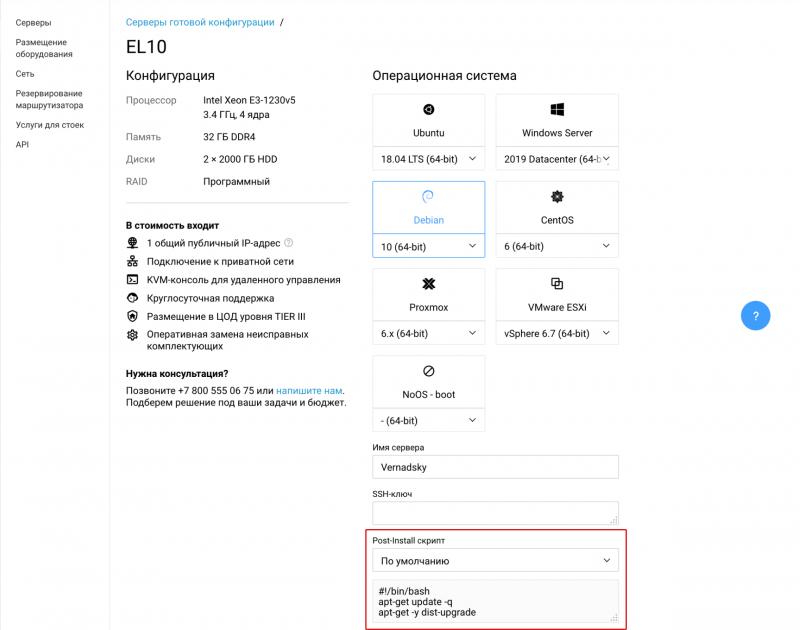
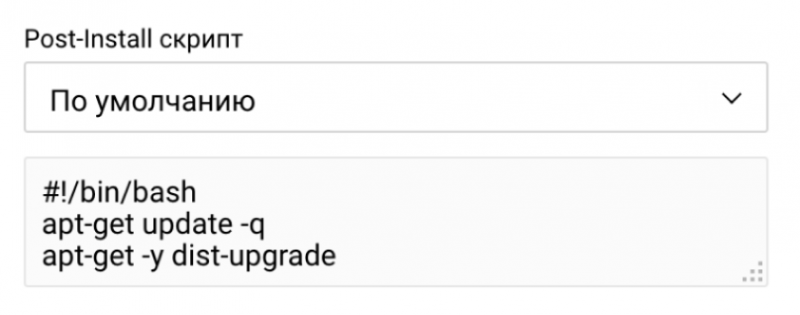
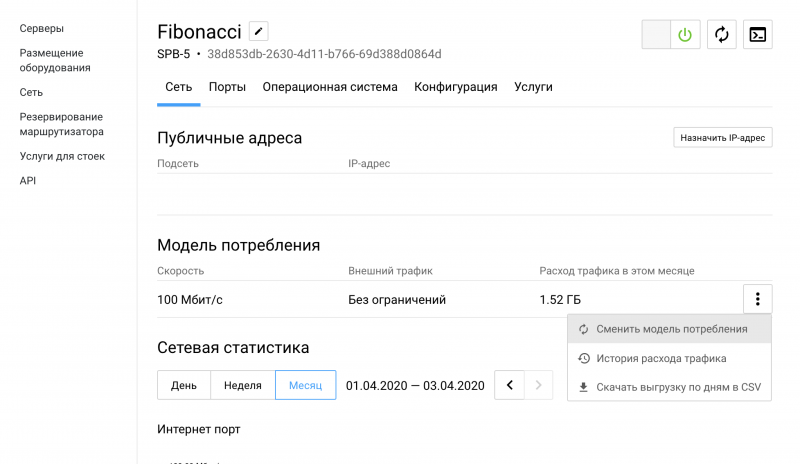
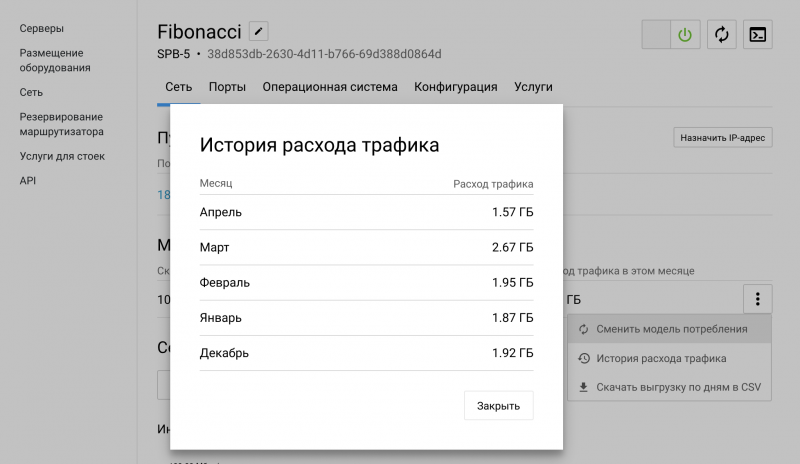
Дешевые БУ SSD Samsung 850 PRO 1TB
Здравствуйте
Мы сняли с оборудования диски Samsung 850 PRO 1TB. Износ не превышает 20% — прослужат еще 2-3 года без проблем, быстрые, надежные — для игр, требовательных задач. Подойдут для замены HDD в компьютере, в ноутбуке, сервере без HWRAID.
Характеристики: market.yandex.ru/product--tverdotelnyi-nakopitel-samsung-mz-7ke1t0bw/11035857/spec?track=char&nid=83821
Продаем по 9 тысяч за шт. В наличии 11 шт. Даем гарантию 2 месяца. Заинтересованные лица пишите в биллинговую систему, чтобы договориться о способе оплаты и передачи оборудования.
billing.netpoint-dc.com/billmgr?func=register&lang=ru
Мы сняли с оборудования диски Samsung 850 PRO 1TB. Износ не превышает 20% — прослужат еще 2-3 года без проблем, быстрые, надежные — для игр, требовательных задач. Подойдут для замены HDD в компьютере, в ноутбуке, сервере без HWRAID.
Характеристики: market.yandex.ru/product--tverdotelnyi-nakopitel-samsung-mz-7ke1t0bw/11035857/spec?track=char&nid=83821
Продаем по 9 тысяч за шт. В наличии 11 шт. Даем гарантию 2 месяца. Заинтересованные лица пишите в биллинговую систему, чтобы договориться о способе оплаты и передачи оборудования.
billing.netpoint-dc.com/billmgr?func=register&lang=ru