Вы слышали об IP-адресах и IPv6? Адрес Интернет-протокола (IP-адрес) — это цифровая метка для идентификации и определения местоположения сетевых устройств. Каждое устройство, подключенное к любой компьютерной сети, которая использует Интернет-протокол для связи, будет иметь IP-адрес.
Его основные цели — идентифицировать сетевой интерфейс устройства и указывать местоположение хоста в сети, тем самым устанавливая путь к этому хосту. Если вы умеете читать этот текст, значит, у вашего компьютера должен быть IP-адрес.
Инженерная группа Интернета (IETF) и IANA впервые развернули исходную версию Интернет-протокола в 1983 году и назвали ее Интернет-протоколом v4 (IPv4). Каждый адрес IPv4 имеет 32 бита, что ограничивает адресное пространство до 4 294 967 296 доступных адресов. Может показаться, что это много, и еще в 1983 году этого, безусловно, было достаточно для нужд всех пользователей Интернета. Но к концу 1990-х, по мере того, как использование Интернета росло и росло, стало очевидно, что это не так, и многие провайдеры интернет-услуг увидели быстрое исчерпание своих доступных адресов IPv4.
В Интернете появилось все больше и больше услуг, и изменилось использование Интернета в домашних хозяйствах. В то время как общего IP-пула было достаточно для большого числа пользователей, которые были подключены всего несколько часов в день с использованием коммутируемых соединений, ситуация изменилась по мере того, как широкополосные соединения становились все более и более распространенными. Будучи подключенным круглосуточно, каждому абоненту теперь требовался выделенный IP-адрес.
Все это побудило к созданию новой версии Интернет-протокола для решения этих проблем. Новая версия протокола была разработана и выпущена в 1998 году и получила название Internet Protocol v6 (IPv6). Размер IPv6-адреса составляет 128 бит, поэтому в его адресном пространстве имеется около 340 282 366 920 938 000 000 000 000 000 000 000 000 уникальных IP-адресов. Или записано цифрами: 340 триллионов, 282 миллиарда, 366 миллионов, 920 тысяч, 938 — с последующими 24 нулями. Достаточно, чтобы каждый атом на поверхности Земли имел IP-адрес. Предположим, этого нам хватит на некоторое время.
После нескольких лет тестирования новый протокол получил более широкое распространение в течение 2000 года. Поскольку последний доступный блок IPv4 / 8 был назначен в апреле 2018 года, мы сейчас находимся в ситуации, когда текущие потребности IPv4 могут быть удовлетворены только путем восстановления неиспользуемых подсетей или обмен IP-адресами между поставщиками услуг. Поскольку Интернет растет с каждым днем, полное исчерпание IPv4, без каких-либо адресов для обмена или подсетей для использования, не за горами. Вот почему в Scaleway мы поощряем использование IPv6 в ваших производственных системах. В этом сообщении блога мы объясним, как использовать IPv6 в различных продуктах Scaleway.
В Scaleway Elements и Scaleway Dedibox все виртуальные экземпляры и выделенные серверы совместимы с IPv6, а возможность подключения по IPv6 предоставляется без каких-либо дополнительных затрат.
IPv6 в виртуальных экземплярах Scaleway Elements
Виртуальные экземпляры Scaleway Elements имеют подсеть / 64 IPv6 каждый. Подсеть статически маршрутизируется к виртуальному экземпляру, и по умолчанию для каждого из ваших экземпляров настроен один IPv6-адрес. Вы можете увидеть настроенные адреса IPv4 и IPv6 вашего экземпляра, а также сетевую маску и информацию о вашей подсети на странице информации об экземпляре каждого виртуального экземпляра:
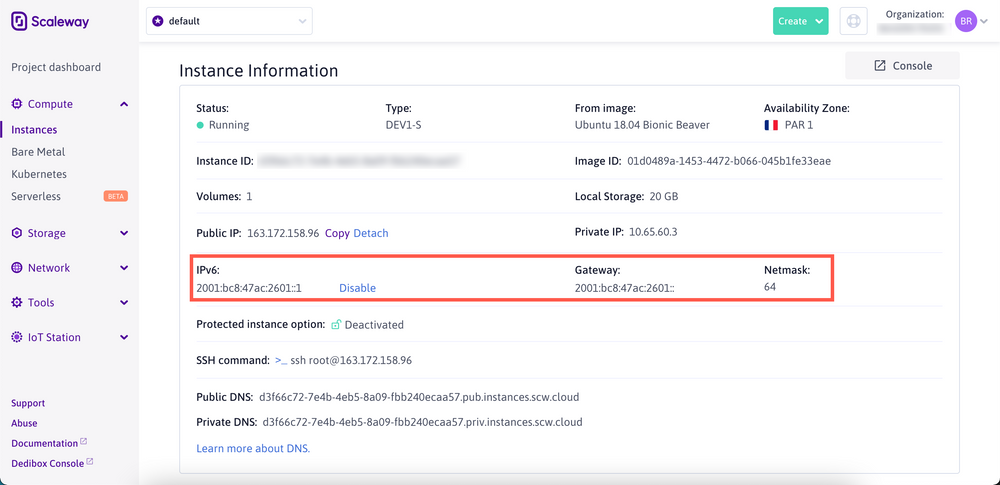 IPv6 в частных сетях Scaleway на виртуальных экземплярах
IPv6 в частных сетях Scaleway на виртуальных экземплярах
Частная сеть на Scaleway Elements — это сеть Ethernet второго уровня, подобная локальной сети. Новый сетевой интерфейс с уникальным адресом управления доступом к среде передачи (MAC-адресом) настраивается на каждом экземпляре в частной сети. Это виртуальные, но полностью частные локальные сети, которые надежно соединяют ваши экземпляры, не открывая их публично. Каждая частная сеть полностью совместима с IPv6. Чтобы настроить IPv6 в своей частной сети, вы всегда должны использовать подсеть / 64, и мы рекомендуем использовать диапазон уникальных локальных адресов (ULA) fc00 :: / 7. Генераторы адресов ULA IPv6 широко доступны для создания персонализированного диапазона.
IPv6 на балансировщиках нагрузки Scaleway
Управляемые балансировщики нагрузки Scaleway — это высокодоступные и полностью управляемые экземпляры, которые распределяют рабочие нагрузки между вашими серверами. В настоящее время общедоступный интерфейс балансировщиков нагрузки поддерживает IPv4, и скоро появится поддержка IPv6. Однако вы уже можете использовать соединения IPv6 для связи между балансировщиком нагрузки и внутренними серверами. Это позволяет вам развертывать свои вычислительные экземпляры без необходимости в общедоступном IPv4, поэтому вы все равно можете помочь избежать исчерпания IPv4.
IPv6 в Scaleway Dedibox
В целях борьбы с полным исчерпанием доступных адресов IPv4 каждый клиент может запросить бесплатную подсеть IPv6 / 48 из консоли Scaleway Dedibox. Это обеспечивает теоретический максимум 18 446 744 073 709 551 616 адресов IPv6.
В отличие от IPv4, IPv6 не имеет маски подсети. Вместо этого используется длина префикса или, для краткости, «префикс». Длина префикса IPv6 работает аналогично CIDR (бесклассовая междоменная маршрутизация) в IPv4. Он определяет, сколько битов адреса определяют сеть, в которой он существует. Длина префикса может иметь любое значение от 1 до 128, но наиболее распространенные префиксы, используемые в сетях IPv6, кратны четырем.
Чтобы использовать подсеть IPv6 на нескольких выделенных серверах, вы можете разделить эту подсеть на более мелкие префиксы со следующими ограничениями:
- Столько префиксов / 56, сколько у вас выделенных серверов
- Столько префиксов / 64, сколько у вас есть резервных IP-адресов
Хотя технически возможно использовать подсети меньшего размера, они непрактичны для сетей на базе Ethernet, поскольку для SLAAC (автоконфигурация адреса без сохранения состояния) требуется 64 бита. SLAAC автоматически генерирует 64-битный идентификатор интерфейса на основе существующего MAC-адреса сетевого интерфейса. Поскольку каждый MAC-адрес уникален, сгенерированный идентификатор интерфейса также уникален. Эти автоматически сгенерированные 64-битные идентификаторы интерфейса действительны во всем мире для адресации и однозначной идентификации каждого сетевого интерфейса в Интернете.
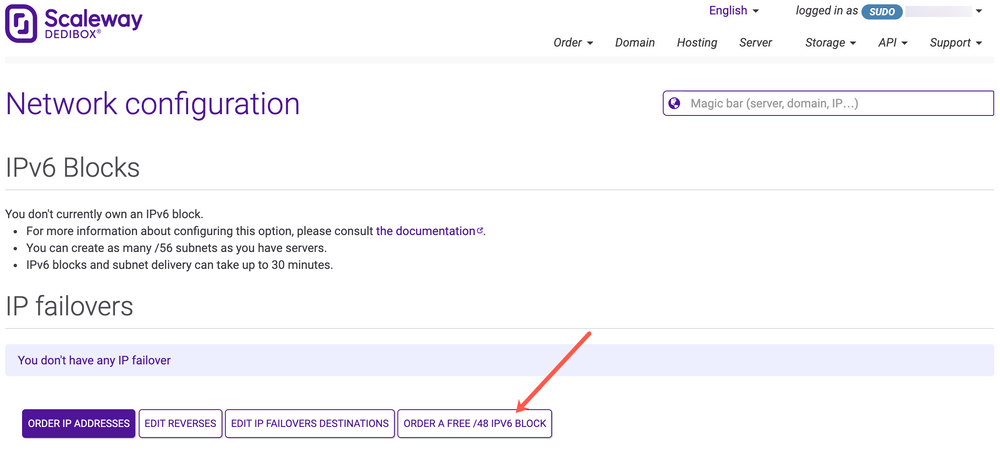
Конфигурация подсети на вашем Dedibox выполняется с использованием клиента DHCPv6 и DUID подсети (уникальный идентификатор DHCP). DUID — это ваш «ключ» для подсети, и DHCP-сервер выделяет подсеть вашему компьютеру, сравнивая DUID со своей базой данных. Если соответствующая комбинация найдена, он доставляет данные конфигурации (адрес, время аренды, DNS-серверы и т. Д.) Клиенту.
Для получения дополнительной информации о настройке IPv6 на вашем сервере Dedibox, в том числе в различных дистрибутивах Linux и Windows, обратитесь к нашей специальной документации.
Автоконфигурация IPv6-адреса без сохранения состояния на серверах Dedibox
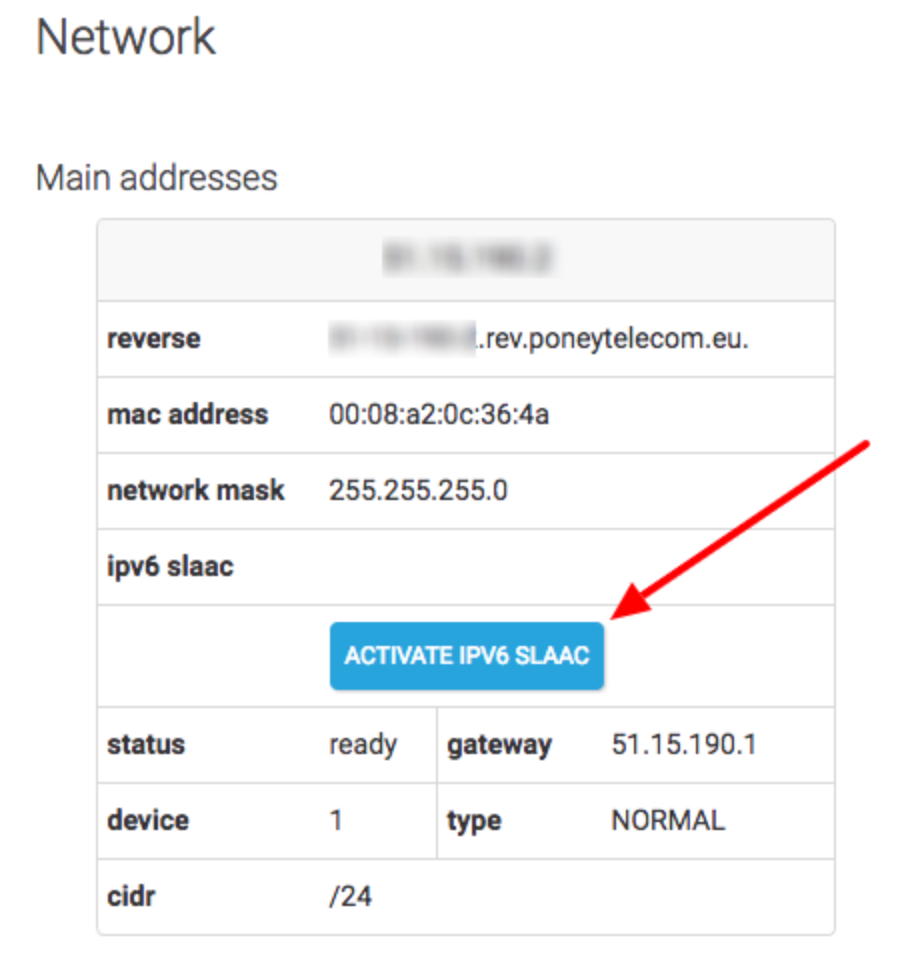
На нескольких выделенных серверах Dedibox вы также можете использовать автоконфигурацию адреса без сохранения состояния (SLAAC), что позволяет вашему серверу автоматически получать адрес IPv6. При использовании SLAAC сервер отправляет запрос маршрутизатора для получения префикса IPv6 с глобальной маршрутизацией, который генерирует полный адрес IPv6 на основе идентификатора сетевого интерфейса, известного как EUI-64. Это делается посредством обмена запросом маршрутизатора -> объявлением маршрутизатора. RA позволяет настроить маршрут по умолчанию и позволяет получить постоянно назначенный статический IPv6 для вашего Dedibox без какой-либо ручной настройки. Вы можете включить эту функцию прямо из консоли, нажав соответствующую кнопку:
 IPv6 на серверах Scaleway Bare Metal Cloud
IPv6 на серверах Scaleway Bare Metal Cloud
Серверы Scaleway Bare Metal Cloud имеют подсеть / 128 IPv6 и позволяют использовать один IPv6-адрес на вашем сервере. Этот IP-адрес настраивается автоматически во время установки машины, и каждый сервер Bare Metal Cloud поддерживает IPv6 без необходимости дополнительной настройки.