
Уважаемый клиент, в связи с новыми беспрецедентными санкциями против РФ к нам поступает всё больше вопросов относительно сложившейся ситуации. В этом письме мы хотели бы ответить на самые актуальные вопросы от наших клиентов.
Про сотрудничество с клиентами из РФ.
Прежде всего хотим сообщить, что мы намерены продолжить обслуживание всех наших клиентов, в том числе и из РФ. Мы НЕ планируем каких либо ограничений для россиян.
Про методы оплаты.
Поступает всё больше информации о том, что те или иные платёжные инструменты более не будут доступны россиянам. Последние новости были связаны с Visa/Mastercard и paypal. Согласно последним данным, начиная с 10-го марта картами (Visa/Mastercard) всех российских банков будет невозможно оплатить услуги за пределами РФ. В связи со сложившейся ситуацией можем порекомендовать следующее:
1. Если обычно вы оплачиваете наши услуги банковской картой или любым другим методом, который уже недоступен в РФ, то продлите услугу на длительный период используя карту российского банка, который не попал под санкции. Сейчас для этого подходящий момент, у нас проводится акция «Spring sale 2022». Согласно условиям акции, если вы продлите vds или виртуальный хостинг на 1 год, то получите скидку до 25%, а также 1 месяц оплаченного периода в качестве бонуса.
Условия акции тут. Продлив заказ на длительный период вы получите большие скидки, приятные бонусы и застрахуете себя от колебания курса валют.
2. Если у вас есть возможность, то получите банковскую карту UnionPay. С её помощью вы сможете оплачивать наши услуги. Список российских банков, которые выпускают карты UnionPay можно найти тут. Вероятно, в скором времени список будет значительно расширен. Не пренебрегайте этой возможностью.
unionpayintl.com/ru/servicesProducts/products/unionPayCard/apply/
3. Обратите внимание на альтернативные методы платежей, например криптовалюту. В условиях жёстких санкций это может быть хорошим вариантом для оплаты услуг компаний, который находятся за пределами РФ. Чтобы оплатить наши услуги с помощью криптовалюты пожалуйста, используйте метод платежа «BTC and other cryptocurrencies (recommended)» или «BTC and other cryptocurrencies (alternative)».
Про блокировки популярных сервисов в РФ и VPN.
С каждым днём растёт количество популярных ресурсов, которые более недоступны в РФ. Например Facebook, YouTube, TikTok и прочие. Хотим напомнить вам, что наша компания предоставляет возможность заказать vds с предустановленным VPN сервером. Сразу же после активации vds Вы получите готовый к использованию VPN. Для этого подойдёт даже минимальный тариф — «VDS Micro» за €2,99 в месяц. Чтобы получить такой сервер, пожалуйста, во время оформления заказа, в качестве ОС выберите «CentOS 7», а в качестве панели управления «OpenVPN».
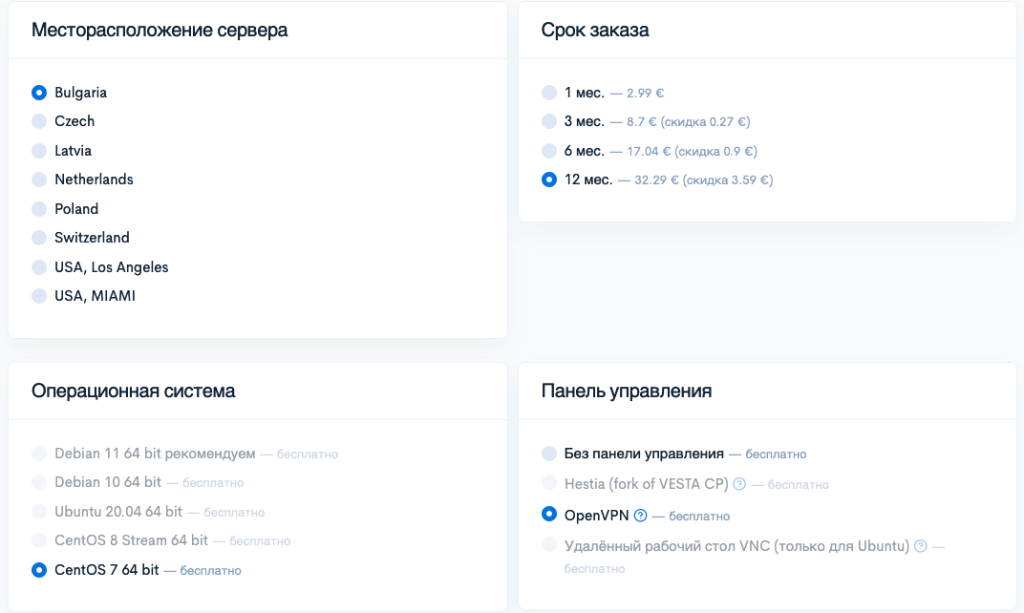
Удачной идей будет заказать vds для VPN по акции «Spring sale 2022» и получить скидку до 60%.
Условия распродажи тут. Более того, VPN сервер можно установить и на любой vds под управлением Linux. Даже на тот vds, на котором работают сайты. Вы можете сделать это самостоятельно или с помощью нашей технической поддержки обратившись в тикеты.
Не уходите в оффлайн — выбирайте дружелюбный хостинг!
С уважением Friendhosting LTD.






