Контент и редакционные материалы Google Cloud
Контент и редакционные материалы Google Cloud
В эпоху искусственного интеллекта, когда один год может казаться десятым, вас можно простить за то, что вы забыли о событиях прошлого месяца, не говоря уже о событиях января. Чтобы освежить вашу память, мы проанализировали данные о количестве читателей главных новостей о продуктах и компаниях за 2025 год. И поскольку мы публикуем много отличных материалов, отражающих лидерство в отрасли, и историй успеха клиентов, мы также использовали эти данные. Вкратце: самые популярные статьи в основном совпадали с нашими крупнейшими анонсами. Но не всегда — в этом году в списке было немало неожиданных хитов. Читайте дальше, чтобы вспомнить этот грандиозный год и, возможно, открыть для себя несколько жемчужин, которые вы могли пропустить.
cloud.google.com/blog/products/gcp/top-google-cloud-blogs-2025/
Январь
2025 год начался успешно с важных новинок в области виртуальных машин, базовых инструментов для ИИ, а также инструментов как для Kubernetes, так и для специалистов по работе с данными. Мы также запустили серию статей « Как это делает Google », посвященную внутренним системам и инженерным принципам, лежащим в основе современного конвейера обнаружения угроз. Мы показали разработчикам, как начать работу с JAX, и сделали прогнозы по развитию ИИ на предстоящий год. Читатели с интересом узнали о том, как L'Oréal создала свою платформу MLOps, и о новаторской работе Deutsche Börse в области облачной финансовой торговли.
Новости о продуктах
Упростите работу разработчиков с Kubernetes с помощью KRO.
Blackwell уже здесь — новые виртуальные машины A4 на базе NVIDIA B200 теперь доступны в режиме предварительного просмотра.
Представляем Vertex AI RAG Engine: масштабируйте свой конвейер Vertex AI RAG с уверенностью.
Представляем BigQuery metastore — унифицированный сервис метаданных с поддержкой Apache Iceberg.
C4A, первый процессор Google Axion, теперь доступен в продаже с SSD-накопителем Titanium.
Лидерство в интеллектуальной сфере:
- Как это делает Google: создание высококачественной, масштабируемой и современной системы обнаружения угроз
- 2025 год и следующие главы в истории искусственного интеллекта
Истории клиентов
- Как акселератор L'Oréal Tech Accelerator создал свою комплексную платформу MLOps
- Торговля в облаке: уроки облачной торговой платформы Deutsche Börse Group
Февраль
Существуют продукты на основе ИИ, а есть продукты, усовершенствованные с помощью ИИ. В этом месяце лидер продаж, Gen AI Toolbox for Databases, относится ко второй категории. В этом месяце читатели также серьезно отнеслись к обучению: блоги о повышении квалификации, ресурсах и сертификации возглавили рейтинги. Результаты нашего партнерства с Anthropic попали в наш список самых читаемых материалов, а руководители инженерных подразделений подробно рассказали о масштабных усилиях Google по оптимизации энергопотребления систем ИИ. Руководители с удовольствием прочитали статью о том, как агенты будут раскрывать информацию в неструктурированных данных (которые составляют 90% информационных активов предприятий), и ознакомились с отрезвляющим отчетом об ИИ и киберпреступности. Во время Mobile World Congress мы увидели значительный интерес к нашей работе с лидерами телекоммуникационной отрасли, такими как Vodafone Italy и Amdocs.
Новости о продукции и компании:
- Объявляем о начале публичного бета-тестирования Gen AI Toolbox для баз данных.
- Получите сертификат Google Cloud в 2025 году — и узнайте, почему последние исследования говорят о важности этого.
- Узнайте о карьерных возможностях и квалификационных требованиях в Google Cloud в нашем новом разделе Career Dreamer.
- Анонсируем Claude 3.7 Sonnet, первую гибридную модель логического мышления от Anthropic, доступную на платформе Vertex AI.
Лидерство мнений
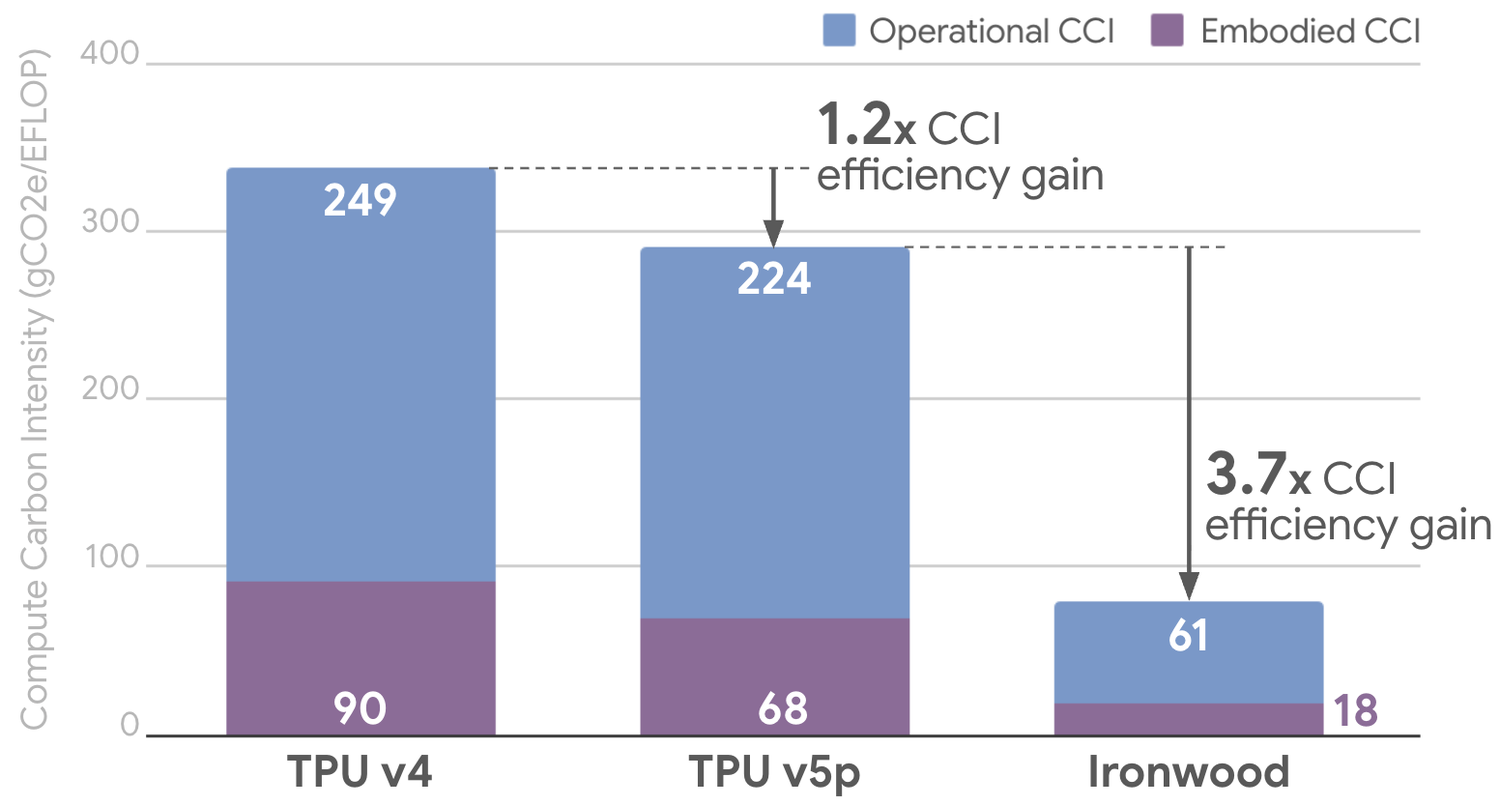
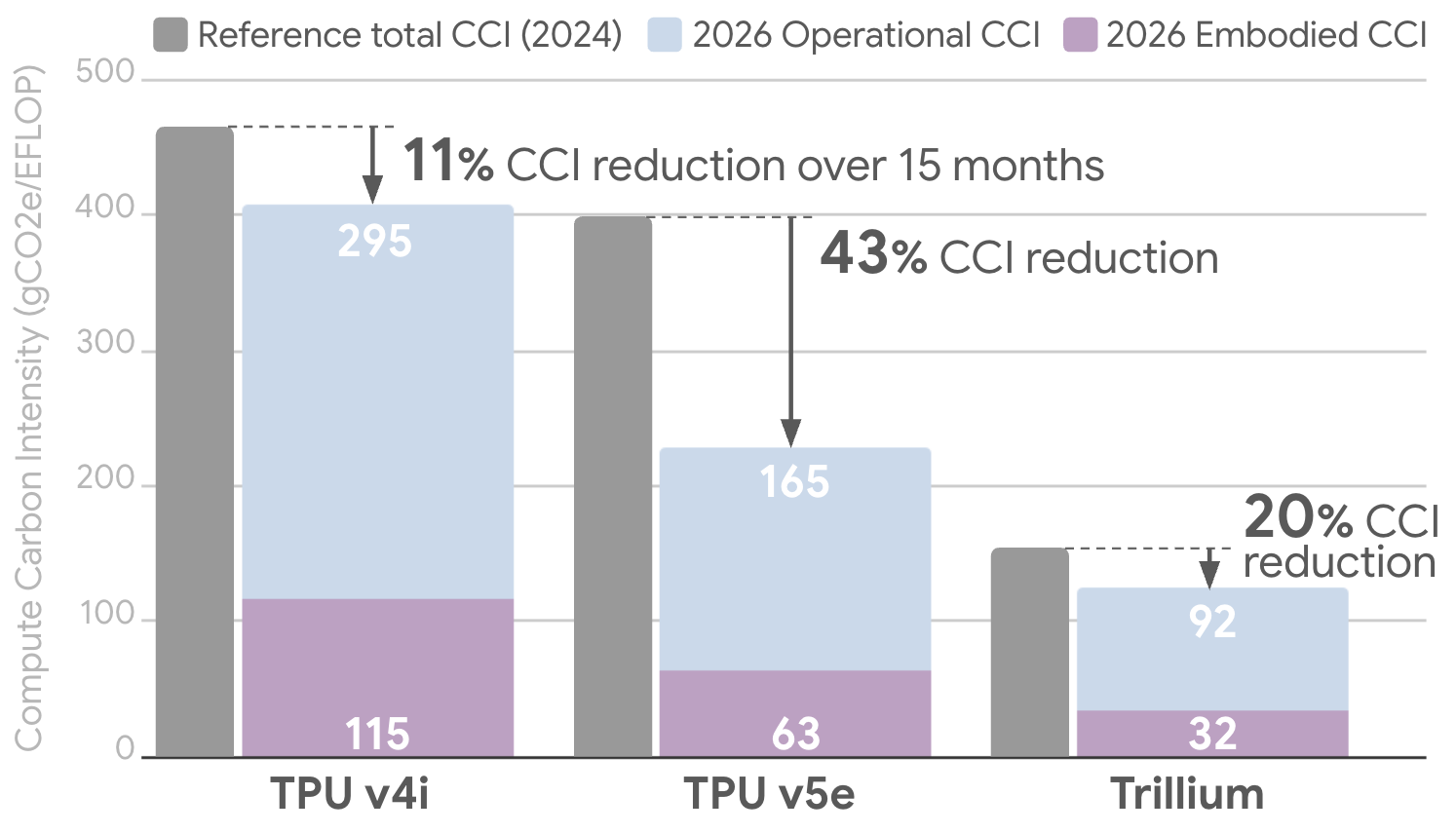
- Разработка устойчивого ИИ: подробный анализ эффективности TPU и выбросов на протяжении всего жизненного цикла.
- От скрытых данных к ценным выводам: как агенты искусственного интеллекта упрощают работу с данными.
- Новые отчеты об искусственном интеллекте и киберпреступности подчеркивают необходимость внедрения передовых методов обеспечения безопасности.
Истории клиентов
- Преобразование данных: как Vodafone Italy модернизировала свою архитектуру данных в облаке.
- Оптимизация сети с помощью ИИ: раскрытие потенциала 5G с Amdocs.
 Март
Март
Когда мы объявили о нашем намерении приобрести стартап в сфере кибербезопасности Wiz, это была крупнейшая сделка Google за всю историю и крупнейшая технологическая сделка года. Мы развили этот успех в области безопасности, запустив AI Protection. Мы также расширили свое присутствие в странах Северной Европы, открыв новый регион, и анонсировали открытую модель Gemma 3 на платформе Vertex AI. Тем временем мы объяснили угрозу, которую представляют для работодателей северокорейские IT-специалисты, показали читателям внутреннюю структуру файловой системы Colossus и вспомнили о том, чему мы научились за 25 лет работы в сфере создания центров обработки данных. Читателей заинтересовал подход Levi к данным и их интеграция в будущие проекты в области ИИ, а в честь фестиваля игр GDC наши партнеры по ИИ поделились новыми взглядами на «живые игры».
Новости о продукции и компании
- Google + Wiz: Укрепление безопасности мультиоблачных решений
- Представляем AI Protection: безопасность для эпохи ИИ.
- Эй, Свериге! Google Cloud запускает новый регион в Швеции
- Анонс Gemma 3 на Vertex AI.
Лидерство мнений
- Главная внутренняя угроза: северокорейские IT-специалисты.
- «Колосс под капотом»: как мы обеспечиваем производительность SSD по ценам HDD.
- 3 ключевых урока, извлеченных из 25 лет работы с крупномасштабными вычислительными системами для складских помещений.
Истории клиентов
- Безупречная стратегия работы с данными Levi's: как специально разработанный ИИ предотвращает «загонение» иконы в рамки.
- Кооперативный режим: Новые партнеры определяют будущее игр с помощью ИИ.
Апрель
В апреле состоялась Google Cloud Next, наша флагманская ежегодная конференция. От Firebase Studio, Ironwood TPUs и Google Agentspace до Vertex AI, Cloud WAN и Gemini 2.5 — сложно ограничиться лишь несколькими историями, было так много потрясающих событий (полный список можно найти в обзоре мероприятия ). Тем временем наша команда системных разработчиков обсуждала инновации для контроля теплового режима инфраструктуры центров обработки данных. А на конференции RSA мы представили наше видение агентного центра управления безопасностью будущего. Что касается клиентов, мы рассказали о стартапах, сыгравших главную роль на Next, и заглянули за кулисы «Волшебника страны Оз» в Sphere.
Новости о продукции и компании
- Представляем Firebase Studio и инструменты разработки для агентов, позволяющие создавать проекты с помощью Gemini.
- Представляем TPU-процессоры Ironwood и новые инновации в области гиперкомпьютеров с искусственным интеллектом.
- Vertex AI предлагает новые способы создания и управления многоагентными системами.
- Масштабируйте корпоративный поиск и внедрение агентов с помощью Google Agentspace.
- Облачная WAN: объедините ваше глобальное предприятие с помощью сети, созданной для эпохи искусственного интеллекта.
- Gemini 2.5 расширяет возможности логического мышления для корпоративных сценариев использования.
- Начало применения агентного ИИ в операциях по обеспечению безопасности на конференции RSAC 2025
Лидерство мнений
- Инфраструктура для ИИ находится на пике популярности. Новые системы распределения электроэнергии и жидкостного охлаждения могут этому способствовать.
- 3 новых способа использования ИИ в качестве помощника в обеспечении безопасности
Истории клиентов
- Глобальные стартапы строят будущее искусственного интеллекта на платформе Google Cloud.
- Магия искусственного интеллекта, лежащая в основе предстоящего проекта Sphere «Волшебник страны Оз».
Май
Учебный год подходил к концу, но читатели снова включились в обучение, чтобы получить сертификаты лидеров в области генеративного ИИ. Вы также были в восторге от новых моделей ИИ для работы с медиаконтентом в Vertex AI, доступности Claude Opus 4 и Claude Sonnet 4 от Anthropic. Мы также узнали, что вы очень рады использовать ИИ для генерации SQL-кода и использовать Cloud Run в качестве платформы для ваших приложений ИИ. Мы описали шаги по построению четко определенной стратегии работы с данными и показали правительствам, как ИИ может реально улучшить их уровень безопасности. А что касается клиентов, мы запустили наши обзоры «Крутые вещи, созданные клиентами» и опубликовали материалы о Формуле E и MLB.
Google Cloud объявляет о первой в своем роде сертификации лидеров в области генеративного искусственного интеллекта.
Расширение возможностей Vertex AI за счет следующей волны генеративных моделей искусственного интеллекта для работы с медиаконтентом.
Анонс Claude Opus 4 и Claude Sonnet 4 от Anthropic на Vertex AI.
Лидерство мнений
- Как научить ИИ писать качественные SQL-запросы: объяснение методов преобразования текста в SQL.
- Развертывание ИИ стало проще: развертывание в Cloud Run из AI Studio или любого клиента MCP.
- Разработка стратегии работы с данными для эпохи искусственного интеллекта.
- Как правительства могут использовать ИИ для улучшения обнаружения угроз и снижения затрат
Истории клиентов
- Крутые вещи, созданные клиентами: майский выпуск
- Расширяя границы возможностей электромобильности: Mountain Recharge в Формуле E
- Использование ИИ для создания по-настоящему персонализированных видеороликов с лучшими моментами матчей MLB: как сервис MLB My Daily Story создает такие яркие моменты.
Июнь
До этого момента перспективы генеративного ИИ в основном были связаны с текстом и кодом. Запуск Veo 3 изменил все. Разработчики, создающие и развертывающие приложения ИИ, восприняли доступность графических процессоров в Cloud Run как большую удачу, и мы продолжили нашу неуклонную работу над инновациями Gemini с помощью 2.5 Flash и Flash-Lite. Мы также поделились своими мыслями о защите агентов ИИ. А чтобы узнать, как на самом деле создавать этих агентов, читатели обратились к статьям о Box, британской компании по недвижимости Schroders и французском люксовом конгломерате LVMH (владельце Louis Vuitton, Channel, Sephora и других).
Вы мечтаете об этом, Veo воплощает это в жизнь: Veo 3 теперь доступен для всех в режиме публичного предварительного просмотра на Vertex AI.
Технология Cloud Run GPUs, теперь доступная для всех, упрощает выполнение задач искусственного интеллекта.
Успех Gemini продолжается с выпуском 2.5 Flash-Lite и появлением в продаже версий 2.5 Flash и Pro на Vertex AI.
Лидерство мнений
- Спросите OCTO: Как разобраться в работе агентов искусственного интеллекта
- Мнение руководителей служб информационной безопасности облачных сервисов: как Google обеспечивает безопасность агентов искусственного интеллекта.
Истории клиентов
- Секрет интеллектуального анализа документов: Box создает улучшенные агенты извлечения данных с использованием фреймворка A2A.
- Как компания Schroders создала своего многоагентного помощника для финансового анализа и исследований
- Внутри идеально ухоженной базы данных LVMH, где зарождаются роскошные агенты искусственного интеллекта.
 Июль
Июль
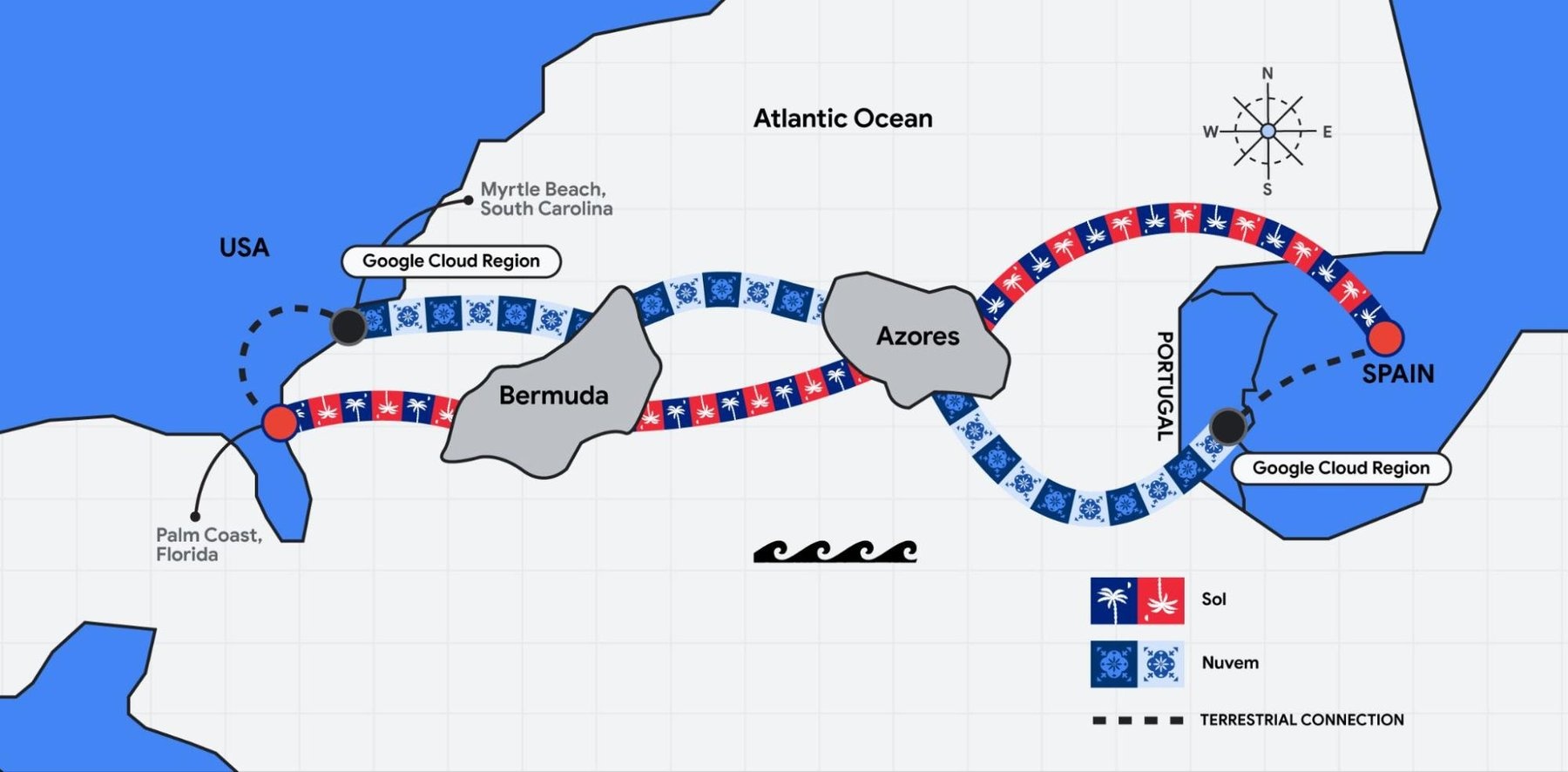
Читатели отвлеклись от темы ИИ, чтобы почитать о сетевой инфраструктуре — а точнее, о новом трансатлантическом кабеле Sol. Затем они вернулись к ИИ: новые модели генерации видео в Vertex; важнейший компонент для создания агентов с сохранением состояния и учетом контекста; и новый набор инструментов для подключения данных BigQuery к средам Agent Development Kit (ADK) и Multi-Cloud Protocol (MCP). Разработчики приветствовали интеграцию Cloud Run и Docker Compose, а руководители компаний с удовольствием ознакомились со списком практических применений агентов ИИ в реальном мире.
В этом месяце мы вернулись к основам безопасности, изучив сохранение некоторых проблем безопасности облачных сервисов. А затем снова вернулись к искусственному интеллекту, представив нашего агента Big Sleep. Читателей также заинтересовало, как ИИ упрощает ведение документации для медсестер в HCA Healthcare, инициативы Ulta Beauty по хранению данных и ведению документации с помощью мобильных устройств, а также переход SmarterX с Snowflake на BigQuery.
Повышение отказоустойчивости сети с помощью трансатлантического кабеля Sol.
Veo 3 и Veo 3 Fast теперь общедоступны на Vertex AI.
Анонсируем доступность банка памяти Vertex AI Agent Engine Memory Bank для всех пользователей в режиме предварительного просмотра.
BigQuery и ADK и MCP: ускорьте разработку агентов с помощью нового набора инструментов от BigQuery.
От локального сервера до запуска: упростите развертывание приложений ИИ с помощью Cloud Run и Docker Compose.
Лидерство мнений
- Безопасное облако. Небезопасное использование. (И что с этим можно сделать)
- Наш агент из компании Big Sleep совершил большой рывок.
Истории клиентов
- Как медсестры определяют будущее искусственного интеллекта в крупнейшей сети больниц Америки, HCA Healthcare.
- Ulta Beauty переосмысливает розничную торговлю косметикой с помощью BigQuery.
- Переход SmarterX с Snowflake на BigQuery ускорил создание моделей и сократил затраты вдвое.
Август
Искусственный интеллект — это ресурсоемкий и энергоемкий процесс; в новом техническом документе мы опубликовали конкретные данные о потреблении энергии нашей инфраструктурой ИИ. Затем все пришли в восторг от Gemini 2.5 Flash Image на Vertex AI, и разработчики, имея в своем распоряжении множество технических чертежей, приступили к работе над своими проектами в области ИИ. Летнее затишье не помешало нашим экспертам по безопасности заняться серьезной проблемой кибермошенничества. Мы также внимательно изучили конкретные инструменты, используемые агентами в Wells Fargo, и то, как Keeta обрабатывает 11 миллионов блокчейн-транзакций в секунду с помощью Spanner.
Сколько энергии потребляет искусственный интеллект Google? Мы произвели расчеты.
Создание визуализаций нового поколения с помощью Gemini 2.5 Flash Image (он же nano-banana) на платформе Vertex AI.
Более 101 варианта использования ИИ нового поколения с техническими схемами.
Лидерство мнений
- В отчете New Threat Horizons подробно описываются меняющиеся риски и способы защиты от них.
- Как руководители служб информационной безопасности и советы директоров могут помочь в борьбе с мошенничеством, совершаемым с использованием киберпреступлений.
- Как прогнозирование погоды на основе искусственного интеллекта может изменить работу энергетических компаний
Истории клиентов
- Как Wells Fargo использует Google Cloud AI для расширения возможностей своих сотрудников с помощью инструментов для управления персоналом
- Как Киита обрабатывает 11 миллионов финансовых транзакций в секунду в блокчейне с помощью Spanner
Сентябрь
Искусственный интеллект — это крутая технология, но как её монетизировать? Один из ответов — протокол агентских платежей (AP2). Разработчики и специалисты по обработке данных, готовящиеся к внедрению ИИ, активно изучали блоги о новых предложениях в области облачных вычислений, отчете DORA за 2025 год и новых обучающих программах. Руководители компаний внимательно изучали наши идеи по построению агентской стратегии работы с данными и делали заметки о лучших способах запуска использования ИИ. И поскольку эра ИИ затрагивает всех, включая руководителей предприятий, мы объяснили, что значит быть «двуязычным» в области ИИ и безопасности. Затем на форуме Google AI Builders Forum стартапы рассказали, как ИИ, инфраструктура и сервисы Google поддерживают их рост. Не остались в стороне и такие предприятия, как Target и Mr. Cooper, которые также продемонстрировали свои возможности в области ИИ.
Развитие коммерции с использованием искусственного интеллекта с помощью нового протокола агентских платежей (AP2)
Новый специалист по анализу данных: от аналитика к архитектору агентов.
Представляем доклад DORA за 2025 год: Состояние разработки программного обеспечения с использованием искусственного интеллекта.
Возвращаемся в школу ИИ: новый курс обучения от Google Cloud, который обеспечит вам навыки работы с ИИ в будущем.
Лидерство мнений
- Создание более совершенных платформ данных для ИИ и не только.
- Для получения конкурентного преимущества советам директоров следует быть «двуязычными» в области ИИ и безопасности.
- Руководство для руководителей по пяти основным вопросам искусственного интеллекта
Истории клиентов
- Как технологический стек Google Cloud в области искусственного интеллекта помогает современным стартапам
- От запроса до корзины: подробности обновления поисковой строки Target с помощью AlloyDB AI.
- Как г-н Купер собрал «команду» агентов искусственного интеллекта для решения сложных вопросов, связанных с ипотекой.
Октябрь
Добро пожаловать в эру Gemini Enterprise, которая предоставляет крупным организациям улучшенную безопасность, контроль данных и расширенные возможности агентов. Чтобы помочь вам подготовиться, мы перезапустили ряд улучшений нашей обучающей платформы и добавили новые программы по коммерции и безопасности. Пока разработчики изучали тонкости подсказок Veo, мы обсуждали обеспечение безопасности цепочки поставок ИИ, создание агентов ИИ для кибербезопасности и обороны, а также новое видение моделирования экономических угроз. Мы сотрудничали с PayPal, чтобы обеспечить коммерцию в чатах с ИИ, немецкий Институт Планка показал, как ИИ может помочь в обмене глубокими научными знаниями, а DZ Bank разработал новаторские способы повышения надежности финансов на основе блокчейна.
Представляем Gemini Enterprise
Google Skills: Ваш новый дом для облачного обучения
Обеспечение безопасной работы веб-платформы с помощью reCAPTCHA
Партнеры, обеспечивающие работу агентской экосистемы Gemini Enterprise.
Лидерство мнений
- Полное руководство по подсказкам для Veo 3.1
- Как обеспечить безопасность цепочки поставок ИИ
- Как это делает Google: создание агентов искусственного интеллекта для кибербезопасности и защиты.
Истории клиентов
- Представляем решение для автоматизированной электронной коммерции от PayPal и Google Cloud для продавцов.
- Как Институт Макса Планка делится экспертными знаниями с помощью мультимодальных агентов
- Оракулы DeFi: как DZ Bank создает надежные потоки данных для децентрализованных приложений
Ноябрь
Будь то Gemini 3, Nana Banana Pro или наши TPU Ironwood седьмого поколения, в этом месяце мы предоставили корпоративным клиентам доступ ко всем нашим новейшим и лучшим технологиям в области искусственного интеллекта. Мы также подробно рассказали о том, как создали крупнейший в истории кластер Kubernetes, насчитывающий 130 000 узлов, и объявили о новом сотрудничестве с AWS для улучшения связи между облаками.
Тем временем мы обновили наши выводы о злонамеренном использовании ИИ со стороны злоумышленников и о рентабельности инвестиций в ИИ для обеспечения безопасности, а руководители компаний высоко оценили нашу статью о программировании атмосферы. Затем, как раз к праздникам, мы рассмотрели, как Mattel использует инструменты ИИ для обновления своих игрушек, а Waze показал, как компания использует Memorystore для поддержания потока трафика в праздничный сезон.
Внедрение Gemini 3 в корпоративную среду
Как это делает Google: создание крупнейшего из известных кластеров Kubernetes, насчитывающего 130 000 узлов.
Представляем Nano Banana Pro для всех строителей и предприятий.
Анонсируем общедоступность Ironwood TPU и новых виртуальных машин Axion для развития вычислительной техники.
AWS и Google Cloud сотрудничают для упрощения работы в многооблачных сетях.
Лидерство мнений
- Последние достижения в использовании инструментов искусственного интеллекта злоумышленниками
- За кулисами ажиотажа: анализ новых данных о рентабельности инвестиций в ИИ в сфере безопасности.
- Как кодирование атмосферы может помочь лидерам действовать быстрее
Истории клиентов
- Революционное решение от Mattel: как искусственный интеллект превращает отзывы клиентов в обновления продуктов в режиме реального времени.
- Waze обеспечивает бесперебойную работу дорожной сети благодаря более чем 1 миллиону считываний данных в реальном времени в секунду из Memorystore.
 Декабрь
Декабрь
Год подходит к концу, но нам еще многое предстоит рассказать. Первые результаты показывают, что вас интересовали способы устранения уязвимости React2Shell, поддержка MCP во всех сервисах Google, а также запуск раннего доступа к AlphaEvolve. И не будем забывать о Gemini 3 Flash, который привлекает внимание своей высокоуровневой логикой, потрясающей скоростью и гибким профилем стоимости.
Что всё это значит для вас и вашего будущего? Важно понимать контекст этих технологических разработок, особенно в области ИИ. Например, команда DORA подготовила руководство о том, как высокоэффективные команды, работающие с платформами, могут интегрировать возможности ИИ в свои рабочие процессы, мы обсудили, как выглядит рабочая сила, готовая к использованию ИИ, а наши коллеги из Управления директора по информационной безопасности опубликовали свои прогнозы по кибербезопасности на 2026 год. Более того (защитник), вы могли бы поступить, как Стефен Карри из «Голден Стэйт Уорриорз», и обратиться к Gemini для анализа своей игры, чтобы подготовиться к предстоящему году. Мы будем следить за тем, как Стеф справится с советами Gemini в Рождество.
Ответ на уязвимость React2Shell (CVE-2025-55182): Обеспечьте безопасность ваших рабочих нагрузок React и Next.js.
Объявляем о поддержке протокола контекста модели (MCP) для сервисов Google.
AlphaEvolve на Google Cloud: ИИ для обнаружения и оптимизации агентов.
Представляем Gemini 3 Flash: интеллект и скорость для предприятий.
Лидерство мнений
- От внедрения к результатам: применение модели возможностей искусственного интеллекта DORA на практике.
- Является ли владение навыками работы с ИИ необходимым компонентом или результатом подготовки квалифицированных кадров для этой области?
- Наш прогноз по кибербезопасности на 2026 год.
Истории клиентов
- Что Стефен Карри узнал о своей игре от специально созданного агента Gemini