Введение
Введение
Сегодня мы наблюдаем тенденцию к ежегодному непрерывному росту количества и мощности DDoS-атак. Это негативно сказывается на доступности как публичных, так и корпоративных сервисов. Последствия для компаний могут быть разными — от финансовых потерь и утечек данных до репутационного ущерба.
Что такое DDoS
Более 36 000 клиентов Selectel генерируют сетевой трафик объемом свыше 500 Гбит/с. Уникальные данные, которые мы получаем в ходе анализа атак на наши сервисы и проекты клиентов, позволяют оценить ландшафт угроз для облачной инфраструктуры.
Мы в Selectel собрали аналитический отчет о DDoS-атаках, отраженных с помощью бесплатного сервиса защиты за первое полугодие 2026. Данные позволяют оценить динамику и основные характеристики DDoS в разрезе облачной инфраструктуры, скорректировать настройки своих IT-систем для защиты.
Ключевые выводы
В первом полугодии 2026 года мы фиксируем рекордные показатели DDoS-активности злоумышленников: растет количество атак, увеличивается их мощность, а отдельные кампании могут продолжаться сотни часов.
Если еще некоторое время назад такие атаки воспринимались скорее как исключение, то сегодня они становятся постоянным фактором риска для цифровых сервисов. Поэтому защита от DDoS должна быть обязательной мерой в процессе обеспечения доступности сервисов 24/7 и устойчивости IT-инфраструктуры, а не временным решением, которое подключается только в момент атаки.
Антон Ведерников, Руководитель направления продуктовой безопасности
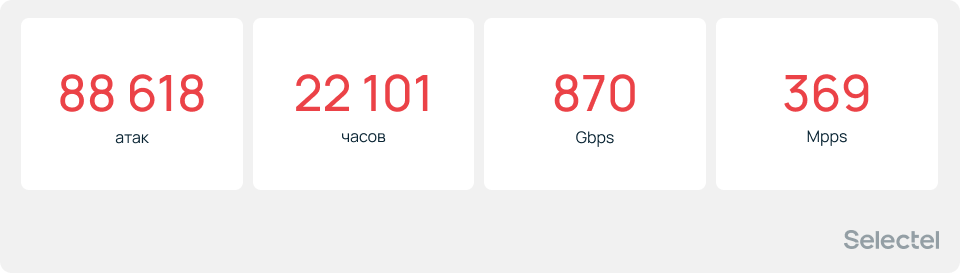
С января по июль 2026 года мы отразили 88 618 атак общей продолжительностью 22 101 час. Максимальный объем составил 870 Гбит/с, а скорость — 369 млн пакетов в секунду. В среднем, системы защиты Selectel отражали порядка 14 770 атак ежемесячно. А самыми популярными типами DDoS остаются TCP PSH/ACK Flood и TCP SYN Flood, которые занимают порядка 58% от общего количества атак.
Детальную аналитику с ключевыми показателями за предыдущие периоды вы можете посмотреть в отчетах:
Наиболее мощные атаки пришлись на январь, а самые продолжительные зафиксировали как в начале, так и в конце периода — в январе и июне соответственно. Средняя общая длительность атак на одного клиента достигает 13 часов, а максимальное время, в течение которого один клиент находился под атакой, составляет 795 часов.
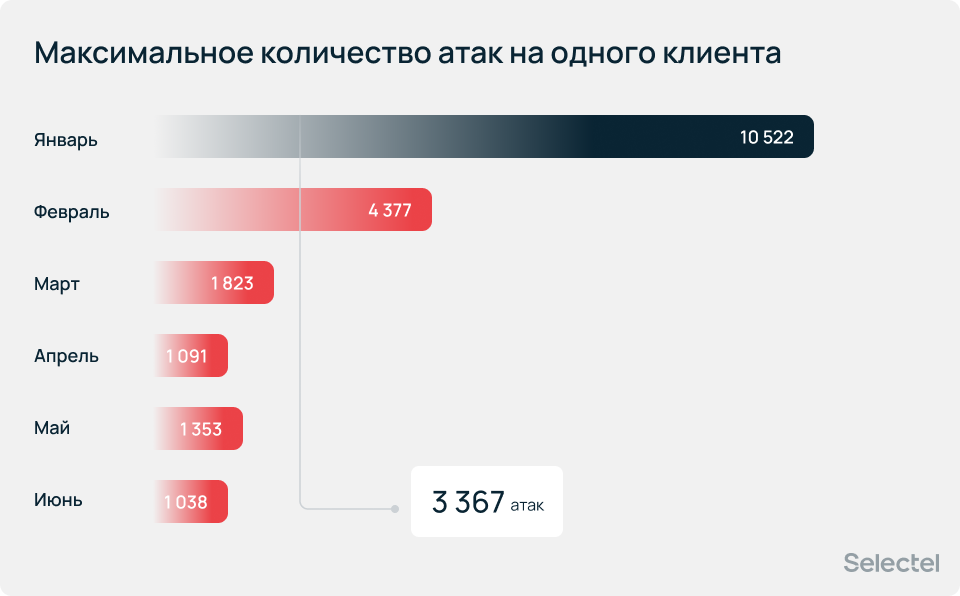
Максимальное количество атак за месяц на одного клиента впервые перешагнуло пятизначное число — 10 522 инцидента. Подобный объем невозможно отбить вручную, поэтому базовая бесплатная защита — важная часть услуг облачного провайдера.
В конце 2025 года, подводя итоги года, мы прогнозировали, что в 2026 будет расти доля атак на экосистемы — в том числе на поставщиков вычислительных облаков. Сегодня мы видим подтверждение этого тренда: растут не только количество, мощность и продолжительность атак, что отражают как данные CURATOR, так и наблюдения Selectel, но и меняется сама природа угроз.
По нашим наблюдениям, злоумышленники все чаще используют более крупные ботнеты и переходят от разовых инцидентов к длительным атакам и давлению. В таких условиях конкурентным преимуществом становится уже не только способность выдержать кратковременный всплеск рекордной мощности, а способность обеспечивать непрерывную работу цифровых сервисов в условиях постоянной атакующей активности.
Эдгар Микаелян, Директор по клиентским решениям, CURATOR
Динамика изменения показателей
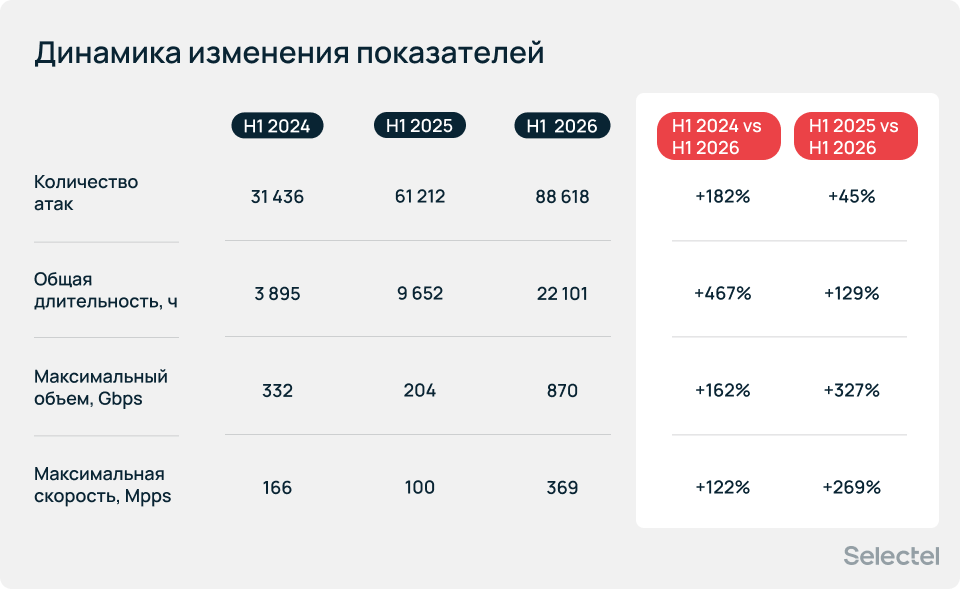
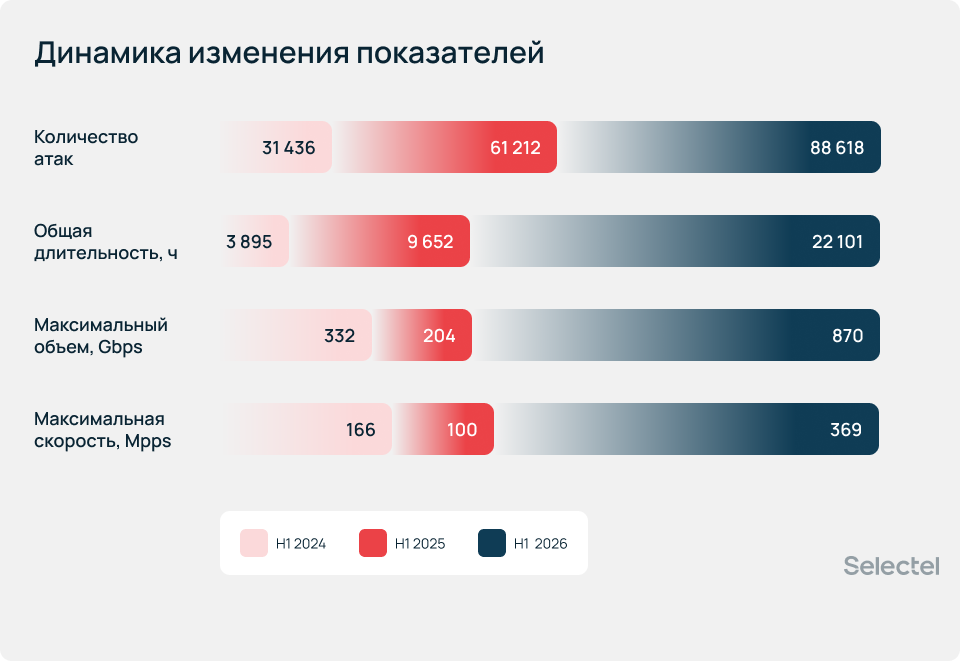
По данным StormWall, во втором квартале 2026 года количество DDoS-атак в мире выросло на 108% по сравнению с тем же периодом прошлого года, а число атак мощностью свыше 2 Тбит/с увеличилось в 3,5 раза. В России цифры чуть ниже, но гораздо важнее другое: сам по себе рост числа и мощности DDoS-атак уже стал нормой. Значимо также и то, как меняются сами угрозы и тактики злоумышленников.
В первой половине 2026 года киберпреступники стали заметно чаще использовать более сложные сценарии атак. Они комбинируют объемные атаки на разных уровнях инфраструктуры и динамически меняют параметры трафика «в процессе». При этом если раньше мы в основном наблюдали разовые всплески трафика, то сейчас все чаще сталкиваемся с длительными повторяющимися и целенаправленными атаками. Во многих случаях цель злоумышленников — не только вывести сервисы из строя, но и максимально увеличить операционные и финансовые издержки атакуемой компании.
Рамиль Хантимиров, CEO и сооснователь компании, StormWall
Аналитика атак
Количество
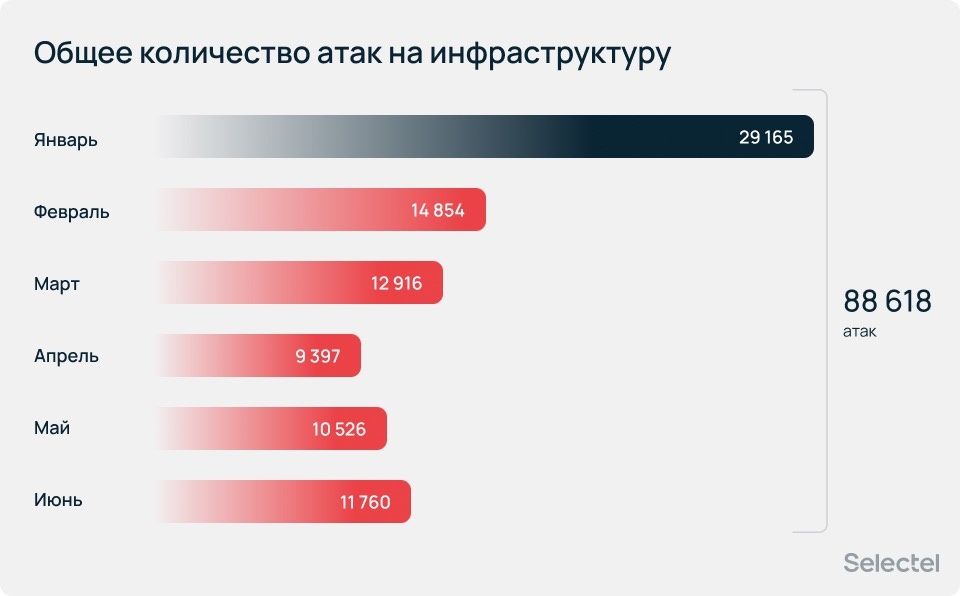
За период с января по июль 2026 года бесплатным сервисом защиты от DDoS-атак Selectel было отражено 88 618 атак.
К концу первого полугодия 2026 года, по данным StormWall, финансовый сектор впервые стал наиболее атакуемой отраслью, на которую пришлось 26% всех DDoS-атак в мире, обогнав телеком-сферу (22%). Злоумышленники все чаще выбирают цели, где даже кратковременный простой способен привести к серьезным финансовым потерям.
Рамиль Хантимиров, CEO и сооснователь компании, StormWall
Наибольшее число инцидентов пришлось на январь (29 165 атак). В среднем мы отражали 14 770 атак в месяц и 44 — на каждого атакованного клиента.
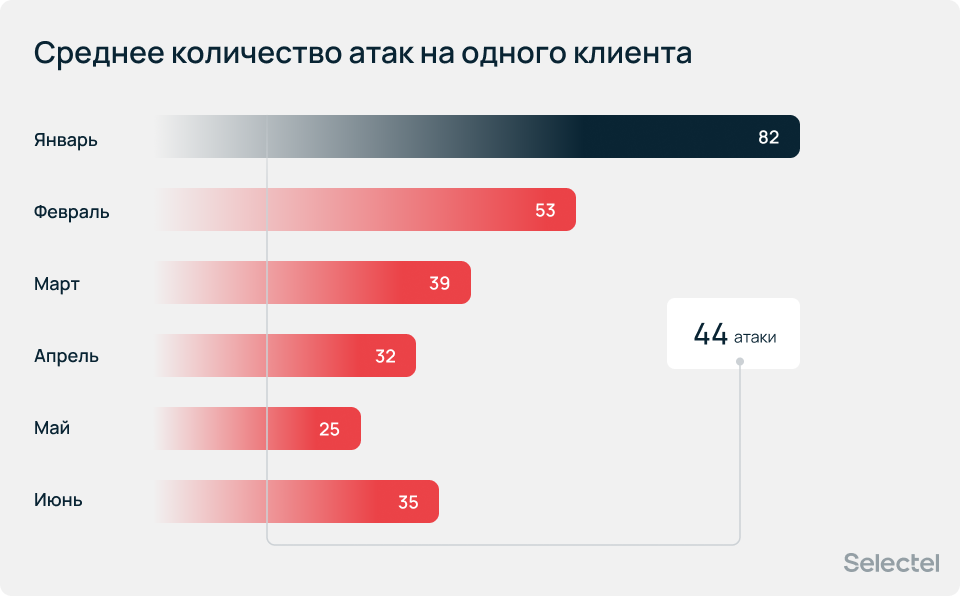
Максимальное количество атак на одного клиента в первом полугодии 2026 года изменялось в десятки раз и в среднем составляло 3 367 инцидент. А наибольшее значение пришлось также на январь — 10 522 инцидента.
Рост числа атак — это лишь внешнее проявление более серьезного процесса. В CURATOR мы наблюдаем качественное изменение всей экосистемы DDoS-угроз: если раньше злоумышленники обычно стремились вывести из строя отдельный сервис, то сегодня они все чаще используют масштабные распределенные ботнеты, способные одновременно атаковать целые облачные платформы и элементы интернет-инфраструктуры. Уже в первом квартале 2026 года мы зафиксировали несколько атак мощностью свыше 1 Тбит/с, а во втором квартале их число продолжило расти. Годом ранее подобные инциденты были скорее исключением.
Эдгар Микаелян, Директор по клиентским решениям, CURATOR
Количество атак действительно увеличилось: в 2025 мы зафиксировали суммарно 2 095 165 атак на уровне L7, тогда как только за первые полгода 2026 на уровне приложений их количество составило 1 538 395, то есть порядка 75% от показателя за весь прошлый год.
Дмитрий Никонов, Директор по продуктам, DDoS-Guard
Мощность
Основные характеристики атаки, определяющие ее мощность на сетевом и транспортном уровнях, — это объем и скорость.
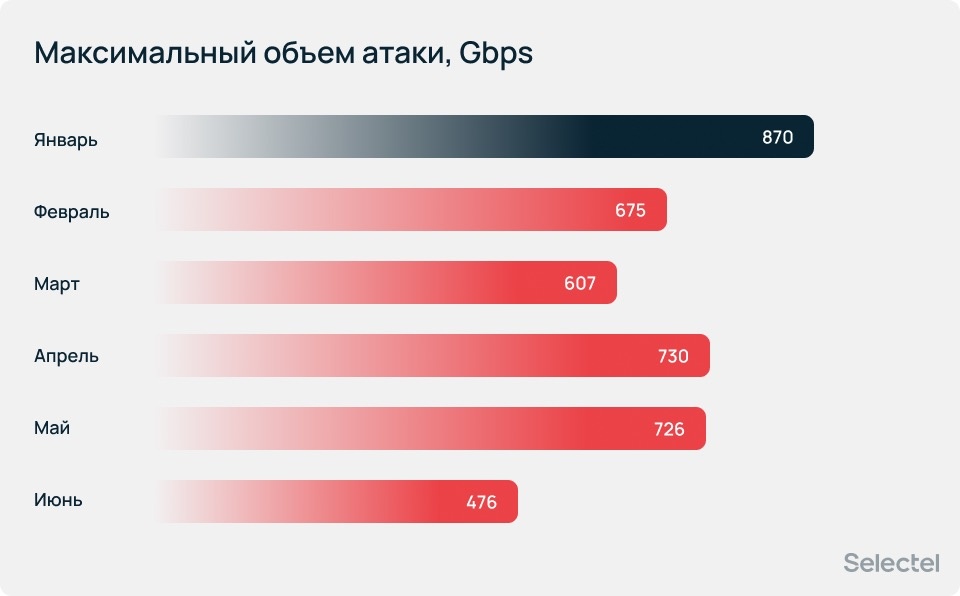
Атаки большого объема, измеряемого в количестве переданных бит за одну секунду, направлены на переполнение полосы пропускания. При этом рекордный объем был достигнут в январе и составил 870 Гбит/с.
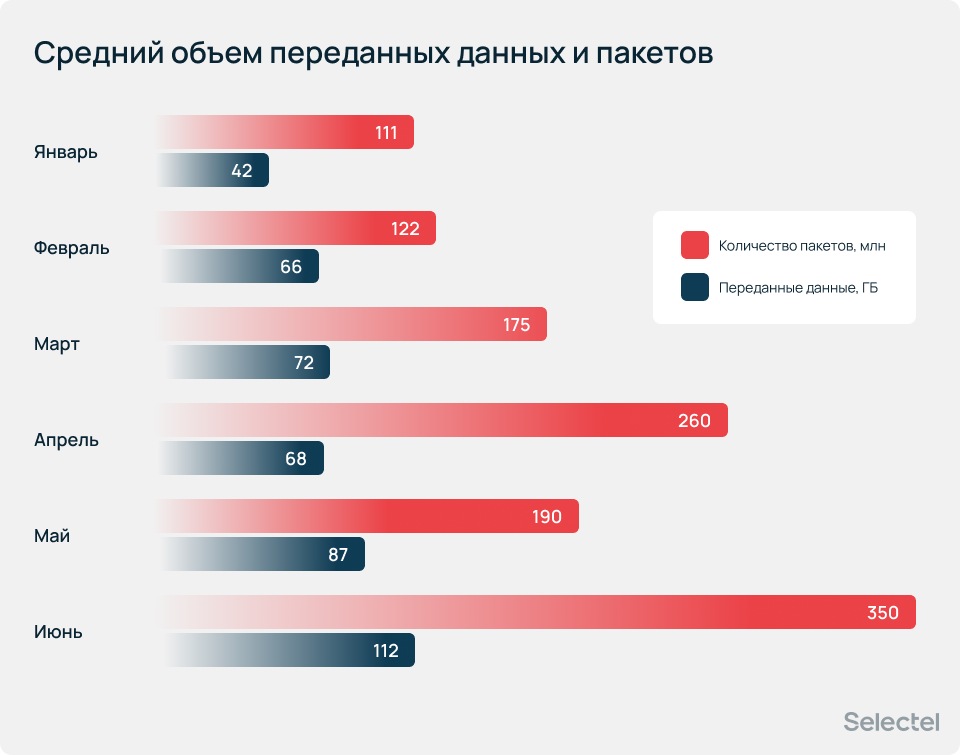
В июне зафиксировали наибольшее значение среднего объема переданных данных за атаку — 112 ГБ, а также максимальное количество переданных пакетов — 350 млн.
Атаки с большой скоростью направлены на исчерпание вычислительных ресурсов сетевого оборудования.
В первом квартале 2026 мы в DDoS-Guard зафиксировали превышение прошлогоднего рекорда мощности атак (600 тыс запросов в секунду против 490 тыс). Во втором квартале также наблюдался стремительный и ощутимый (более чем на 200%) рост среднего числа атак в час (469 против 230 — максимума за весь 2025), что при пересчете на сутки выглядит еще более внушительно — 11,2 тысячи атак в день против 5,3 тысячи всего год назад.
Дмитрий Никонов, Директор по продуктам, DDoS-Guard
Самая скоростная атака была зафиксирована в апреле и достигла 369 миллионов пакетов в секунду. Это почти в 2,4 раза больше, чем максимальная скорость атаки в январе.
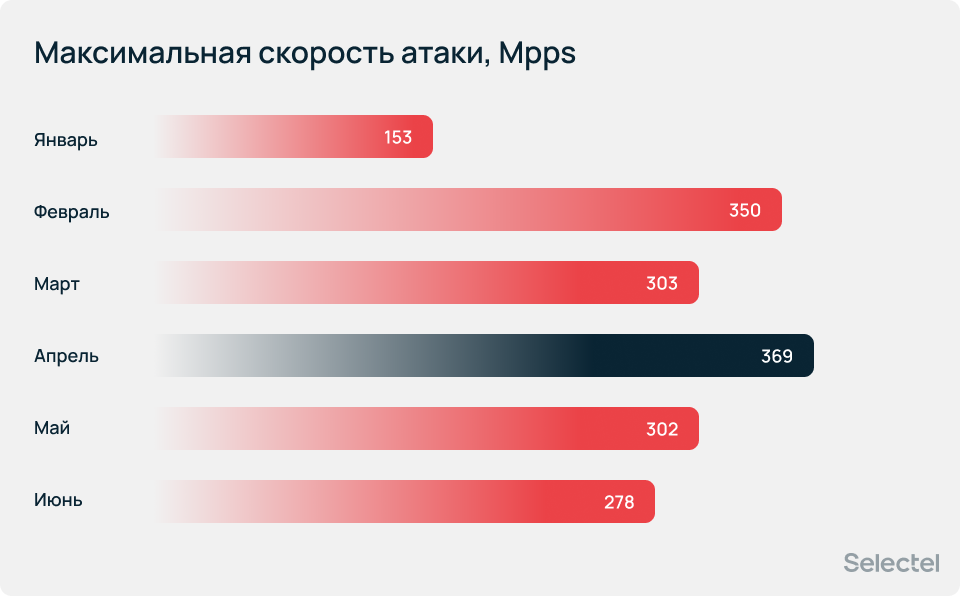
Рост пиковой мощности атак следует не только из увеличения числа зараженных устройств. Мы наблюдаем появление ботнетов нового поколения, которые способны гибко менять параметры атаки, распределять нагрузку между различными источниками и эффективнее использовать собственные ресурсы.
По нашим данным, только за второй квартал 2026 года количество инцидентов мощностью свыше 2 Тбит/с выросло в 3,5 раза, а средняя мощность атак на телеком-сектор увеличилась сразу в 5 раз. Именно поэтому сегодня даже очень крупные и, казалось бы, уже защищенные компании все чаще сталкиваются с терабитными атаками. И они постепенно становятся нормой.
Эдгар Микаелян, Директор по клиентским решениям, CURATOR
Продолжительность
Суммарная продолжительность атак с января по июль 2026 года составила 22 101 час. Почти такое же количество часов мы отражали атаки за весь 2025 год.
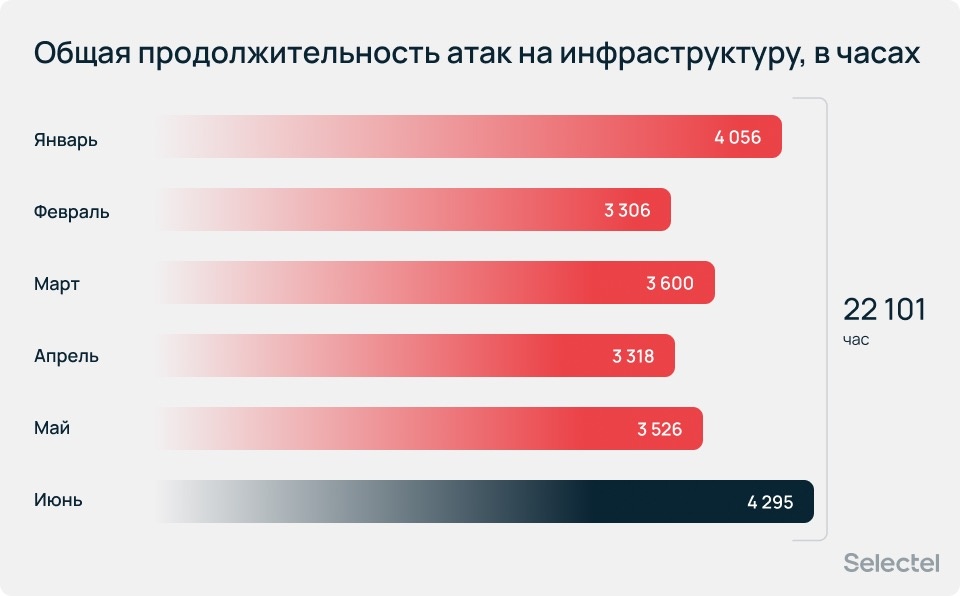
Наибольшая продолжительность атак зарегистрирована в июне. Она достигает 4 295 часов. При этом значительных изменений показателя от месяца к месяцу нет.
Средняя длительность атаки росла на протяжении всего периода от 8 минут в январе до 22 минут в июне, а максимальная длительность одной атаки зафиксирована в мае — и составила 172 часа, что в 5,5 раз больше значения марта.
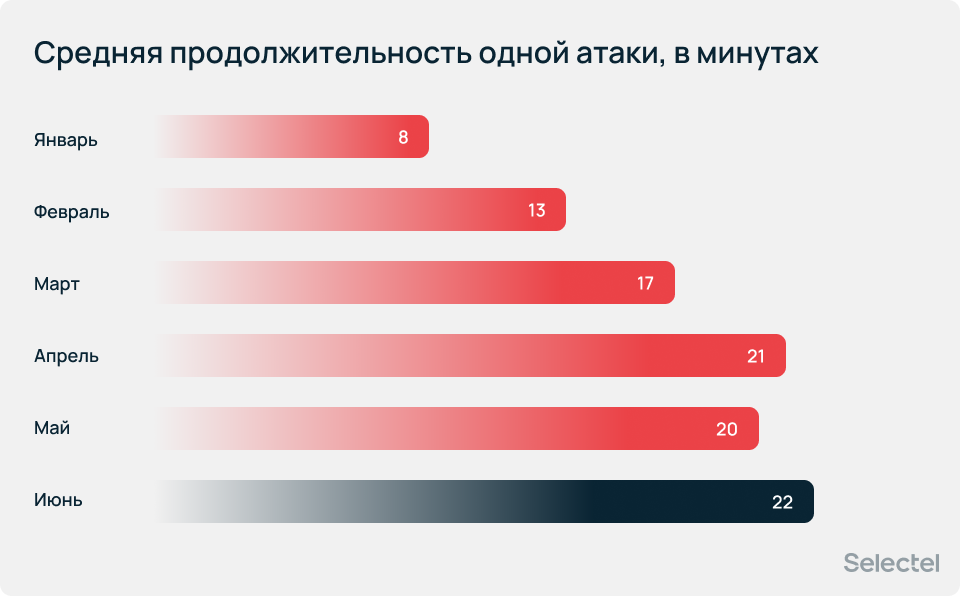
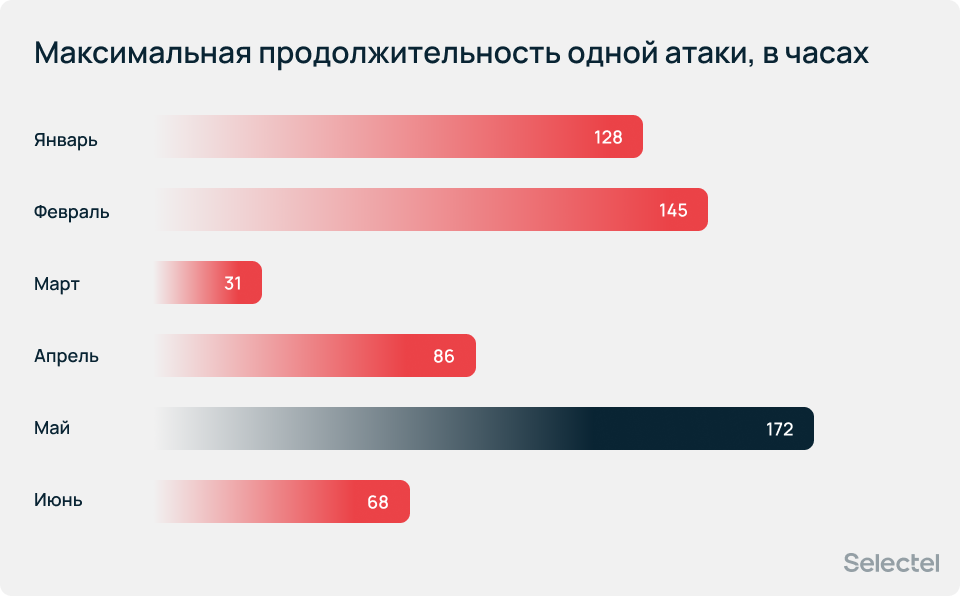
Средняя общая продолжительность атак на одного клиента не превышала 13 часов.
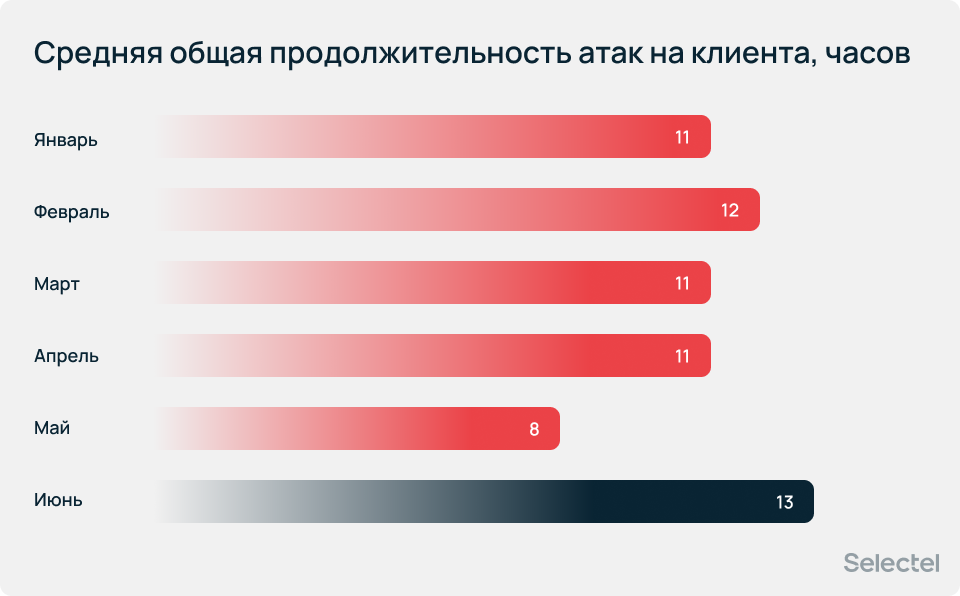
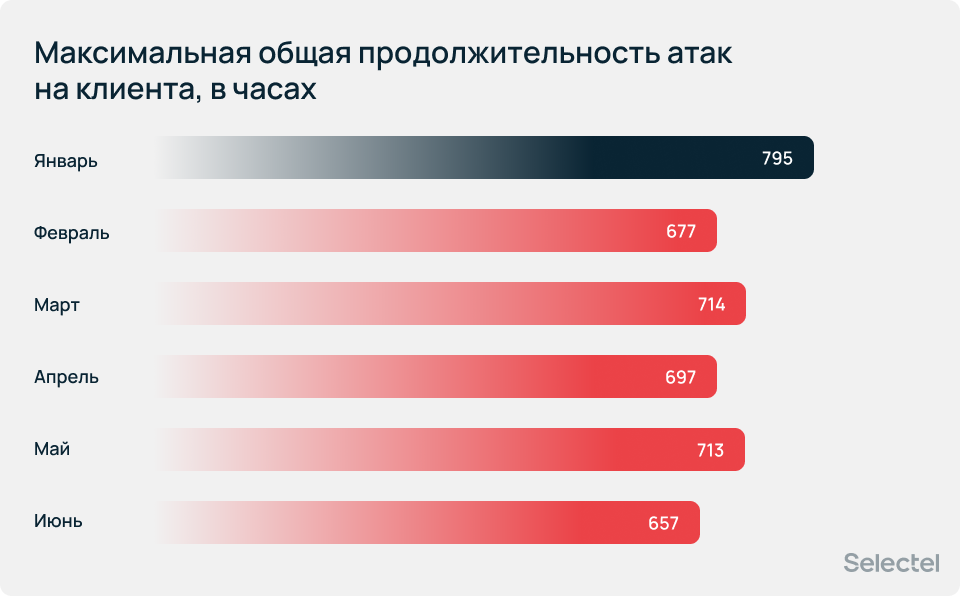
Максимальная общая продолжительность атак на одного клиента превысила 795 часов за один календарный месяц.
 Типы атак
Типы атак
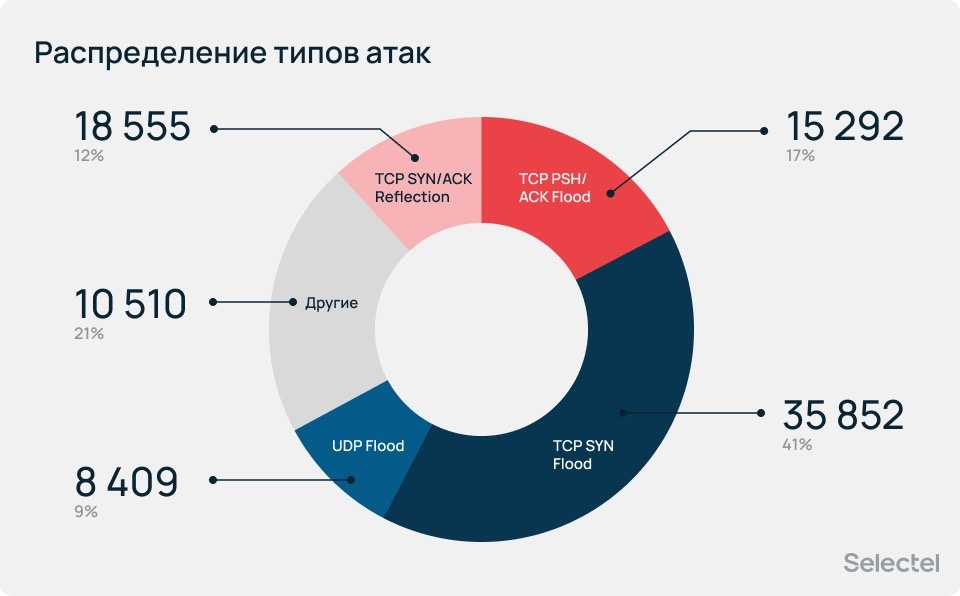
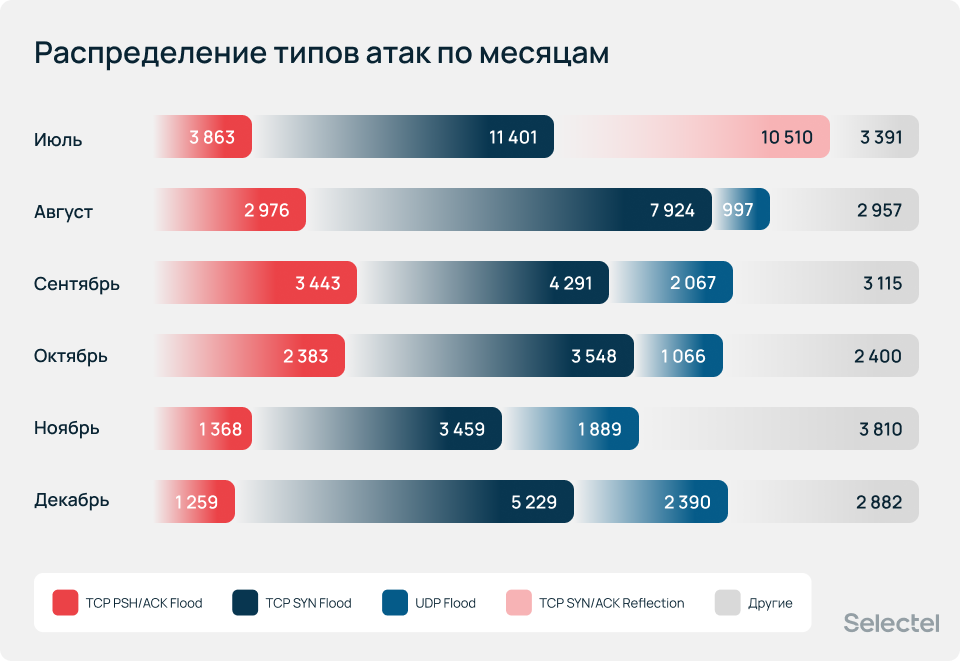
Распределение типов атак по месяцам менялось значительно — к июню атаки стали более разнообразными и доля категории «Другие» увеличилась с 11,6% в январе до 36,2% в мае. При этом самыми популярными были и остаются атаки типа TCP SYN Flood и TCP PSH/ACK Flood. Они занимают 57,8% от общего количества атак.
Также постепенно увеличивается доля атак UDP Flood, которая составила 9,5%. Аномально высокую долю заняли атаки типа TCP SYN/ACK Reflection (36% в январе и 11,9% за весь период), которые были зафиксированы только в январе и в остальные периоды не повторялись.
- TCP SYN Flood реализуется путем отправки множества SYN-запросов на подключение, при этом ответные SYN+ACK пакеты, отправленные сервером, игнорируются. Это приводит к тому, что на сервере появляется очередь из полуоткрытых соединений, которые не позволяют установить новые легитимные подключения, что приводит к невозможности подключения пользователей или длительному ожиданию.
- TCP PSH/ACK Flood реализуется путем отправки множества фальсифицированных ACK-пакетов на определенные или случайные номера портов атакуемого узла, которые не принадлежат ни одной из сессий в списке соединений. Тот, в свою очередь, вынужден тратить вычислительные ресурсы на проверку поддельных пакетов.
- UDP Flood реализуется путем отправки множества UDP-пакетов на случайные или определенные порты атакуемого узла. Поскольку протокол UDP работает без установления соединения, сервер не создает очередь полуоткрытых сессий, но вынужден обрабатывать каждый входящий пакет на уровне операционной системы.
- TCP SYN/ACK Reflection реализуется путем отправки множества SYN-запросов на адреса сторонних легитимных серверов (отражателей), при этом в качестве IP-адреса отправителя подделывается IP-адрес жертвы. Сторонние серверы, следуя логике протокола TCP, отправляют ответные пакеты SYN+ACK не атакующему, а на адрес жертвы.
 Инсайты от партнеров
Инсайты от партнеров
Рост распределенности атак
Статистика DDoS-Guard показывает стремительный рост такого важного параметра мощности DDoS-атак как распределенность, то есть числа источников атакующего трафика.
В 2025 году максимальное количество уникальных IP в рамках одной атаки превышало 2 млн, но уже в первом квартале 2026 года в рамках одной атаки мы зафиксировали более 3,1 млн уникальных адресов. То есть, рост распределенности DDoS всего за несколько месяцев составил 50% — это самый высокий показатель за время наблюдений.
Дмитрий Никонов, Директор по продуктам, DDoS-Guard
Применение ИИ в DDoS
Дополнительным фактором развития DDoS-атак становятся автоматизация. По оценке StormWall, если в первом квартале 2026 года около 22% DDoS-атак уже использовали инструменты искусственного интеллекта, то во втором квартале их доля выросла примерно до 34%. Такие решения позволяют быстрее адаптировать параметры трафика, имитировать поведение легитимных пользователей и оперативно менять сценарий атаки в ответ на действия защитных систем. В результате порог входа снижается, а сложные DDoS-атаки становятся доступнее для более широкого круга злоумышленников.
Рамиль Хантимиров, CEO и сооснователь компании, StormWall
Методология
Основной источник данных для отчета — системы защиты от DDoS-атак, которые мы используем на уровне сетевой инфраструктуры дата-центров Selectel. Весь входящий трафик проходит через узлы очистки и анализируется на наличие вредоносной активности.
Нелегитимные запросы отбрасываются — поступает только очищенный входящий трафик. Обладая информацией об исходящем трафике, система использует дополнительные алгоритмы, которые повышают точность фильтрации при TCP-атаках до 99,9%.
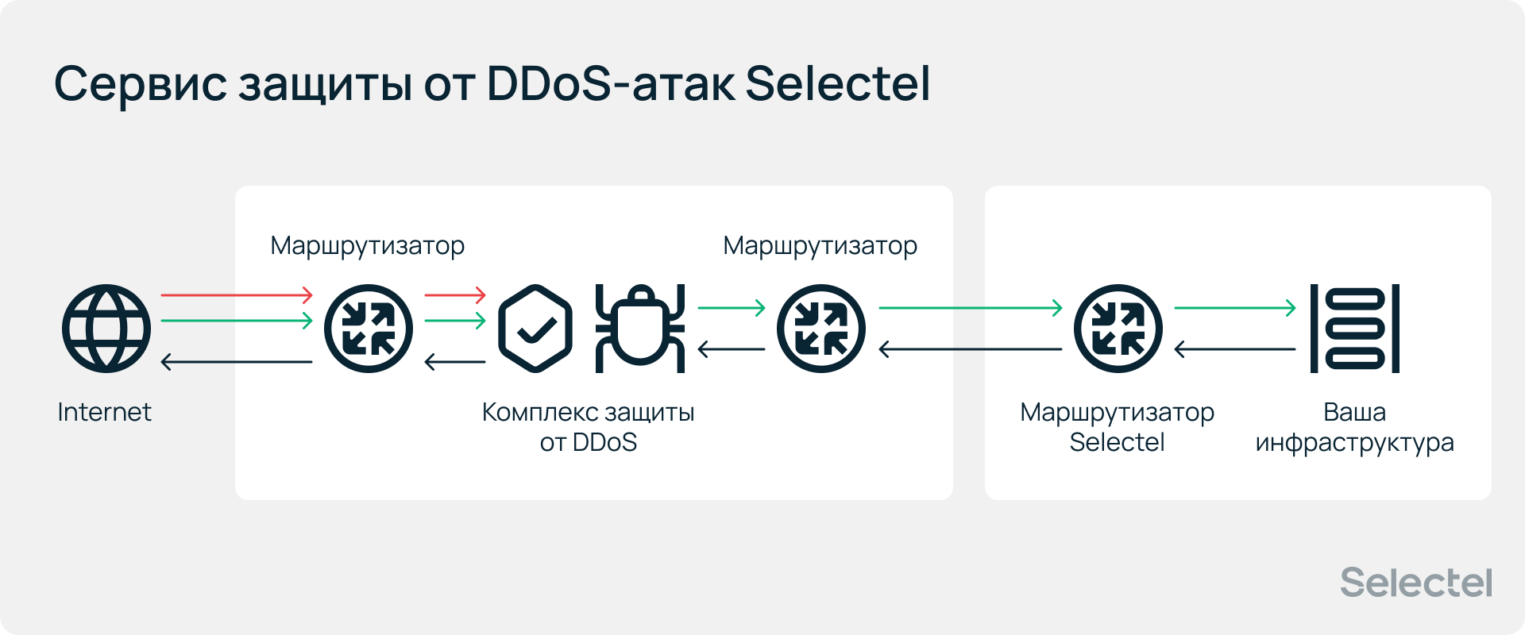 Бесплатный сервис защиты от DDoS-атак
Бесплатный сервис защиты от DDoS-атак работает при использовании облака Selectel, платформенных сервисов и выделенных серверов, включая аттестованные сегменты.
Сервис обеспечивает защиту на сетевом (L3) и транспортном (L4) уровнях от различного типа атак:
- атак с отражением на основе UDP (DNS, NTP, memcache и пр.);
- атак с использованием фрагментированного IP-трафика;
- TCP SYN/RST/PSH flood;
- различных типов UDP flood и ICMP flood.
Отдельной атакой считается вредоносная активность, которая соответствует ряду критериев:
- направлена на конкретный IP-адрес,
- относится к одному типу атак,
- имеет перерывы в активности не более трех минут.
Пример 1. Атаки UDP Flood на один и тот же IP-адрес с промежутком в минуту будут объединены в одну. В течение трех минут после прекращения активности атака будет считаться завершенной.
Пример 2. Одновременно один и тот же IP-адрес атакуют с помощью Flood- и Reflection-атак. Активность продолжается в течение семи минут. В данном случае будет зафиксировано две атаки.