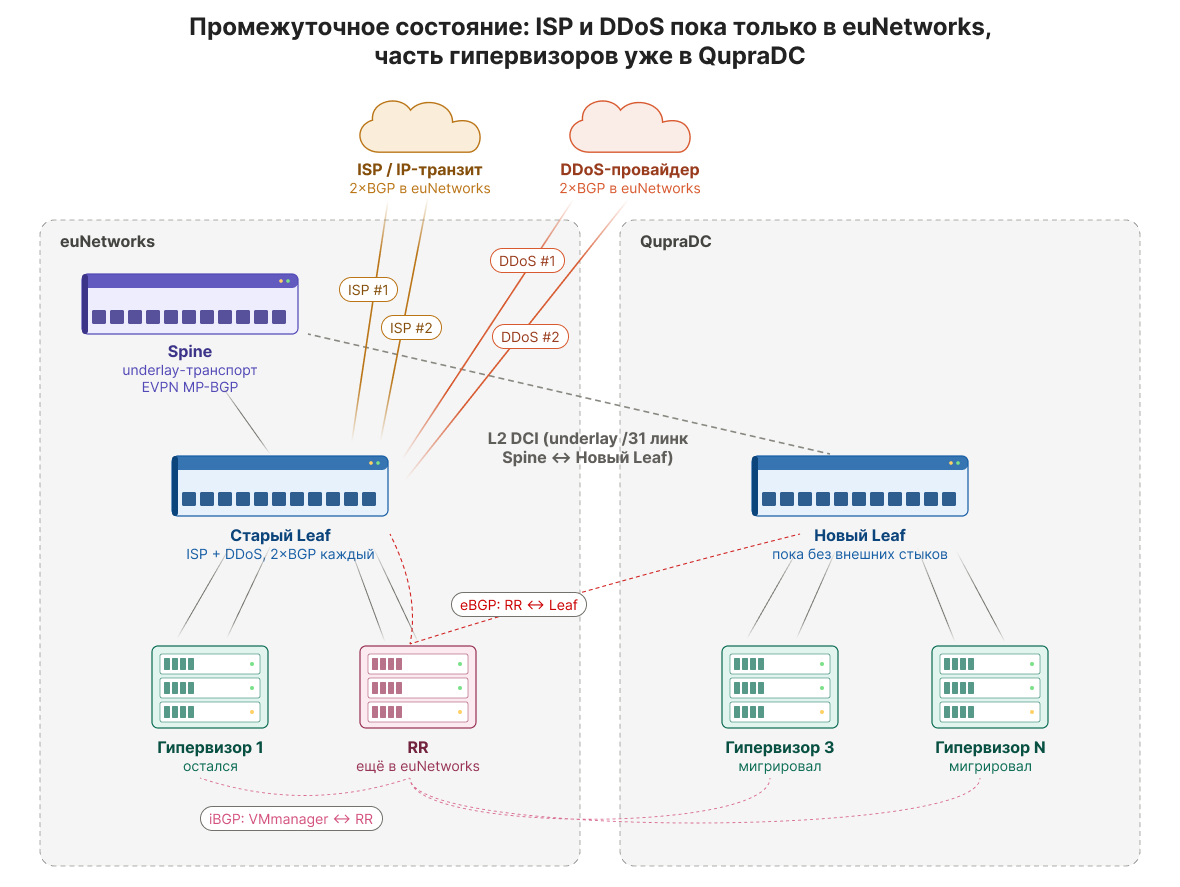
Когда новый Leaf стал частью фабрики, мы вывели один родительский сервер из клиентской нагрузки, физически перевезли его в QupraDC и подключили к новому Leaf.
Ключевая задача была сохранить модель сервиса и адресацию. Клиент не должен был почувствовать, что сервер теперь находится в другом дата-центре. Для этого мы перенесли нужные сервисные настройки на новый Leaf, проверили маршрутизацию до гипервизора, доступность виртуальных машин и прохождение трафика в обе стороны.
Получилась временная, но рабочая топология: часть серверов оставалась в euNetworks, часть уже находилась в QupraDC, старый Spine физически оставался в euNetworks, новый Leaf был в QupraDC, между площадками работал временный канал, а логически всё это оставалось одной фабрикой.
Маршрут до виртуальной машины на перенесённом сервере мог выглядеть так: интернет → старый Leaf → Spine → междатацентровый канал (DCI) → новый Leaf → гипервизор → VM.
Это не самый прямой путь, но для промежуточного состояния он был приемлем: задержка увеличилась на единицы миллисекунд, а для нашей VDS-нагрузки это не столь критично. Главное — сервис оставался доступен, а мы получали возможность переносить серверы партиями.
После успешного теста мы начали перевозить клиентскую нагрузку постепенно. Примерно половина серверов переехала в QupraDC и стала подключаться к новому Leaf, пока старая площадка продолжала обслуживать оставшуюся часть нагрузки.
В сетевых миграциях часто выигрывает не тот, кто делает всё сразу и одним переключением, а тот, кто умеет долго и безопасно жить в промежуточном состоянии. В нашем случае промежуточное состояние было понятным, наблюдаемым и контролируемым.
Перенос внешней связности и инфраструктуры
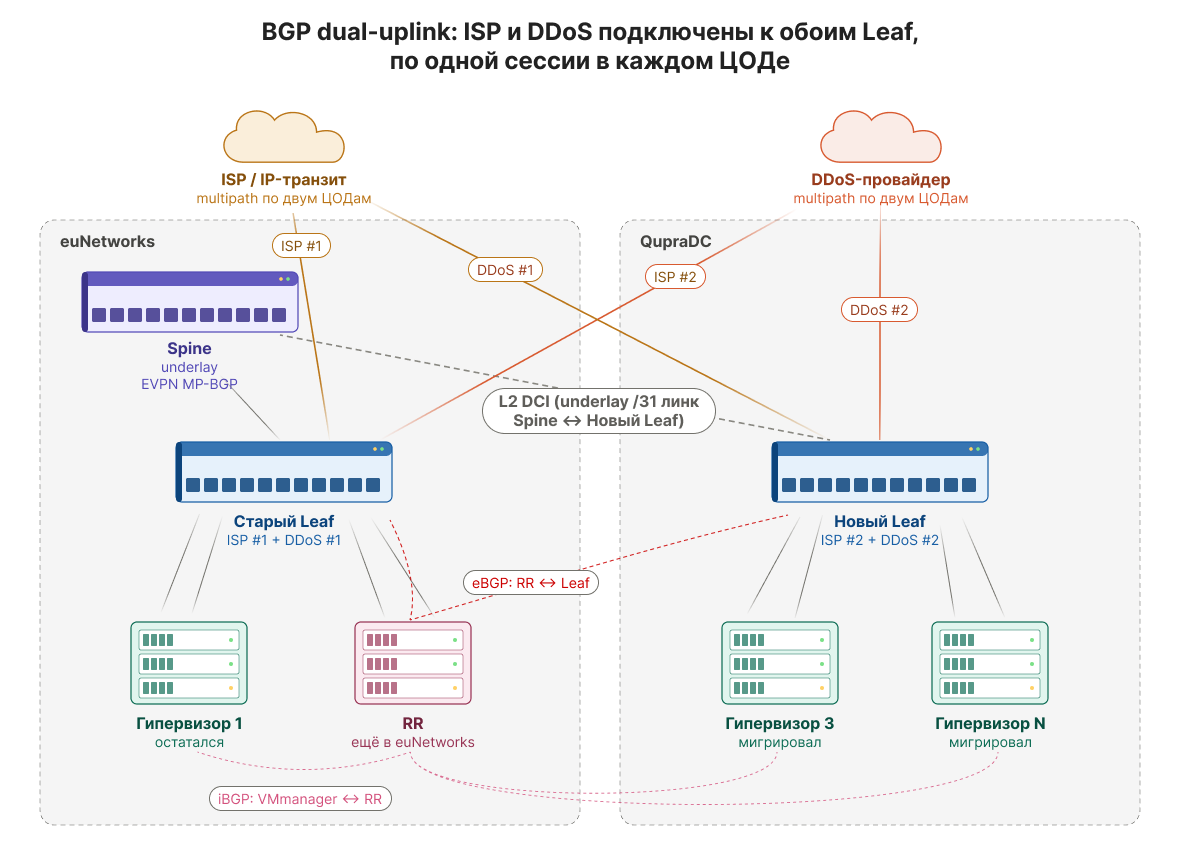
Когда в QupraDC оказалась примерно половина нагрузки, стало нерационально гонять весь внешний трафик через старую площадку. Серверы уже физически находились в новом дата-центре, но весь входящий и исходящий трафик всё ещё проходил через euNetworks, старый Leaf и временный междатацентровый канал.
К счастью, наш IP-транзитный оператор присутствовал и в QupraDC. Это позволило перенести одну из BGP-сессий с апстримом в новую локацию.
Здесь важно уточнить: в QupraDC мы не повторяли старую физику 2×10G. При переносе стыка в новую локацию сразу включили 100G-подключение на новом Leaf. Сервисно это выглядело как перенос одной из двух BGP-сессий вместе с её VLAN и point-to-point-адресацией /31, а физически — как переход новой площадки на 100G-аплинк.
После этого схема стала такой:
- одна BGP-сессия с апстримом осталась на старом Leaf в euNetworks через старый 10G-стык;
- вторая BGP-сессия с тем же апстримом поднялась на новом Leaf в QupraDC уже через 100G-подключение;
- оба Leaf продолжили участвовать в общей фабрике;
- внешний трафик начал распределяться между двумя площадками.
С нашей стороны появился второй выход к тому же оператору, но уже из новой локации и на новой физике. На каждом Leaf был свой локальный default-route от апстрима. Кроме того, default-route мог распространяться внутри overlay как EVPN Type 5 route, чтобы у фабрики сохранялась связность между частями временной схемы.
Оператор со своей стороны также использовал multipath и старался отдавать входящий трафик относительно симметрично. В результате мы получили два полезных эффекта.
Первый — разгрузили временный канал между дата-центрами. Трафик к серверам, которые уже находились в QupraDC, теперь мог приходить и уходить через аплинк в той же локации, а не обязательно через euNetworks.
Второй — получили первый практический элемент отказоустойчивости внешней связности. Да, это всё ещё была переходная схема, но уже не один-единственный внешний выход на всю распределённую между двумя ЦОД нагрузку.
DDoS-сервис переносился параллельно и по той же логике. DDoS-защитный провайдер тоже присутствовал в QupraDC, поэтому его подключение можно было перенести в новую локацию без изменения прежней модели. Стык с ним также состоял из двух BGP-сессий на двух разных юнитах, с разными VLAN-тегами на два разных Leaf. С точки зрения маршрутизации и фильтров всё осталось прежним: изменилось только физическое место подключения.
На этом этапе состояние выглядело так: часть серверов уже в QupraDC, часть ещё в euNetworks, внешний транзит, в том числе защищённый, работает на обеих площадках, в QupraDC уже используется 100G-стык к апстриму, оба Leaf участвуют в маршрутизации, миграция продолжается без остановки клиентского сервиса.
После переноса основной части клиентской нагрузки пришла очередь инфраструктурных виртуальных машин.
Перевозить route reflector нужно аккуратно. Если одновременно потерять оба, гипервизоры не смогут нормально распространять маршруты до виртуальных машин, и сеть начнёт терять информацию о достижимости префиксов VDS.
Поэтому мы переносили их по одному: проверяли текущее состояние BGP-сессий и набор отражаемых маршрутов, выводили один route reflector из активной эксплуатации, перевозили или перезапускали его в новой локации, дожидались восстановления BGP-сессий, проверяли, что маршруты от гипервизоров снова видны на Leaf, и только после этого переходили ко второму route reflector.
В сетевой инфраструктуре route reflector — это не просто очередная виртуальная машина. Это элемент управляющей плоскости, и обращаться с ним нужно соответствующе.
После переноса RR и оставшейся инфраструктуры мы перенесли вторую BGP-сессию с апстримом в QupraDC. Напомню, внешняя связность в новой локации уже строилась на 100G: целевая схема предусматривала два независимых 100G-стыка, по одному на каждый Leaf.
К этому моменту вся клиентская и инфраструктурная нагрузка находилась в QupraDC. Старая площадка фактически оставалась только местом, где ещё физически стояли старые Leaf и Spine, а также один инфраструктурный сервер виртуализации, который нужно было убрать последним.
Финальный переезд железа и приведение схемы к отказоустойчивому виду
Когда клиентской нагрузки в euNetworks уже не осталось, мы смогли перевезти старое сетевое оборудование и другие остатки инфраструктуры.
На этом этапе старый Leaf и Spine уже не были критичны для клиентского сервиса в прежнем смысле. Основная нагрузка находилась в QupraDC, внешние BGP-сессии были перенесены туда же, а временный междатацентровый канал продолжал поддерживать связность на время завершения работ.
Мы обесточили старый Leaf и Spine, демонтировали их, перевезли в QupraDC, смонтировали и включили обратно.
Ключевой момент: конфигурацию менять не пришлось. Адресация underlay сохранилась, роли устройств сохранились, BGP-сессии после включения поднялись заново. С точки зрения фабрики это выглядело почти так, как будто патчкорды стали короче, а устройства переехали физически ближе к остальной нагрузке.
После этого переезд можно было считать завершённым: клиентская нагрузка находилась в QupraDC, инфраструктурные сервисы находились там же, обе BGP-сессии к апстриму были подняты из QupraDC на 100G-стыках, стык с DDoS-провайдером был перенесён в QupraDC, старое сетевое оборудование было физически перевезено на новую площадку.
Временный междатацентровый канал, который был нужен только как инструмент миграции, мы незамедлительно разобрали.
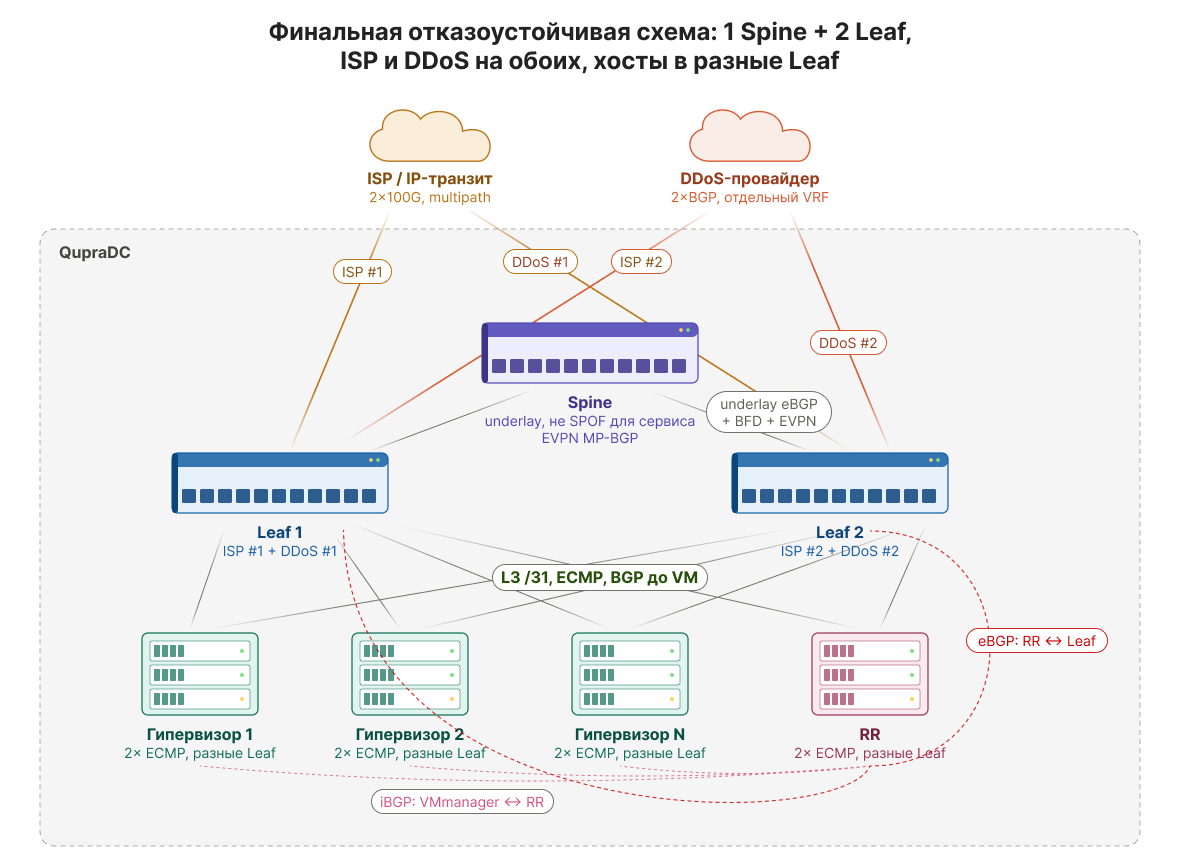
После переезда обнаружилась ожидаемая промежуточная ситуация: большая часть серверов по-прежнему была подключена только к одному Leaf — тому самому, который мы первым установили в QupraDC для миграции.
Для переезда этого было достаточно. Для нормальной эксплуатации — уже нет. Если этот Leaf потерять целиком, значительная часть серверов потеряет внешнюю связность.
Поэтому следующим этапом мы начали перекладывать серверные подключения так, чтобы каждый гипервизор имел по одному рабочему 10G-линку в каждый Leaf.
Здесь важно не спутать это с классическим LACP/ESI-LAG. Мы не собирали два физических линка в один L2-агрегат и не строили multihoming через LACP. Модель осталась той же, что и раньше. Разница только в том, что теперь эти два L3-пути идут не в один и тот же Leaf, а в два разных.
Так мы получили простую и понятную отказоустойчивость на уровне доступа. Если падает один линк, трафик остаётся на втором. Если падает один Leaf, для гипервизора это также выглядит как потеря одного из next-hop, а второй путь продолжает работать.
С точки зрения диагностики такая схема остаётся очень прозрачной. Нет необходимости выяснять, что именно произошло с LACP-состоянием, кто из пары коммутаторов считает себя активным и как отработала дополнительная сигнализация EVPN multihoming. В такой схеме DF election завязан на Type 4 — Ethernet Segment route, а aliasing и mass-withdraw — на Type 1 Ethernet A-D routes: per-ES и per-EVI. Это рабочая модель, но при отказах в ней появляется больше состояний, которые нужно уметь проверять и отлаживать.
В нашем случае есть интерфейс, есть connected route, есть next-hop, есть BGP-анонс VM-префикса. Каждый элемент можно проверить отдельно.
Важный нюанс — IPMI. У большинства серверов отдельный порт управления один. Его невозможно одновременно подключить в два Leaf без дополнительной схемы. Поэтому IPMI-порты мы распределили симметрично: часть серверов смотрит в первый Leaf, часть — во второй. При отказе одного Leaf мы теряем доступ к IPMI части серверов, но не ко всем сразу. Для этой задачи это приемлемый компромисс.
После финальной коммутации внешняя связность выглядела так:
- каждый Leaf имеет собственное 100G-подключение к апстриму;
- каждая BGP-сессия поднимается независимо;
- оба Leaf могут анонсировать одинаковый набор наших префиксов;
- отказ одного Leaf не убивает внешний канал целиком;
- отказ одного 100G-линка не оставляет площадку без транзита;
- входящий и исходящий трафик может распределяться через multipath.
Проверка отказов и один Spine как компромисс
После миграции и перекладки серверных линков мы провели серию отказных тестов. Это обязательный этап: отказоустойчивость нельзя считать существующей только потому, что она нарисована на схеме.
Проверяли несколько сценариев.
Первый сценарий — перезагрузка одного Leaf. При его недоступности серверы убирают недоступный next-hop из ECMP-группы и продолжают использовать второй путь, а внешний трафик перераспределяется через другой Leaf. Для клиентского сервиса это не должно выглядеть как полноценная авария: возможна кратковременная потеря отдельных пакетов в момент сходимости, но не длительный простой.
Второй сценарий — перезагрузка второго Leaf. Проверка симметричная, но её всё равно нужно проводить отдельно. В реальной эксплуатации часто выясняется, что «одинаковые» устройства отличаются мелочами: набором подключённых серверов, BGP-соседствами, политиками или физической коммутацией.
Третий сценарий — отключение серверных интерфейсов. При физическом обрыве всё работает быстро: сетевой стек гипервизора видит carrier loss, маршрут через этот интерфейс перестаёт использоваться, и трафик остаётся на другом ECMP-пути. В этом случае не нужно ждать истечения BGP holdtime, потому что проблема видна на уровне интерфейса.
BGP-таймеры важны для других случаев: например, если BGP-демон на соседней стороне завис, а физический линк при этом остался поднятым. Для таких сценариев худшее время обнаружения зависит уже от настроек BGP/BFD.
Четвёртый сценарий — отключение линков к апстриму. Когда внешний интерфейс становится недоступен, из таблицы маршрутизации уходят связанные с ним connected routes, BGP-сессия к оператору теряет транспортную связность и сбрасывается. После этого маршруты через этот стык перестают использоваться, а трафик перераспределяется через оставшийся внешний путь.
Пятый сценарий — проверка DDoS-сегмента. Здесь всё плюс/минус аналогично, проверяется отказ стыка к DDoS-провайдеру.
Для быстрой детекции отказов в самой IP-фабрике используется BFD. Благодаря BFD мы не ждём длинных BGP-таймаутов: если сосед перестаёт отвечать, путь быстрее признаётся нерабочим, и трафик перераспределяется по другим next-hop'ам в рамках ECMP-группы
В итоге мы получили то, что хотели: базовую отказоустойчивость на уровне серверных подключений, разнесение внешнего транзита по двум Leaf и кратный рост внешней полосы.
Внимательный читатель заметит: после всех улучшений Spine всё ещё один. Значит ли это, что он остаётся single point of failure?
Формально — да, если смотреть на фабрику как на каноническую Spine–Leaf-архитектуру. В идеальном мире Spine тоже должно быть минимум два. Тогда отказ любого одного устройства на любом уровне не приводит к потере связности фабрики.
Но в нашей текущей топологии отказ Spine не равен полной остановке клиентского сервиса.
Причина в том, что два Leaf после переезда не завязаны на Spine как на единственную точку выхода наружу или единственный шлюз для серверов:
- каждый Leaf имеет собственную BGP-сессию к апстриму;
- каждый Leaf получает свой локальный default-route от оператора;
- оба Leaf анонсируют одинаковый набор наших внешних префиксов;
- гипервизоры подключены к обоим Leaf отдельными L3-связями;
- маршруты до виртуальных машин распространяются через BGP;
- если нет BGP-сигнализации до конкретного VM-префикса, сеть не считает этот путь рабочим.
То есть ситуация «трафик пришёл на Leaf, а дальше его некуда доставить» в нормальном состоянии не должна возникать. Если конкретный хостовой линк падает, соответствующий путь исчезает. Если Leaf теряет внешнюю связность, трафик может уйти через второй Leaf, у которого есть свой апстрим.
При этом один Spine всё равно остаётся техническим компромиссом. Он приемлем для текущего масштаба и текущей топологии, но его не нужно выдавать за идеальную архитектуру. Когда появится следующий Leaf или вырастут требования к отказоустойчивости fabric-underlay, я буду предлагать вернуться к вопросу второго Spine.
В какой-то момент один Spine перестаёт быть разумным компромиссом и становится техническим долгом. Тогда фабрику нужно будет довести до более канонической Clos-топологии с избыточностью на каждом уровне.
Итоги второй части и что дальше
В результате мы не просто переехали из euNetworks в QupraDC. Мы использовали вынужденную миграцию как повод улучшить архитектуру.
До переезда схема была минимальной: один Leaf, один Spine, вся нагрузка в одной физической локации, внешний аплинк 2×10G, Leaf одновременно выполняет роли server leaf и border leaf, отказоустойчивость на уровне фабрики минимальная.
После переезда схема стала заметно сильнее: два Leaf в новой локации, серверные подключения разнесены по двум Leaf, внешние BGP-сессии к апстриму подняты с разных Leaf, внешняя физическая связность в QupraDC сразу собрана на 2×100G, DDoS-сервис перенесён в QupraDC, его подключения также разнесены по двум Leaf.
Главное — что мы не меняли архитектурную модель в процессе переезда. Новый Leaf встроился в уже существующую фабрику, серверы продолжили работать в routed-модели, VM-префиксы продолжили распространяться через BGP, а EVPN-VXLAN остался общей управляющей и сервисной основой площадки.
Именно поэтому миграция была управляемой. Мы не превращали переезд в одну большую рискованную операцию, в которую пришлось бы уместить все этапы, а долго жили в промежуточных состояниях: сначала один Leaf в старой локации, потом второй Leaf в новой, потом часть серверов там и часть здесь, потом BGP-сессии с апстримом на двух площадках, потом вся нагрузка в QupraDC, потом физический переезд старого оборудования.
Это, пожалуй, главный вывод всей второй части: хорошая миграция — это не момент, когда кто-то нажал большую красную кнопку и надеется, что всё взлетит. Хорошая миграция — это цепочка состояний, каждое из которых можно наблюдать, проверить и при необходимости удерживать столько, сколько нужно.
Второй вывод — временные схемы нужно проектировать так же аккуратно, как постоянные. Даже если канал между ЦОД нужен на несколько недель, у него должны быть понятная роль, понятные ограничения, наблюдаемость и критерии отключения. Иначе временная миграционная конструкция легко превращается в часть продакшена, о которой все забыли.
Третий вывод — отказоустойчивость иногда появляется не как отдельный большой проект, а как правильно использованная возможность. Нам всё равно понадобился второй Leaf для переезда. Можно было воспринимать его как вынужденную покупку, а можно было встроить в будущую целевую схему. Мы выбрали второе и получили базовую устойчивость на уровне доступа.
Следующий необходимый этап — второй независимый апстрим. Две BGP-сессии к одному оператору дают резервирование на уровне наших стыков, Leaf-коммутаторов и физических линков. Но они не защищают от аварии внутри сети самого ISP: проблем на магистрали, ошибок маршрутизации, отказов route-server'ов провайдера или неудачных изменений в его политике. В такой ситуации уже не так важно, что с нашей стороны подняты две сессии: если проблема находится внутри операторской сети, оба стыка могут деградировать одновременно.
Поэтому нужен хотя бы полуавтоматический резерв через другого оператора. На первом этапе это не обязательно должна быть полноценная схема с балансировкой. Достаточно иметь резервный default-route от второго апстрима, менее приоритетный через BGP policy: основной default используется через текущего оператора, а при его отказе трафик автоматически уходит через резервный путь.
Но здесь есть важный нюанс: такое переключение сработает само только если BGP-сессия действительно погасла и маршрут был отозван. Аварии внутри операторской сети не всегда выглядят именно так. Сессия может оставаться поднятой, default-route — присутствовать в RIB, а качество связности при этом уже стать неприемлемым. В таких случаях нужны мониторинг, понятные процедуры переключения и рабочий OOBM-доступ, чтобы можно было быстро вмешаться и поменять политику маршрутизации не через сломанную сеть.
И вполне вероятно, что в какой-то момент появится смысл вынести внешнюю маршрутизацию на полноценную пару border-router'ов операторского класса с full view. Но это уже следующий этап для нас: сотни гигабит трафика, несколько апстримов, более сложный traffic engineering и отдельные требования к пиринговой политике.
Ещё один очевидный шаг — второй Spine. Пока один Spine остаётся приемлемым компромиссом для текущей топологии, но при дальнейшем росте Leaf-коммутаторов и требований к отказоустойчивости его нужно будет добавить. Тогда фабрика станет ближе к канонической Clos-топологии: несколько Leaf, несколько Spine и отсутствие единственной точки отказа не только в underlay, но и в overlay control plane. В нашей схеме Spine участвует в распространении EVPN-информации, поэтому его резервирование важно не только для транспортного уровня, но и для управляющей плоскости overlay.
Главный результат уже достигнут: мы ушли от минимальной схемы с одним Leaf, перевезли площадку онлайн, сохранили клиентскую адресацию, увеличили внешнюю полосу и получили более устойчивую архитектуру. А всё началось с простого требования: построить небольшую и недорогую площадку с заделом на будущее.
Автор статьи: Рене, сетевой инженер FirstVDS
firstvds.ru
0 комментариев
Вставка изображения
Оставить комментарий