31 Декабря, 2020
31 Декабря, 2020
Итоги года или как мы в mClouds.ru обновились в 2020
В конце года хотим подвести итоги развития нашей облачной платформы и вспомнить основные достижения 2020 года. Поехали!
Увеличили вычислительные мощности облака!
В первый день февраля мы запустили высокопроизводительные серверы на базе процессоров Intel Xeon Gold 6254 с базовой тактовой частотой 3.1 GHz и до 3.9 ГГц в режиме Turbo Boost. Серверы имеют по два блока питания, подключенные к независимым источникам питания, а также подключены в сеть по 4-м портам 10 Гбит
Пользователи могут размещать высоконагруженные системы, такие как ERP, CRM и приложения 1С с 36 vCPU и до 768 Гб оперативной памяти.
Подключаем каждый сервер облака по 50 Гбит/сек!
После длительных тестов запустили новую стойку с портами коммутаторов 25 Гбит/с. Все серверы в новой стойке подключаются двумя портами по 25 Гбит/с в два коммутатора. На хабре мы опубликовали статью с тестированием новых процессоров Intel Xeon Gold 6242R — 20 ядер и с базовой тактовой частотой 3.1 ГГц и 3.8 ГГЦ в режиме постоянного Turbo Boost, которые мы начали добавлять в высокопроизводительный кластер.
Вошли в ТОП рейтинга облачных провайдеров Cnews
Мы рады отметить, что по результатам сравнения облачный провайдер mClouds предоставляет услуги на высшем уровне и входит в топ-10 провайдеров страны. Market.Cnews составили и опубликовали первый в России рейтинг облачных провайдеров. Для составления рейтинга аудитор собрал и внимательно изучил SLA ведущих IaaS провайдеров страны и провел оценку по балльной системе
Провели много улучшений в наших сервисах, среди которых:
Расширили и ускорили all-flash СХД
В облаке мы используем системы хранения IBM FlashSystem 5000 на базе SSD дисков. Летом мы увеличили емкость, повысили производительность, а также сократили задержки массивов.
Добавили к автоматической публикации новые операционные системы
В этом году многие операционные системы на базе Linux обновились — мы подготовили шаблоны Ubuntu 19, Ubuntu 20 и CentOS 8 и добавили их поддержку в репозиторий облака к автоматической публикации виртуальных машин.
Заменили виртуальные маршрутизаторы Cisco CSR 1000v, теперь за маршрутизацию отвечают пара Cisco ASR 1001-X
За маршрутизацию у нас теперь отвечают быстрые и надежные роутеры Cisco серии ASR 1001-x. Каждый их них справляется с роутингом трафика до 20 гбит/сек, обеспечивая при этом быструю сходимость, в случае сбоя на каналах провайдеров.
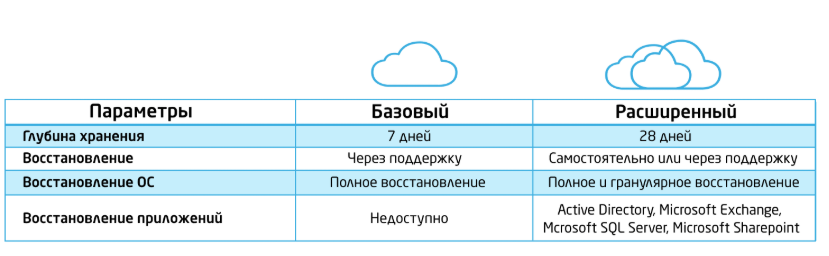
Оптимизировали подсистему резервного копирования
Увеличили ёмкость и уменьшили окно выполнения заданий резервного копирования. Объем данных, хранимых в облаке, постоянно растет, вместе с этим растет и объем данных на системах хранения резервных копий.
Перешли на электронный документооборот
С 1 апреля мы перестали рассылать бумажные документы, обмен документами осуществляется через электронные системы документооборота. Предлагаем вам с 2021 года перейти на ЭДО, если вы этого ещё не сделали.
Анбоксинг и первоначальная настройка коммутаторов Huawei CloudEngine
Проверили возможности Intel Xeon Gold 6254 для работы с 1С в облаке по тесту Гилева
В ноябре мы получили новые серверы с обновленными 20-ти ядерными процессорами Intel Xeon Gold 6242R и тоже их протестировали!
Как управлять облачной инфраструктурой с помощью Terraform
25 Декабря, 2020
Как заблокировать доступ к nginx из других стран
nginx-geo2ip
21 Декабря, 2020
Обновление программ стимулирования
Бонусная программа
При единовременном продлении услуги на 3 месяца на счёт зачисляются 10% от суммы продления, на 6 месяцев — 15% и при оплате на один год зачислим 20%!
Реферальная партнёрская программа
Повысили процент вознаграждения с 5% до 10% и действует реферальная программа для «Быстрых серверов» и услуги «Виртуальные серверы».
Мы предоставляем единовременную скидку за привлечение нового клиента за первый месяц — 40%. Ежемесячная 15% скидка после окончания первого оплаченного периода при объеме продаж до 100 000 р/мес. и 20% от 100 000 р/мес.
01 Декабря, 2020
Обновление цен на лицензии Microsoft в 2021 году
21 Ноября, 2020
Распределенное облако и еще восемь главных трендов в 2021 году по мнению Gartner
- Интернет Поведений (IoB)
- Сеть кибербезопасности (Cybersecurity Mesh)
- Объединенный опыт (Total Experience)
- Интеллектуальный композиционный бизнес (Intelligent Composable Business)
- Гиперавтоматизация
- Операции отовсюду (Anywhere Operations)
- ИИ-инжиниринг
- Распределенное облако
- Вычисления повышенной конфиденциальности (Privacy-Enhancing Computation)
13 Ноября, 2020
Новый релиз Ubuntu 20.10. Что нового?
07 Ноября, 2020
Запускаем роутер Mikrotik CHR в облаке под управлением VMware vCloud Director 10
16 Октября, 2020
Microsoft выпустили ряд обновлений, которые закрывают 87 уязвимостей
Microsoft отключает Flash Player для Windows
12 Октября, 2020
Представлена первая в мире оперативная память DDR5
11 Октября, 2020
Microsoft запланировал приобрести телекоммуникационное подразделение Nokia
30 Сентября, 2020
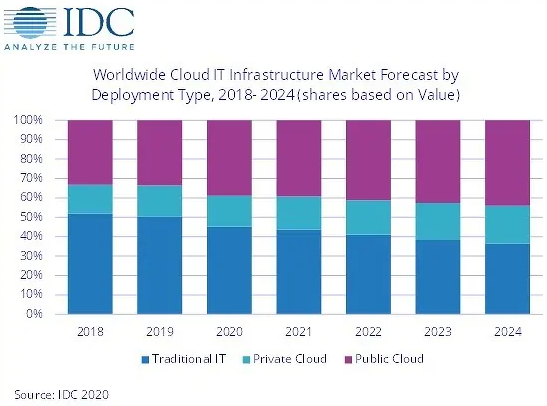
Расходы на оборудование для облаков впервые превысили расходы на традиционную инфраструктуру
 28 Сентября, 2020
28 Сентября, 2020
Локальные серверы или облако? Результат исследования Uptime Institute
uptimeinstitute.com/2020-data-center-industry-survey-results
17 Сентября, 2020
Nvidia планирует выпускать серверные процессоры на базе Arm
10 Сентября, 2020
Microsoft откажется от поддержки Adobe Flash в январе 2021 года
Cisco исправили ряд уязвимостей в Cisco Jabber для Windows
Пользовательские темы для Windows могут похитить ваши данные
04 Сентября, 2020
У Intel Xeon новый логотип: компания обновила брендирование с 2006 года
21 Августа, 2020
Установка и первоначальная оптимизация 1С-Битрикс на VPS
10 Августа, 2020
Маркетплейс Cnews опубликовал первый в России рейтинг SLA облачных провайдеров
Мы рады отметить, что по результатам сравнения облачный провайдер mClouds предоставляет услуги на высшем уровне и входит в топ-10 провайдеров страны (7 место).
29 Июля, 2020
«Мяу-атака» удалила больше 4000 баз данных
Аналитик информационной безопасности Боб Дьяченко обнаружил крупную атаку от анонимной группировки. Одной из первых жертв «мяу-хакеров» стала база данных VPN-провайдера UFO VPN. Злоумышленники украли и удалили с инфраструктуры провайдера пароли, IP-адреса, а также другие конфиденциальные данные людей.
UFO VPN не единственная жертва злоумышленников. По — по данным аналитика последний раз действия хакеров были замечены 20 июля, а в общей сумме уже удалено больше 4000 баз данных.
20 Июля, 2020
В Windows Server обнаружена критическая уязвимость Check Point «SigRed»
16 Июля, 2020
Предоставили облачную инфраструктуру для организации удаленного обучения студентов РГГУ
Считается, что пандемия идет на спад, но она все еще влияет на нашу повседневную жизнь — многие компании оставляют удаленный режим работы, а учебные заведения продолжают внедрять дистанционные методы обучения студентов.
В марте к нам обратился партнер EOS.ru с предложением помочь институту информационных наук и безопасности РГГУ. Учебному заведению требовалось организовать удаленные рабочие места, а также настроить документооборот для своевременной сдачи работ от учащихся.
24 Апреля, 2020
Выпущен релиз Ubuntu 20.04 LTS. Что нового?
13 Апреля, 2020
Высокопроизводительные виртуальные серверы
loud Gold VPS X1 1 vCPU / 4 GB RAM / 40 GB SSD — за 1999Р
Cloud Gold VPS X2 2 vCPU / 8 GB RAM / 40 GB SSD — за 2999Р
Cloud Gold VPS X4 4 vCPU / 16 GB RAM / 70 GB SSD — за 5999Р
Cloud Gold VPS X6 6 vCPU / 24 GB RAM / 70 GB SSD — за 8599Р
Cloud Gold VPS X8 8 vCPU / 32 GB RAM / 90 GB SSD — за 11499Р
31 Марта, 2020
Приостановление бумажного документооборота. Переходим на электронный.
30 Марта, 2020
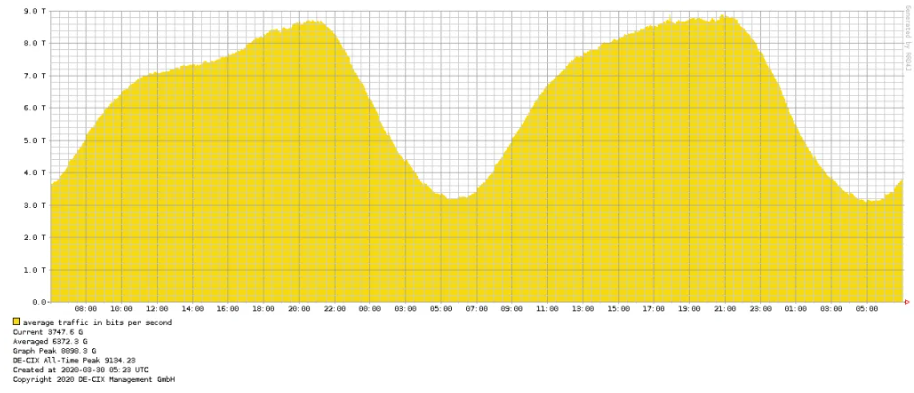
Рекордный уровень передаваемого трафика на DE-CIX и MSK-IX
Вечером 29 марта на площадке DE-CIX во Франкфурте был достигнут трафик рекордного уровня — более 9,1 терабит в секунду! Это не только новый мировой рекорд, это также самый высокий скачок трафика, который когда-либо имел место быть на DE-CIX. Максимальный трафик DE-CIX во Франкфурте за все время, достигнутый в начале марта, составлял 8,3 Тбит/с.
 25 Марта, 2020
25 Марта, 2020
ADV200006: новая уязвимость в Windows
24 Марта, 2020
Удалённый доступ для компаний: переходим на «удалёнку»
Мы все наслышаны о COVID-19 и какие последствия он несёт для людей и для бизнеса. Безопасность сотрудников и организация их удалённой работы — вот какие головные боли стоят перед руководящим персоналом.
23 Марта, 2020
Первоначальная конфигурация виртуального дата-центра
 20 Марта, 2020
20 Марта, 2020
Как управлять облаком на базе vCloud Director 10
 01 Февраля, 2020
01 Февраля, 2020
Новые процессоры Intel Xeon Scalable Gold 6200 3+ ГГЦ доступны в облаке mClouds
У нас хорошие новости для тех, кто ждал доступности процессоров высокой тактовой частоты в нашем облаке, выше 3 ГГц. Сегодня официально анонсируем публичную доступность новых процессоров Intel последнего поколения Xeon Scalable Gold 6200 серии ( Cascade Lake ), анонсированных Intel в 2019 году. В нашем облаке запущен новый кластер на данном типе процессоров, которые значительно производительнее процессоров предыдущих поколений Xeon E5-2600 v1-v4.
Используются 18-ти ядерные процессоры модели Xeon Gold 6254 базовой частотой 3.1 ГГЦ. Особенностью данных процессоров является высокая производительно на одно ядро — частота 3.9 GHz в режиме Turbo Boost на все вычислительные ядра. Также немаловажную роль в производительность вносит высокая пропускная способность оперативной памяти — шести канальная память DDR со скоростью 2933 МГЦ.
Непосредственно вычислительными нодами служат серверы Dell EMC PowerEdge R640, позволяя установить по два таких процессора на один сервер. Серверы имеют по два блока питания, подключенные к независимым источникам питания, а также подключены в сеть по 4-м портам 10Gb/S.
15 Января, 2020
Уязвимость Windows CryptoAPI / CVE-2020-0601
13 Января, 2020
Окончание поддержки Windows Server 2008 и Windows Server 2008 R2
15 Ноября, 2019
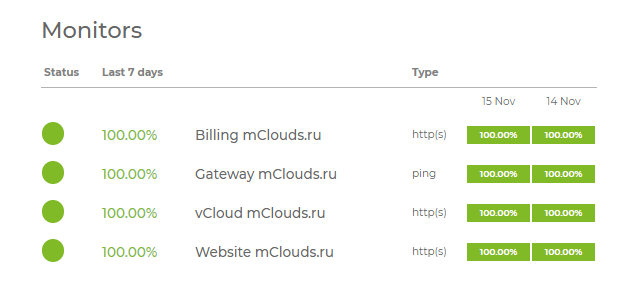
Запущена статус-панель доступности сервисов облака
 29 Октября, 2019
29 Октября, 2019
Резервное копирование в облаке
3-2-1.
Согласно правилу 3-2-1, рекомендуется создавать не менее трёх резервных копий, в двух форматах хранения, где одна из копий будет находится на отдельном хранилище, например, в облаке.
24 Октября, 2019
Как работает DNS?
17 Октября, 2019
Новая версия VMware Tools 11 доступна для установки!
14 Августа, 2019
BlueKeep-2 новая уязвимость для всех версий Windows
29 Июля, 2019
Критическая уязвимость в FTP сервере ProFTPd
17 Июня, 2019
В почтовом сервере Exim в версиях с 4.87 по 4.91 включительно обнаружена критическая уязвимость безопасности, позволяющая выполнить код на сервере с правами root. Это значит, что злоумышленник может получить доступ к серверу пользователя Exim. Так как ISPmanager работает с Exim, владельцы панели тоже под угрозой.
17 Апреля, 2019
Уважаемые клиенты, восстановили доступ к консоли виртуального сервера, подключение осуществляется с панели управления по адресу my.mclouds.ru.
13 Апреля, 2019
Конфликт апрельских обновлений Windows Server с антивирусами Avira, Sophos и Avast
02 Апреля, 2019
Уважаемые клиенты, сообщаем вам, что с 15 апреля 2019 года будут действовать новые тарифные планы для услуг Виртуальные серверы VPS и Виртуальная инфраструктура IaaS.
20 Марта, 2019
Правила базовой безопасности Windows Server
 21 Февраля, 2019
21 Февраля, 2019
Обновление до vCloud Director 9
11 Января, 2019
Windows Server 2019 доступен для Windows VPS
13 Декабря, 2018
Повышение цен на лицензии Microsoft
03 Декабря, 2018
Обновление цен на лицензии Microsoft
21 Ноября, 2018
Экскурсия по дата-центру NORD-4 в 360(VR)
21 Ноября, 2018
SMS уведомления
02 Ноября, 2018
Добавили готовый шаблон Windows Server 2019, теперь любой пользователь IaaS может протестировать новую ОС от компании Microsoft. Образ доступен и в виде ISO в публичном каталоге под названием: SW_DVD9_Win_Server_STD_CORE_2019_64Bit_Russian_DC_STD_MLF_X21-96590.ISO
06 Сентября, 2018
Теперь, при оплате за длительный период начисляются бонусы на баланс в личном кабинете mClouds.ru. Все просто:
Оплата за 3 месяца – 10% на счет;
За 6 месяцев – 15% на счет;
За год – 20% на счет.
23 Июля, 2018
Смена пароля пользователя в Windows Server 2016 / 2012 R2
Создание пользователя Windows Server 2016 / 2012 R2
Установка нового порта подключения RDP в Windows Server 2016 / 2012 R2
19 Июля, 2018
Установка торговой платформы форекс MetaTrader 5
12 Июля, 2018
Уведомляем Вас, что 18.07.2018 с 00:00 по МСК до 04:00 по МСК будут проводиться плановые работы по модернизации оборудования на площадке в Москве (ММТС-9), в связи с чем возможны 2 кратковременных перерыва связи до 5 минут каждый. Данные работы необходимы для улучшения качества оказываемых нашей компанией услуг.
07 Июня, 2018
На субботу 9 июня запланированы технические работы по сетевой части с 19:00 до 22:00.
Возможно кратковременное пропадание доступа в сеть Интернет.
17 Мая, 2018
Вы можете оформить виртуальный сервер VPS с Windows Server и бесплатной лицензией Windows. Наша команда обновила все шаблоны операционной системы Windows Server, установлены все доступные обновления системы. Образы поставляются с предустановленным ПО: Chrome, Firefox, 7-zip.
15 Мая, 2018
Встречаем вторую половину мая со скидкой на тариф Saturn (4 vCPU / 6 GB RAM / 90 GB SSD). Скидка в 20% доступна по промокоду SATURN1599.
09 Мая, 2018
Недавно была обнаружена уязвимость протоколе CredSSP под кодом CVE-2018-0886. CredSSP используется для авторизации пользователей при подключении с помощью RDP. Этот метод подключения используется в Windows Server по умолчанию.
04 Марта, 2018
Уважаемые клиенты, уведомляем Вас, что с 05.03.2018 г. будут изменены тарифы для услуг «Виртуальный сервер (VPS)».
Внимание: Цены применяются только для новых заказов с 05.03.2018.
05 Февраля, 2018
Обновили шаблоны Windows Server 2012 R2 и Windows Server 2016. Образы поставляются с предустановленным ПО: Chrome, Firefox, 7-zip и с обновлением образа системы.
25 Января, 2018
Обновление цен
Уважаемые клиенты, уведомляем Вас, что с 01.02.2018 г. будут изменены цены на ресурсы для услуг «Виртуальный сервер (VPS)» и «Виртуальный Центр Обработки Данных (IaaS / VDC)».
Внимание:
Цены применяются только для новых заказов с 01.02.2018.
23 Января, 2018
Дата-центр NORD-4 прошел сертификацию Uptime Institute Tier III: Operational Sustainability
16 Ноября, 2017
Облачный виртуальный сервер от mClouds.ru показал результаты на уровне 48 баллов, этот показатель близок к замечательному, и можно с уверенностью сказать, что облачные серверы mClouds.ru и тариф Saturn идеально подходят в качестве платформы для размещения 1С: Предприятия!
13 Ноября, 2017
Производительность виртуальных серверов mClouds.ru
 03 Ноября, 2017
03 Ноября, 2017
Как устроена система мониторинга холодоснабжения нашего дата центра
Наши коллеги из дата-центра NORD-4 компании Даталайн, в котором находится наше оборудование, рассказали о том, как устроена система мониторинга холодоснабжения в дата центре.
14 Сентября, 2017
Хостинг для 1С-Битрикс
20 Августа, 2017
Обновление реквизитов
16 Августа, 2017
Внедрили бесплатное резервное копирование на всех тарифы VPS и IaaS
Бэкап будет производиться автоматически каждую субботу в 00:00 по МСК. Глубина копирования — 7 дней, т.е. мы будем хранить 2 ваши резервные копии (ближайшую прошедшую субботу и субботу до нее).
17 Июля, 2017
Запускаем бонусную программу для пользователей VPS и IaaS!
При оплате за 3 месяца получайте 10% на баланс, за 6 месяцев – 15%, за год – 20%. Действующие клиенты, воспользовавшиеся услугой до 1 июля так же попадают под действие программы.
06 Июня, 2017
Identity-as-a-Service (IDaaS). Что это?
02 Июня, 2017
Cisco CSR 1000v: Надёжность – залог успеха. Часть 2
15 Мая, 2017
WannaCry: что произошло и как защититься
12 Мая, 2017
Производительность ЦОД в твоём кармане
В итоге, мы идём к тенденции, когда мобильное устройство будет являться только экраном для воспроизведения контента, а обработка информации будет происходить на серверах в дата-центрах.
11 Мая, 2017
Скорость решает все!
Проектируя нашу инфраструктуру, мы поставили себя на место заказчика, а также посмотрели на время — на дворе был таки январь 2016 года. Что мы видим со стороны заказчика? Мы опросили потенциальных клиентов на VPS серверы. По большей вывод по результату опроса был простой — заказчики совершенно не хотят еще и в облаке тратить время на выбор типов дисков, как с одних на другие потом переходить, в случае если не будет хватать производительности. Хотят быстрый массив для своих серверов. И хотят этот массив на SSD дисках — в абсолютном большинстве случаев это дает заметно бОльшую производительность.
Со стороны 2016 года — мы были уверены в двух вещах. SAS диски на шпинделях — время оставшейся жизни 2-3 года, потом все, отомрут как SCSI, стоят дорого, скорость дают так-себе. Строить дисковую подсистему на SAS — недальновидно и заранее проигрышно в долговременной перспективе. Минусы — для дистижения хотя-бы 10 000 IOPS надо ставить пару полок по 25 дисков SAS 10к. Это не особо энергоэффективно, и не очень то быстро, и со временем будет занимать кучу места в стойках. Все эти кучи полок вы наверное уже видели на многочисленных брутальных фото из ЦОДов. Все это скоро уйдет в историю. Те, кто это замечают, уже с достаточно высокой скоростью переходят на flash диски. Это вопрос буквально пары-тройки лет. Вряд-ли дольше. Вот что мы думаем по этому поводу.
Подводя итог нашему краткому обзору и отвечая на вопрос в заголовке… Мы считаем что облачные серверы, будь то одиночные пулы VPS серверов, или же полноценный набор ресурсов по модели IAAS — в 2017 году должны быть только на SSD хранилищах, обеспечивая стабильно высокую скорость отклика приложений, и не заставлять заказчика делать выбор в заранее проигрышную сторону, погружая его в думы, что разместить на средних дисках, что на медленных, а что на быстрых. Все бизнес приложения должны быть на быстром хранилище, без компромиссов. Исключение мы допускаем только для архивных данных.
27 Апреля, 2017
Huawei CloudEngine 6800: обзор и опыт использования
11 Апреля, 2017
Cisco CSR 1000v: Обзор возможностей. Часть 1
10 Апреля, 2017
Обзор дата-центра NORD4
03 Апреля, 2017
В апреле 2017 года исполнится год, как запущен в коммерческую эксплуатацию проект mClouds.ru, основная цель которого — предоставление ресурсов хранения и вычисления для b2b-клиентов. За прошедшее время нами был получен интересный опыт, от выбора технических решений до решения факапов, которым мы хотим поделиться с вами. История первая — о муках выбора ЦОД в самой большой стране мира. Собственно, от величины проблемы и начались.
Проект запущен системным интегратором «Мастер», базирующемся в г. Тюмень, как у нас говорят — Лучшем городе земли. Идея запуска mСlouds.ru состояла изначально не в том, чтобы выходить на открытый рынок облачного хостинга,
а в том, чтобы предоставить своим b2b-клиентам вычислительные ресурсы для песочниц и резервных нужд, как например генерация отчётов, удалённый репозиторий для резервных копий, внешний мониторинг, не основные базы данных. Также решение покрывает потребности небольших компаний SMB сектора в серверах, используемых для 1С: Предприятия. Если учесть, что с ростом курса доллара покупать собственные серверы, не говоря уж о обеспечении их ИБП, охлаждением и прочей инфраструктурой, стало отнимать много финансовых ресурсов. Поэтому внутри нашей компании было принято решение — развить собственное облачное направление, благо технический бэкграунд наших инженеров это позволял и позволяет.
Нами был поставлен срок выхода в продуктивную среду на первые числа апреля и в течение трёх месяцев мы обкатывали программные и аппаратные возможности на базе платформы VMware vSphere. Кроме того, нам удалось адаптировать для облачной инфраструктуры многие Enterprise-решения, и это интересный опыт, которым мы хотим поделиться.


Наш проект начал работать в Центре Компетенций (далее по тексту ЦК) на базе нашей компании, поэтому вопроса о выборе площадки не было. Мощности охлаждения и ИБП вполне хватало для обеспечения корректной работы подсистемы охлаждения и энергопитания. Однако ближе к намеченной дате выхода на рынок обозначилась проблема, где проект должен будет жить? Учитывая, что мы находимся не в Москве или Санкт-Петербурге, где с этим нет никаких проблем (все-таки там сосредоточено большинство всех коммерческих центров обработки данных в стране), то для Тюмени это вовсе не тривиальный вопрос.
Итак, в Тюмени есть всё что угодно, кроме грамотных коммерческих ЦОД, а с таким термином как TIER 3 здесь знакомы не все, включая те площадки, которые мы посетили для ознакомления. Есть корпоративные серверные помещения, несколько государственных ЦОД, площадки телеком-провайдеров, но как таковых коммерческих ЦОД нет, не говоря уж о какой-либо их сертификации. С каналами интернет тоже не все благополучно, например, подключение с пропускной способностью в 1Гбит/сек стоит совсем дорого. Если сказать о том, что канал должен иметь перспективу роста до 10 Гбит/сек, то глаза и вовсе округлялись, на лице или по телефону считывалось, что ребята первый раз услышали запросы на такие скорости в нашем регионе. Так что мы начали смотреть на ЦОДы в РФ.
Екатеринбург — в данном городе есть ЦОД операторов связи, например Мегафон и Ростелеком. Но в процессе общения мы поняли, что предоставление и уровень сервиса, требуемый для облачного провайдера, это не к ним, так как они сами акцентируют внимание больше на предоставление вычислительных ресурсов, нежели на предоставление услуги по размещению оборудования. В итоге, адекватный ценник мы так и не получили, продолжаем изучение.

Дата-центр ГАУ «ИТ-ПАРК», республика Татарстан
Казань — здесь уже всё получше, есть ИТ-парк, Иннополис, видно что в ИТ тут понимают, интересуются и любят это направление. Достаточно профессионально подходят, но опять уже учитывая наше расположение — логистически нам очень уж неудобно до Казани добираться. Поэтому тонких моментов, как инженерку, SLA и каналы связи не рассматривали.

Начали обзор рынка с Санкт-Петербурга. Первый дата-центр (далее ДЦ), на который обратили внимание оказался ЦОД SDN. Достойный уровень инженерных систем с довольно чётким описанием, интересные соседи, например ВКонтакте, адекватная цена, уровень общения и готовность отвечать на все наши вопросы. Далее были рассмотрены услуги colocation от Selectel, Fiord и других ДЦ. Мы почти приняли для себя решение размещать mClouds.ru именно в питерском SDN. Однако на весы опять встала логистика, хоть в SDN есть услуга удалённых рук, тем не менее в случае какой-либо нештатной ситуации (да и штатной тоже) мы не смогли бы оперативно десантироваться в Питер, учитывая что мы физически находимся в Тюмени и, увы, в Санкт-Петербург до нас всего один рейс в день, — а это очень высокие риски по сроку реагирования. Однако для тех, у кого нет сложностей с логистикой до Питера, SDN однозначно один из лучших среди рассмотренных вариантов, как нам кажется.
Рынок коммерческих ЦОД Москвы, конечно, самый крупный. Тут есть из чего выбрать. Сами ЦОДы мы разделили на несколько категорий:
- ЦОД крупных интеграторов
- коммерческие ЦОД, сертифицированные по программе Uptime Institute
- ЦОД телеком-операторов
- небольшие и самостоятельные коммерческие ЦОД, заявляющие соответствие уровню Tier 3
- площадки различных хостеров, от самостоятельных до выделенных зон в крупных коммерческих ЦОД
- Рассмотрим первую категорию. Основные потребители услуг — заказчики интеграторов, им же и основной приоритет. На наш взгляд, ориентация явно не на небольшие проекты. Примеры — ЦОД «Компрессор» компании КРОК, ЦОД «Траст-Инфо» от Ай-теко.
- Вторая категория. Ассоциации — красиво, круто и… дорого. Из первичного отбора мы выделили три компании: DataSpace, DataPro и Dataline. Посмотрели, облизнулись и пошли дальше. В данные ДЦ надо приходить когда проект уже подрос, ну что же, ушли расти.
- Третья категория — это ЦОД телеком-операторов. Достаточно низкая гибкость за счёт постоянных и очень долгих согласований, долгие ответы менеджеров, отсутствие доступа к оборудованию в ночное время и порядок цен, сопоставимый с сертифицированными ДЦ.
- Четвертая категория. К слову сказать, из этого категории мы и выбрали наш будущий дом для проекта. Выбрали ЦОД, который позиционируется как сеть клубных дата-центров. Понравились быстротой реакции, готовностью все показать и рассказать, связностью с другими площадками, готовностью получить наше оборудование из транспортной компании и своими силами смонтировать его в стойке, что для нас означало значительную экономию на командировках инженеров. Инфраструктура ЦОДа подходила под наши требования.
Забегая вперед скажу, что проработали мы в выбранном ЦОД до конца 2016 года. В течении года был один простой летом на 2 часа 30 минут из-за сбоя в системе кондиционирования, и сбой сетевого оборудования ЦОДа, в результате мы потеряли каналы связи до внешнего мира на несколько часов. К сожалению, компетенций сотрудников ЦОДа не хватило для быстрого устранения сбоя и как впоследствии мы узнали, на площадке не было резервного оборудования. Сделали выводы и устранили возможное повторение такой ситуации в будущем. Всем клиентам были вынуждены компенсировать месячную абонентскую плату, хоть формально и оставались в рамках SLA. А ведь ЦОД это все-таки основа, фундамент работоспособности оборудования. Это запишем в минусы этой категории ЦОДов.
Пятую категорию мы серьезно не рассматривали. Тут собственные ЦОДы хостинг-провайдеров, которые переделаны из каких-либо помещений и с тем или иным успехом эксплуатируются. Инвестиции в собственные площадки достойны уважения, но мы считаем, что купить профессиональную услугу и сервис будет более функционально и надёжно. Но экономика, конечно, может пострадать, что отразится на конечной стоимости услуги.
Как итог мы с нового 2017 года работаем в сертифицированном ЦОД NORD4 по программе TIER 3 от Uptime Institute, компании Dataline. Очень адекватный сервис, высокая гибкость и, самое главное, — высокая надежность. Детально прописанный договор и подробный SLA по работоспособности и реакции. На Хабре уже были обзоры этого ЦОД и подробное описание инфраструктуры.
01 Марта, 2017
Обновление системы резервного копирования
Выполнили апгрейд подсистемы резервного копирования, в результате чего показатели восстановления виртуальных машин были снижены на 25%.
Мониторинг виртуальных машин
Добавлен мониторинг виртуальной инфраструктуры для корпоративных пользователей: администраторы системы могут видеть полную информацию об утилизации ресурсов и просматривать линию тренда на основании прошедших меток производительности системы. Это позволит отследить утилизацию виртуальных машин и вовремя увеличить или уменьшить количество используемых ресурсов.
01 февраля, 2017
New TIER3 certified DC
С января месяца все клиенты размещаются в дата-центре NORD4, сертифицированном по программе Uptime Institute Tier III: Design и Uptime Institute Tier III: Constructed Facility.
All-flash storage
Мы полностью перешли на all-flash массив с тремя основополагающими принципами: отказоустойчивость, быстродействие и масштабируемость.
За отказоустойчивость отвечают передовые технологии от компаний EMC и VMware, которые позволяют вывести из эксплуатации несколько серверов без потерь данных.
Быстродействие и надёжность гарантируется с помощью дисков Intel S3520 Datacenter Class.
Intel Xeon E5 ready
Произвели унификацию вычислительных ресурсов, теперь за высокопроизводительные вычисления отвечают процессоры линейки Intel Xeon E5-2670 (2.6 GHz), которые могут обеспечить комфортную работу бизнес приложениям, например, 1C: Предприятие.
10G only
Обмен данными между виртуальными серверами возможен на скорости 10G, где высокую пропускную способность и малую задержку обеспечивают коммутаторы линейки Huawei CloudEngine 6800.