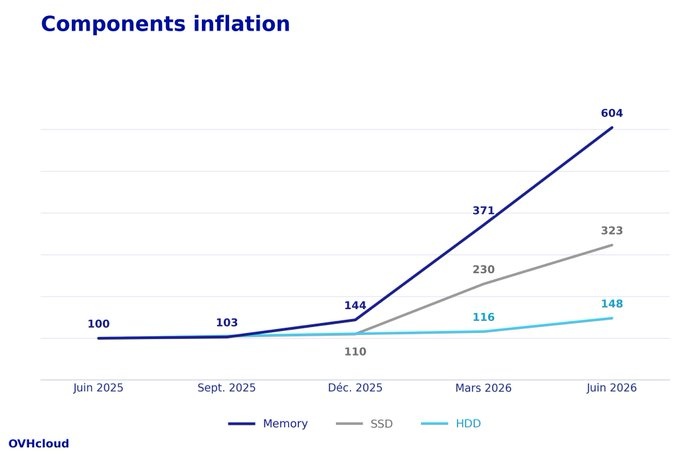
Инфляция компьютерных компонентов продолжается с моего последнего твита в феврале. В основе всего лежит ИИ, которому нужны GPU, а тем самым и RAM. Три мировых поставщика RAM переконфигурировали свои заводы, чтобы производить очень прибыльную RAM (HBM) в ущерб стандартной RAM (DDR4/DDR5).
В этом месяце, в июне 2026 года, мы платим за RAM в 6 раз дороже, чем платили в июне 2025 года. Мы уже знаем, что в сентябре 2026 года она будет в ×9, в то время как прогнозы на начало 2027 года — ×12!?
Помимо этого ×12 за 16 месяцев на RAM, ×7 на дисках NVMe и ×3,5 на дисках HDD, поговаривают, что рост цен затронет и чипы — а значит, CPU, материнские платы и сетевые карты — на +15–20 %… на данный момент.
Наши предложения
Главная проблема, которую мы хотим избежать, — это нехватка деталей и невозможность поставить вам Cloud. Тем более что вы, новые клиенты, в большом числе осознаете, что компьютерное оборудование стоит безумных денег или что его просто невозможно получить вовремя. И поэтому переходите на Cloud.
Напоминаем: для части существующих клиентов и новых заказов мы пересмотрели цены на наши предложения в апреле. Кроме того, мы успешно предвидели повышения июня 2026 года, поэтому нам не придется менять цены до сентября 2026 года. Однако, учитывая, что цены продолжают расти, мы не сможем удерживать текущие цены после сентября 2026 года.
Как и в апреле, мы повысим цены для существующих клиентов и новых заказов в
конце августа 2026 года — для двух последних поколений каждой линейки (текущее и предыдущее) — например, Advance Gen4 и Gen3, Scale Gen3 и Gen2.
Ни один клиент из более ранних линеек (Gen-2) не будет затронут, как и в апреле — например, Kimsufi, Rise, Advance Gen2 и Gen1, Scale Gen1.
Детали будут сообщены в конце июля / начале августа.
Календарь
- С начала июля 2026 года мы меняем цены на опции RAM и диски для новых заказов.
- С начала сентября 2026 года мы меняем цены на наши предложения Gen и Gen-1 для новых заказов.
- С начала октября 2026 года мы меняем цены для существующих клиентов Gen и Gen-1.
- Чтобы сохранить текущие цены, вы можете продлить услуги, оплатив 12 / 24 / 48 месяцев заранее (upfront), что зафиксирует цены на этот период.
Перспектива
Ситуация исключительная и продлится до 2028 года. Спрос на ИИ безумный на всех уровнях: дата-центры, GPU, token-as-a-service, агентный ИИ. Все хотят его, все используют. Именно это вызывает удар по всему бизнесу, который не «ИИ».
Мы остаемся полностью прозрачными с вами. В
феврале мы сказали вам, что произойдет; это произошло, и вы пережили это вместе с нами. Сегодня мы снова говорим вам, что грядет. Теперь вам решать, как действовать и что для вас лучше. С нашей стороны мы продолжим играть в игру прозрачности и выбирать стратегию предвидения.