Что в имени? Понимание "края" сети Google Cloud

Google занимается созданием инфраструктуры, которая позволяет модернизировать и запускать рабочие нагрузки, а также подключаться к большему количеству пользователей, независимо от того, где они находятся. Частью этой инфраструктуры является наша обширная глобальная сеть, которая обеспечивает лучшую в своем классе возможность подключения для клиентов Google Cloud, и нашу пограничную сеть, которая позволяет вам подключаться к интернет-провайдерам и конечным клиентам.
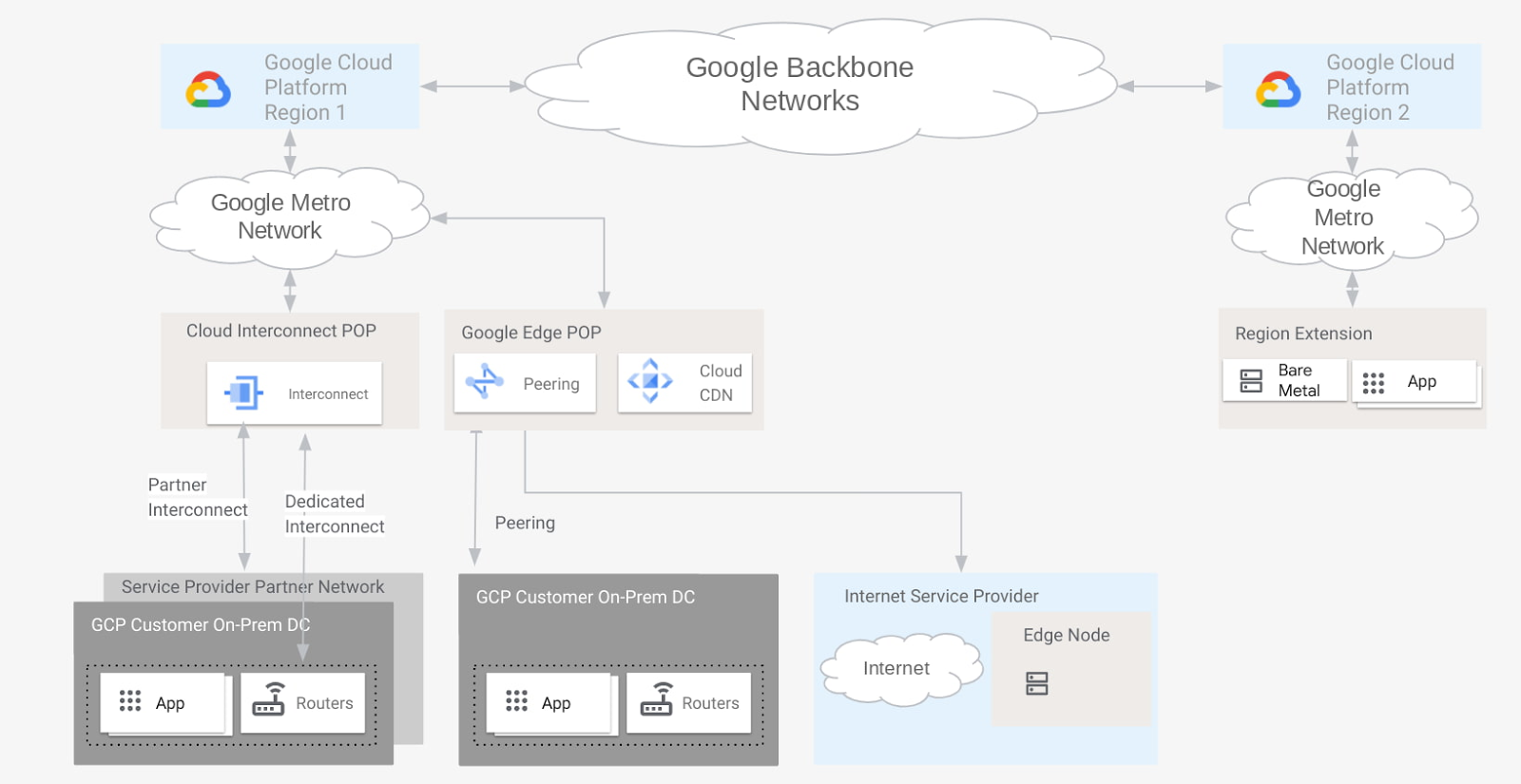
Когда дело доходит до выбора способа подключения к Google Cloud, мы предлагаем множество гибких вариантов, которые оптимизируют производительность и затраты. Но когда дело доходит до границы сети Google, что составляет границу? В зависимости от ваших требований и предпочтений в отношении подключения ваша организация может рассматривать различные точки разграничения в нашей сети как «границу», каждая из которых выполняет передачу трафика по-своему. Например, клиент телекоммуникационной компании может считать, что граница — это место, где расположены глобальные кеши Google (GGC), а не граничная точка присутствия (POP), где происходит пиринг.
В этом сообщении блога мы описываем различные точки присутствия в нашей сети, как они подключаются к Google Cloud и как происходит передача трафика. Вооружившись этой информацией, вы сможете принять более обоснованное решение о том, как лучше всего подключиться к Google Cloud.
Опорные регионы и зоны
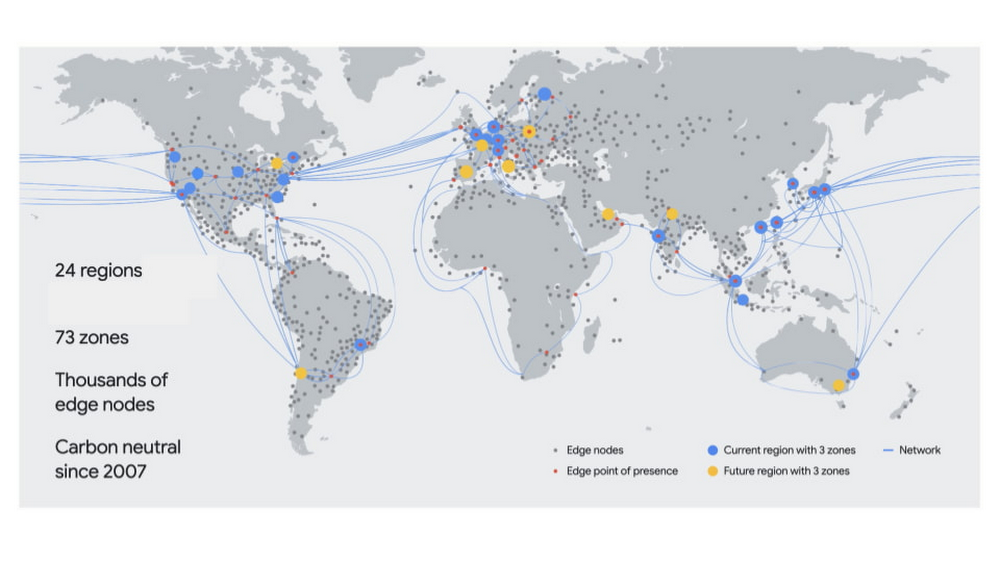
Первое, о чем следует подумать при рассмотрении вариантов периферии, — это то, где ваши рабочие нагрузки выполняются в Google Cloud. Google Cloud размещает вычислительные ресурсы в нескольких местах по всему миру, которые включают разные регионы и зоны. Регион включает центры обработки данных в определенном географическом месте, где вы можете разместить свои ресурсы. В регионах есть три и более зон. Например, регион us-west1 обозначает регион на западном побережье США, который состоит из трех зон: us-west1-a, us-west1-b и us-west1-c.
cloud.google.com/compute/docs/regions-zones
Edge POPs
Наши пограничные точки присутствия — это место, где мы подключаем сеть Google к Интернету через пиринг. Мы присутствуем на более чем 180 интернет-коммутаторах и более чем 160 объектах межсетевого обмена по всему миру. Google управляет большой глобальной ячеистой сетью, которая соединяет наши пограничные точки доступа с нашими центрами обработки данных. Управляя разветвленной глобальной сетью точек подключения, мы можем приблизить трафик Google к нашим партнерам, тем самым уменьшив их затраты, задержку и улучшив работу конечных пользователей.
Google напрямую соединяется со всеми основными поставщиками интернет-услуг (ISP), и подавляющая часть трафика из сети Google к нашим клиентам передается через прямые соединения с интернет-провайдером клиента.
www.peeringdb.com/net/433
cloud.google.com/vpc/docs/edge-locations
Облачный CDN
Cloud CDN (сеть доставки контента) использует глобально распределенные граничные точки доступа Google для кэширования облачного контента рядом с конечными пользователями. Cloud CDN опирается на инфраструктуру на пограничных точках доступа, которую Google использует для кэширования контента, связанного с его собственными веб-ресурсами, которые обслуживают миллиарды пользователей. Такой подход приближает облачный контент к клиентам и конечным пользователям и связывает отдельные точки присутствия в максимально возможное количество сетей. Это сокращает время ожидания и гарантирует, что у нас будет емкость для больших всплесков трафика (например, для потоковой передачи мультимедийных событий или праздничных продаж).
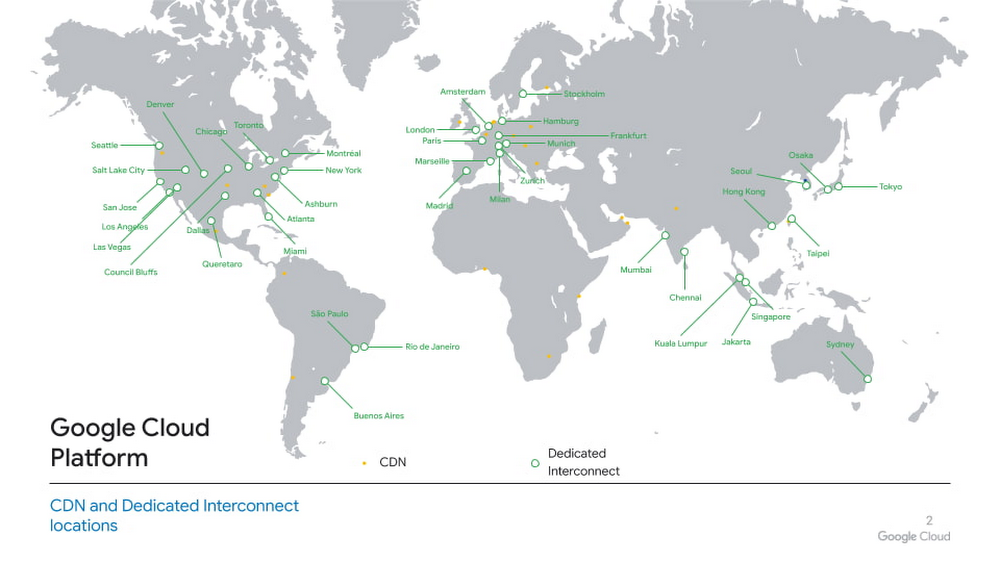
Точки подключения Cloud Interconnect
Выделенное межсоединение обеспечивает прямые физические соединения между вашей локальной сетью и сетью Google. Выделенное межсоединение позволяет эффективно передавать большие объемы данных между сетями. Для Dedicated Interconnect ваша сеть должна физически соответствовать сети Google в поддерживаемом объекте размещения, также известном как место подключения Interconnect. Это средство — это место, где поставщик, поставщик средств совместного размещения, устанавливает канал между вашей сетью и точкой присутствия Google. Вы также можете использовать Partner Interconnect для подключения к Google через поддерживаемого поставщика услуг. Сегодня вы можете подключить межсоединение к Google Cloud в более чем 95 местах.
cloud.google.com/network-connectivity/docs/interconnect/concepts/choosing-colocation-facilities
cloud.google.com/network-connectivity/docs/interconnect/concepts/dedicated-overview
Пограничные узлы или Google Global Cache
Наши граничные узлы представляют собой уровень инфраструктуры Google, ближайший к пользователям Google, и работают в более чем 1300 городах в более чем 200 странах и территориях. С помощью наших граничных узлов сетевые операторы и интернет-провайдеры размещают кеши, предоставленные Google, внутри своей сети. Статический контент, популярный среди пользователей хоста (например, YouTube и Google Play), временно кэшируется на этих граничных узлах, что позволяет пользователям получать этот контент гораздо ближе к их местоположению. Это улучшает работу пользователей и снижает общие требования к пропускной способности сети.
peering.google.com/#/infrastructure
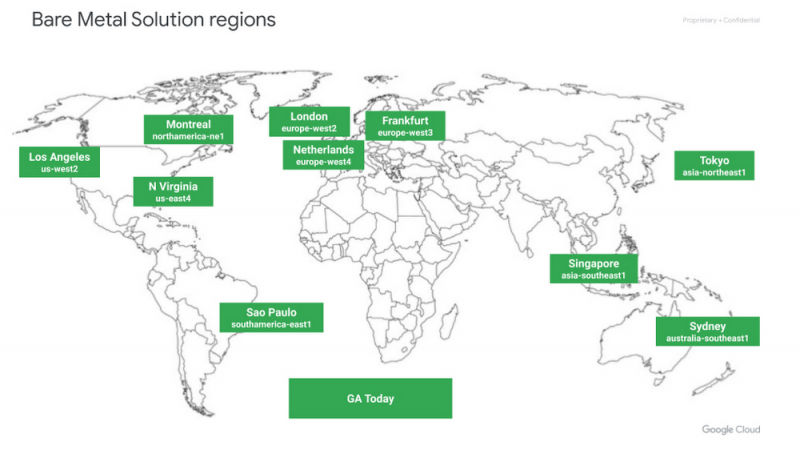
Расширения региона
Для определенных специализированных рабочих нагрузок, таких как Bare Metal Solution, Google размещает серверы в центрах колокации, близких к регионам GCP, чтобы обеспечить подключение с низкой задержкой (обычно <2 мс) для рабочих нагрузок, работающих в Google Cloud. Эти объекты называются расширениями региона.
К краю и обратно
Край в глазах смотрящего. Несмотря на эти и без того огромные вложения в инфраструктуру, сеть и партнерство, мы считаем, что путь к совершенству только начинается. По мере того, как Google Cloud расширяется по охвату и возможностям, ландшафт приложений снова развивается с такими чертами, как критическая надежность, сверхнизкая задержка, встроенный искусственный интеллект, а также тесная интеграция и взаимодействие с сетями 5G и не только. Мы с нетерпением ждем возможности стимулировать будущую эволюцию границ сети, а также возможностей граничного облака. Следите за обновлениями, поскольку мы продолжаем развертывать новые периферийные сайты, возможности и услуги.
Мы надеемся, что в этом посте проясняются предложения Google для границ сети и то, как они помогают соединить ваши приложения, работающие в Google Cloud, с вашими конечными пользователями. Чтобы узнать больше о сетевых возможностях Google Cloud, ознакомьтесь с этими руководствами и решениями по сетевым технологиям Google Cloud.
cloud.google.com/docs/tutorials#networking