https://timeweb.cloud
31 июля 2026 Новые правила для владельцев доменов .ru,.рф и .su
https://timeweb.cloud
31 июля 2026 Новые правила для владельцев доменов .ru,.рф и .su
Ситуация: с 1 сентября у всех регистраторов доменов .ru.рф и .su должна быть кнопка идентификации владельца, которая подтягивает данные через ЕСИА.
Видим, что вы переживаете, а где же эта кнопка у нас. Актуальный статус одной строкой — кнопка есть, но скрыта.
Мы ждем финальный ОК от профильной организации — обещают в ближайшие недели. Кнопка появится в панели сразу после подтверждения.
Сложность вот в чем:
1. Компании, которые подключали ЕСИА по своей инициативе еще до принятия 569-ФЗ, делали это по упрощенной процедуре.
2. Сейчас процедура не упрощенная. Нужно не просто нарисовать кнопку и подключить через API, но и обеспечить много чего еще. Например, согласовать все этапы с регулятором и докупить оборудование.
Добавим контекст — С 1 сентября 2026 владельцы доменов .ru.рф и .su, должны будут проходить официальную идентификацию через ЕСИА. Проще говоря, подтверждать свою личность через Госуслуги. Этого требует новый ФЗ №149.
Без подтверждения станет невозможно регистрировать новые домены, продлевать старые, передавать на них права, менять NS-серверы и регистратора.
Вы можете не ждать кнопку, если ваши регистрационные данные совпадают с Госуслугами. Если нет — вам нужно самостоятельно их актуализировать. Кнопка лишь сверит эти данные и, если они не совпадают, вернет ошибку.
Единственное, что вы можете сделать, это продлить или зарегистрировать домен до 1 сентября 2026 года. Однако когда срок подойдет к концу вам все-равно потребуется пройти идентификацию.
30 июля 2026 Вернули регу в СПб
Можно успеть, пока снова не разобрали. Заказать облачный сервер.
Kubernetes, Managed Databases, S3 и App Platform в этой локации тоже в строю.
29 июля 2026 Запросы к российским API без ошибок TLS
Многие российские сервисы работают на сертификатах Минцифры (Russian Trusted CA). Только у приложений их по умолчанию нет, а если их не добавить — соединение обрывается с ошибкой проверки.
Теперь в App Platform можно включить поддержку сертификатов Минцифры — сразу при создании приложения или в настройках уже существующего.
Что дают сертификаты:
1. Приложение обращается к российским API без ошибок TLS
2. Не нужно дописывать установку сертификатов в сборку и следить за ней при обновлениях
3. Проверка сертификатов остается включенной, а соединение защищено
— В бэкенд-приложениях сертификаты автоматически попадают в доверенное хранилище.
— В Docker-приложениях их нужно включить в список доверенных самостоятельно. Пошаговая инструкция есть в документации.
22 июля 2026 Пак обновлений в AI Gateway разблокирован
Но сначала о другом. На днях опубликуем на Хабре исследование о том, сколько запросов к нашей доке приходит от AI-агентов. Спойлер: много!
А теперь о двух важных релизах в AI Gateway:
1. Новые модели OpenAI: речь и изображения
Добавили модели для синтеза и распознавания речи — GPT-4o mini TTS, GPT-4o mini Transcribe и GPT-4o Transcribe, а для генерации изображений — GPT Images 2.0.
Голосовые интерфейсы, транскрибация звонков, картинки для продукта — теперь доступны без отдельных интеграций через AI Gateway.
2. Модели в контуре российской инфраструктуры
Для проектов, которым важно соблюдать 152-ФЗ: добавили модели, которые работают в РФ — без трансграничной передачи данных. В панели они собраны под фильтром «Локальные».
В списке: Qwen 3 235B Instruct, Qwen 3 Coder 480B A35B, DeepSeek R1 Distill Qwen 32B, Kimi K2 Instruct, Kimi K2.6, GLM 4.6 357B, GPT OSS 120B.
Пока эти модели доступны в AI Gateway — в AI-агентах появятся немного позже.
21 июля 2026 Меняем архитектуру взаимодействия сервисов
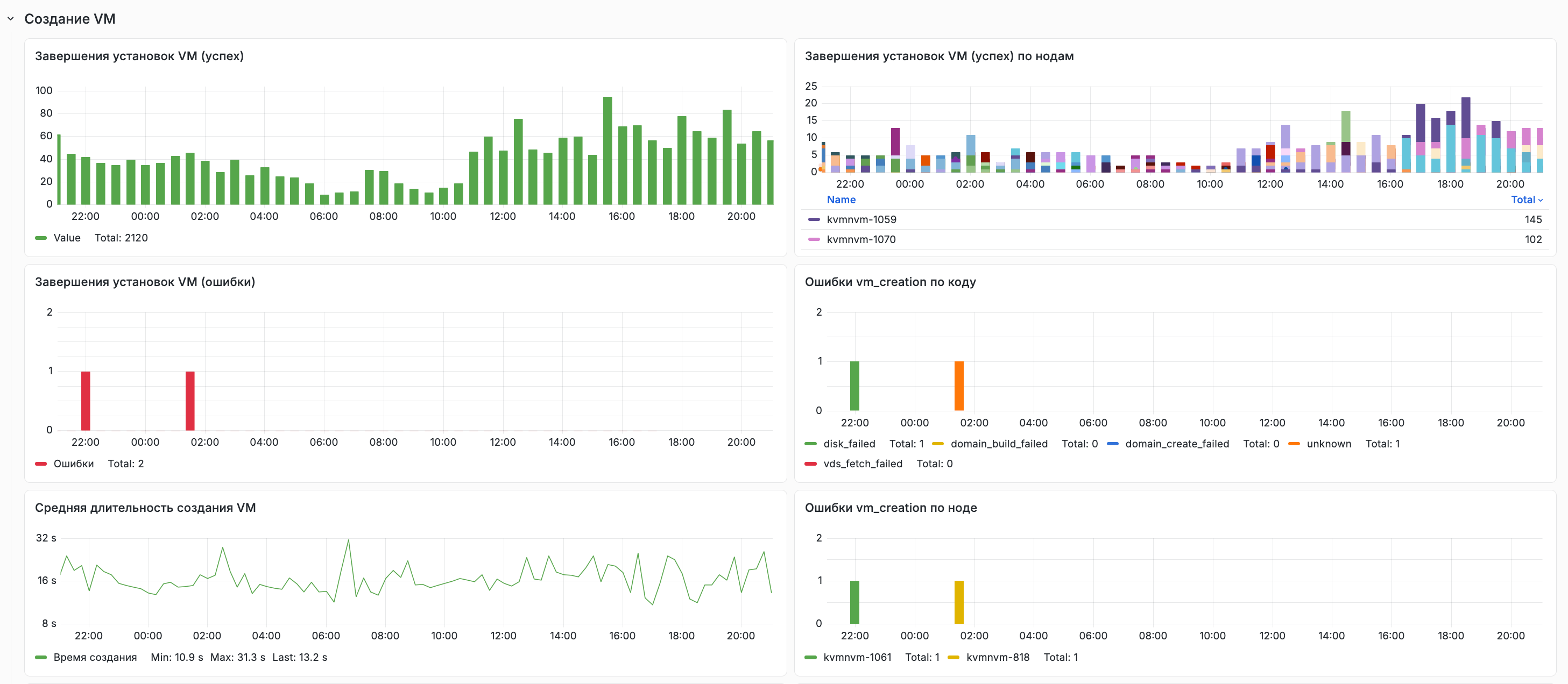
Начнем с самого заметного: стандартный облачный сервер теперь создается в среднем за 30 секунд — от клика на кнопку до готовой машины.
За этим стоит смена архитектуры. На каждом гипервизоре теперь работает свой агент: центральное API ставит задачу → агент выполняет ее на месте и сразу отчитывается.
Цепочка каждой операции стала проще, а независимые процессы идут параллельно, а не по очереди.
И эта схема прозрачная: каждый шаг создания сервера виден на графиках. Если что-то начинает замедляться или сбоить, мы сразу замечаем это по данным — и чиним точечно, а не ищем по всей цепочке.
Что дальше. Переводим на новую схему остальное: управляемые базы данных, серверы с Windows, установку из образов.
Это часть инфраструктурных работ, о которых рассказываем в последних постах: меньше ручных операций, больше автоматики и метрик.
17 июля 2026 Обновленный интерфейс доменов в App Platform
Последние недели разбирали техдолг, чтобы сервисы работали быстрее и предсказуемее. Большая часть работ незаметна снаружи, но одно обновление вы увидите сразу — в доменах App Platform.
Домены — очень чувствительный узел: ошибка в привязке, и приложение не откроется у ваших пользователей. Раньше редактировать их приходилось на отдельной странице, в отрыве от остальных настроек приложения.
Теперь сценарий другой: открываете вкладку «Домены» в настройках приложения → выбираете уже добавленный домен или вводите внешний → «Сохранить» → готово, приложение доступно по домену.
Подробнее о привязке
timeweb.cloud/docs/apps/upravlenie-apps-v-paneli#privyazka-domena
1. Домен уже занят другим сервисом? Предупредим об этом заранее — и после сохранения сами перепривяжем его на нужное приложение.
2. Добавляете внешний домен? Подскажем нужный IP прямо в окне — вам останется добавить A-запись у своего регистратора.
16 июля 2026 Ваш агент может в разы больше, чем вы думаете
Агент, конечно, может подсказать вам команду, но выполнять ее все равно придется руками. С MCP-сервером иначе: подключаете один раз — и агент действует самостоятельно.
Самое приятное: интеграцию под каждый инструмент писать не нужно. Достаточно взять из галереи:
1. Для разработки — Context7. Попросите обновить зависимости под Next.js 14 → агент возьмет доку 14-й версии, а не из 12-й, которую запомнил при обучении.
2. Для инфраструктуры — Timeweb Cloud MCP. Даете команду развернуть сервер, проверить статус кластера или посмотреть баланс → агент запросит разрешение и выполнит все необходимые действия.
3. Для бизнес-задач — Яндекс Поиск, amoCRM, Контур.Фокус, Bitrix24 и VK Реклама → агент сам найдет нужное в сети, обновит CRM или подтянет статистику кампаний.
А если нужного сервиса нет — любой удаленный MCP-сервер подключается вручную. Например, Google Drive для ответов с опорой на документы с диска или MySQL для запросов к базе прямо из диалога. Подробнее о подключении → в документации
15 июля 2026 Набрали 1165 баллов в новом рейтинге CNews
Сегодня даже стартапу легко доступны те же управляемые сервисы, что и крупным компаниям: Kubernetes, хранилище S3, и базы данных с бэкапами. Если раньше было четкое разделение: «облако для больших» и «облако для маленьких», то теперь это просто инструмент. И главные требования к нему — легко встраиваться в процессы и быть удобным для команды.
Как раз это и учитывал CNews в своем первом рейтинге облаков для малого и среднего бизнеса — и мы заняли в нем первое место.
Максимум баллов набрали в четырех направлениях:
1. Стек управляемых сервисов — за функциональность баз данных, Kubernetes и S3
2. Панель управления — потому что все под рукой с интерактивными дашбордами и сквозным поиском по инфраструктуре
3. AI-агенты — за выбор инструментов для бизнеса: OpenAI-совместимый API, подключение MCP-серверов и множество моделей
4. Цены — одни из самых доступных на рынке
Кажется, рынок наконец определился, что небольшим командам нужно от облака: управляемые сервисы, готовые AI-решения и комплексная поддержка для бизнеса.
14 июля 2026 Подборка под ваш кластер
Kubernetes и так мощный оркестратор, а с нужными аддонами дорастает до полноценной продакшен-среды. На основе статистики ваших установок собрали пять задач, которые можно закрыть аддонами:
1. Envoy Gateway — принимать весь трафик через одну точку входа
Разводит входящие запросы по сервисам — не нужно выдавать каждому отдельный внешний IP. Заодно балансирует нагрузку.
2. cert-manager — продлевать SSL-сертификаты автоматически
Сам выпускает и продлевает сертификаты — посетители не увидят предупреждение о небезопасном соединении.
3. CSI Driver — не терять данные при перезапуске подов
Подключает подам постоянные диски. В первую очередь будет полезно базам данных.
4. kube-prometheus-stack — видеть все, что происходит с кластером
Собирает метрики по всему кластеру и выводит их на готовые дашборды. Если что-то идет не так — прилетает алерт.
5. ArgoCD — деплоить прямо из Git
Синхронизирует кластер с репозиторием. Меняете манифест и кластер сам приходит к нужному состоянию.
А вместе они закрывают весь цикл работы кластера: принять трафик → защитить его → сохранить данные → следить за состоянием → доставлять обновления.
13 июля 2026 Продолжаем усиливать инфраструктуру
1. Перенастроили политики libvirt
Раньше при высокой нагрузке очереди забивались и libvirt дольше расставлял задачи по приоритетам. Отсюда вытекали проблемы — установка отменяется или зависает.
Мы протестировали новые настройки, после чего раскатали на ноды во всех регионах. Теперь действия из панели отрабатывают гораздо быстрее и без проблем.
2. Перевели AI-агентов на High Availability
Теперь у нас два геораспределенных кластера: один находится в Германии, второй в США. Все важные сервисы реплицируются внутри одного региона и дублируются в другой.
3. Свежие дистрибутивы на основе Debian перешли на нативное получение IPv6 по DHCP
Тут логика простая — серверы с публичным IPv6, но без IPv4, теперь грузятся быстрее.
10 июля 2026 Расширили выбор моделей в AI-агентах
Добавили новинки, которые уже ждут вас в панели:
1. GPT 5.6 — Sol, Terra и Luna. Для широкого круга задач: от текста и кода до цепочки рассуждений.
2. Grok 4.5. Для работы с актуальным контекстом.
3. Qwen 3.7 Max, 3.7 Plus и 3.6 Plus. Max — под самые тяжелые задачи, Plus — баланс скорости и качества ответов.
Заодно подключили нового провайдера — Z.ai с линейкой GLM: 5.2, 4.7 и 4.7 FlashX. Это открытые модели, заточенные под код и агентные сценарии.
Это еще не все. Модели, которые раньше делились на thinking и non-thinking, объединили в одну — режим размышлений можно включить прямо в плейграунде.
9 июля 2026 Самое интересное об S3 — в одном видео
Рассказываем про то, что вообще умеет S3 и под какие задачи его берут:
1. Раздача статики через CDN. Файлы находятся в S3, а CDN раздает их пользователям из ближайшей точки.
2. Обмен файлами по временным ссылкам. S3 выдает временный доступ к файлу без настройки прав.
3. Медиа для каталогов. Фото товаров размещаются в S3, не занимают место на сервере и не нагружают приложение.
4. Резервное копирование. Бэкапы лежат вне основного сервера — вне основного сервера и не зависят от его состояния.
Что из этого пригодится именно вашему проекту, рассказал в видеообзоре наш продакт-менеджер Сергей Плеханов. А еще — почему файлы невозможно потерять, и за счет чего S3 помогает экономить.
Смотрите на удобной площадке: ютуб, вк, рутуб.
www.youtube.com/watch?v=OKJILZMVewk
vkvideo.ru/video-28839208_456239650
rutube.ru/video/bb6e8b5999272876454e15e8b0bd97c3/
8 июля 2026 Обновления в объектном менеджере S3
Недавно посчитали, что в нашем S3 лежит уже 2,7 млрд ваших объектов, и их становится только больше. Все они защищены тройной репликацией, поэтому остаются доступны даже при отказе отдельных узлов.
Помимо доступности развиваем и сам объектный менеджер — вот что добавили недавно:
1. Возможность предпросмотра
74 новых формата — видео, текстовые файлы, таблицы, документы и презентации доступны для просмотра прямо в объектном менеджере без скачивания.
Полный список поддерживаемых форматов.
2. Роль «Чтение и запись»
Добавили по вашим запросам. С этой ролью сотрудник, сервис или приложение работает только с объектами — читает, загружает, изменяет и удаляет. Настройки бакета и управление хранилищем остаются закрыты, так что задеть конфигурацию не получится. Остальные роли и уровни доступа собрали в доке.
timeweb.cloud/docs/s3-storage/manage-storage/additional-users#urovni-dostupa
7 июля 2026 Апдейты от наших инженеров
Расскажем об инфраструктурных работах в трех направлениях.
1. Масштабируем сервис сетевых дисков
Сервис отвечает за операции вокруг сетевых дисков: создание, монтирование, подключение. Запросов к нему становится больше, и особенно это заметно на пиках — диск может создаваться или монтироваться не сразу.
Переработали архитектуру сервиса и сделали ее распределенной. Сервис масштабируется горизонтально, мощность растет вслед за нагрузкой — прежнее ограничение по скорости снято.
2. Изолируем проблемные ноды в очереди
Как только нода перестает отвечать, сразу откладываем приходящие на нее задачи. Ускорили этот процесс, чтобы нода изолировалась быстрее и не тянула за собой остальные — очередь не застревает, а живые ноды работают как обычно.
Немного технических деталей: мы регулярно проверяем доступность нод через libvirt. Если нода несколько раз подряд не отвечает, помечаем ее как недоступную → задачи к ней откладываются, пока связь не восстановится
3. Ускоряем создание бэкапов
Обновляем парк хранилищ в Москве на более производительное оборудование и заодно приводим все хранилища к единой конфигурации. За счет этого бэкапы создаются быстрее.
На весь парк уйдет около двух месяцев. Данные реплицируются на время работ, так что обновление не затронет ваши проекты.
И это, конечно, не все. Часть обновлений еще обкатываем — поделимся ими, когда сами убедимся, что все работает стабильно.
7 июля 2026 Jivo в AI-агентах
Более 270 000 компаний в России используют этот онлайн-чат. Теперь к нему можно подключить AI-агента — он сам ответит на типовые вопросы клиентов.
Клиент пишет в Jivo-чат → AI-агент сразу отвечает по базе знаний → администратор видит все ответы и в реальном времени может подхватить диалог или поправить бота. Без отдельных окон и переключений между вкладками.
Пошаговая настройка →
timeweb.cloud/docs/ai-agents/manage-agents/jivo
Что чат с агентом дает вашему проекту:
1. Поддержка 24/7 — агент отвечает мгновенно ночью, в выходные и в пики обращений.
2. Меньше нагрузки на операторов — команда будет подключаться только к сложным запросам, а типовые вопросы агент возьмет на себя.
3. Ни один диалог не потеряется — когда агент не справляется, он сам передает обращение оператору со свободным доступом к чату.
6 июля 2026 Туда, где охлаждение умеет резервироваться
Нашей новой локацией для зоны ams-1 станет ЦОД NorthC
Прямо сейчас совместно с инженерами площадки мы экстренно расширяем мощности по питанию под объемы наших стоек. На саму миграцию закладываем месяц. Подробности — скоро.
3 июля 2026 Цифры, о которых неприятно говорить
Много вопросов по поводу DDoS. На эту тему у нас много материалов, которыми мы периодически делимся. Сейчас картина следующая:
- В этот сезон мы сталкиваемся с новой атакой широким конусом на 80 000 IP-адресов одновременно, что делает обнаружение заметно более проблематичным. В отдельных случаях, мы говорим о ~2 000 pps на отдельный хост, что очень не просто отличить от фонового трафика.
- Атаки по-прежнему идут преимущественно на L3/4 уровни UDP-флудом, в то время как объем паразитного трафика вырос до ~150 млн пакетов в секунду.
- Волны атак в пике достигают 3 Тбит/с — это беспрецедентный для РФ объем, который становится новой реальностью в 2026 году.
Видим вопросы о том, что мы с этим делаем. Тут правильнее дать слово Максиму Яковлеву, это наш CTO:
Мы давно сотрудничаем с крупнейшим российским провайдером в области информационной безопасности StormWall, пользуемся их решениями. У нас есть ряд внутренних детекторов аномалий, которые при обнаружении нехарактерных для сети пиков, переводят ее за систему очистки StormWall.
На сегодняшний день, по сочетанию факторов, мы считаем этот подход наиболее эффективным, как в разрезе техники, так и экономики. Это позволяет снизить влияние на инфраструктуру, при этом не делая трафик заградительно дорогим для всех.
Когда мы публикуем сообщение в алерт, это означает, что начинает работать массовая фильтрация.
На текущий момент фильтрация защищает эффективно, но при этом может задевать легитимный трафик, который попадает под паттерн атаки. В этом случае идеально работает только индивидуальное включение защиты с подбором под конкретный трафик. Это может быть решение на стороне клиента или через нас — через донастройку StormWall или подключение DDoS-Guard, по запросу или напрямую из панели управления.
1 июля 2026 Про инцидент в зоне ams-1
1. Инфраструктура в зоне ams-1 полностью восстановлена — с сегодняшнего дня всем клиентам подключен нулевой биллинг до 5 июля включительно, инфраструктура будет полностью бесплатной.
2. Мы инициировали процедуру переезда в другой ЦОД. Под наши объемы в 65 000 виртуальных машин есть хороший вариант с нужной емкостью по стойкам, но в них нужно нарастить мощности по питанию → для этого совместно с ЦОД будем проводить срочные работы по расширению в ближайшие 2 недели. Также прорабатываем вариант аренды второго ЦОДа в локации, чтобы можно было организовать полноценное резервирование. Реалистичный срок срочного переезда учитывая объемы и регион — месяц.
3. Для этой локации будет организовано бесплатное бэкапирование в другой регион.