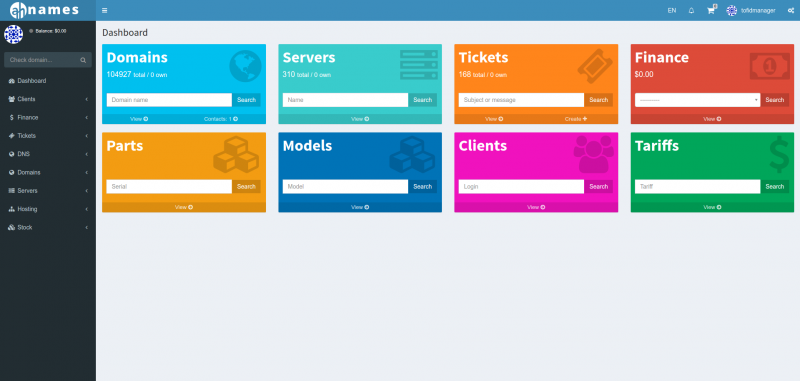
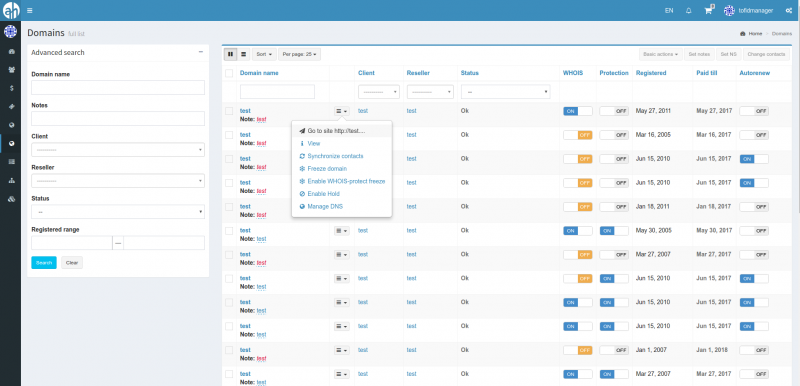
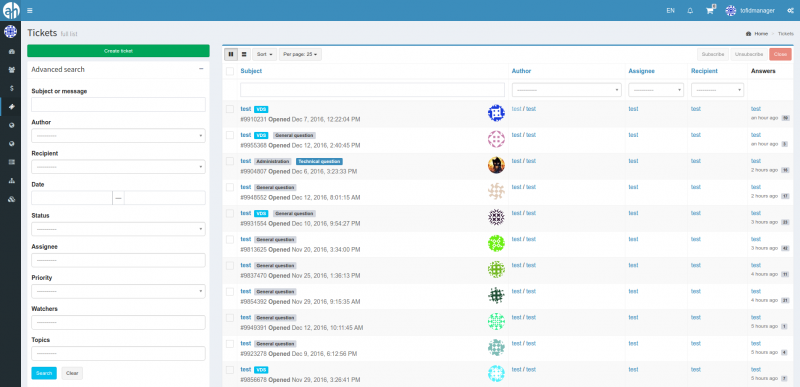
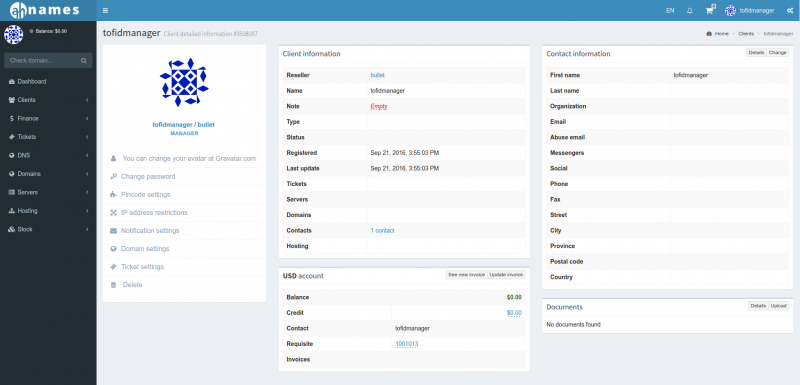
Алма означает «душа» на многих латинских языках, включая испанский и итальянский. Слово происходит от латинского almus, что означает «питательный, добрый».
Душевное сообщество
Ни одно техническое сообщество не может быть таким задушевным и страстным, как сообщество Linux. Это заботливое, совместное и питательное сообщество, которое превратило усилия отдельного человека в программное обеспечение, на котором основан мир.
История Linux начинается с личной истории Линуса Торвальдса, который в 1991 году объявил о разработке бесплатного UNIX-подобного ядра для машин x86 — ядра, которое он назвал Linux. Ядро для сообщества.
Разработчики быстро увидели потенциал бесплатного ядра UNIX с открытым исходным кодом. Шаг за шагом члены невероятно увлеченного сообщества разработчиков превратили Linux в мощное гибкое ядро, лежащее в основе бесчисленных популярных операционных систем — от настольных компьютеров до центров обработки данных.
Разнообразие сообщества Linux
Сообщество Linux удивительно разнообразно. Ядро сообщества состоит из замечательно преданных разработчиков и сопровождающих. В него также входят организации, занимающиеся развитием Linux и другого бесплатного программного обеспечения с открытым исходным кодом (FOSS). Например, Linux Foundation.
Поставщики, включая страстную команду CloudLinux, — еще один важный компонент сообщества Linux. Поставщики предоставляют критически важные ресурсы, которые помогают расти, создавать и поддерживать Linux.
Вместе, как отдельные лица, так и организации, мы формируем сообщество, которое является душой Linux. Вместе мы переносим Linux в будущее, всегда осознавая потребности сообщества Linux.
Таким образом, AlmaLinux родился из нашей страсти и необходимости оживить сердце и душу Linux.
AlmaLinux — ответ на потребность сообщества в замене CentOS
В декабре 2020 года сообщество потеряло один из важнейших ресурсов. Red Hat объявила, что CentOS больше не будет выпускаться как стабильный выпуск, а будет заменен постоянно обновляемым CentOS Stream.
В CloudLinux мы быстро осознали огромные последствия объявления Red Hat, поэтому мы пошли на замену CentOS: бинарно совместимый форк RHEL® 1: 1, который можно использовать бесплатно и с открытым исходным кодом. Мы дали ему кодовое название Project Lenix.
Теперь мы объявляем результаты проекта Lenix: AlmaLinux. Новый дистрибутив Linux, который будет выпущен в первом квартале 2021 года, позволит пользователям CentOS легко переключиться на замену CentOS, которая пользуется постоянной поддержкой.
Переключение требует минимальных усилий: поскольку AlmaLinux является бинарно-совместимой вилкой RHEL, базой для CentOS, переключение с CentOS на AlmaLinux чрезвычайно просто.
В партнерстве с сообществом
Мы разрабатываем AlmaLinux в тесном сотрудничестве с сообществом: включая сообщество в управлении и в каждом ключевом решении. CloudLinux обязуется поддерживать этот важный дистрибутив как минимум до 2029 года, инвестируя в его разработку минимум 1 миллион долларов в год.
Однако организация проекта с открытым исходным кодом означает, что сообщество может продвигать AlmaLinux вперед независимо от того, что происходит с организацией CloudLinux.
Итак, в заключение, именно так мы выбрали название AlmaLinux. AlmaLinux — это навсегда бесплатный дистрибутив Linux для сообщества, созданный сообществом и воплощающий душу сообщества.
almalinux.org