Запуск серверов Cloudflare 13-го поколения: обмен кэша на ядра для двукратного увеличения производительности периферийных вычислений

Два года назад Cloudflare развернула наш парк серверов 12-го поколения на базе процессоров AMD EPYC Genoa-X с их огромным 3D V-кэшем. Эта архитектура с большим объемом кэша идеально подходила для нашего уровня обработки запросов, на тот момент FL1. Но при оценке оборудования следующего поколения мы столкнулись с дилеммой — процессоры, обеспечивающие наибольший прирост пропускной способности, сопровождались значительным уменьшением объема кэша. Наш устаревший программный стек не был оптимизирован для этого, и потенциальные преимущества в пропускной способности ограничивались растущей задержкой.
В этом блоге описывается, как переход на FL2 — переписанный на Rust основной слой обработки запросов Cloudflare — позволил нам продемонстрировать весь потенциал Gen 13 и добиться повышения производительности, которое было бы невозможно на нашей предыдущей платформе. FL2 устраняет зависимость от большего кэша, позволяя масштабировать производительность в зависимости от количества ядер, сохраняя при этом наши соглашения об уровне обслуживания (SLA). Сегодня мы с гордостью объявляем о запуске Cloudflare Gen 13 на базе серверов AMD EPYC™ 5-го поколения Turin, работающих под управлением FL2, эффективно захватывая и масштабируя производительность на периферии сети.
Что предлагает AMD EPYCTurin?
- Процессоры AMD EPYC 5-го поколения на базе архитектуры Turin обеспечивают не только увеличение количества ядер. Архитектура улучшает работу серверов Cloudflare по многим параметрам.
- Увеличено в 2 раза количество ядер: до 192 ядер против 96 ядер у 12-го поколения, при этом технология SMT обеспечивает 384 потока.
- Улучшенная производительность на такт: архитектурные улучшения Zen 5 обеспечивают более высокую частоту инструкций за цикл по сравнению с Zen 4.
- Повышенная энергоэффективность: несмотря на большее количество ядер, Turin потребляет до 32% меньше ватт на ядро по сравнению с Genoa-X.
- Поддержка DDR5-6400: более высокая пропускная способность памяти для обеспечения работы всех этих ядер.
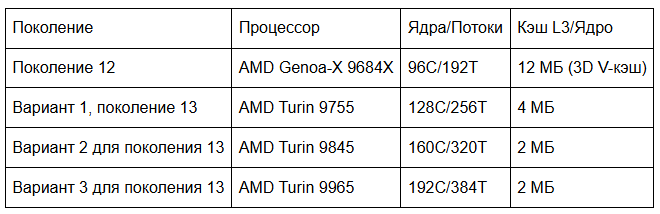
Однако процессоры Turin с высокой плотностью OPN намеренно идут на компромисс: приоритет отдается пропускной способности, а не кэшу на ядро. Наш анализ всей линейки Turin выявил этот сдвиг. Например, сравнение процессоров Turin с самой высокой плотностью OPN с нашими процессорами Gen 12 Genoa-X показывает, что 192 ядра Turin используют 384 МБ кэша L3. Это оставляет каждому ядру доступ всего к 2 МБ, что составляет одну шестую часть от объема кэша Gen 12. Для любой рабочей нагрузки, которая в значительной степени зависит от локальности кэша, как в нашем случае, это сокращение представляло серьезную проблему.
Диагностика проблемы с помощью счетчиков производительности.
Для нашего слоя обработки запросов FL1, основанного на NGINX и LuaJIT, это сокращение кэша представляло собой серьезную проблему. Но мы не просто предположили, что это будет проблемой; мы провели измерения.
В ходе оценки производительности процессоров 13-го поколения мы собрали данные счетчиков производительности и профилирования процессора, чтобы точно определить, что происходит «под капотом», используя инструмент AMD uProf. Полученные данные показали:
- По сравнению с серверами 12-го поколения, оснащенными 3D V-кэш-процессорами, частота промахов в кэше L3 значительно возросла.
- Задержка при выборке данных из памяти определяла основное время обработки запроса, поскольку данные, которые ранее хранились в L3, теперь требовали обращения к DRAM.
- Увеличение задержки возрастало по мере роста загрузки ЦП и ухудшения конкуренции за кэш.
Попадание в кэш L3 завершается примерно за 50 циклов; промахи в кэше L3, требующие доступа к DRAM, занимают более 350 циклов, что на порядок больше. При в 6 раз меньшем объеме кэша на ядро, FL1 на процессорах 13-го поколения обращался к памяти гораздо чаще, что приводило к задержкам.
Компромисс: задержка против пропускной способности
Наши первоначальные тесты, проведенные на FL1 на процессорах 13-го поколения, подтвердили то, что уже указывали счетчики производительности. Хотя процессор Turin мог обеспечить более высокую пропускную способность, это сопровождалось значительными задержками.
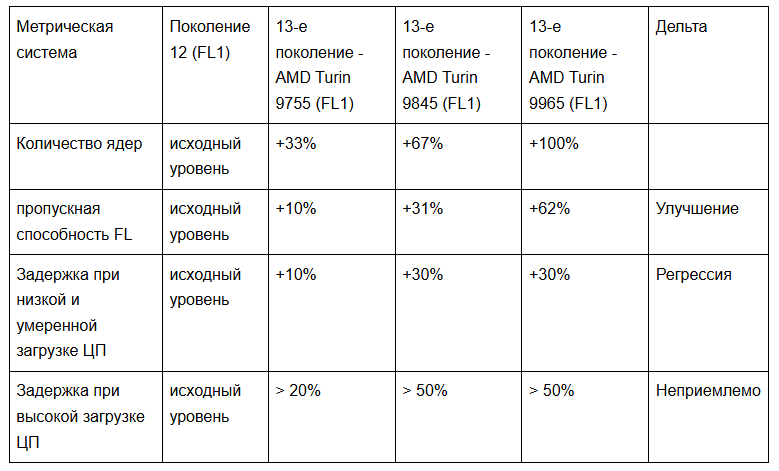
Оценочный сервер Gen 13 с процессором AMD Turin 9965, показавший 60% прирост пропускной способности, оказался впечатляющим, а повышение производительности обеспечило наибольшее улучшение общей стоимости владения (TCO) для Cloudflare.
Однако увеличение задержки более чем на 50% неприемлемо. Рост задержки обработки запросов напрямую повлияет на качество обслуживания клиентов. Мы столкнулись со знакомым вопросом об инфраструктуре: принять ли решение без выгоды с точки зрения совокупной стоимости владения, смириться с увеличением задержки или найти способ повысить эффективность без увеличения задержки?
Постепенное повышение производительности за счет оптимизации параметров.
Чтобы найти путь к оптимальному результату, мы сотрудничали с AMD для анализа данных Turin 9965 и проведения целенаправленных экспериментов по оптимизации. Мы систематически тестировали множество конфигураций:
- Настройка оборудования: корректировка аппаратных средств предварительной выборки и фильтров зондирования Data Fabric (DF), показавшая лишь незначительные улучшения.
- Увеличение количества рабочих: запуск большего количества рабочих уровня FL1, что повысило производительность, но привело к перераспределению ресурсов из других производственных служб.
- Привязка и изоляция ЦП: Настройка конфигураций изоляции рабочих нагрузок для поиска оптимального сочетания, с ограниченным успехом.
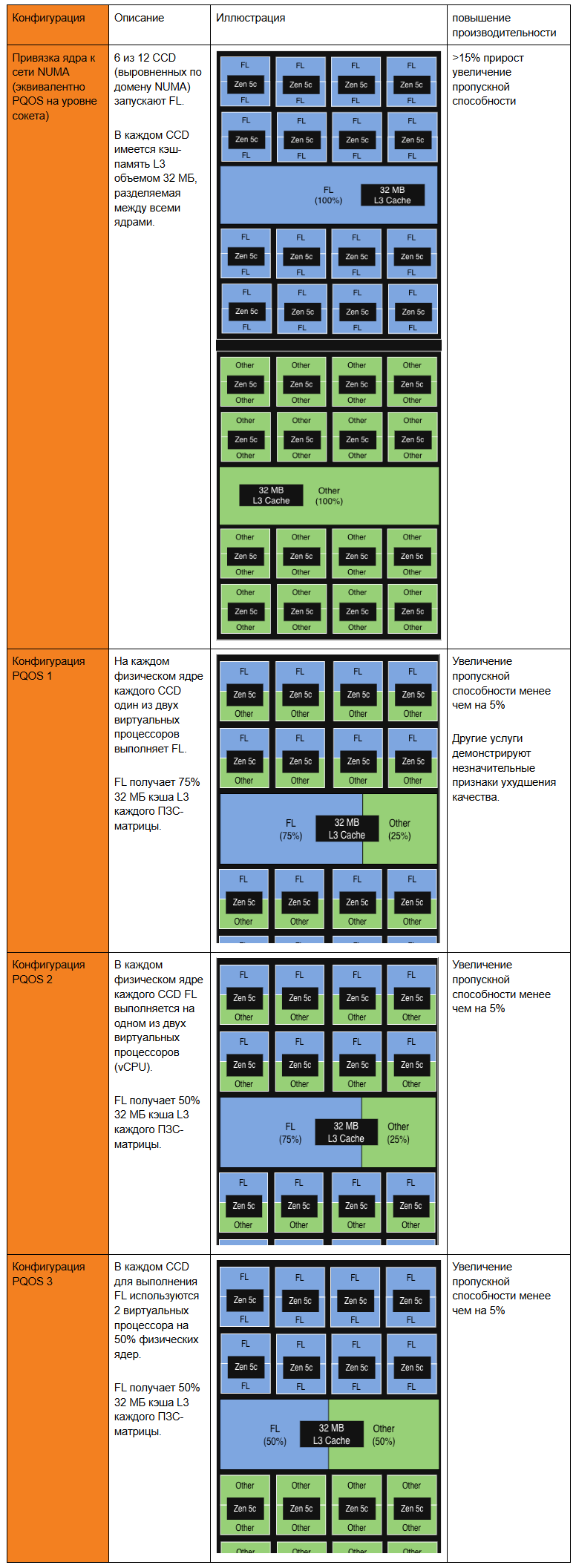
Конфигурация, которая в конечном итоге принесла наибольшую пользу, оказалась конфигурацией с поддержкой технологии AMD Platform Quality of Service (PQOS). Расширения PQOS позволяют осуществлять тонкую регулировку совместно используемых ресурсов, таких как кэш и пропускная способность памяти. Поскольку процессоры Turin состоят из одного кристалла ввода-вывода и до 12 кристаллов ядерных комплексов (CCD), каждый из которых использует кэш L3 на 16 ядрах, мы протестировали эту технологию. Вот как показали себя различные экспериментальные конфигурации.
Сначала мы использовали PQOS для выделения выделенной доли кэша L3 в рамках одного CCD для FL1, и прирост был минимальным. Однако, когда мы масштабировали концепцию до уровня сокета, выделив весь CCD исключительно для FL1, мы увидели значительный прирост пропускной способности при сохранении приемлемой задержки.
Возможность: работа над FL2 уже велась.
Настройка оборудования и конфигурация ресурсов обеспечили умеренный прирост производительности, но для того, чтобы по-настоящему раскрыть потенциал производительности архитектуры 13-го поколения, мы понимали, что нам придется переписать наш программный стек, чтобы коренным образом изменить способ использования системных ресурсов.
К счастью, нам не приходилось начинать с нуля. Как мы объявили во время Недели Дня рождения 2025 года, мы уже перестраивали FL1 с нуля. FL2 — это полная переработка нашего слоя обработки запросов на Rust, построенная на основе наших фреймворков Pingora и Oxy, заменяющая 15 лет кода NGINX и LuaJIT.
Проект FL2 не был инициирован для решения проблемы кэша 13-го поколения — он был обусловлен необходимостью повышения безопасности (безопасность памяти в Rust), ускорения темпов разработки (строгая модульная система) и повышения общей производительности (меньше ресурсов ЦП, меньше памяти, модульное выполнение).
Более чистая архитектура FL2, с улучшенными шаблонами доступа к памяти и меньшим количеством динамического выделения памяти, возможно, не будет зависеть от огромных кэшей L3 так, как это было в FL1. Это дало нам возможность использовать переход на FL2, чтобы доказать, можно ли реализовать прирост пропускной способности Gen 13 без увеличения задержки.
Проверка: FL2 на Gen 13
По мере развертывания FL2, показатели производительности наших серверов 13-го поколения подтвердили наши предположения.

Повышение эффективности работы нашей новой системы FL2 оказалось существенным еще до каких-либо оптимизаций. FL2 сократила задержку на 70%, что позволило нам повысить загрузку ЦП на процессорах 13-го поколения, строго соблюдая наши соглашения об уровне обслуживания (SLA) по задержке. В случае с FL1 это было бы невозможно.
Благодаря эффективному устранению узкого места в кэше, FL2 позволяет масштабировать пропускную способность линейно в зависимости от количества ядер. Влияние неоспоримо на высокопроизводительные процессоры AMD Turin 9965: мы добились двукратного прироста производительности, раскрыв истинный потенциал оборудования. Дальнейшая настройка системы позволит нам добиться еще большей мощности от нашего парка процессоров 13-го поколения.
Улучшение характеристик с появлением 13-го поколения.
Благодаря тому, что FL2 раскрыл огромный потенциал высокопроизводительных процессоров AMD Turin 9965 с большим количеством ядер, мы официально выбрали эти процессоры для развертывания в рамках 13-го поколения. Аппаратная квалификация завершена, и серверы 13-го поколения уже поставляются в больших объемах для поддержки нашего глобального развертывания.
Улучшения производительности
Влияние Gen 13 на бизнес
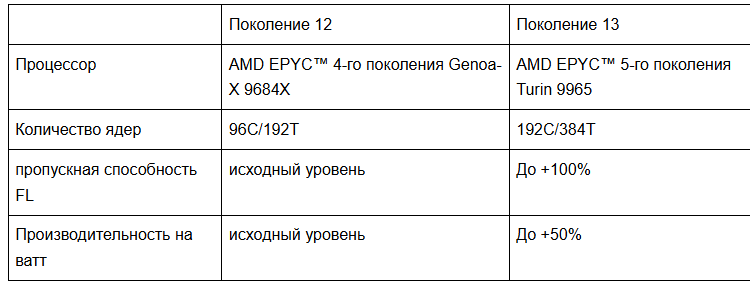
Увеличенная вдвое пропускная способность по сравнению с Gen 12 для бескомпромиссного качества обслуживания клиентов: удваивая пропускную способность при сохранении соответствия нашим соглашениям об уровне обслуживания (SLA) по задержке, мы гарантируем, что наши приложения останутся быстрыми и отзывчивыми, а также смогут выдерживать огромные пики трафика.
Повышение производительности на 50% на ватт по сравнению с 12-м поколением для устойчивого масштабирования: это повышение энергоэффективности не только снижает затраты на расширение центров обработки данных, но и позволяет нам обрабатывать растущий трафик со значительно меньшим углеродным следом на каждый запрос.
На 60% более высокая пропускная способность стоек по сравнению с Gen 12 для глобальных обновлений на периферии сети: Благодаря достижению такой плотности пропускной способности при сохранении постоянного энергопотребления стойки, мы можем беспрепятственно развертывать вычислительные мощности нового поколения в любой точке мира в рамках нашей глобальной сети на периферии сети, обеспечивая высочайшую производительность именно там, где это необходимо нашим клиентам.
Gen 13 + FL2: готовы к пределу возможностей
Наш устаревший уровень обработки запросов FL1 столкнулся с проблемой конкуренции за кэш на Gen 13, что вынудило нас пойти на неприемлемый компромисс между пропускной способностью и задержкой. Вместо того чтобы идти на компромисс, мы создали FL2.
Разработанная с использованием значительно более оптимизированной схемы доступа к памяти, технология FL2 устраняет зависимость от огромных кэшей L3 и обеспечивает линейное масштабирование в зависимости от количества ядер. Работая на платформе AMD Turin 13-го поколения, FL2 обеспечивает вдвое большую пропускную способность и 50% повышение энергоэффективности, при этом сохраняя задержку в пределах наших соглашений об уровне обслуживания (SLA). Этот прорыв является отличным напоминанием о важности совместной разработки аппаратного и программного обеспечения. Серверы 13-го поколения, не ограниченные лимитами кэша, теперь готовы к развертыванию для обработки миллионов запросов в глобальной сети Cloudflare.
Если вас интересует работа над инфраструктурными проектами глобального масштаба, мы нанимаем сотрудников www.cloudflare.com/careers/jobs
0 комментариев
Вставка изображения
Оставить комментарий