Bastion? Мы говорим об инди-игре?
Не в этот раз! (хотя это хорошая игра!).

В OVHcloud довольно много наших инфраструктур построено поверх Linux-боксов. У нас много разных вкусов; такие как Debian, Ubuntu, Red Hat… и этот список можно продолжить. У нас даже был старый добрый Gentoos однажды! Все они хранятся на голых металлических серверах, на виртуальных машинах и в контейнерах повсюду. Пока у него есть процессор (или vCPU), мы, вероятно, загрузили на него какой-нибудь дистрибутив Linux. Но это еще не все. У нас также были коробки Solaris, которые позже превратились в коробки OmniOS, которые теперь превратились в блестящие коробки FreeBSD. У нас также есть много сетевых устройств, разделенных на разных конструкторов, охватывающих широкий спектр поколений моделей.
Как вы, наверное, догадались, у нас есть разнородные системы, которые работают для предоставления нескольких различных сервисов. Но независимо от этой неоднородности, знаете ли вы, что у них общего? Да, все они пингуются, но есть кое-что более интересное: все они могут управляться через ssh.
Проблема
Уже давно SSH является стандартом администратора де-факто — он заменил устаревшие программы, такие как rlogin, которые с радостью передавали ваш пароль в незашифрованном виде по сети, — поэтому мы используем его постоянно, как и большинство представителей отрасли.
Есть два обычных способа его использования: либо вы просто вводите пароль своей учетной записи, когда его запрашивает удаленный сервер, что более или менее похоже на rlogin (без вашего пароля, передаваемого в виде открытого текста по проводам); или вы используете аутентификацию с открытым ключом, генерируя так называемую «пару ключей», когда закрытый ключ находится на вашем столе (или в смарт-карте), а соответствующий открытый ключ — на удаленном сервере.
Проблема в том, что ни один из этих двух способов не является действительно удовлетворительным в контексте предприятия.
Аутентификация по паролю
Во-первых, пароль способ. Ну, мы все уже знаем, что пароли отстой. Либо вы выбираете тот, который слишком легко взломать, либо вы выбираете очень сложный, который вы никогда не вспомните. Это заставляет вас использовать менеджер паролей, который защищен… мастер-паролем. Даже надежные парольные фразы, такие как «Правильное крепление батареи для лошадей», в конце концов являются не более чем сложным паролем. Они приносят целый ряд проблем, таких как тот факт, что они всегда подвергаются атакам грубой силы, и некоторые пользователи могут быть поражены чумой повторного использования пароля. Как системный администратор, вы никогда не спите спокойно, когда знаете, что безопасность ваших систем находится всего в одном пароле. Конечно, есть способы снижения риска, такие как принудительное периодическое обновление пароля, минимальная длина и / или сложность пароля, или отключение учетной записи после нескольких сбоев и т. Д. Но вы просто возлагаете дополнительную нагрузку на своих пользователей и по-прежнему не достижение удовлетворительного уровня безопасности.
Аутентификация с открытым ключом
Во-вторых, способ pubkey. Исправление проблем с паролями проходит долгий путь, но затем проблема становится масштабируемой. Переносить ваш открытый ключ на домашний сервер очень просто, но когда у вас есть десятки тысяч серверов / устройств, а также тысячи сотрудников, которые администрируют какое-то постоянно меняющееся подмножество указанных серверов / устройств, это быстро становится сложным. Действительно, сделать это правильно и поддерживать его в долгосрочной перспективе в контексте предприятия — это настоящая проблема.
PKI-аутентификация
Ради полноты — потому что я слышу вас отсюда, гуру SSH! — в последних версиях серверов SSH существует третий способ, а именно аутентификация на основе PKI с доверенным центром сертификации (CA). Вы устанавливаете общедоступный сертификат своего CA на всех своих серверах, и они принимают любое соединение, аутентифицированное сертификатом, предоставленным этим CA, полагаясь на имя субъекта сертификата. Это указывает, к какой учетной записи можно получить доступ на сервере, между прочим. Это очень централизованный способ управления вашими доступом со всей властью того, кто контролирует ваш ЦС. Это может быть очень успешным, если сделать это очень осторожно, с большим количеством безопасности и процессов вокруг рабочих процессов доставки сертификатов. Правильное управление ЦС не является шуткой и может привести к серьезным укусам, если вы поступите неправильно. Это также является сравнительно недавним дополнением к OpenSSH, и, учитывая неоднородность, которую мы обрисовали выше, она оставила бы множество систем на стороне. Есть и еще одна причина, по которой мы не выбрали этот метод, но прежде чем углубляться в него, давайте поговорим о наших потребностях.
Что нам нужно
В OVHcloud у нас есть различные технические команды, которые управляют своей собственной инфраструктурой, а не полагаются на общий внутренний ИТ-отдел. Этот принцип является частью культуры компании и ДНК. У него есть свои недостатки; такие как дополнительная сложность в ведении исчерпывающей и актуальной инвентаризации наших собственных активов, но ее преимущества намного превосходят их: несколько команд могут выполнять итерации быстрее, поскольку они могут использовать существующие продукты OVHcloud в качестве строительных блоков для создания новых, инновационных продуктов, Однако это не должно происходить за счет безопасности, которая является основополагающей для всего, что мы делаем в OVHcloud.
Но как нам удалось разработать системы безопасности на основе управления SSH для всех этих серверов, не мешая различным операционным командам?
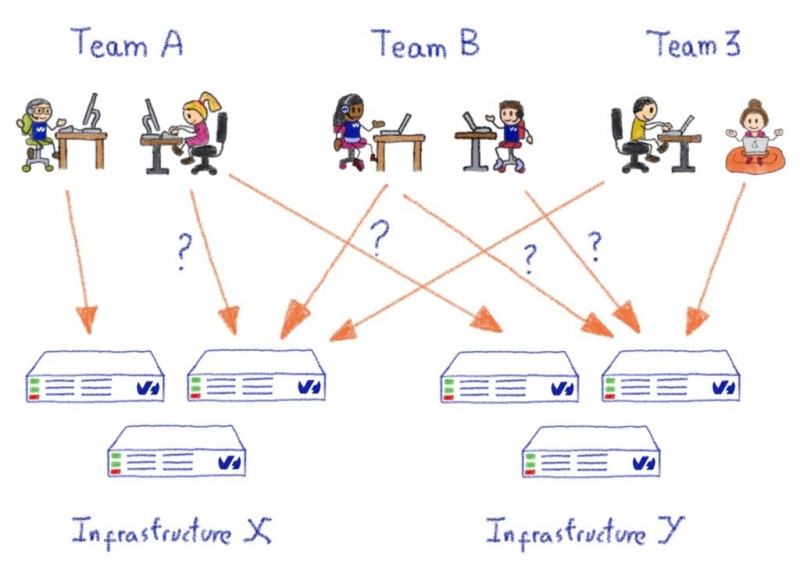
Требуется несколько важных вещей:
ДЕЛЕГАЦИЯ
- Любой вид централизованной «группы безопасности», ответственной за обработку разрешений на доступ для всей компании, запрещен. Это не масштабируется, независимо от того, как вы это делаете.
- Менеджеры или технические руководители должны быть полностью автономны в управлении своим собственным периметром с точки зрения серверов / систем / устройств и в отношении тех лиц, которым предоставлен доступ в пределах их периметра.
- Участник команды, переходящий в другую команду или из компании, должен быть полностью цельным процессом, независимо от того, к каким системам этот человек имел доступ (помните гетерогенность выше?).
- Предоставление доступа новому члену команды также должно быть беспроблемным, чтобы они могли испачкать руки как можно быстрее.
- Временное предоставление доступа кому-либо за пределами группы (или компании) к данному активу на ограниченный период времени должно быть легким.
- Все это должно быть сделано автономным
AUDITABILITY & TRACEABILITY
- Каждое действие должно быть зарегистрировано с большим количеством деталей; будь то изменение разрешения или соединение с системой; будь успешным или нет. Мы также хотим, чтобы это было применимо к некоторым SIEM.
- Каждый терминальный сеанс должен быть записан. Да, вы правильно прочитали. Это особенность, которая вам никогда не понадобится… пока вы этого не сделаете.
- Должно быть легко создавать отчеты для проведения проверок доступа.
БЕЗОПАСНОСТЬ И УСТОЙЧИВОСТЬ
- Мы должны обеспечить больше безопасности, чем простой прямой доступ по SSH, без дополнительных затрат.
- Любой компонент, который мы должны добавить для удовлетворения этих потребностей, должен постоянно работать и даже (особенно), когда остальная часть вашей инфраструктуры разваливается, потому что именно тогда вам потребуется SSH.
- Так какова другая причина, по которой мы не выбрали путь PKI? Что ж, это ограничило бы автономию командных групп: только центр сертификации мог бы выдавать или отзывать сертификаты, но мы хотим, чтобы эта власть была в руках командных групп. В случае с PKI, если бы мы хотели дать им некоторую власть, нам пришлось бы реализовать сложную логику вокруг CA, чтобы сделать это возможным, и мы не хотели идти по этому пути.
Войдите в бастион!
Чтобы отвечать нашим сложным требованиям, у нас есть специализированная машина, которая находится между администраторами и инфраструктурами — бастион, — чья работа состоит в том, чтобы обрабатывать все важные элементы, перечисленные выше, в дополнение к разделению фаз аутентификации и авторизации. Мы будем использовать аутентификацию с открытым ключом с обеих сторон. Давайте на минутку увидим простой пример рабочего процесса подключения с использованием этого дизайна:
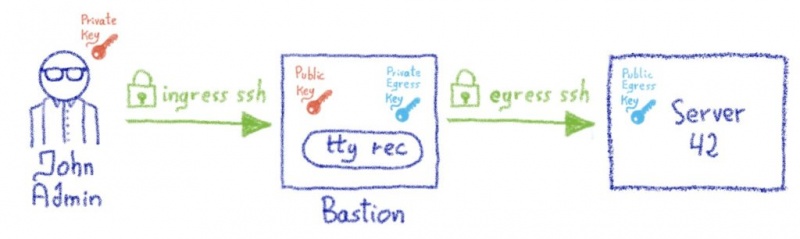
- Администратор хочет подключиться к машине с именем server42
- Он не может напрямую использовать SSH с ноутбука своей компании на сервер42, поскольку сервер42 защищен брандмауэром и разрешает только входящие соединения SSH из бастионных кластеров компании.
- Вместо этого администратор начинает сеанс SSH с бастионом, используя свою именную учетную запись. Его ноутбук согласовывает сессию SSH, используя свой закрытый ключ. Это этап аутентификации: бастион гарантирует, что администратор, представившийся как Джон Админ, действительно является этим человеком, что возможно благодаря тому факту, что открытый ключ Джона Админа находится внутри его учетной записи бастиона. Мы называем это * входной * связью.
- После аутентификации Джона Админа он просит бастион открыть соединение с учетной записью root на сервере42.
- Бастион проверяет, разрешен ли John Admin доступ к корневой учетной записи на сервере42, это часть авторизации. Скажем для примера, что Джону Админу действительно разрешено подключаться к этому серверу, используя закрытый ключ своей команды (подробнее об этом позже).
- Бастион инициирует SSH-соединение с сервером 42 от имени Джона Админа, используя закрытый ключ бастиона своей команды.
- Брандмауэр server42 разрешает входящие SSH-соединения от бастиона, и соединение успешно согласовывается, поскольку открытый ключ бастиона команды John Admin установлен на корневой учетной записи server42. Мы называем это * выходной * связью.
- Теперь у нас есть два установленных SSH-соединения: входное соединение между John Admin и бастионом и выходное соединение между бастионом и сервером42.
Теперь происходит какое-то волшебство, и бастион «соединяет» эти два соединения вместе, используя псевдотерминал (pty) между ними. Теперь у Джона Админа сложилось впечатление, что он напрямую подключен к серверу42 и может взаимодействовать с ним, как если бы это было так.
Между тем, бастион может записывать все, что набрано Джоном Админом (или, точнее, все, что * видит * Джон Админ, мы не будем записывать пароли, которые он вводит на терминалах noecho!), Это обрабатывается с помощью ovh- программа ttyrec.
Чтобы быть совершенно понятным, server42 не знает, кто такой Джон Админ, и не нуждается в этом: мы отделили часть аутентификации и авторизации. Только бастион должен знать и аутентифицировать администратора, а удаленный сервер только знает и доверяет бастиону (или, точнее, команде Джона Админа на бастионе). Это открывает целый ряд возможностей… но об этом подробнее в следующем посте!
Этот пост является первым из серии постов, касающихся бастиона. В следующих статьях мы рассмотрим часть авторизации, а именно личные ключи и доступы, группы и все, что связано с ними. Мы также рассмотрим различные роли, которые существуют на бастионе, чтобы сделать его таким универсальным. Мы поговорим о некоторых вариантах дизайна и о том, как мы хотим, чтобы безопасность была в центре этих решений — с некоторыми техническими подробностями.