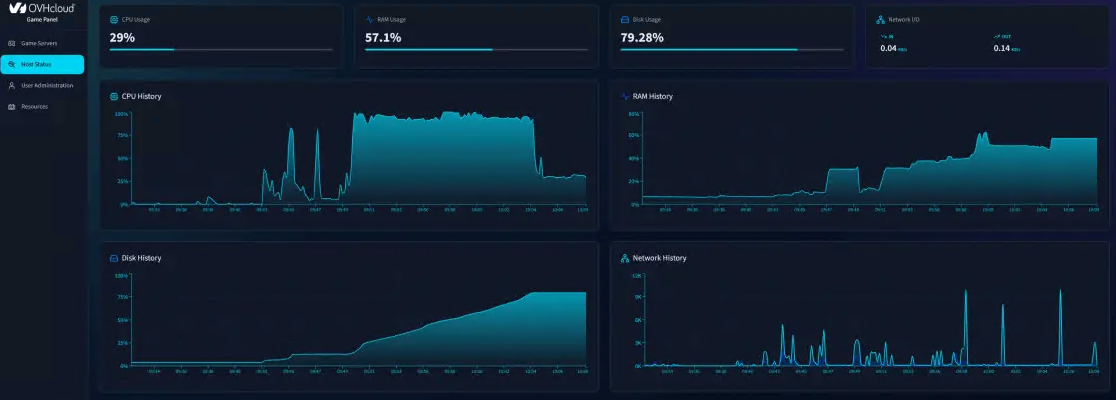
OVHcloud использует Belenos от Quandela для ускорения развития европейского квантового сектора

Рубе – 17 апреля 2026 г. – На форуме Quantum Defense Forum компания OVHcloud, мировой игрок и европейский лидер в области облачных вычислений, и компания Quandela, специализирующаяся на фотонных квантовых вычислениях, объявили о появлении компьютера Belenos на квантовой платформе OVHcloud.
Представленная прошлой осенью платформа OVHcloud Quantum Platform демократизирует использование квантовых вычислений и доступ к передовым технологиям благодаря модели потребления «квантовые вычисления как услуга» (QaaS). С добавлением Belenos, OVHcloud продолжает реализацию своей амбициозной дорожной карты по созданию квантовых компьютеров, доступных из облака.
В Belenos de Quandel используется технология квантовой фотоники, обеспечивающая вычислительную мощность в 12 кубитов. Это позволяет экспериментировать с новыми алгоритмами в различных и инновационных областях, таких как классификация и генерация изображений, ускорение искусственного интеллекта и квантовое машинное обучение (QML). Новые области применения в электромагнитном моделировании, структурной механике, горении в двигателях, моделировании материалов, метеорологии и наблюдении за Землей также выигрывают от достижений в области квантовых вычислений.
С 2022 года Группа поддерживает европейскую квантовую экосистему, предоставляя самый широкий спектр квантовых эмуляторов на основе своей инфраструктуры, которой пользуются более тысячи человек. Сейчас, предлагая пятнадцать доступных квантовых эмуляторов (включая Perceval и MerLin) по цене от 0,03 евро в час, Группа помогает пользователям познакомиться с различными моделями квантовых вычислений.
Мы рады выполнить обещание, заложенное в квантовой платформе, добавив второй эталонный квантовый компьютер, Belenos, от французской компании Quandela. Квантовая революция набирает обороты, и OVHcloud намерена занять свое законное место в качестве европейского лидера в области облачных технологий в рамках экосистемыговорит Мирослав Клаба, директор по исследованиям и разработкам OVHcloud.
Квантовая платформа OVHcloud предоставляет доступ к реальным квантовым компьютерам, стремясь ускорить внедрение квантовых вычислений в частном секторе. Квантовый процессор Belenos предлагается как услуга с оплатой по фактическому использованию, с точностью до секунды, без каких-либо обязательств.
Интеграция 12 кубитов Belenos в предложение OVHcloud знаменует собой решающий шаг для квантовых вычислений в Европе. Доступный через облако, этот фотонный компьютер становится конкретным инструментом для бизнеса. С помощью OVHcloud мы предлагаем специалистам по обработке данных и новаторам средства для разработки своих алгоритмов на гибкой и суверенной инфраструктуреговорит Никколо Сомаски, генеральный директор и соучредитель Quandela.