https://timeweb.cloud
30 июня 2026 Про перегретый дата-центр
https://timeweb.cloud
30 июня 2026 Про перегретый дата-центр
В мае мы рассказывали, как перевезли инфраструктуру в зоне ams-1 из закрывающегося ЦОДа в новый.
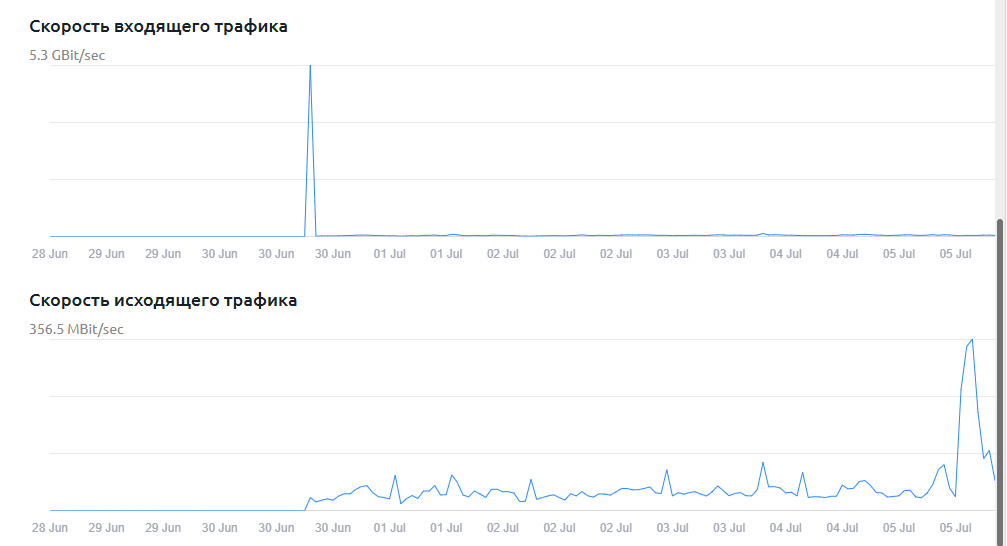
Сценарий, где новый дата-центр с полноценной системой охлаждения и резервирования, выходит из строя, потому что чиллеры вышли из строя, было сложно себе представить. Но он произошел.
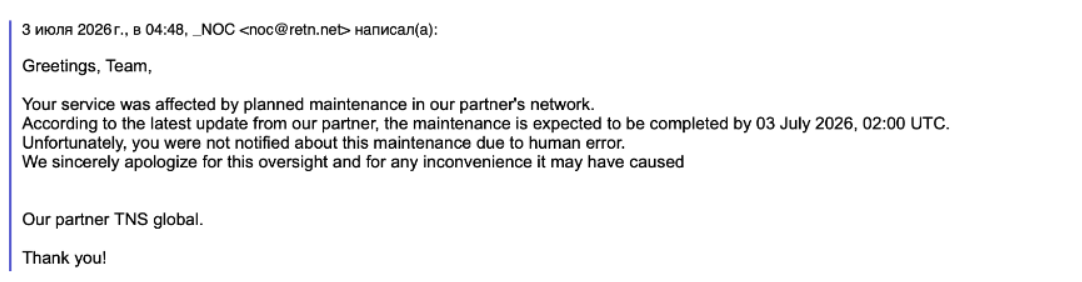
В дополнение к этому цепочка подрядчиков, отвечающих за обслуживание охлаждающего оборудования со стороны ЦОДа ведет себя в лучших традициях анекдотов. Медленно, малоэффективно и абсолютно без какой-либо конкретики по срокам. Вот что нам ответили буквально час назад.
Попытки запустить отказавший чиллер не увенчались успехом. Сейчас ЦОД организовал срочную поставку новых силовых кабелей (вероятно для подключения внешнего чиллера к сети ДЦ) — обещают завтра до 12-14 мск. Параллельно ЦОД привлекает дополнительного профильного специалиста для углубленной диагностики и восстановления узла системы охлаждения, но он будет там завтра утром.
Это не соответствует ни нашим ожиданиям, ни нашим стандартам качества и обслуживания.
Мы запустили процесс по поиску нового ЦОДа и дальнейшей миграции оборудования. Но честно — процесс это не быстрый, бюрократичный и требует предварительного согласования многих технических деталей. Особенно учитывая локацию и текущие реалии.
Писать в саппорт с вопросами по срокам не особо целесообразно, так как мы сами ждем информацию.
Как есть.
24 июня 2026 Обновили ядро Linux на всех Ryzen-серверах в Москве

В копилку стабильности — и с конкретным обновлением под капотом.
Во время работы с высокопроизводительными серверами на Ryzen 7950X нашли причину редких зависаний нод. На старом ядре Ubuntu 22.04 эти процессоры могли работать нестабильно.
Это могло обернуться внезапной недоступностью виртуальных машин, хотя с самими проектами все было в порядке.
Чтобы устранить проблему, обновили ОС и ядро на всех Ryzen-серверах в московской локации.
Переезд выполнили поэтапно: сначала подняли резервные серверы, перенесли на них проекты и только потом приступили к обновлению основных хостов. Поэтому пользователи не столкнулись с простоем.
Теперь гипервизоры работают на новом ядре, а риски возможных зависаний нод осталась в прошлом.
Если вам нужны мощные серверы в Москве, есть еще одна новость — расширили парк Ryzen 7950X, чтобы было больше доступных конфигураций под ваши проекты.
19 июня 2026 AI-агенты в связке с Cline, Codex и OpenCode
Наших AI-агентов и AI Gateway можно использовать прямо в инструментах разработки.
Подключаете один раз → и дальше задаете вопросы по проекту, редактируете код и запускаете команды в терминале — прямо в рабочем окне.
Как это устроено: среда обращается к модели через OpenAI-совместимый API по вашему ключу. Используете наши модели и инфраструктуру, а интерфейс — привычный редактор или окно чата.
Подключение сводится к трем полям в настройках расширения:
- 1. Тип провайдера — OpenAI Compatible
- 2. Базовый URL агента или AI Gateway
- 3. И, наконец, ваш API-ключ.
Дальше можно отправлять запросы модели прямо из кода. Если используете AI Gateway, в настройках доступны и параметры генерации — размер контекста, лимит токенов, температура.
Подробнее о каждой среде в доке →
Cline,
Codex и
OpenCode.
18 июня 2026 История USmall — хайлоад изнутри
6+ млн товаров, 130 ритейлеров и до 70 млн запросов во время распродаж. Мигрировали USmall в наше облако и записали видеокейс о том, как устроена инфраструктура такого проекта.
Из любопытного:
- 1. 130 площадок — 130 изолированных контуров. На каждую свой репозиторий и Docker-образ. Релизы независимы, все изменения изолированы.
- 2. Свой механизм иерархических подов. В основе паттерн одноразовых подов — каждый выполняет один цикл и завершается. Поверх него команда построила иерархию, где родительский под запускает дочерние. Так обходят ограничение Python по пропускной способности одного воркера и обрабатывают задачи параллельно.
- 3. Выделенный сервер под оркестратор. Когда Airflow потребовалась отдельная конфигурация, под него собрали сервер на двух 32-ядерных процессорах и перенесли без простоя.
- 4. AI прямо в Kubernetes-кластере. В тестовом режиме крутится нейросеть, которая ускоряет подключение новых магазинов.
Все это команда ведет сама — новые ноды добавляет за пару минут через панель, без отдельных DevOps-инженеров. А инфраструктура у нас вышла на 35% дешевле прежнего провайдера — при том же объеме.
В видео Станислав, руководитель Python-разработки USmall, рассказывает про архитектуру и почему выбрали наше облако.
Смотреть видеокейс на
ютубе,
рутубе и в
вк.
Или читать подробный разбор на сайте →
timeweb.cloud/success-story/usmall
17 июня 2026 IPv6 в базах данных
Теперь облачной базе данных можно выдать бесплатный публичный IPv6-адрес.
Полезно, если:
1. Уже раскатали IPv6 в своей инфраструктуре и не хотите держать IPv4 только ради базы
2. Масштабируете проект и постепенно уходите от дефицитных IPv4-адресов
3. Строите cloud-native или корпоративную инфраструктуру, где важна поддержка IPv6.
Подключается в пару кликов: при создании новой базы или в настройках существующей «Сеть» → «Публичный IPv6-адрес». Если переключателя IPv6 у базы нет — значит, на вашей сети он пока недоступен.
При защищенном TLS-подключении адрес автоматически привяжется к техническому домену базы. Остальные детали в документации →
timeweb.cloud/docs/public-ip/ipv6-adresa
Фича появилась не случайно — ее давно просили в разделе идей (тут и тут), теперь она в проде.
Привязать айпишник к базе
16 июня 2026 Получили награду от Иннополиса
Посетили закрытую встречу резидентов и партнеров Иннополиса с участием руководства Татарстана. Обсудили совместные планы и получили неожиданную, но приятную статуэтку (на фото).
Напомним, что осенью прошлого года наш офис переехал в Казань, где мы участвуем в развитии ИТ-среды и выстраиваем сотрудничество с Университетом Иннополис.
Рады, что коллеги отметили нашу динамику. А ведь времени прошло всего ничего.
Вдохновляет
16 июня 2026 Изменение цен на выделенные серверы
С 1 июля 2026 года цены на выделенные серверы в Москве и Санкт-Петербурге вырастут на 12%.
Причина: рост цен на стойки и серверы со стороны поставщиков.
Цена на выделенные серверы в других локациях, серверы с GPU, расширение канала и доп IP-адреса остаются без изменений.
Рекомендуем заблаговременно внести на баланс сумму, достаточную для оплаты серверов по новым тарифам.
11 июня 2026 Хранилище S3-бакетов и сетевых дисков в Петербурге перевалило за 6 петабайт
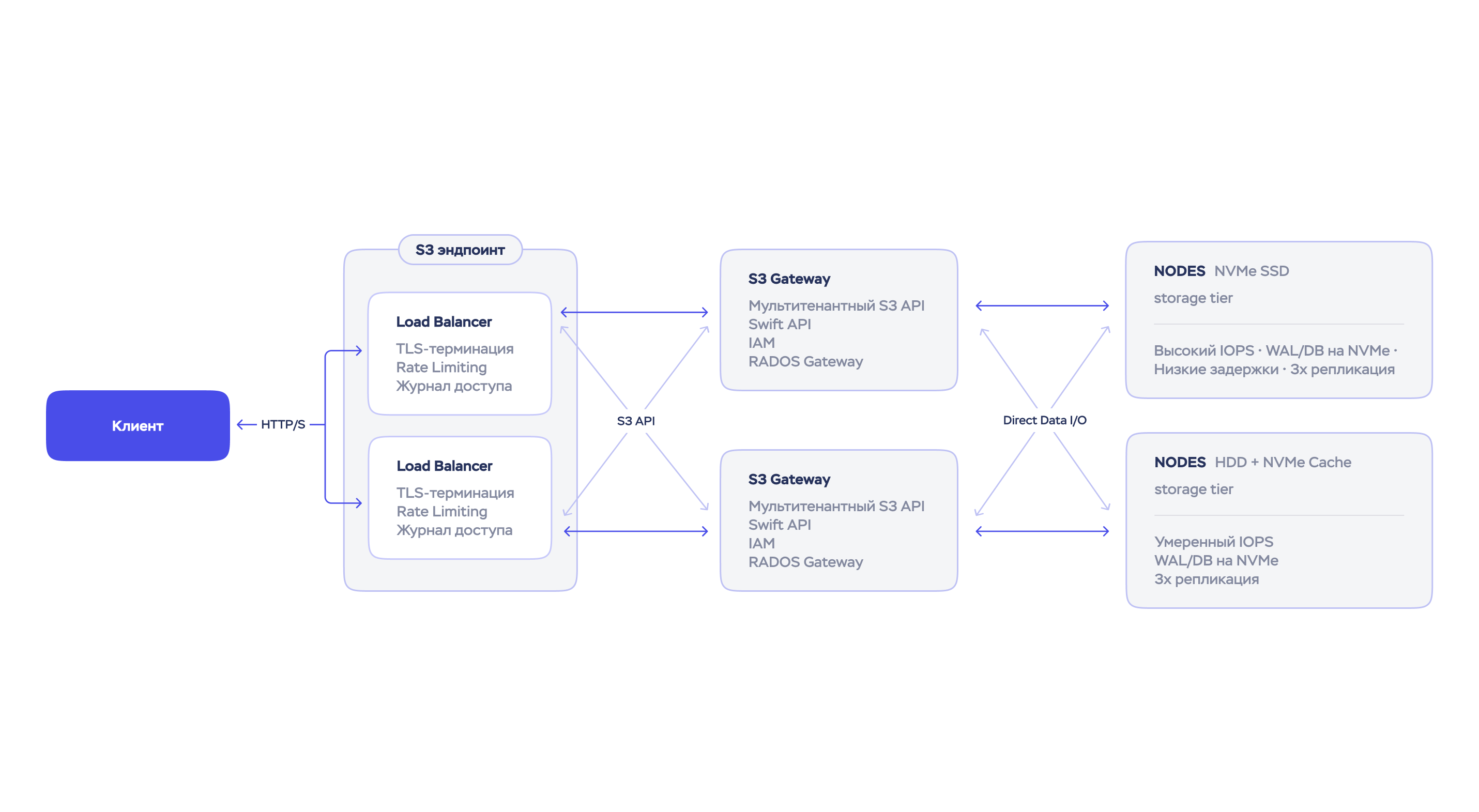
В прошлых новостях про инфраструктуру рассказали, как облако устроено изнутри. Сегодня спускаемся уровнем ниже — в кластер, где физически лежат ваши бакеты и сетевые диски. Повод подходящий — после ввода двух новых нод общая емкость кластера превысила 6 петабайт.
Две трети этого объема занимают запасные копии, и так задумано. Все объекты реплицируются трижды — на разных серверах и в разных стойках.
Зачем столько копий? Диски — расходник и ломаются без расписания: бывают месяцы без единой замены, а в прошлом поменяли сразу три из 436 накопителей кластера.
Каждая замена проходит незаметно для ваших проектов: вышел из строя диск → кластер за пару часов восстанавливает копии на соседних нодах, и данные все это время можно читать и записывать.
Что под капотом. Ceph-кластер из 27 серверов с двумя тирами: быстрые NVMe-ноды — под активные данные, емкие HDD — под архивы и объекты, к которым обращаются редко. Между уровнями данные распределяются автоматически.
Кластер растет быстро. В феврале 2024 года в нем было три ноды и 70 терабайт под данные клиентов, сейчас — 27 нод и 2 петабайта. В 30 раз больше за два с половиной года.
Недавно добавили еще две ноды — одну в горячий тир, одну в холодный, ввели без окон обслуживания, данные перераспределились фоном.
6 петабайт — не предел. Про новые отметки расскажем в следующих постах.
10 июня 2026 Запустили мониторинг сервисов
Теперь можно отслеживать стабильность работы сайтов, серверов и приложений, размещенных в нашей инфраструктуре или на сторонних платформах.
Если что-то пойдет не так, вы сразу получите уведомление на почту, в Телеграм или Макс. О восстановлении — тоже.
Что можно мониторить:
Сайты и веб-приложения. Интернет-магазин упал ночью — узнаете сразу, а не утром по потерянным заказам.
Доступность серверов. Сервер перестал отвечать на запросы — среагируете до того, как это заметят остальные.
TCP-порты сервисов — базы данных, почта, API. База перестала отвечать — увидите до того, как приложение начнет спамить юзеров ошибками.
SSL-сертификаты. Продлите сертификат заранее — пока пользователи не заметили в браузере предупреждение о небезопасном соединении.
Проверки идут из нескольких регионов — без ложных алертов из-за временных сетевых сбоев.
Бонусом: история инцидентов по каждому сервису, дашборд с аптаймом, настройка интервала и таймаута, пауза без потери настроек. Подробнее в документации →
timeweb.cloud/docs/monitoring
Стоимость — 30 ₽ в месяц за сервис, списания почасовые.
Подключить мониторинг →
timeweb.cloud/my/monitoring
8 июня 2026 Последние инфраструктурные изменения
Атака на DNS, отказ диска, плановые работы на хосте — раньше это могло влиять на работу ваших проектов. С ростом числа клиентов и нагрузок прежние архитектурные решения перестали справляться.
Перестроили инфраструктуру по трем направлениям так, чтобы такие ситуации проходили для вас незаметно — или с минимальным эффектом.
1. Защитили исходящие запросы ваших серверов
Приложения регулярно обращаются к внешним сервисам по доменным именам — платежным шлюзам, API, базам, репозиториям. Каждый запрос проходит через наши DNS-резолверы. При мощной атаке на них запросы могли подвисать или не доходить — приложения теряли связь с внешним миром, даже когда серверы работали штатно.
Развернули резолверы по схеме anycast: запрос уходит на ближайший доступный узел → нагрузка распределяется между всеми. Атака на один узел не выводит DNS из строя — остальные продолжают отвечать, и приложения работают стабильно.
2. Отвязали данные от конкретного хоста
Внедряем сетевое хранилище NVMe-oF вместо локальных дисков. Начали с Москвы, постепенно раскатываем дальше.
На практике: если у конкретной ноды отказывает железо, сервер быстрее перезапускается на исправном оборудовании. Не нужно ждать, пока починят именно эту ноду, или разворачиваться из бэкапа.
3. Сделали миграцию виртуальных машин универсальной
С ростом числа клиентских конфигураций уперлись в корнер-кейсы — на некоторых миграция могла подвисать или требовать остановки сервера. Теперь переносим серверы быстро и без даунтайма в любом конфиге. Обычно в трех сценариях:
Плановые работы на железе: на время обслуживания хоста мигрируем машины на другой.
Балансировка: если хост перегружен, переносим часть виртуалок на свободный.
Проблемное железо: если нода ведет себя нестабильно, сразу запускаем миграцию до реальных сбоев.
Главная идея — закладывать запас прочности, чтобы инфраструктура справлялась и с текущим ростом, и с нештатными ситуациями.
P.S. Инженеры уже пишут статью на Хабр про факапы и победы в росте инфраструктуры. Пишите в комментариях, что хотите там увидеть — разберем.
3 июня 2026 Поручить работу с сервисами своему AI-агенту
Чтобы поднять сервер, базу и бакет под новый проект — можно просто создать AI-агента в связке с Timeweb Cloud MCP. Пишете агенту, что нужно, он запрашивает подтверждение и после вашего разрешения берется за работу.
Причем наш MCP можно подключить и к стороннему агенту — например, Cursor, Claude или своему боту. Подробнее про подключение → в доке.
Из последних апдейтов — открыли для MCP почти весь публичный API. Доступны все методы, кроме удаления, добавим их позже.
Что вы можете поручить агенту в связке с Timeweb Cloud MCP:
Запустить инфраструктуру с нуля
Создай сервер на Ubuntu 24.04 с 4 ГБ RAM в Москве для тестов
Мониторить работу
Покажи список серверов и их статус, а еще оцени состояние кластера
Собрать контур под проект
Создай балансировщик и добавь в него 2 сервера, а потом настрой приватную сеть между ними
Запустить AI-агента с поддержкой MCP →
timeweb.cloud/my/cloud-ai/tools
2 июня 2026 Под капотом управляемых сервисов
Вместе с инфраструктурой и сетью продолжаем менять то, что напрямую влияет на стабильность. Сегодня подробнее про управляемые сервисы — базы данных, кластеры Kubernetes, балансировщики и др.
Главное — перестроили процесс развертывания сервисов.
Теперь задачи разделены: cloud-init поднимает сервис при создании, а фоновая служба агента на инстансах DBaaS обслуживает его дальше.
Что это значит для вас — сервисы в среднем создаются на 3 минуты быстрее. А за счет сокращения задержки между запросом из панели и его выполнением агент оперативнее применяет изменения.
Параллельно:
1. Пересобрали образы ОС под сервисы. Вместо универсального образа у баз данных, Kubernetes и других сервисов теперь свой минимальный образ только с нужными зависимостями. За счет этого сервис создается быстрее и не зависит от состояния внешних репозиториев.
2. Подняли все версии PostgreSQL до последних минорных. Обновили линейки 17.x, 16.x, 15.x — чтобы у вас был доступ к стабильным версиям с закрытыми уязвимостями.
3. Усилили безопасность управляемых баз. Перенесли сетевую изоляцию на уровень гипервизора виртуальной машины и пересмотрели список доступных расширений PostgreSQL.