Несколько месяцев назад Cloudflare объявила о переходе на FL2, нашу переработанную на Rust версию основного уровня обработки запросов Cloudflare. Этот переход ускоряет нашу способность помогать создавать лучший Интернет для всех. Благодаря миграции в программном стеке, Cloudflare обновила конструкцию серверного оборудования, улучшив его возможности и повысив эффективность для удовлетворения меняющихся потребностей нашей сети и программного обеспечения.
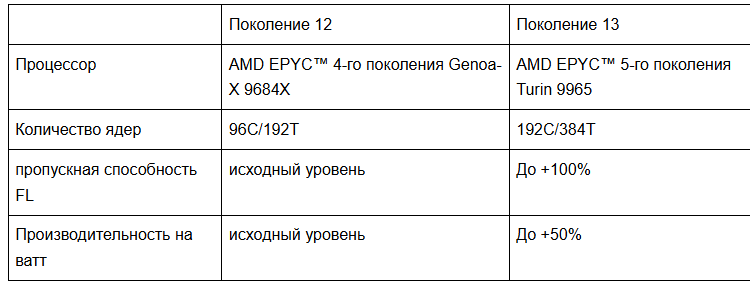
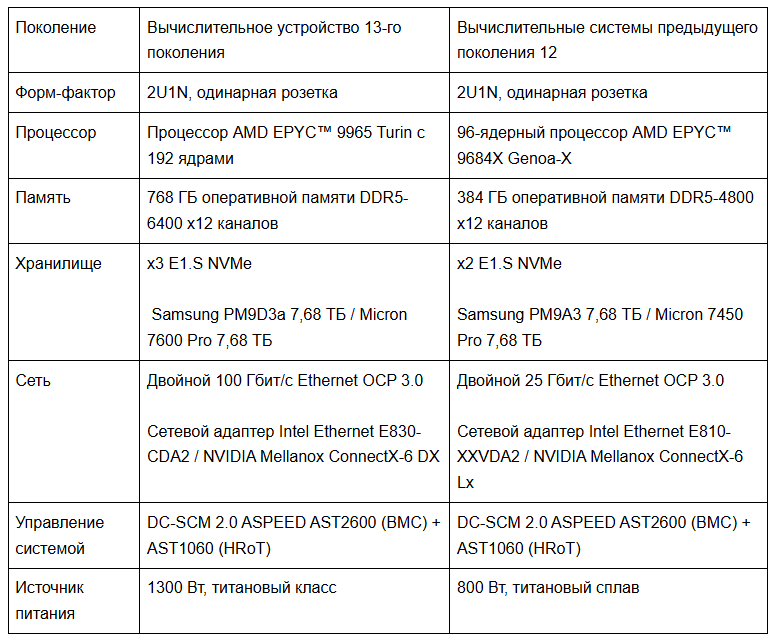
Серверы 13-го поколения оснащены 192-ядерным процессором AMD EPYC Turin 9965, 768 ГБ оперативной памяти DDR5-6400, 24 ТБ хранилища PCIe 5.0 NVMe и двумя сетевыми картами с портами 100 Гбит/с.
13-е поколение предлагает:
- До 2 раз более высокая пропускная способность по сравнению с Gen 12 при сохранении уровня задержки в пределах SLA.
- Повышение производительности на ватт до 50%, что снижает затраты на расширение центров обработки данных.
- Увеличение пропускной способности на стойку до 60% при сохранении постоянного энергопотребления стойки.
- Вдвое больший объем памяти, в 1,5 раза больший объем хранилища, в 4 раза большая пропускная способность сети.
- В дополнение к шифрованию памяти, добавлена поддержка аппаратного шифрования PCIe.
- Улучшена поддержка мощных, требующих интенсивного теплоотвода ускорителей PCIe, устанавливаемых без доработок.
В этой статье в блоге подробно рассматривается инженерное обоснование выбора каждого из основных компонентов: что мы оценивали, что выбрали и почему.
 Процессор
Процессор

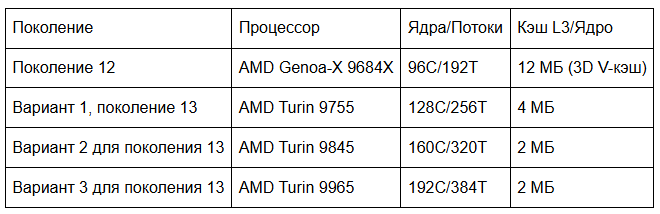
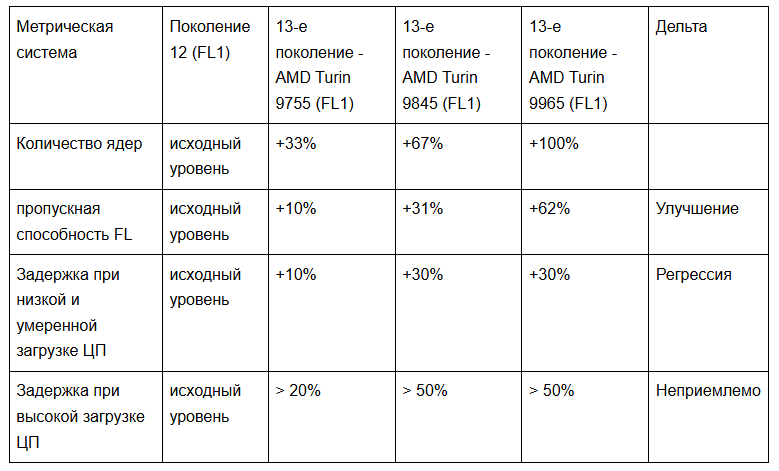
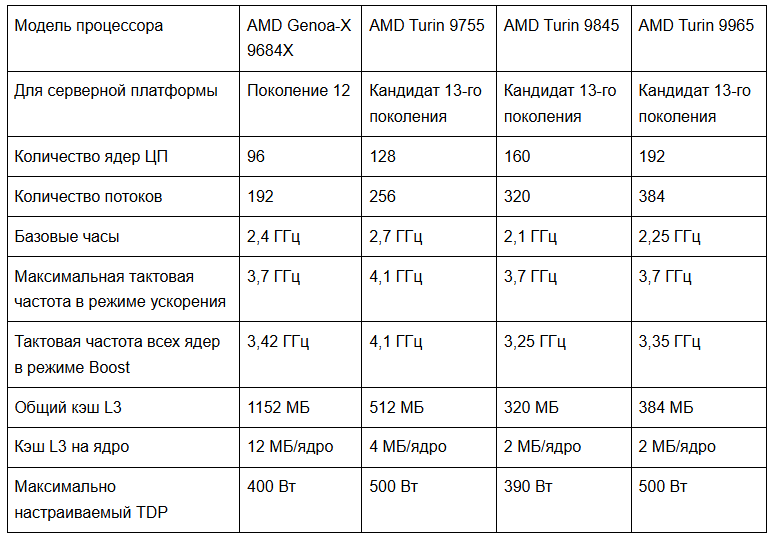
На этапе проектирования мы протестировали несколько процессоров AMD EPYC™ 5-го поколения, получивших кодовое название Turin, в аппаратной лаборатории Cloudflare: AMD Turin 9755, AMD Turin 9845 и AMD Turin 9965. В таблице ниже приведены различия в характеристиках кандидатов для серверов 13-го поколения по сравнению с AMD Genoa-X 9684X, используемым в наших серверах 12-го поколения. Следует отметить, что все три кандидата предлагают увеличение количества ядер, но с меньшим объемом кэша L3 на ядро. Однако, благодаря переходу на FL2, новые рабочие нагрузки менее зависимы от кэша L3 и хорошо масштабируются с увеличением количества ядер, обеспечивая увеличение пропускной способности до 100%.
Три представленных процессора предназначены для разных сценариев использования: AMD Turin 9755 предлагает превосходную производительность на ядро, AMD Turin 9965 жертвует производительностью на ядро ради энергоэффективности, а AMD Turin 9845 жертвует количеством ядер ради меньшего энергопотребления сокета. Мы протестировали три процессора в производственной среде.
 Почему именно AMD Turin 9965?
Почему именно AMD Turin 9965?
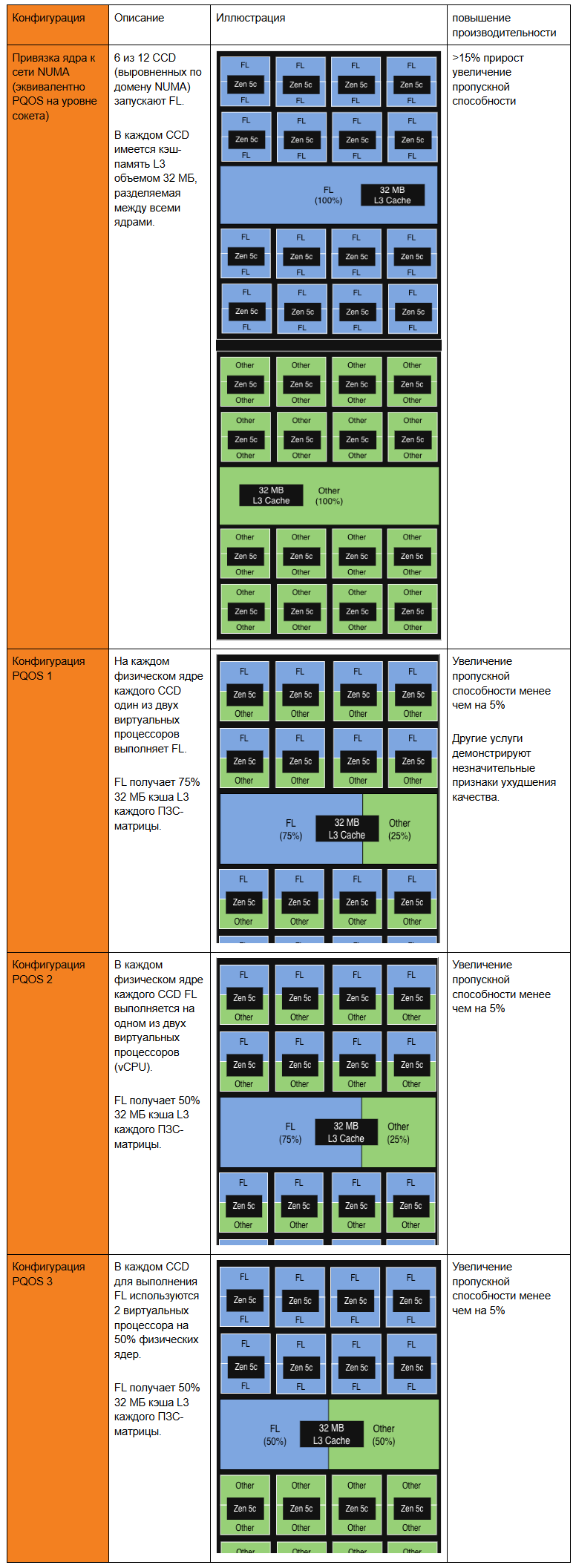
Во-первых, FL2 положила конец проблеме нехватки кэша L3.
Кэш L3 — это большой кэш последнего уровня, разделяемый всеми ядрами ЦП на одном вычислительном кристалле для хранения часто используемых данных. Он заполняет пробел между медленной основной памятью, находящейся вне ЦП, и быстрым, но меньшим по размеру кэшем L1 и L2 на ЦП, уменьшая задержку доступа ЦП к данным.
Некоторые могут заметить, что у 9965 всего 2 МБ кэша L3 на ядро, что на 83,3% меньше, чем 12 МБ на ядро у Genoa-X 9684X 12-го поколения. Зачем отказываться от того самого преимущества в кэше, которое дало Gen 12 его превосходство? Ответ кроется в том, как эволюционировали наши рабочие нагрузки.
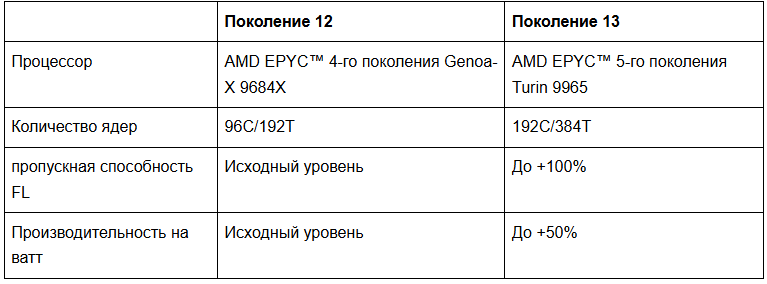
Cloudflare перешла с FL1 на FL2, полностью переписав свой слой обработки запросов на Rust. Благодаря новому программному стеку конвейер обработки запросов Cloudflare стал значительно менее зависимым от большого кэша L3. Нагрузки FL2 масштабируются почти линейно с количеством ядер, а 192 ядра 9965 обеспечивают двукратное увеличение количества аппаратных потоков по сравнению с Gen 12.
Во-вторых, производительность на единицу общей стоимости владения (TCO). В ходе производственной оценки 192 ядра 9965 показали наибольшее суммарное количество запросов в секунду среди трех кандидатов, а его производительность на ватт благоприятно масштабировалась при TDP 500 Вт, обеспечивая превосходную общую стоимость владения на уровне стойки.
Во-третьих, простота в эксплуатации. Наши оперативные группы отдают предпочтение меньшему количеству серверов с высокой плотностью размещения. Управление парком машин с 192 ядрами означает меньшее количество узлов, которые необходимо выделять, обновлять и контролировать на единицу предоставленных вычислительных ресурсов. Это напрямую снижает операционные издержки в нашей глобальной сети.
Наконец, они обладают обратной совместимостью. Архитектура процессоров AMD поддерживает память DDR5-6400, PCIe Gen 5.0 и CXL 2.0 Type 3 во всех моделях. AMD Turin 9965 имеет наибольшее количество высокопроизводительных ядер на сокет в отрасли, что максимизирует вычислительную плотность на сокет, поддерживая конкурентоспособность и актуальность платформы на долгие годы. Переход с AMD Genoa-X 9684X на AMD Turin 9965 обеспечивает более длительную поддержку безопасности от AMD, продлевая срок службы серверов Gen 13 до того, как они устареют и потребуют обновления.
Память

Поскольку процессор AMD Turin имеет вдвое больше ядер, чем предыдущее поколение, ему требуется больше памяти, как по объему, так и по пропускной способности, для обеспечения увеличения производительности.
Максимальная пропускная способность при использовании 12 каналов.
Выбранный процессор AMD EPYC 9965 поддерживает двенадцать каналов памяти, и для 13-го поколения мы устанавливаем модули во все из них. Мы выбрали 64 ГБ памяти DDR5-6400 ECC RDIMM в конфигурации «один модуль на канал» (1DPC).
Эта конфигурация обеспечивает пиковую пропускную способность памяти 614 ГБ/с на сокет, что на 33,3% больше по сравнению с нашей серверной платформой 12-го поколения. Используя все 12 каналов, мы гарантируем, что процессор никогда не будет испытывать «нехватку» данных, даже при самых ресурсоемких параллельных нагрузках.
Использование сбалансированной конфигурации всех двенадцати каналов памяти — одинаковая емкость на канал, без смешанных конфигураций — является распространенной передовой практикой. Это важно с точки зрения эксплуатации: процессоры AMD Turin используют чередование памяти по всем каналам памяти с одинаковым типом DIMM, одинаковой емкостью памяти и одинаковой конфигурацией ранга. Чередование увеличивает пропускную способность памяти за счет распределения непрерывного доступа к памяти по всем каналам памяти в наборе чередующихся каналов, вместо того чтобы направлять весь доступ к памяти на один или небольшое подмножество каналов памяти.
Оптимальный объем памяти — 4 ГБ на ядро.
Наши серверы 12-го поколения имеют конфигурацию с 4 ГБ оперативной памяти на ядро. Мы пересмотрели это решение при проектировании серверов 13-го поколения.
Cloudflare ежемесячно запускает множество новых продуктов и услуг, и каждый новый продукт или услуга требует всё большего объёма памяти. Со временем это приводит к накоплению объёма памяти, что может стать проблемой нехватки памяти, если объём памяти не будет рассчитан должным образом.
Первоначально предполагалось соотношение памяти к ядру от 4 до 6 ГБ на ядро. При наличии 192 ядер на AMD Turin 9965 это соответствует диапазону от 768 ГБ до 1152 ГБ. Следует отметить, что при больших объемах шаг изменения емкости модуля DIMM обычно составляет 16 ГБ. При 12 каналах в конфигурации 1DPC доступны варианты 12x 48 ГБ (576 ГБ), 12x 64 ГБ (768 ГБ) или 12x 96 ГБ (1152 ГБ).
- 12 x 48 ГБ = 576 ГБ, или 1,5 ГБ на поток. Объем памяти в этой конфигурации слишком мал; это приведет к нехватке памяти для ресурсоемких задач и нарушению нижнего предела.
- 12 x 96 ГБ = 1152 ГБ, или 3,0 ГБ/поток. Это означает увеличение емкости на ядро на 50%, а также приведет к увеличению энергопотребления и существенному росту стоимости, особенно в нынешних рыночных условиях, когда цены на память в 10 раз выше, чем год назад.
- 12 x 64 ГБ = 768 ГБ, или 2,0 ГБ/поток (4 ГБ/ядро). Эта конфигурация соответствует нашему соотношению памяти к ядрам в Gen 12 и представляет собой двукратное увеличение объема памяти на сервер. Сохранение объема памяти на уровне 4 ГБ на ядро обеспечивает достаточную емкость для рабочих нагрузок, масштабируемых с увеличением количества ядер, таких как наша основная рабочая нагрузка, FL, и обеспечивает достаточный запас памяти для будущего роста без избыточного выделения ресурсов.
FL2 использует память более эффективно, чем FL1: наши внутренние измерения показывают, что FL2 использует менее половины ресурсов процессора, чем FL1, и значительно меньше половины памяти. Высвобожденные ресурсы, полученные в результате миграции программного стека, обеспечивают достаточный запас для поддержки роста Cloudflare в течение следующих нескольких лет.
Решение: 12 модулей по 64 ГБ, что в сумме составляет 768 ГБ. Это сохраняет проверенное соотношение 4 ГБ/ядро, обеспечивает двукратное увеличение общей емкости по сравнению с 12-м поколением и остается в оптимальном ценовом диапазоне модулей DIMM.
Повышение эффективности за счет двойного ранга
В Gen 12 мы продемонстрировали, что двухранговые модули DIMM обеспечивают заметно более высокую пропускную способность памяти, чем одноранговые модули, с преимуществами до 17,8% при соотношении чтения и записи 1:1. Двухранговые модули DIMM быстрее, потому что они позволяют контроллеру памяти обращаться к одному рангу, пока другой обновляется. Этот же принцип применим и здесь.
Наши требования также предусматривают пропускную способность памяти примерно в 1 ГБ/с на каждый аппаратный поток. При пиковой пропускной способности в 614 ГБ/с на 384 потоках мы обеспечиваем 1,6 ГБ/с на поток, что значительно превышает минимальный показатель. Анализ производственных условий показал, что рабочие нагрузки Cloudflare не ограничены пропускной способностью памяти, поэтому мы сохраняем этот запас как резерв для будущего роста нагрузки.
Выбрав модули памяти DDR5 RDIMM 2Rx4 с максимальной поддерживаемой частотой 6400 МТ/с, мы обеспечиваем минимальную задержку и наилучшую производительность в конфигурации памяти нашей платформы Gen 13.
Хранилище
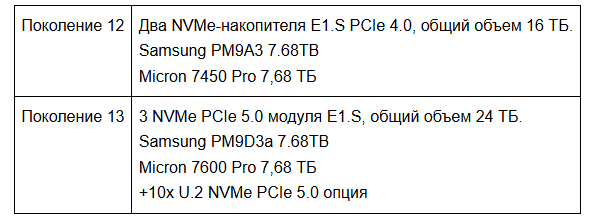
В 12-м поколении наша архитектура хранения данных претерпела трансформацию, когда мы перешли от M.2 к EDSFF E1.S. В 13-м поколении мы увеличиваем емкость хранения и пропускную способность, чтобы соответствовать новейшим технологиям. Мы также добавили фронтальный отсек для накопителей, что обеспечивает гибкость и позволяет устанавливать до 10 накопителей U.2, чтобы идти в ногу с ростом продаж продуктов хранения Cloudflare.
Переход на PCIe 5.0
В Gen 13 используются накопители NVMe PCIe Gen 5.0. Хотя Gen 4.0 хорошо себя зарекомендовал, переход на Gen 5.0 гарантирует, что наша подсистема хранения данных сможет передавать данные с меньшей задержкой и справляться с возросшими требованиями к пропускной способности хранилища, предъявляемыми новым процессором.
от 16 ТБ до 24 ТБ
Помимо увеличения скорости, мы физически расширяем массив с двух до трех NVMe-накопителей. Наша серверная платформа 12-го поколения была разработана с четырьмя слотами для накопителей E1.S, но только два из них были заняты 8-терабайтными дисками. Серверная платформа 13-го поколения использует ту же конструкцию с четырьмя доступными слотами для накопителей E1.S, но три из них заняты 8-терабайтными дисками. Зачем добавлять третий диск? Это увеличивает емкость хранилища на сервер с 16 ТБ до 24 ТБ, обеспечивая расширение нашей общей емкости хранилища для поддержания и улучшения производительности кэша CDN. Это также поддерживает прогнозируемый рост для Durable Objects, Containers и сервисов Quicksilver.
Передний отсек для дисков для установки дополнительных накопителей.
Для Gen 13 шасси спроектировано с передним отсеком для накопителей, который может поддерживать до десяти накопителей U.2 PCIe Gen 5.0 NVMe. Передний отсек для накопителей позволяет Cloudflare использовать одно и то же шасси на вычислительных и хранилищных платформах, а также обеспечивает гибкость при необходимости преобразования вычислительной версии в версию для хранения данных.
Выносливость и надежность
Мы проектируем наши серверы с расчетом на 5-летний срок службы и требуем от накопителей ресурс в 1 операцию записи в день (DWPD) на протяжении всего срока службы сервера.
Как Samsung PM9D3a, так и Micron 7600 Pro соответствуют спецификации 1 DWPD с аппаратным резервированием (OP) приблизительно на 7%. Если в будущем потребуется более высокая ресурсоемкость, у нас есть возможность зарезервировать дополнительную пользовательскую мощность для увеличения эффективного OP.
Соответствие стандартам NVMe 2.0 и OCP NVMe 2.0
Как Samsung PM9D3a, так и Micron 7600 используют спецификацию NVMe 2.0 (вместо NVMe 1.4) и спецификацию OCP NVMe Cloud SSD Specification 2.0. Ключевые улучшения включают в себя зонированные пространства имен (ZNS) для более эффективного управления усилением записи, команду Simple Copy Command для перемещения данных внутри устройства без пересечения шины PCIe, а также улучшенную блокировку команд и функций для более жесткого контроля безопасности. Спецификация OCP 2.0 также добавляет расширенные возможности телеметрии и отладки, специально разработанные для работы в центрах обработки данных, что соответствует нашему акценту на управляемость всего парка устройств.
Тепловой КПД
Накопители по-прежнему будут выполнены в форм-факторе E1.S толщиной 15 мм. Большая площадь поверхности корпуса необходима для охлаждения новых контроллеров Gen 5.0, которые могут потреблять до 25 Вт при длительной интенсивной работе. Корпус высотой 2U обеспечивает достаточный воздушный поток над накопителями E1.S, а также отсеками для накопителей U.2, — преимущество, подтвержденное нами в Gen 12, когда мы приняли решение перейти от форм-фактора 1U к 2U.
Сеть

Более восьми лет два порта 25 Гбит/с Ethernet составляли основу нашего парка оборудования. С 2018 года они хорошо нам служили, но по мере совершенствования процессоров для обработки большего количества запросов и масштабируемости нашей продукции мы официально достигли предела своих возможностей. Для 13-го поколения мы вчетверо увеличиваем пропускную способность каждого порта.
Почему именно 100 Гбит/с Ethernet и почему именно сейчас?
Пропускная способность сетевых интерфейсных карт (NIC) должна соответствовать росту вычислительной производительности. При наличии 192 современных ядер наши каналы 25 Гбит/с Ethernet станут ощутимым узким местом. Данные, полученные в ходе недельной эксплуатации наших центров обработки данных по всему миру, показали, что на наших серверах 12-го поколения пропускная способность P95 на порт стабильно превышает 50% от доступной пропускной способности. Поскольку пропускная способность на каждом сервере 13-го поколения удваивается, мы рискуем перегрузить пропускную способность сетевых интерфейсных карт.
Решение перейти на 100 GbE вместо 50 GbE было продиктовано экономическими соображениями отрасли: объемы производства трансиверов 50 GbE остаются низкими, что делает их невыгодным вариантом для цепочки поставок. Два порта 100 GbE также обеспечивают суммарную пропускную способность 200 Гбит/с на сервер, что гарантирует готовность к росту трафика в ближайшие несколько лет.
Выбор оборудования и совместимость
Мы сохраняем нашу стратегию работы с двумя поставщиками, чтобы обеспечить устойчивость цепочки поставок — урок, который мы с трудом усвоили во время пандемии, когда закупка сетевых карт Gen 11 у одного поставщика привела к тому, что мы оказались в затруднительном положении.
Обе сетевые карты соответствуют форм-фактору OCP 3.0 SFF/TSFF со встроенной защелкой, что обеспечивает унифицированность шасси с Gen 12 и гарантирует, что полевым специалистам не потребуются новые инструменты или обучение для замены.
Распределение PCIe
Слот OCP 3.0 NIC на материнской плате имеет выделенные линии PCIe 4.0 x16, обеспечивающие двунаправленную пропускную способность 256 Гбит/с, чего более чем достаточно для двух интерфейсов 100 Гбит/с (суммарная скорость 200 Гбит/с) с запасом.
Управление

Мы сохраняем архитектурный сдвиг, введенный в Gen 12, заключающийся в разделении компонентов управления и безопасности от материнской платы на модуль
Project Argus Data Center Secure Control Module 2.0.
 Непрерывность работы с DC-SCM 2.0
Непрерывность работы с DC-SCM 2.0
Мы продолжаем развивать стандарт Data Center Secure Control Module 2.0 (DC-SCM 2.0). Разделяя функции управления и безопасности от материнской платы, мы гарантируем, что «мозг» системы безопасности сервера останется модульным и защищенным.
В модуле DC-SCM размещены наши наиболее важные компоненты:
- Базовая система ввода-вывода (BIOS)
- Контроллер управления материнской платой (BMC)
- Аппаратный корень доверия (HRoT) и TPM (Infineon SLB 9672)
- Два флэш-чипа BMC/BIOS для резервирования
Почему мы продолжаем работу над DC-SCM 2.0
Решение сохранить эту архитектуру для 13-го поколения обусловлено доказанным повышением уровня безопасности, которое мы наблюдали в предыдущем поколении. Перенеся эти функции в отдельный модуль, мы сохраняем:
- Быстрое восстановление: Двойное резервирование образов позволяет практически мгновенно восстановить прошивку BIOS/UEFI и BMC в случае обнаружения случайного повреждения или вредоносного обновления.
- Физическая прочность: В шасси 13-го поколения механизм обнаружения вторжений также смещен дальше от плоского края шасси, что затрудняет физический перехват.
- Шифрование PCIe: В дополнение к технологии TSME (Transparent Secure Memory Encryption) для шифрования данных между процессором и памятью, которая была включена еще в наших платформах 10-го поколения, процессор AMD Turin 9965 для 13-го поколения расширяет шифрование на трафик PCIe, что гарантирует защиту данных при передаче по каждой шине в системе.
- Операционная согласованность: Использование стека управления Gen 12 означает, что наши процедуры аудита безопасности, развертывания, предоставления ресурсов и операционных стандартов остаются полностью совместимыми.
Power

По мере модернизации вычислительных и сетевых возможностей серверов, их энергопотребление, естественно, также увеличилось. Серверы 13-го поколения оснащены более мощными блоками питания для обеспечения необходимой мощности.
Переход к мощности 1300 Вт
В то время как наши узлы 12-го поколения комфортно работали с резервным источником питания 800 Вт 80 PLUS Titanium CRPS (Common Redundant Power Supply), спецификация 13-го поколения требует более мощного источника питания. Мы выбрали резервный источник питания 80 PLUS Titanium CRPS мощностью 1300 Вт.
Потребляемая мощность процессоров Gen 13 в типичном режиме работы выросла до 850 Вт, что на 250 Вт больше, чем 600 Вт у Gen 12. Основными факторами являются процессор с TDP 500 Вт (вместо 400 Вт), удвоение объема памяти и дополнительный NVMe-накопитель.
Почему 1300 Вт вместо 1000 Вт? В существующей экосистеме блоков питания отсутствуют жизнеспособные высокоэффективные варианты мощностью 1000 Вт. Для обеспечения надежности цепочки поставок мы перешли к следующему отраслевому стандарту — 1300 Вт.
Регламент ЕС Lot 9 требует, чтобы серверы, развертываемые в Европейском Союзе, имели блоки питания с КПД при нагрузке 10%, 20%, 50% и 100%, равным или превышающим пороговое значение, указанное в регламенте. Это пороговое значение соответствует требованиям программы сертификации блоков питания 80 PLUS, предусматривающим использование блоков питания титанового класса. Для Gen 13 мы выбрали блоки питания титанового класса, чтобы обеспечить полное соответствие требованиям EU Lot 9 и гарантировать возможность развертывания серверов в наших европейских центрах обработки данных и за их пределами.
Тепловая конструкция: 2U снова приносит свои плоды.
Принятый нами в 12-м поколении форм-фактор 2U1N продолжает приносить свои плоды. В 13-м поколении используются 5 80-мм вентиляторов (против 4 в 12-м поколении) для компенсации возросшей тепловой нагрузки от процессора мощностью 500 Вт. Больший объем вентиляторов в сочетании с характеристиками воздушного потока в 2U-корпусе означает, что вентиляторы работают значительно ниже максимального рабочего цикла при типичных температурах окружающей среды, поддерживая энергопотребление вентиляторов в диапазоне < 50 Вт на вентилятор.
Поддержка ускорителя без дополнительных настроек

Сохранение модульности нашего парка серверов является ключевым требованием к их проектированию. Это требование позволило Cloudflare быстро модернизировать и развернуть графические процессоры по всему миру более чем в 100 городах в 2024 году. В 13-м поколении мы продолжаем поддерживать высокопроизводительные дополнительные карты PCIe.
В 13-м поколении обновлена компоновка корпуса в форм-факторе 2U, адаптированная для поддержки более высоких требований к питанию и теплоотводу. Если в 12-м поколении использовалась только одна двухслотовая видеокарта, то архитектура 13-го поколения теперь поддерживает две двухслотовые карты PCIe.
Стартовая площадка для масштабирования Cloudflare и выведения его на новый уровень.
Каждое поколение серверов Cloudflare — это попытка сбалансировать противоречащие друг другу ограничения: производительность против энергопотребления, емкость против стоимости, гибкость против простоты. Серверы 13-го поколения имеют вдвое больше ядер, вдвое больший объем памяти, вчетверо большую пропускную способность сети, в 1,5 раза больший объем хранилища и обеспечивают перспективность для развертывания в ускоренном режиме — и все это при одновременном снижении общей стоимости владения и сохранении надежного набора функций управления и уровня безопасности, которые требуются нашему глобальному парку серверов.
Серверы 13-го поколения полностью сертифицированы и будут развернуты для обработки миллионов запросов в глобальной сети Cloudflare в более чем 330 городах. Как всегда, стремление Cloudflare к максимально эффективному предоставлению услуг в Интернете на этом не заканчивается. По мере начала развертывания 13-го поколения мы планируем архитектуру для 14-го поколения.
Если вас вдохновляет возможность внести свой вклад в создание лучшего интернета, присоединяйтесь к нам. Мы набираем сотрудников
www.cloudflare.com/careers/jobs/