По состоянию на 30 июня 2018 года в центрах обработки данных Backblaze было 100254 вращающихся жестких диска. Из этого числа было 1,989 загрузочных дисков и 98,265 дисков данных. В этом обзоре рассматриваются квартальные и пожизненные статистические данные для моделей данных, работающих в наших центрах обработки данных. Мы также рассмотрим сравнение корпоративных и потребительских дисков, сначала рассмотрим наши 14-тонные диски Toshiba и представим вам две новые характеристики SMART. По пути мы поделимся наблюдениями и представлениями о представленных данных, и мы с нетерпением ожидаем, что вы сделаете то же самое в комментариях.
Статистика надежности жестких дисков для Q2 2018
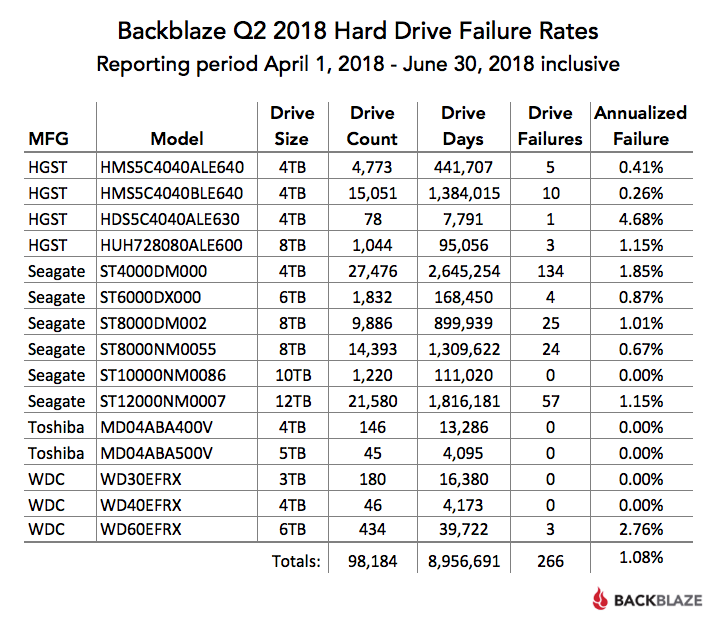
Из 98,265 жестких дисков, которые мы наблюдали в конце Q2 2018, мы исключили из рассмотрения те приводы, которые использовались для тестирования, и те модели накопителей, для которых у нас не было не менее 45 дисков. Это оставляет нам 98,184 жестких диска. Таблица ниже охватывает только Q2 2018.
 Примечания и наблюдения
Примечания и наблюдения
Если модель привода имеет частоту отказа 0%, это просто означает, что во время Q2 2018 не было сбоев привода этой модели.
Годовой показатель сбоя (AFR) для Q2 составляет всего 1,08%, что значительно ниже АФК Q1 2018 и является нашим самым низким квартальным AFR. Тем не менее, квартальные показатели отказов могут быть нестабильными, особенно для моделей с небольшим количеством дисков и / или небольшого количества Дней Drive.
Было 81 диск (98,265 минус 98,184), которые не были включены в список выше, потому что у нас не было, по крайней мере, 45 из данной модели привода. Мы используем 45 дисков той же модели, что и минимальное число, когда мы сообщаем статистику квартальных, ежегодных и пожизненных дисков. Использование 45 приводов носит исторический характер, так как это количество дисков в наших оригинальных накопителях.
Миграция жестких дисков продолжается
Квартальная диаграмма Q2 2018 выше была основана на 98184 жестких дисках. Это было всего лишь на 138 жестких дисков, чем на Q1 2018, который был основан на 98 046 дисках. Тем не менее, мы добавили около 40 PB облачного хранилища в течение первого квартала. Если бы мы попытались сохранить 40 PB на 138 дополнительных дисках, добавленных в Q2, то каждый новый жесткий диск должен был хранить около 300 ТБ данных. В то время как жесткие диски на 300 ТБ были бы потрясающими, менее опасная реальность заключается в том, что мы заменили более 4 600 приводов 4 ТБ с почти 4 800 приводов 12 ТБ.
Возраст заменяемых приводов 4 ТБ составлял от 3,5 до 4 лет. Во всех случаях их уровень отказов составлял 3% AFR (годовой показатель отказов) или меньше, поэтому зачем их удалять? Простая плотность приводов — в этом случае три раза хранится в одном и том же корпусе. Сегодня четыре года службы — это время, когда финансовый смысл заключается в замене существующих дисков и создании нового объекта с новыми стойками и т. Д. Хотя есть несколько факторов, которые принимают решение о переносе на накопители с более высокой плотностью, сохраняя жесткие диски за пределами этого переломного пункта означают, что мы будем использовать ценную недвижимость для центров обработки данных.
Диски Toshiba 14 ТБ и SMART Stats 23 и 24
Во втором квартале мы добавили к нашему миксу двадцать 14 ТБ Toshiba (модель: MG07ACA14TA) (этого недостаточно, чтобы быть включенными в наши диаграммы), но это изменится, поскольку мы заказали еще 1200 дисков, которые будут развернуты в Q3. Это 9-пластинные накопители с гелием, которые используют технологию записи CMR / PRM (не SMR).
В дополнение к тому, что для нас были новые диски, приводы Toshiba 14 ТБ также добавляют две новые пары SMART stat: SMART 23 (состояние гелия ниже) и SMART 24 (верхнее состояние гелия). Оба атрибута сообщают о нормальных и необработанных значениях, причем исходные значения в настоящее время равны 0, а нормализованные значения равны 100. Когда мы узнаем больше об этих значениях, мы сообщим вам об этом. Тем временем, те из вас, кто использует наши данные теста жесткого диска, должны будут обновить вашу схему данных и загрузить сценарии для чтения в новых атрибутах.
Кстати, ни один из 20 приводов Toshiba 14 ТБ не прошел через 3 недели на службе, но еще слишком рано делать какие-либо выводы.
Статистика надежности жестких дисков на весь срок службы
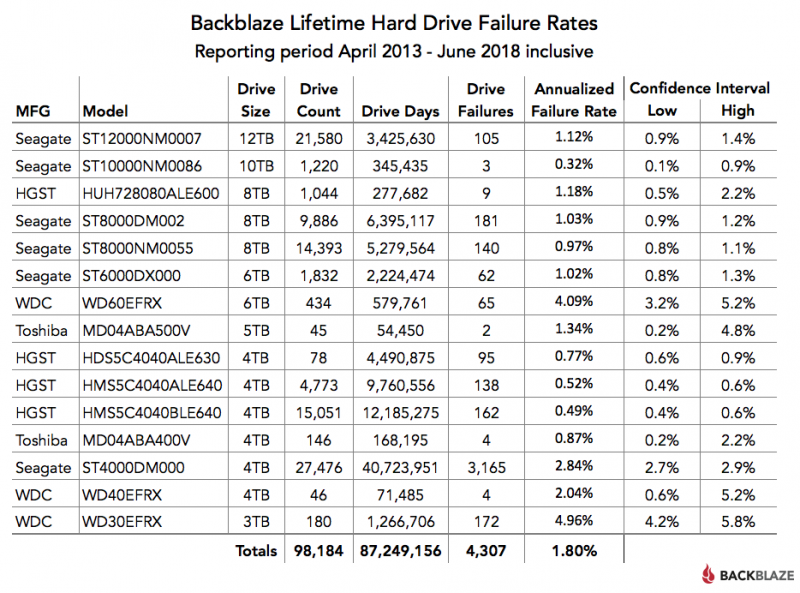
Хотя ежеквартальный график, представленный ранее, представляет большой интерес, реальный тест любой модели привода со временем. Ниже приведен график отказов по продолжительности жизни для всех моделей жестких дисков, работающих по состоянию на 30 июня 2018 года. Для каждой модели мы вычисляем ее надежность, начиная с того момента, когда она была впервые установлена
 Примечания и наблюдения
Примечания и наблюдения
Комбинированный AFR для всех более крупных приводов (8-, 10- и 12 ТБ) составляет всего 1,02%. Многие из этих дисков были развернуты в прошлом году, поэтому в данных есть некоторая волатильность, но мы ожидаем, что эта общая ставка несколько снизится в течение следующих нескольких лет.
Общая частота отказов для всех жестких дисков в обслуживании составляет 1,80%. Это самый низкий показатель, который мы когда-либо достигали, с предыдущим минимумом 1,84% с 1-го квартала 2018 года.
Корпоративные и потребительские жесткие диски
В нашем обзоре состояния жестких дисков Q3 2017 мы сравнили две модели жестких дисков Seagate 8 ТБ: один диск с потребительским классом (модель: ST8000DM002), а другой — диск корпоративного класса (модель: ST8000NM0055). Давайте сравним показатели годовых убытков в течение всего периода с 3-го квартала 2017 года и 2-го квартала 2018 года:
Пожизненная AFR по состоянию на 3 квартал 2017 года
- 8 ТБ потребителей: 1,1% в год
- 8 корпоративных корпоративных дисков: 1,2% в год
Пожизненная AFR по состоянию на 2 квартал 2018 года
- 8 ТБ потребителей: 1.03% годовой нормы отказа
- 8 корпоративных корпоративных дисков: 0,97%
Хммм, похоже, что корпоративные диски «выигрывают». Но прежде чем мы объявим победу, давайте заглянем в несколько деталей.
Начнем с дней диска, общее количество дней работы всех жестких дисков данной модели.
- 8 ТБ потребителя (модель: ST8000DM002): 6 395 117 дней движения
- Предприятие 8 ТБ (модель: ST8000NM0055): 5 279 564 дня
Обе модели имеют достаточное количество рабочих дней и достаточно близки по общему числу. Пока никаких изменений в нашем заключении.
Затем мы рассмотрим доверительные интервалы для каждой модели, чтобы увидеть диапазон возможностей в двух отклонениях.
- 8 потребителей ТБ (модель: ST8000DM002): диапазон 0,9% до 1,2%
- предприятие 8 ТБ (модель: ST8000NM0055): диапазон 0,8% до 1,1%
Диапазоны близки, но возможны множественные исходы. Например, потребительский диск может быть ниже 0,9%, а корпоративный диск может достигать 1,1%. Это не помогает или не нарушает наш вывод.
Наконец, мы будем смотреть на возраст диска — на самом деле средний возраст, чтобы быть точным. Это среднее время в оперативном обслуживании, в месяцах, всех приводов данной модели. Мы начнем с момента, когда каждый диск достигнет примерно текущего количества дисков. Таким образом, добавление новых дисков (без замены) будет иметь минимальный эффект.
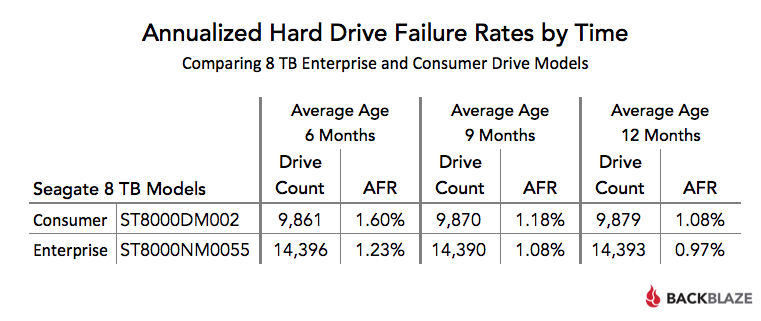
Когда вы ограничиваете количество дисков и средний возраст, AFR (годовая частота отказов) корпоративного диска последовательно ниже, чем у потребительского диска для этих двух моделей накопителей — хотя и не так много.
Является ли каждая модель предприятия лучше, чем любая соответствующая потребительская модель, неизвестна, но ниже приведены несколько причин, по которым вы можете выбрать один класс диска над другим:

Известно, что Backblaze является «экономным» при покупке дисков. Когда вы покупаете 100 дисков за раз или сталкиваетесь с кризисом накопителя, имеет смысл приобретать потребительские приводы. Когда вы начинаете покупать жесткие диски на 100 петабайт за раз, ценовой разрыв между корпоративными и потребительскими дисками сжимается до такой степени, что другие факторы вступают в игру.
Жесткие диски по номерам
С апреля 2013 года Backblaze записывает и сохраняет ежедневную статистику жесткого диска с дисков в наших центрах обработки данных. Каждая запись состоит из даты, производителя, модели, серийного номера, статуса (операционного или неудачного) и всех атрибутов SMART, сообщаемых этим диском. В настоящее время более 100 миллионов записей. Полный набор данных, используемый для создания информации, представленной в этом обзоре, доступен на нашей странице данных на жестком диске. Вы можете бесплатно скачать и использовать эти данные для своей собственной цели. Все, что мы просим, это три вещи: 1) вы цитируете Backblaze в качестве источника, если используете данные, 2) вы признаете, что несете единоличную ответственность за использование данных, и 3) вы не продаете эти данные никому. Это бесплатно.
Если вам просто нужны обобщенные данные, используемые для создания таблиц и диаграмм в этом сообщении в блоге, вы можете загрузить ZIP-файл, содержащий электронную таблицу MS Excel.
Удачи и сообщите нам, если вы найдете что-нибудь интересное в комментариях ниже или напрямую свяжитесь с нами.