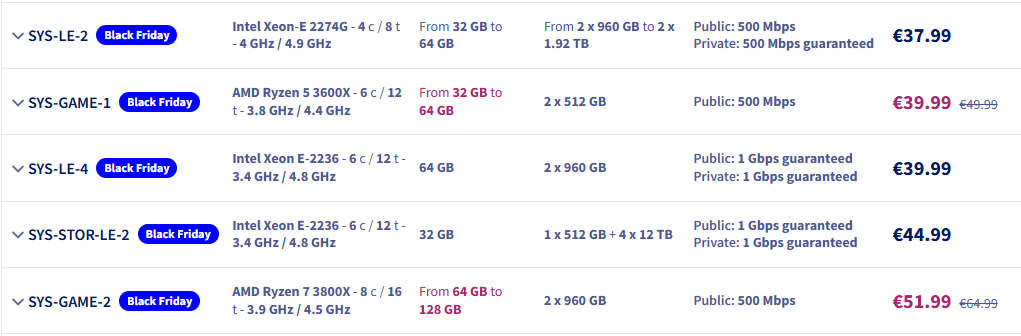
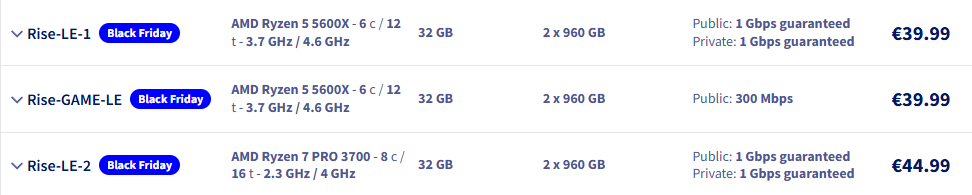
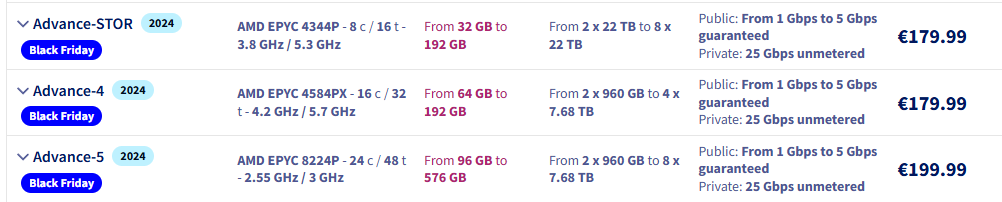
OVHcloud заключил неисключительное соглашение с
SambaNova. Этот стартап из Кремниевой долины разрабатывает перепрограммируемые чипы для быстрого вывода языковых моделей, при этом потребляя меньше энергии, чем видеокарты
Nvidia.
По словам Октава Клабы, соучредителя и генерального директора группы, это подразумевает, помимо прочего, развитие возможностей вывода. Под выводом, напомним, понимается реализация моделей машинного обучения и искусственного интеллекта в процессе производства. Когда ChatGPT отвечает на вопрос пользователя, это пример вывода.
Три режима вывода ИИ
Октав Клаба, со своей стороны, выделяет три типа вывода, которые он планирует предложить в OVHcloud. Во-первых, это базовый вывод, который уже доступен широкой публике.
Скоро будут доступны еще два режима.
С 31 декабря пакетный вывод позволит асинхронно обрабатывать большие объёмы данных. И наконец, то, что интересует эту статью: сверхбыстрый вывод, которого ожидают пользователи большинства ИИ-помощников. С таким инструментом, как ChatGPT, вы видите, как буквы формируются прямо на ваших глазах; это просто потрясающе
говорит Октав Клаба.
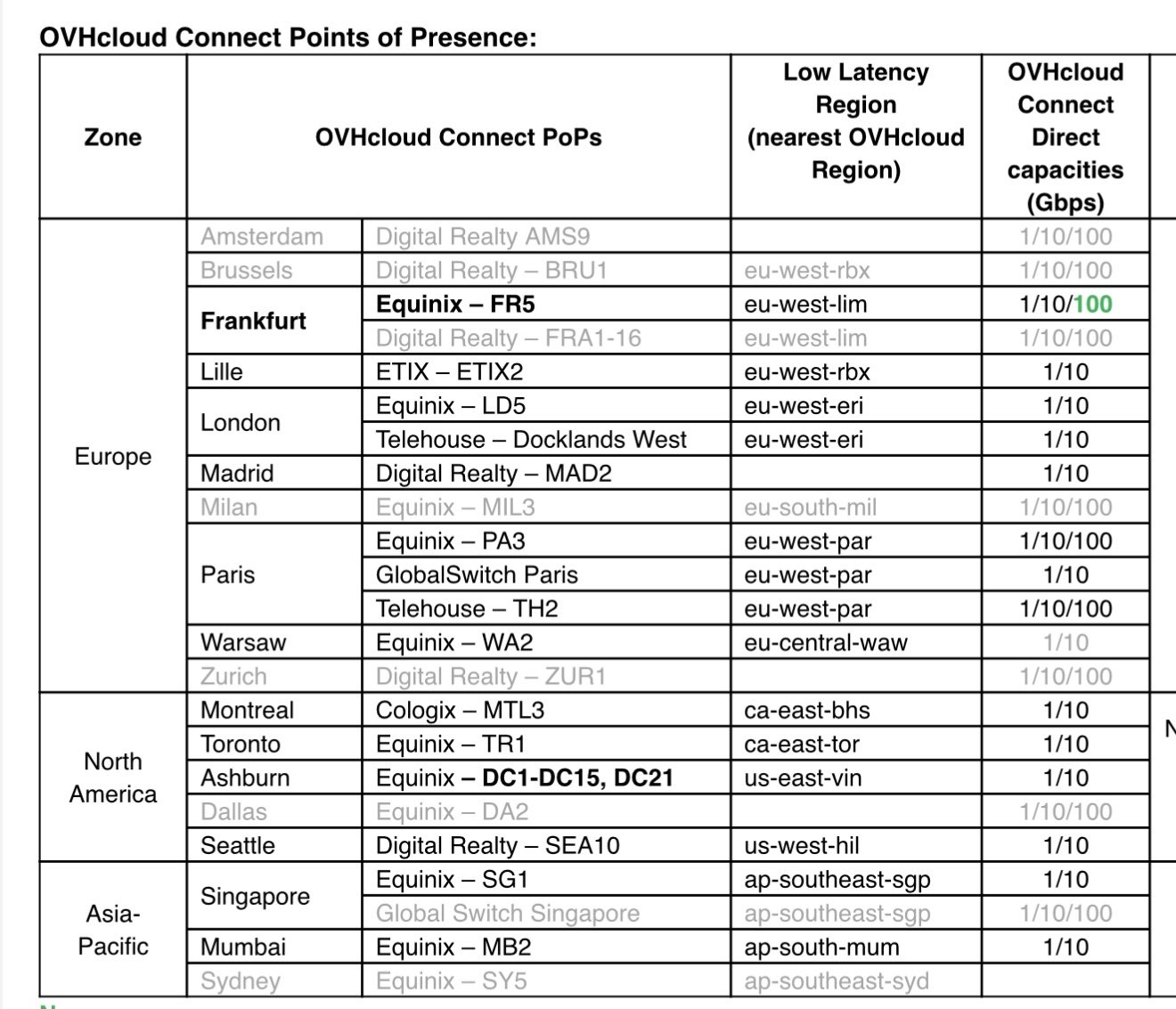
Для пакетного и базового режимов OVHcloud может использовать существующие экземпляры Nvidia: H100, V100S, A10, L4, L40S и RTX 5000. С 30 ноября компания будет предоставлять H200 через свои инструменты искусственного интеллекта. Также планируется запуск RTX 6000 Pro, B200 и B300, но дата выхода пока не объявлена.
Но для высокоскоростного вывода провайдер намерен предложить доступ к стойкам SambaNova.
SambaNova — обещание быстрого вывода с низким углеродным следом
SambaNova, гораздо менее известная, чем Nvidia, — американский разработчик перепрограммируемого чипа, предназначенного для выполнения задач искусственного интеллекта (обучения или вывода). Эти чипы называются RDU (Reconfigurable Dataflow Units).
ASICS можно перенастраивать в соответствии с рабочими нагрузками и моделями. Это делает его гораздо более устойчивым
заявил Октав Клаба на пресс-конференции перед саммитом OVHCloud.
Компания SambaNova, с которой LeMagIT познакомился во время пресс-тура в 2022 году, была основана бывшими сотрудниками Sun Microsystems/Oracle и учёными, окончившими Стэнфорд. В то время компания-единорог уже заявляла, что её технология способна выполнять модели типа GPT с высокой скоростью.
Стойка SambaNovaСтойка SambaNova, сфотографированная в 2022 году

Мы протестировали Cerebras, Groq и SambaNova. Мы пришли к выводу, что SambaNova обеспечивает наилучшее соотношение производительности, цены и занимаемой площади в центрах обработки данных
говорит Октав Клаба
SambaNova удалось разместить 16 чипов SN40L, четвёртого поколения своих 5-нм чипов (производства TSMC), в одной стойке (по 2 RDU на лезвие, 8 лезвий). Для обеспечения эквивалентной вычислительной мощности Groq потребовалось бы 9 стоек, а Cerebras — четыре. «SambaRack» может обрабатывать передовые модели с более чем 400 миллиардами параметров, включая Llama 4 Maverick и DeepSeek R1 (671 миллиард параметров).
По расчётам SambaNova, одна стойка может вместить до 5 триллионов параметров.
Ещё одной отличительной особенностью чипа SN40L является наличие 520 МБ кэш-памяти SRAM и 64 ГБ памяти HBM. К нему можно подключить 768 ГБ оперативной памяти DDR4. В общей сложности стойка SN40L-16 имеет 8 ГБ SRAM, 1 ТБ HBM и 12 ТБ оперативной памяти DDR4. По словам Октава Клаба, эта стойка потребляет в среднем 10 кВт (пиковая мощность — 14,5 кВт) и может вместить «десятки» моделей, которые можно сменить «менее чем за 2 миллисекунды». «В то время как с графическими процессорами Nvidia это занимает от 30 секунд до 3 минут». Для сравнения, очень мощная стойка GB300NVL72 (с общим объёмом 40 ТБ HBM3e) потребляет от 130 до 140 кВт, по данным Supermicro.
Агенты с открытым исходным кодом и ИИ для различных профессий
Но, как отмечает глава французского поставщика, самое интересное — это скорость ответов.
SambaNova заявляет, что с Llama 4 Maverick она может получать более 100 токенов в секунду. С более мелкими моделями, такими как Llama 3.1 8B, эта скорость достигает более 1000 токенов в секунду по сравнению с 1837 токенами в секунду у Cerebras.
Напоминаем, что функция Lightning Speed в приложении Le Chat от Mistral AI реализована на базе чипов Cerebras, установленных в дата-центре в Лас-Вегасе.
Сейчас мы развёртываем первое шасси SambaNova в нашем центре обработки данных Gravelines. Если рынок отреагирует положительно, мы планируем добавить стойки в каждый из наших центров обработки данных
говорит Октав Клаба
Речь идёт не о предоставлении прямого доступа к экземплярам GPU/RPU Nvidia и фреймворкам SambaNova. Вместо этого OVHcloud предоставляет эти вычислительные возможности через свой сервис AI Endpoint. Через API он предоставляет доступ примерно к сорока моделям генеративного ИИ и обработки естественного языка. Эти модели в основном имеют открытый вес.
Наша стратегия в области графических процессоров ориентирована на логический вывод, особенно на модели с открытым исходным кодом
говорит генеральный директор OVHcloud.
Параллельно французский провайдер разрабатывает OmisimO, ИИ-помощника на базе SHAI, программного агента с открытым исходным кодом для ИИ (Apache 2.0). Идея заключается в том, чтобы способствовать появлению реальных сценариев использования, полезных для бизнеса, таких как ИИ-агенты, подключенные к CRM-системам компаний.
Модель ценообразования для API конечных точек ИИ во многом зависит от скорости отклика. Базовый API, как правило, основан на тарификации на основе токенов. Цена зависит от выбранного уровня LLM (локальное управление жизненным циклом). Для объёмов токенов, обрабатываемых через пакетный API, OVHcloud обещает скидку и возможность планировать запросы вне периодов пикового потребления. Для быстрого API потребуется минимальный ежемесячный взнос, но поставщик гарантирует «сверхвысокую пропускную способность, сверхбыструю доставку и повышенную конфиденциальность». Выпуск этого API запланирован на 2026 год.
Объявление о партнерстве было сделано на следующий день после того, как Nvidia опубликовала результаты за третий финансовый квартал 2026 года.
Продажи Blackwell необычайно высоки, и графические процессоры для облака распроданы
заявил в пресс-релизе Дженсен Хуанг, основатель и генеральный директор Nvidia.
Графические процессоры: «проблема бизнес-модели»
Октав Клаба, отвечая на вопрос о гонке вооружений среди облачных провайдеров, осторожен.
Когда я инвестирую, меня интересует прибыльный рост. Я отказываюсь играть в лотерею. Мы делаем это, исходя из потребностей клиентов. Мы хотим знать, кто и за что будет платить
Руководитель утверждает, что придерживается «защитной» инвестиционной стратегии.
Правда о графических процессорах H100, купленных три года назад, заключается в том, что они практически бесполезны. Люди постепенно поймут, что инвестиционные циклы для графических процессоров гораздо короче, чем для центральных процессоров. Через 18 или 24 месяца у вас уже есть серьёзные вопросы, которые нужно задать себе. А через 36 месяцев вы теряете почти 80% стоимости
Это объясняет, почему OVH не вкладывает значительные средства в обучение суперкомпьютеров.
Провайдеры программ LLM переходят на кодирование с точностью FP4 во время обучения. Графические процессоры H100 не поддерживают FP4. Графические процессоры H200 уже широко распространены; снизите ли вы цену на H100 или потеряете клиентов из-за того, что они будут использовать более дешёвые H200? Проблема в бизнес-модели
объясняет Октав Клаба