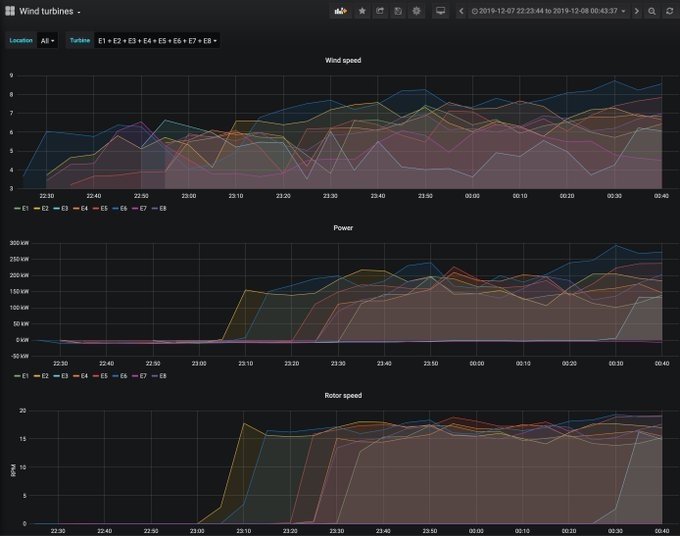
RBX network 30-03-2020 (45 min)
У нас проблема с сетевым подключением.
Наши команды на это.
travaux.ovh.net/?do=details&id=43793
Комментарий OVH — Понедельник, 30 марта 2020 года, 18:05
В настоящее время мы проверяем нашу магистральную и базовую сетевую инфраструктуру.
Услуги возвращаются гладко. Мы все еще расследуем
Комментарий OVH — Понедельник, 30 марта 2020 года, 18:08
В настоящее время мы сосредотачиваем наши исследования и действия на некоторой базовой инфраструктуре.
Комментарий OVH — Понедельник, 30 марта 2020 г., 18:15
Инцидент инфраструктуры подтвержден. Этот инцидент не связан с внешними событиями.
Комментарий OVH — Понедельник, 30 марта 2020 г., 18:25
Сервисы постепенно восстанавливаются после изоляции неисправной сетевой инфраструктуры.
Мы продолжаем следить за тем, чтобы услуги были восстановлены.
Комментарий OVH — понедельник, 30 марта 2020 г., 18:59
Дефектная инфраструктура, которую мы изолировали, расположена в RBX, что в первую очередь влияет на услуги этого DC.
Мы обострили этот инцидент у производителя с критической серьезностью для диагностики и нормализации избыточности сервиса.
В настоящее время работа нашей сети нормализовалась.
Комментарий OVH — понедельник, 30 марта 2020 г., 19:22
Этот сетевой инцидент затронул услуги наших центров обработки данных Roubaix с 5:01 до 5:40 вечера CEST, а также магистральный трафик, который там протекает.
Все службы теперь, похоже, восстановлены, и наши команды сейчас работают над тем, чтобы обеспечить полное восстановление.
Мы устраняем причину этого инцидента, о котором будет сообщено позже. До тех пор мы продолжаем держать вас в курсе наших достижений.
Комментарий OVH — понедельник, 30 марта 2020 г., 19:48
После подтверждения диагноза службой поддержки производителя мы постепенно возобновляем связи инфраструктуры, которую мы полностью изолировали.
Эта операция позволит вернуться к номинальной ситуации, за исключением материальной части данного оборудования, которая останется изолированной до дальнейшего уведомления.
Комментарий OVH — понедельник, 30 марта 2020 г., 21:15
Мы завершили активацию ссылок для обеспечения безопасности трафика через эту инфраструктуру.
Компонент по умолчанию остается изолированным до дальнейшего уведомления и будет заменен позже.
Комментарий OVH — понедельник, 30 марта 2020 г., 22:56
Мы только что завершили перенос оставшихся ссылок на изолированный компонент.
Поэтому ситуация нормализуется, и вся емкость снова полностью доступна.
Мы планируем заменить изолированный компонент в течение 72 часов, чтобы мы могли продолжить устранение неполадок.
Мы будем держать вас в курсе любых дальнейших действий.
Наши команды на это.
travaux.ovh.net/?do=details&id=43793
Комментарий OVH — Понедельник, 30 марта 2020 года, 18:05
В настоящее время мы проверяем нашу магистральную и базовую сетевую инфраструктуру.
Услуги возвращаются гладко. Мы все еще расследуем
Комментарий OVH — Понедельник, 30 марта 2020 года, 18:08
В настоящее время мы сосредотачиваем наши исследования и действия на некоторой базовой инфраструктуре.
Комментарий OVH — Понедельник, 30 марта 2020 г., 18:15
Инцидент инфраструктуры подтвержден. Этот инцидент не связан с внешними событиями.
Комментарий OVH — Понедельник, 30 марта 2020 г., 18:25
Сервисы постепенно восстанавливаются после изоляции неисправной сетевой инфраструктуры.
Мы продолжаем следить за тем, чтобы услуги были восстановлены.
Комментарий OVH — понедельник, 30 марта 2020 г., 18:59
Дефектная инфраструктура, которую мы изолировали, расположена в RBX, что в первую очередь влияет на услуги этого DC.
Мы обострили этот инцидент у производителя с критической серьезностью для диагностики и нормализации избыточности сервиса.
В настоящее время работа нашей сети нормализовалась.
Комментарий OVH — понедельник, 30 марта 2020 г., 19:22
Этот сетевой инцидент затронул услуги наших центров обработки данных Roubaix с 5:01 до 5:40 вечера CEST, а также магистральный трафик, который там протекает.
Все службы теперь, похоже, восстановлены, и наши команды сейчас работают над тем, чтобы обеспечить полное восстановление.
Мы устраняем причину этого инцидента, о котором будет сообщено позже. До тех пор мы продолжаем держать вас в курсе наших достижений.
Комментарий OVH — понедельник, 30 марта 2020 г., 19:48
После подтверждения диагноза службой поддержки производителя мы постепенно возобновляем связи инфраструктуры, которую мы полностью изолировали.
Эта операция позволит вернуться к номинальной ситуации, за исключением материальной части данного оборудования, которая останется изолированной до дальнейшего уведомления.
Комментарий OVH — понедельник, 30 марта 2020 г., 21:15
Мы завершили активацию ссылок для обеспечения безопасности трафика через эту инфраструктуру.
Компонент по умолчанию остается изолированным до дальнейшего уведомления и будет заменен позже.
Комментарий OVH — понедельник, 30 марта 2020 г., 22:56
Мы только что завершили перенос оставшихся ссылок на изолированный компонент.
Поэтому ситуация нормализуется, и вся емкость снова полностью доступна.
Мы планируем заменить изолированный компонент в течение 72 часов, чтобы мы могли продолжить устранение неполадок.
Мы будем держать вас в курсе любых дальнейших действий.