После запуска Scaleway Dedibox в начале 2020 года мы объявляем о выпуске нового поколения высокопроизводительных выделенных серверов от Scaleway Dedibox под названием Generation 7. Scaleway Dedibox предоставляет в аренду без минимального срока действия обязательств конфигурации выделенных серверов очень высокого класса с широкий спектр возможностей настройки. Эти предложения будут доступны в нескольких центрах обработки данных во Франции (DC5 / DC2) и Нидерландах (AMS1), и благодаря большой задержке и большей пропускной способности, поколение 7 будет ориентировано на мировой рынок.
Модернизированы линейки PRO и CORE.
Scaleway придерживается стратегии премиум-класса, обновляя модели выделенных серверов Dedibox через два месяца после запуска самых мощных в мире серверов Bare Metal с линейкой Ultimate Performance. Scaleway — одна из немногих компаний в мире, которые предоставляют предложения по размещению, общедоступному облаку и высокопроизводительным выделенным серверам, которые можно использовать в месяц (выделенные серверы Dedibox) или в час (серверы Bare Metal).
Сегодня мы обновляем нашу линейку PRO выделенными серверами S, M и L, а нашу линейку CORE — выделенными серверами M, L, XL и XXL.
Доступны два первых предложения поколения 7
 www.scaleway.com/en/dedibox/core/core-7-l-a/
www.scaleway.com/en/dedibox/core/core-7-l-a/
 www.scaleway.com/en/dedibox/core/core-7-xxl-a/
Ассортимент PRO предлагает отличный баланс между процессором, памятью и хранилищем.
www.scaleway.com/en/dedibox/core/core-7-xxl-a/
Ассортимент PRO предлагает отличный баланс между процессором, памятью и хранилищем.
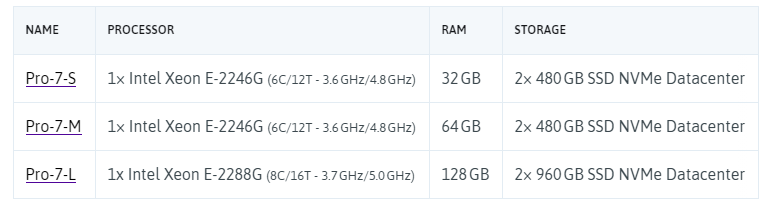
Обратите внимание, что выбранные процессоры Intel Xeon E включают графическое ядро Intel UHD P630 (буква G в номенклатуре Intel).
Ассортимент CORE предлагает для интенсивных нагрузок
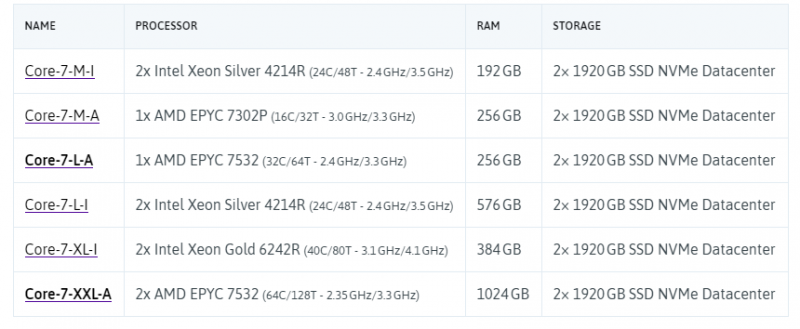
Обратите внимание, что R в названии процессоров Intel Silver (Refresh) соответствует последней версии для лучшего соотношения цена / качество.
Линейка Core с двумя архитектурами ЦП: Intel Xeon и AMD EPYC
В линейке Core серверы M и L поставляются с двумя типами ЦП: Intel Xeon и AMD EPYC. Имена этих машин содержат в конце буквы, обозначающие серверы на базе процессоров Intel или AMD. Например: Core-7-L-A для AMD и Core-7-L-I для Intel.
Scaleway предлагает вам самый широкий выбор конфигураций оборудования для высокопроизводительных выделенных серверов, которые наилучшим образом подходят для ваших проектов производственной инфраструктуры.
Расширенная настройка
Запуск поколения 7 также сопровождался новыми параметрами настройки, которые будут доступны только на выделенных серверах Dedibox поколения 7.
Пропускная способность до 25 Гбит/с
Интернет-соединение выделенных серверов Dedibox основано на высокопроизводительной, сверхбыстрой, надежной и полностью ячеистой сети и имеет пропускную способность 10 Тбит/с с несколькими операторами и точками обмена.
Выделенные серверы 7-го поколения имеют пропускную способность в 1 Гбит/с, что по умолчанию не гарантируется с неограниченным трафиком. Опция дополнительной пропускной способности позволяет увеличить пропускную способность до 25 Гбит/с на каждый сервер.
Подробнее
www.scaleway.com/en/dedibox/network/bandwidth/
Настройка оборудования
Выделенные серверы 7-го поколения по умолчанию поставляются с двумя дисками NVMe Datacenter. Настройка позволяет добавлять дополнительные диски для увеличения емкости серверов NVMe, SSD или SATA.
Цена дополнительных дисков взимается единожды при добавлении настройки. Ежемесячная плата за настройку этого диска не взимается. Обратите внимание, что эта опция доступна на серверах с дополнительной Бизнес-службой.
Откройте для себя все параметры настройки диска
www.scaleway.com/en/dedibox/storage/local-disks/
Уровень бизнес-обслуживания
Уровень бизнес-обслуживания — не новая функция. Мы рекомендуем добавить его на все производственные серверы, чтобы воспользоваться лучшими услугами Scaleway Dedibox. Например, он позволяет настроить сервер с дополнительными дисками.
Все услуги, входящие в уровень бизнес-обслуживания, перечислены ниже:
- Премиум и приоритетная помощь: доступна по билетам и по телефону, 24/7
- Поддержка: специальный менеджер по работе с клиентами
- Уровень обслуживания улучшений (SLA): гарантия 99,95% (базовый уровень: 99,9%),
- Гарантии вмешательства (GTI): H + 1 (Базовая: H + 4),
- Повышение RPN частной сети: пропускная способность до 10 Гбит / с
- Безопасность: Расширенная или лечебная защита
- Подробнее об уровне бизнес-услуг
Заключение
Поколение 7 обеспечивает то, что нужно нашим клиентам, с 9 новыми эталонами высокопроизводительных выделенных серверов, доступных в многопользовательских центрах обработки данных и дополненных всеми высококачественными услугами Scaleway Dedibox.
Давайте переживем опыт Dedibox с новым поколением 7! Ознакомьтесь со всеми предложениями нового поколения Dedibox 7-го поколения.







