Приватный DNS: управляйте инфраструктурой без IP-адресов и DHCP

Мы запустили приватный DNS-сервер — изолированный DNS‑резолвер для приватных сетей с временем отклика до 1 мс и поддержкой нагрузки свыше 5000 запросов в секунду.
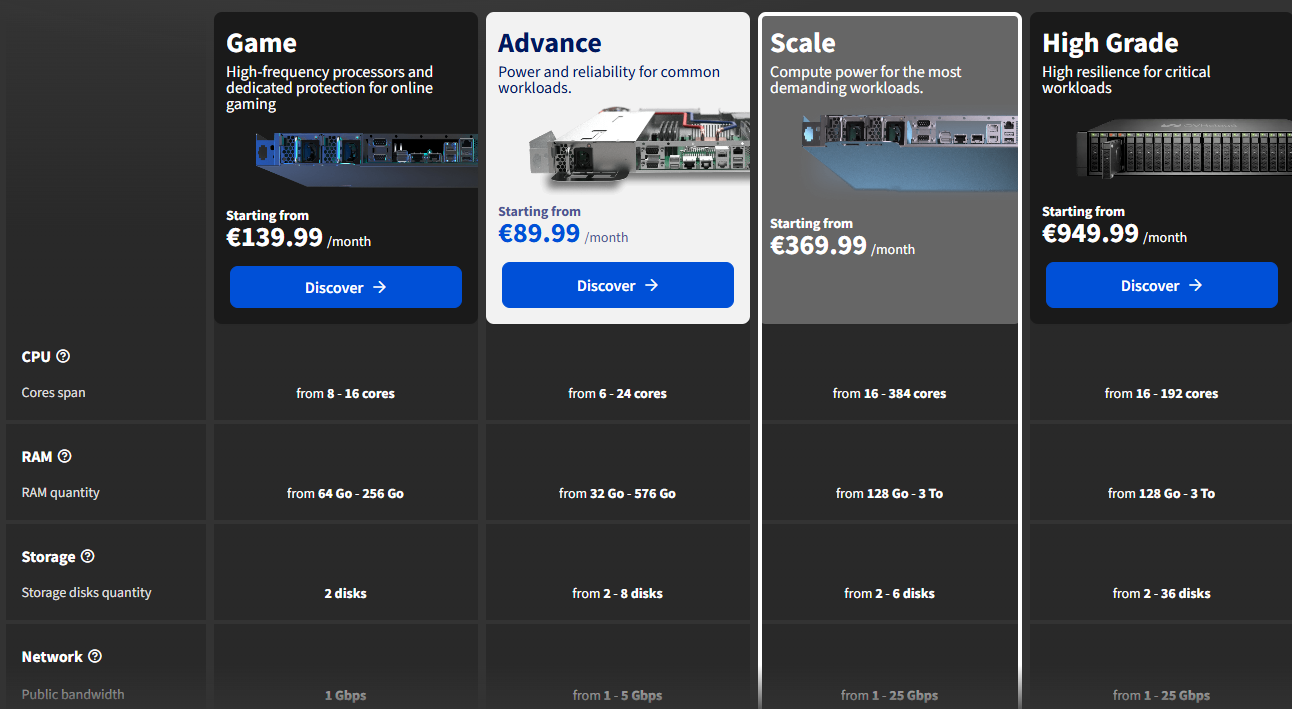
Что умеет сервис
- Два DNS-резолвера на каждую сеть с High Availability по умолчанию — отказоустойчивость без дополнительных настроек.
- Автоматическая генерация A-записей — при подключении сети к DNS-зоне записи для новых виртуальных машин создаются автоматически на основе имени VM.
- Единая точка управления для облачных серверов, выделенных серверов и кластеров Managed Kubernetes — без DHCP.
- Управление через API и Terraform — DNS становится частью CI/CD и IaC.
- Гранулярные роли и аудит-логи — разграничение прав для пользователей и команд, история действий хранится 90 дней.
- Поддержка любых FQDN — без подтверждения прав на домен и без ограничений по доменной зоне.
Какие задачи закрывает приватный DNS
- Безопасность. DNS развернут в изолированном сегменте — топология сети не видна снаружи, защита от DNS Rebinding и SSRF.
- Гибкое управление. При смене бэкенда или миграции между пулами достаточно обновить DNS-записи.
- Гибридная инфраструктура. Единая адресация работает независимо от расположения ресурсов — в облаке или на выделенных серверах.
Стоимость: подключение сети к DNS-резолверу — 1 179.68 KZT/мес. Создание и хранение приватных зон и записей — бесплатно.
servercore.com/ru/services/private-dns-server/