Постоянные читатели: начну с извинений за то, что эта статья не была опубликована в наш традиционный день отчёта — 4 мая (или около того). Пожалуйста, знайте, что я скучал по многочисленным и разнообразным каламбурам на тему «Звёздных войн» так же сильно, как (я уверен) вы скучали по ним — поэтому я, пожалуй, добавлю несколько, просто так.
Тем не менее, задержка была по уважительной причине. Мы усердно расследовали нарушение в работе системы. (Видите? Мы вернулись!) Подробности мы обсудим после того, как разберемся с цифрами, а пока вот небольшой анонс: в этом квартале мы заметили нечто необычное в данных, что не было полностью тенденцией к сбоям. Однако это побудило нас пересмотреть и подтвердить предположения, лежащие в основе нашего анализа Drive Stats, прежде чем публиковать результаты.
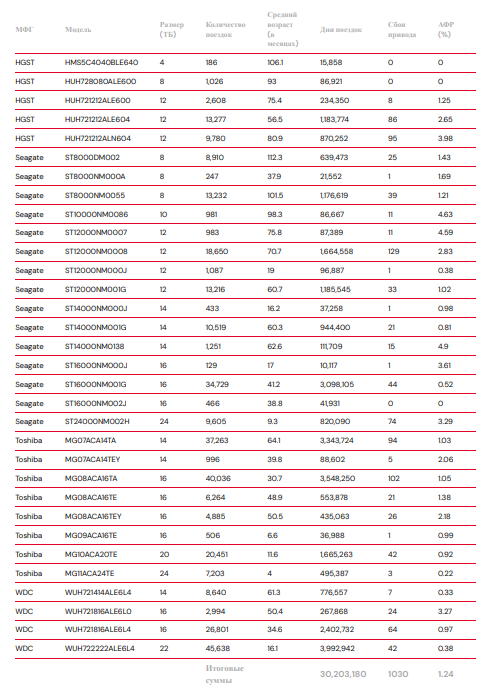
Показатели отказов жестких дисков в 1 квартале 2026 года
По состоянию на конец первого квартала 2026 года компания Backblaze отслеживала 345 662 диска, используемых для хранения данных. Для нашей оценки мы исключили из рассмотрения 3907 загрузочных дисков и 492 жестких диска, поскольку они не соответствовали критериям включения. Критерии, которые мы использовали, будут рассмотрены в следующем разделе этого отчета. После исключения этих дисков для анализа осталось 341 263 жестких диска. В таблице ниже показаны годовые показатели отказов за первый квартал 2026 года для этой группы дисков.
Показатели частоты отказов жестких дисков Backblaze за первый квартал 2026 года
Отчетный период: 1 января 2026 г. – 31 марта 2026 г. включительно.
Модели приводов с количеством приводов > 100 и количеством приводных дней > 10 000 по состоянию на 31 марта 2026 г. в 1 квартале 2026 г.
 Заметки и наблюдения
Заметки и наблюдения
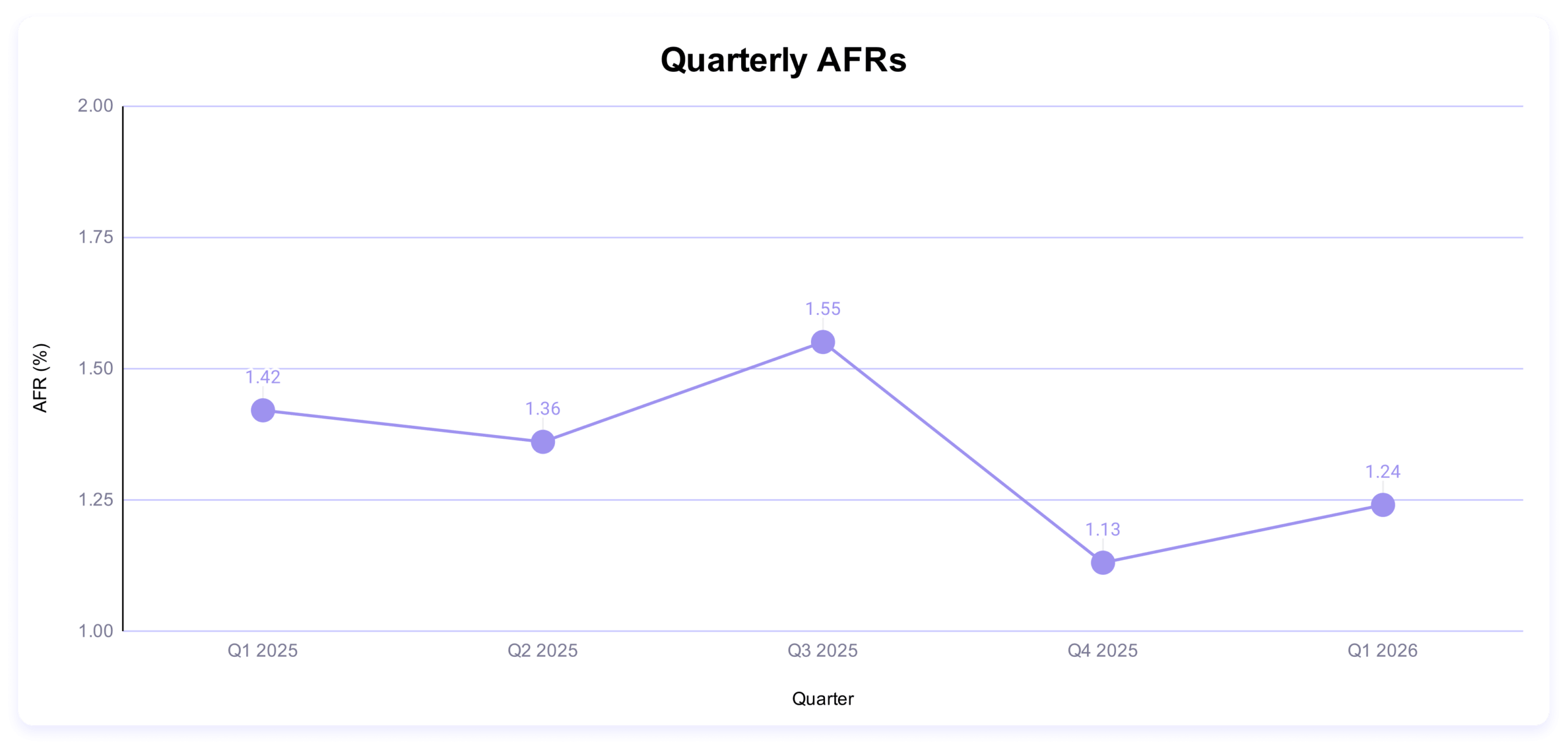
Квартальный показатель AFR составляет 1,24%. Это выше, чем в прошлом квартале, но ниже, чем в предыдущем году.
В этом квартале новых моделей накопителей не было. Это не является чем-то из ряда вон выходящим, но довольно редкое явление. За последние восемь кварталов новые накопители появлялись у нас всего шесть раз.
Инвестиции в накопители большей емкости продолжаются. В прошлом квартале мы установили 10 220 накопителей, и 9 404 из них имели емкость более 20 ТБ. Хотя эти накопители еще относительно новые, их показатель AFR (соотношение годовых и резервных дисков) впечатляет – 0,85% в целом.
Впечатляет, очень впечатляет. Эти накопители не вышли из строя ни разу:
- HGST HMS5C4040BLE640 (4 ТБ)
- HGST HUH728080ALE600 (8 ТБ)
- Seagate ST16000NM002J (16 ТБ)
И у этих накопителей был один:
- Seagate ST8000NM000A (8 ТБ)
- Seagate ST12000NM000J (12 ТБ)
- Seagate ST14000NM000J (14 ТБ)
- Seagate ST16000NM000J (16 ТБ)
- Toshiba MG09ACA16TE (16 ТБ)
Этот список подтверждает тезис, который мы высказывали в нескольких разных источниках: количество отказов не обязательно означает низкий показатель AFR. В этом списке жесткий диск Seagate ST16000NM000J (16 ТБ) показал показатель AFR 3,61% — при наличии всего 129 дисков в парке, даже один отказ резко повышает показатель AFR.
Это не те накопители, которые вам нужны.
Как уже упоминалось, мы удаляем диски, не соответствующие нашим критериям. Причины, по которым мы ввели эти исключения, мы уже объясняли в предыдущих отчетах, но вот краткое изложение сути:

Независимо от того, включена ли конкретная модель привода в диаграммы и таблицы этой статьи, все данные по отдельным позициям содержатся в нашем наборе данных статистики приводов, который вы можете загрузить, посетив нашу страницу статистики приводов.
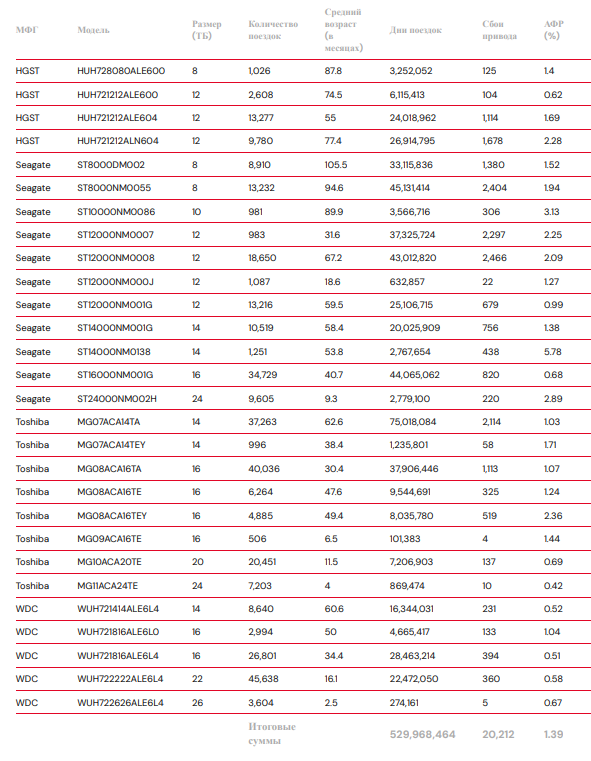
Показатели отказов жестких дисков за весь срок службы
Теперь давайте рассмотрим показатели отказов за весь срок службы. Напомним, что
Отчетный период: 1 января 2026 г. – 31 марта 2026 г. включительно.
Модели приводов с количеством приводов > 100 и количеством приводных дней > 10 000 по состоянию на 31 марта 2026 г. в 1 квартале 2026 г.
Заметки и наблюдения
Не сбивайтесь с курса. Показатель отказов за весь срок службы составляет 1,39%.
Привет! Три накопителя попали в таблицу показателей за весь срок службы, включая наш 26-терабайтный накопитель (который в прошлый раз показал чуть меньше, чем ожидалось):
- Toshiba MG09ACA16TE (16 ТБ)
- WDC WUH722222ALE6L4 (22 ТБ)
- WDC WUH722626ALE6L4 (26 ТБ)
Вы мне хорошо послужили. Последние из наших 4-терабайтных жестких дисков наконец-то перестали соответствовать критериям исключения для таблицы срока службы. HGST HMS5C4040ALE640 полностью распродан, а в пуле осталось всего 186 дисков HGST HMS5C4040BLE640 (4 ТБ).
Делай или не делай: когда неудача — не единственный критерий оценки
Как я уже намекнул во введении, в этом квартале неожиданное поведение выявило один из самых интересных крайних случаев, которые мы наблюдали за последнее время, и он проливает свет на некоторые важные истины о проекте Drive Stats. Что еще интереснее, это привело лишь к незначительному увеличению частоты сбоев, отчасти благодаря некоторым мерам по их устранению, которые нам удалось предпринять. Потерпите немного — здесь задействовано несколько взаимосвязанных проблем.
Мы часто говорили, что отдельные накопители в рамках одного производителя, и даже в рамках одной модели, могут значительно отличаться. В данном конкретном случае это было именно так: обнаружились две разные механические проблемы, одна из которых влияла на запись, а другая — на работу накопителя после перезагрузки. Тот факт, что это были два разных типа проблем, затруднил первоначальное расследование, и в зависимости от возраста накопителя, любая из проблем, обе или ни одна из них не могли повлиять на модель накопителя.
Кроме того, в обоих случаях ошибки не затрагивали все диски в пуле, и в течение длительного времени частота отказов была вполне приемлемой. Когда мы стали замечать больше сбоев, мы связали их с проблемой питания и смогли помочь снизить частоту перезагрузки систем хранения данных, содержащих эти диски. На практике это выглядело так: мы переводили хранилища с предполагаемыми проблемами в режим запрета загрузки и держали их в резерве. После завершения расследования мы смогли понять полную картину.
Здесь я хочу подчеркнуть один момент, который я уже неоднократно отмечал: показатели отказов наших накопителей, и то, о чем мы сообщаем в целом, являются результатом активной работы людей по управлению отказами и рисками. Вы можете ясно видеть это здесь — устранение одной из двух основных причин снизило общий риск для этой модели накопителей; и, пока мы это делали, у нас был альтернативный вариант, который позволил нам использовать накопители, хотя и другим способом.
Между тем, это также отражает точку зрения, которую мы высказывали с самого начала, ещё с тех пор, как говорили: «Почему бы не использовать потребительское оборудование для создания облачного хранилища?» Определенный уровень риска всегда приемлем. Система, которая стремится к полному отсутствию сбоев на аппаратном уровне, неразумна, учитывая, что наш программный уровень в значительной степени предотвращает потерю данных.
Всегда есть двое.
И все же это расследование имело особое значение, потому что мы обнаружили довольно много жестких дисков (не все — опять же, у этого инцидента было несколько причин), которые вышли из строя в первый же день. Поскольку это так, есть еще один важный аспект, который следует учитывать, — это то, как мы определяем отказ и как написана программа Drive Stats.
Вкратце, в конце каждого дня программа на C++ собирает различные статистические данные SMART. Если диск присутствовал накануне, а сегодня отсутствует, это регистрируется как сбой. Есть и другие элементы этой головоломки, включая период ретроспективного анализа. Так, если исчезнувший серийный номер диска появляется снова на второй (или третий, или четвертый) день, это задним числом говорит нам, что это не был сбой. Мы обрезаем этот период в конце квартала, что означает, что есть несколько дисков, которые могут быть ложноположительными срабатываниями такого рода, но вероятность довольно низка (и где-то нужно что-то обрезать).
Но вот что более важно: функция Drive Stats основана на условной логике. Поскольку она определяет сбой на основе присутствия диска в пуле накануне, это означает, что мы не можем определять сбои в первый день, используя только программу Drive Stats.
Что это значит для нас в будущем? Неужели мы совсем занижали данные о сбоях в первый день эксплуатации? Короткий ответ: да, вероятно. Но вернемся к оговорке про «управляемую среду» — как только диски попадают в центры обработки данных, они уже проходят период квалификации. Поэтому сбои в первый день эксплуатации у нас относительно редки.
Однако это означает, что следует проявлять осторожность, особенно если вы относитесь к тем, кто предпочитает использовать полный набор данных для своих проектов. Данные логлайна позволяют получить статистику SMART, но только для накопителей, которые осмелились проработать до конца первого дня.