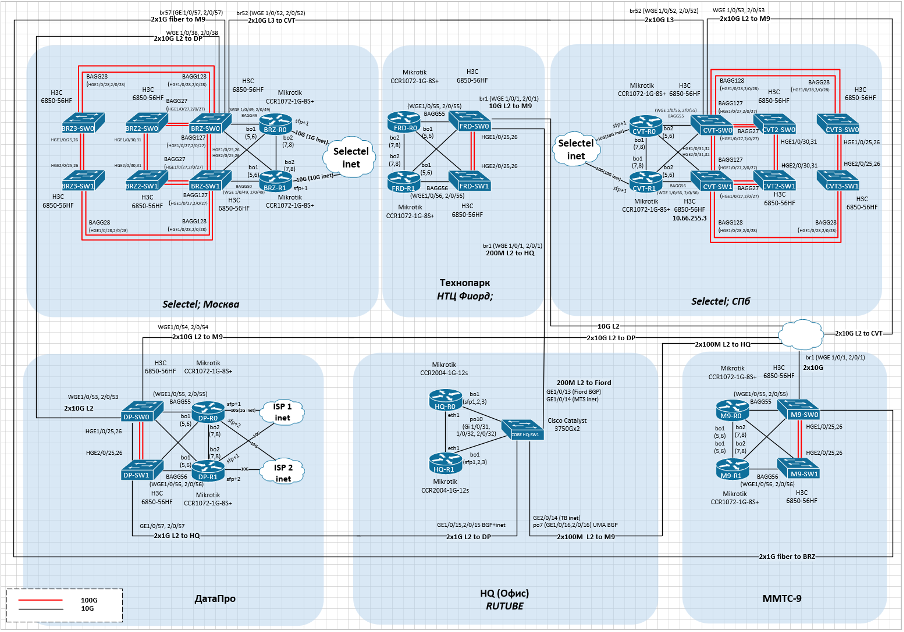
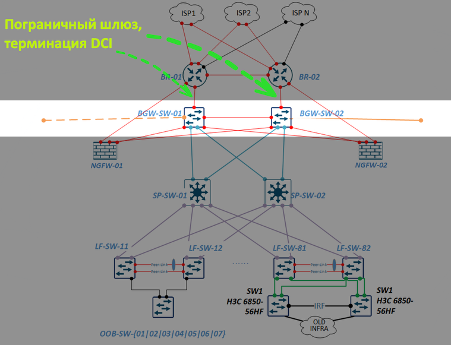
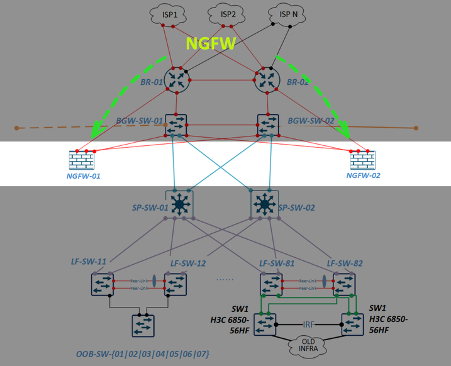
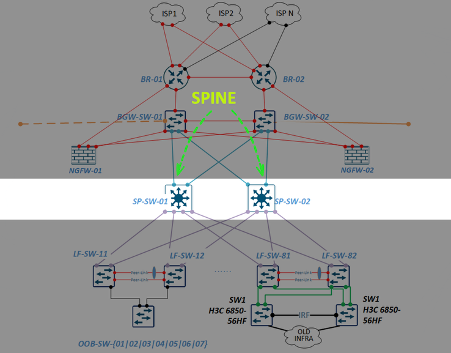
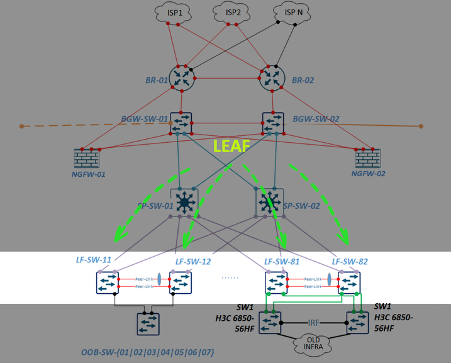
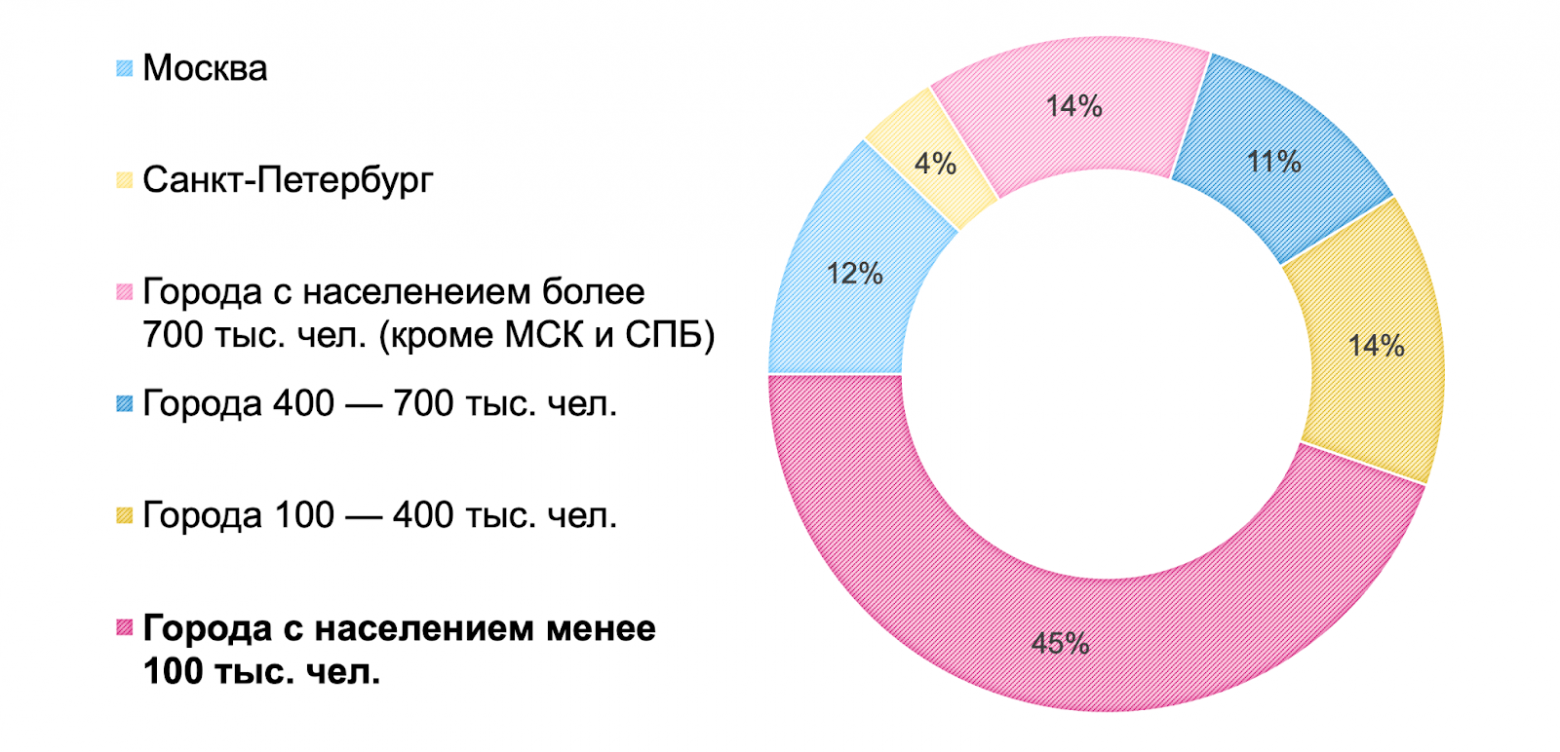
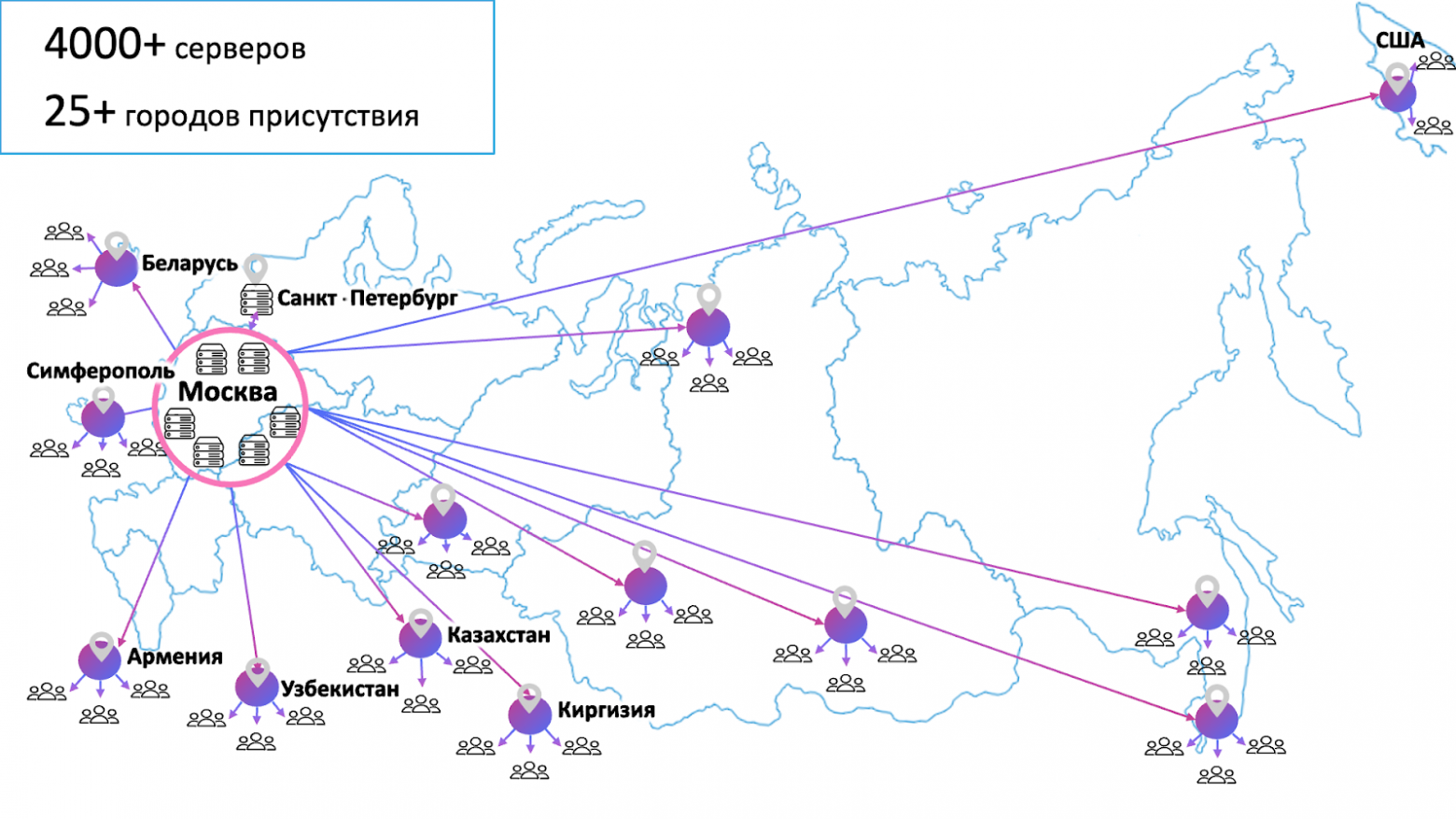
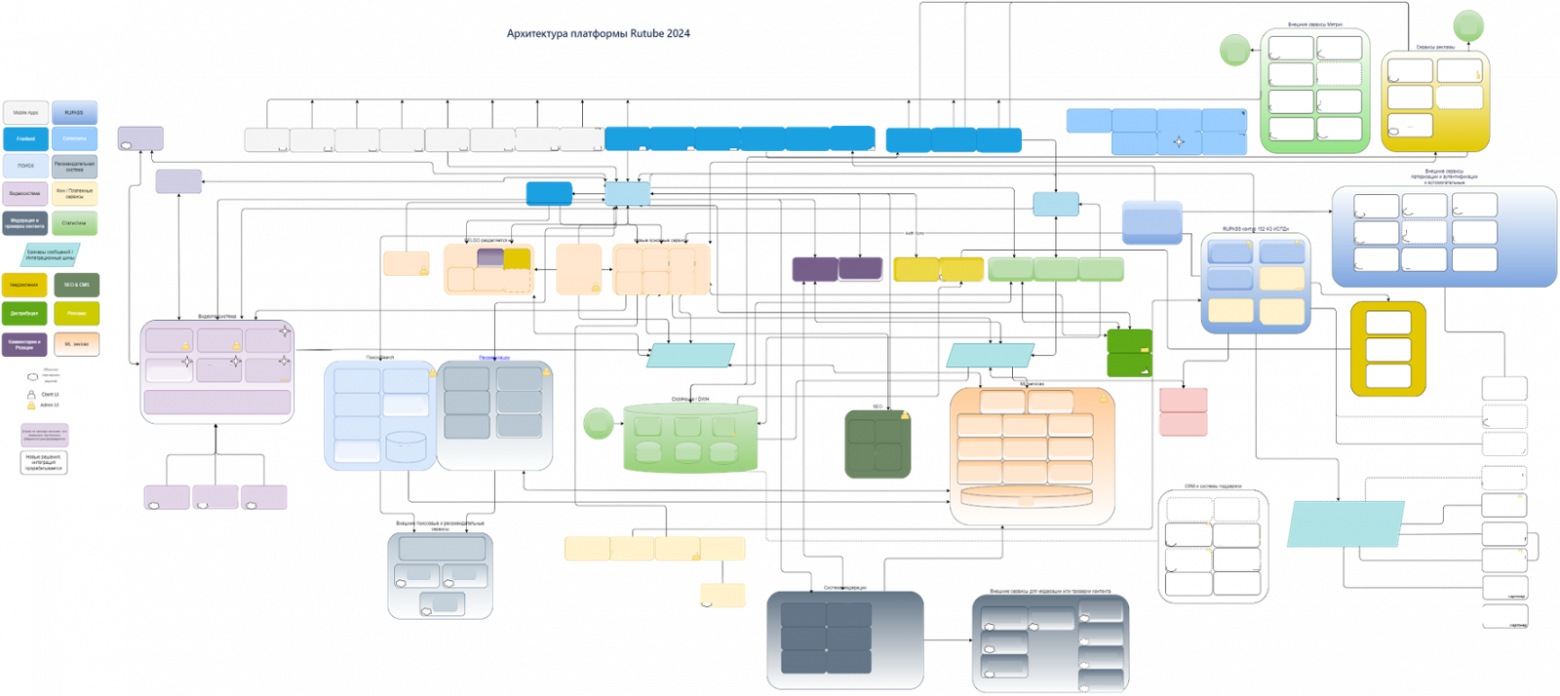
Меня зовут Дмитрий Иванов, я начальник отдела эксплуатации IT-инфраструктуры RUTUBE, что на наши деньги переводится как SRE-тимлид. В этой статье разберу задачу доставки контента и расскажу о решениях, которые помогают нам в RUTUBE.
Дано: с одной стороны у нас 17,7 млн ежедневных пользователей, а с другой — 400 млн единиц контента. Оба эти показателя постоянно увеличиваются, а география присутствия пользователей расширяется.
Требуется: показывать всем нашим пользователям видео из библиотеки быстро, надежно и эффективно.
Как взаимосвязаны эти приоритеты и в чём проблема:
- Раздавать видео по всей нашей большой стране и за её пределы из одного хранилища, очевидно, не быстро — пинг от Москвы до Владивостока около 100 мс.
- Некоторые видео популярнее других, то есть одновременно их хотят посмотреть очень много пользователей. Если показывать такие видео напрямую из видеохранилища, это не будет надежно — потому что вся нагрузка пойдет на один сервер, серверу может стать плохо и «кина не будет».
- Чтобы раздавать контент быстро, надо его разместить как можно ближе к зрителю. Но с учётом размера нашей библиотеки мы не можем её всю разложить по всем точкам присутствия пользователей — это будет неэффективно.
Решением этой задачи, как понятно из названия, является CDN — Content Delivery Network. Далее в статье сначала определим особенности нашего контента и то, какие требования к CDN в связи с этим возникают, а потом будем искать способы им соответствовать.
Контент на RUTUBE — что нужно доставлять
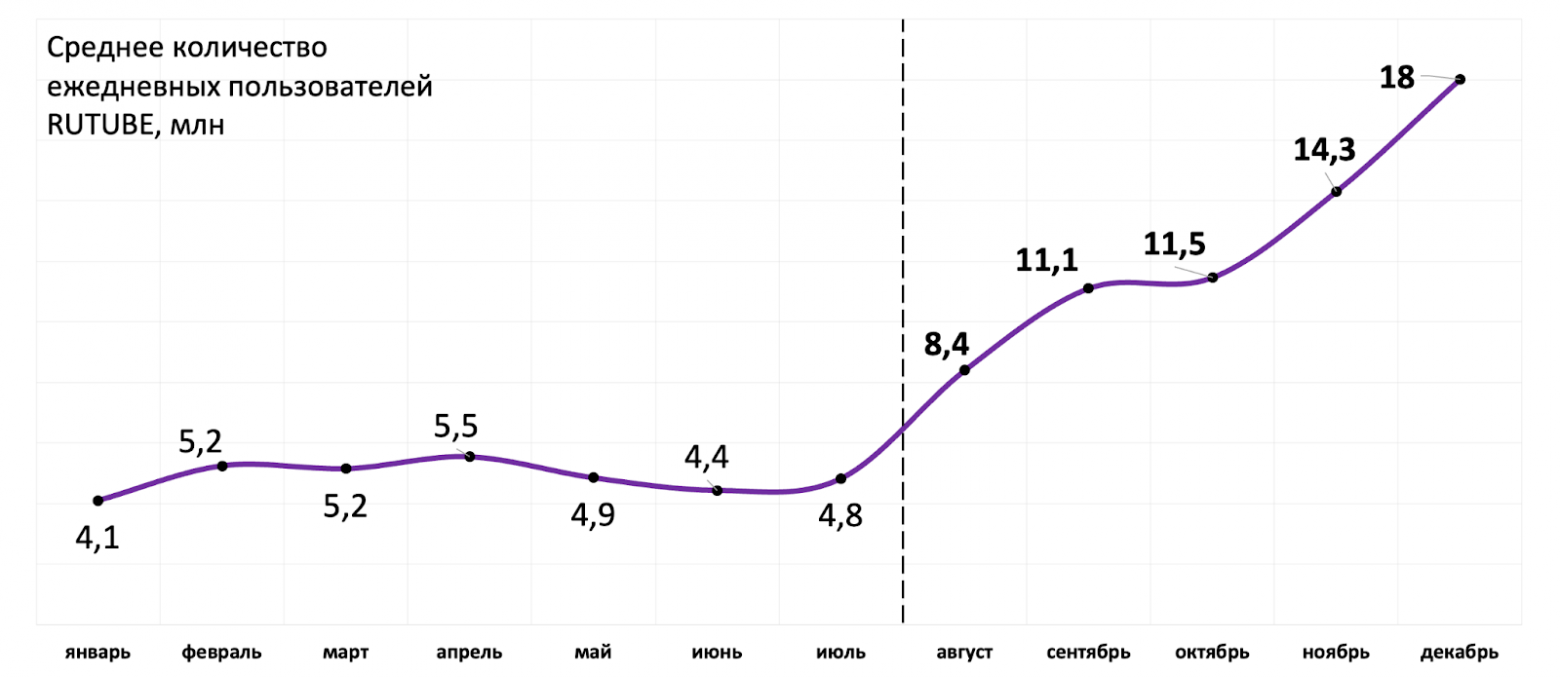
Количество пользователей и количество контента видеохостинга — взаимосвязаны. Чтобы привлекать больше зрителей, нужно большое разнообразие видео, и наоборот — новые пользователи загружают новые ролики. Ниже реальный график роста библиотеки контента.
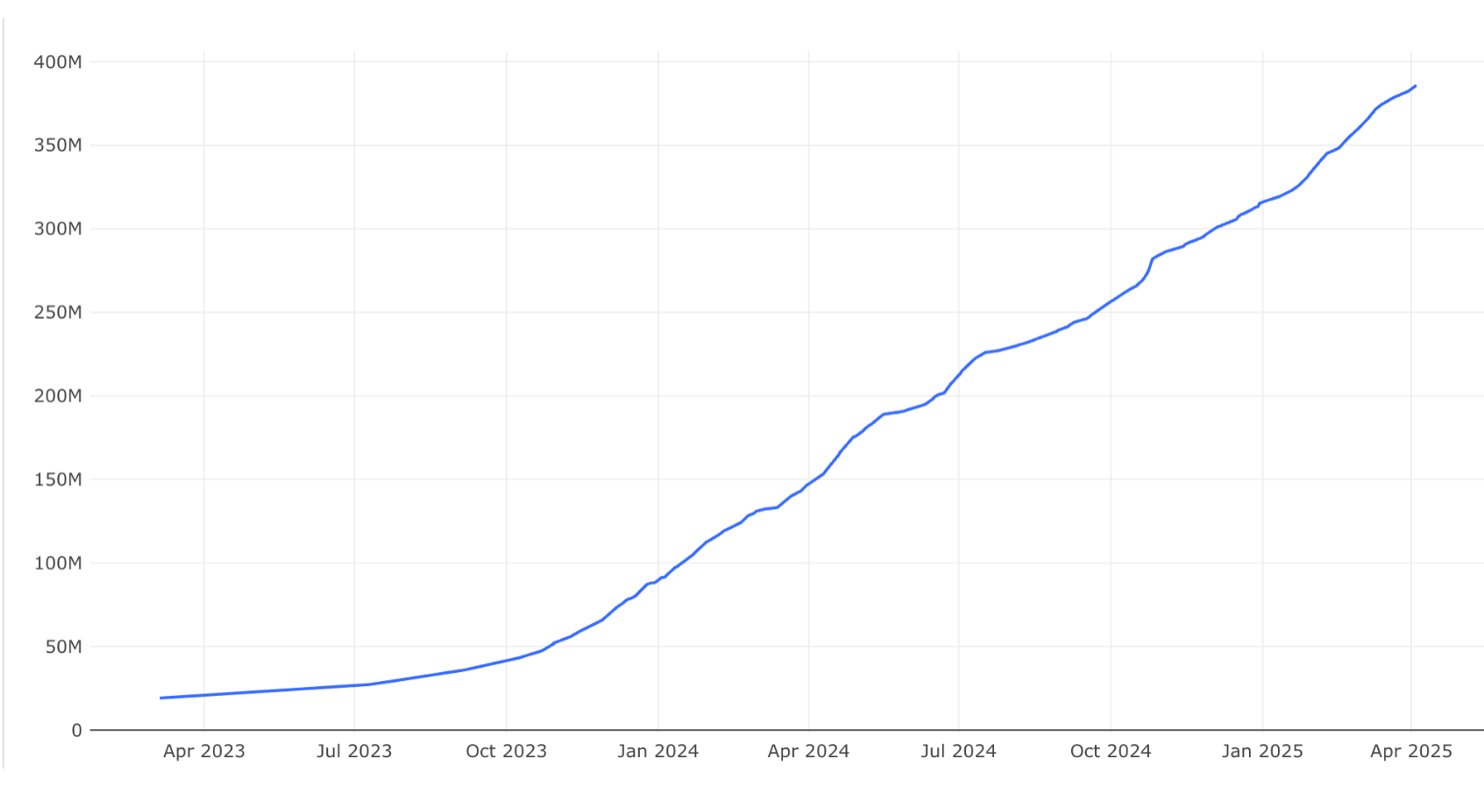
Рост хранилища и пользовательской базы имеет большое значение в разрезе масштабирования, о чем подробнее можно прочитать в статье об архитектуре RUTUBE. В рамках темы CDN нам важно, что библиотека постоянно расширяется, и в ней есть более и менее популярные видео. Если построить график, где по оси абсцисс будут единицы контента, а по оси ординат — просмотры, то получится гипербола примерно как на рисунке ниже.
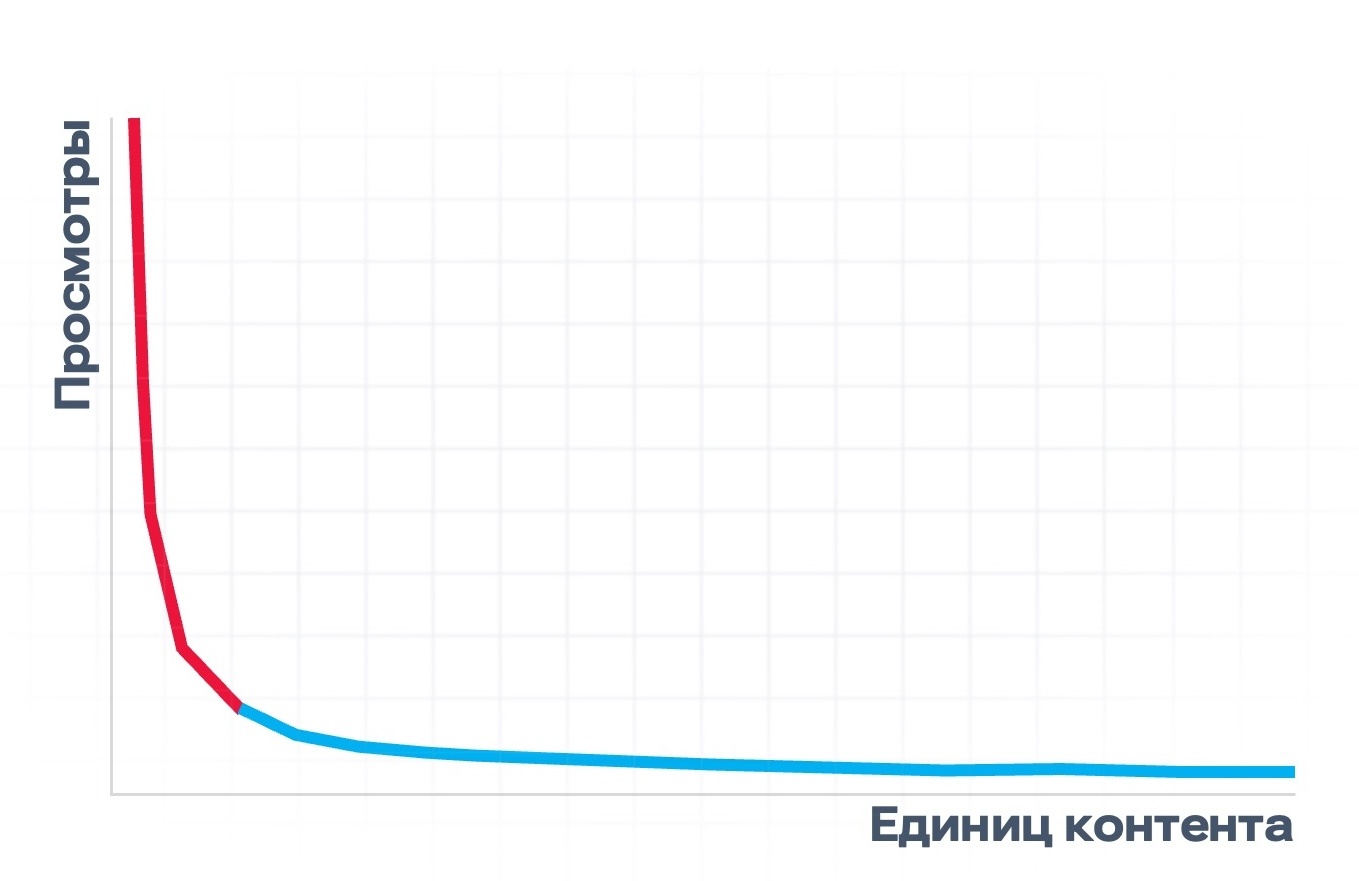
У нас есть небольшой процент видео, которые смотрят часто, и длинный хвост контента с гораздо меньшим количеством просмотров (например, видео со встречи одноклассников или обзор товаров в магазине у дома). В соответствии с этим мы можем поделить контент на горячий, то есть востребованный в данный момент, и холодный — интересный ограниченной аудитории.
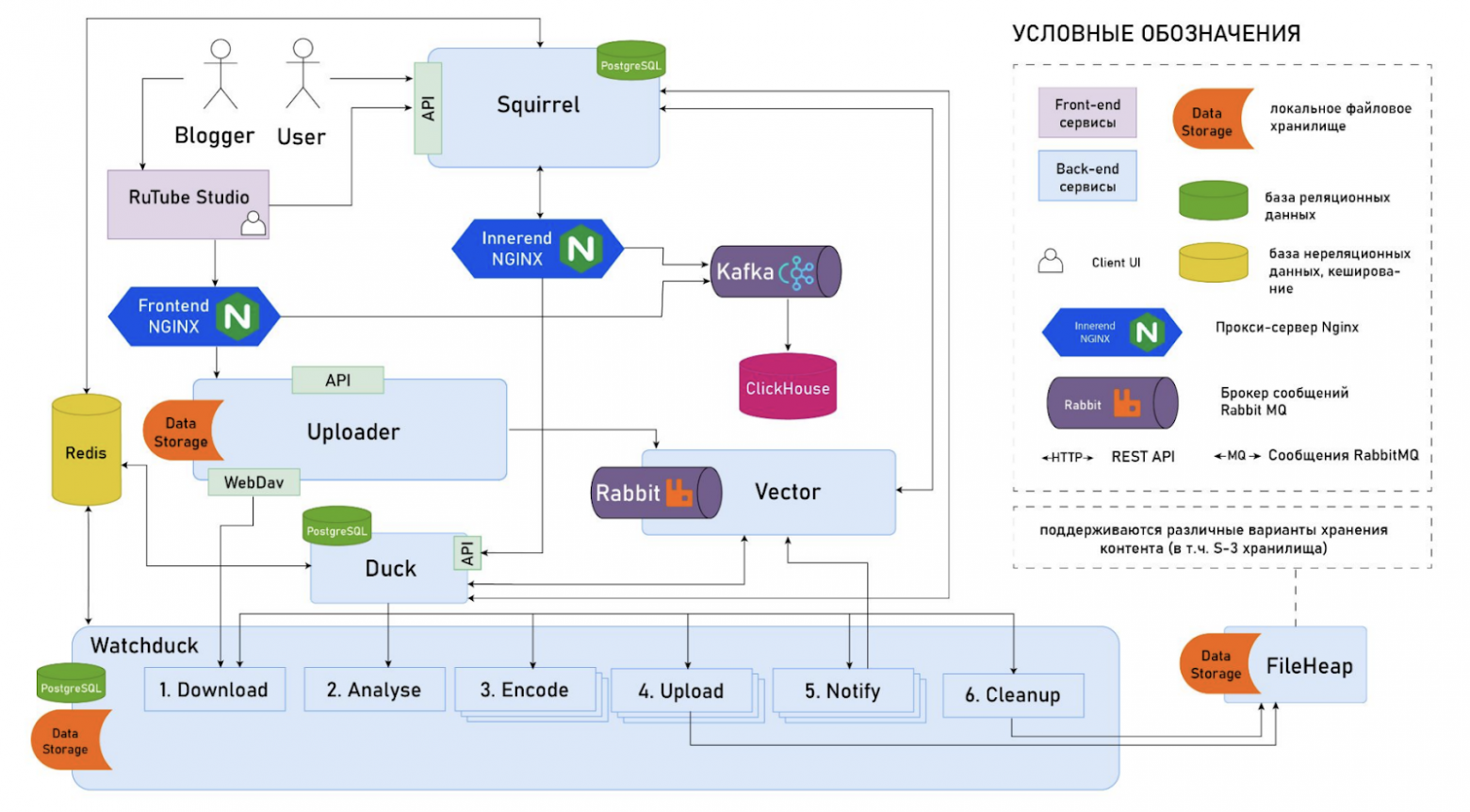
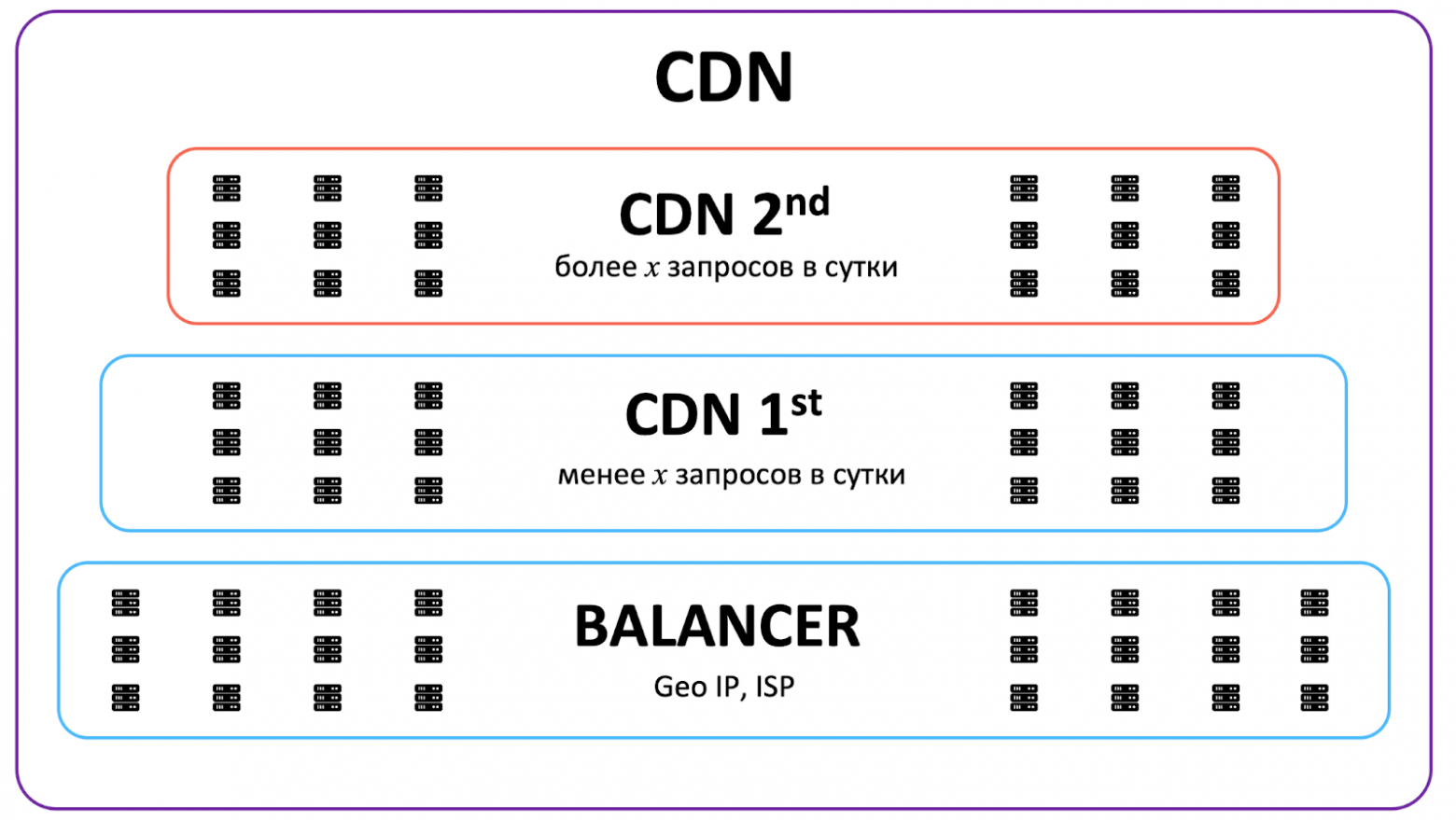
Два уровня кэширования
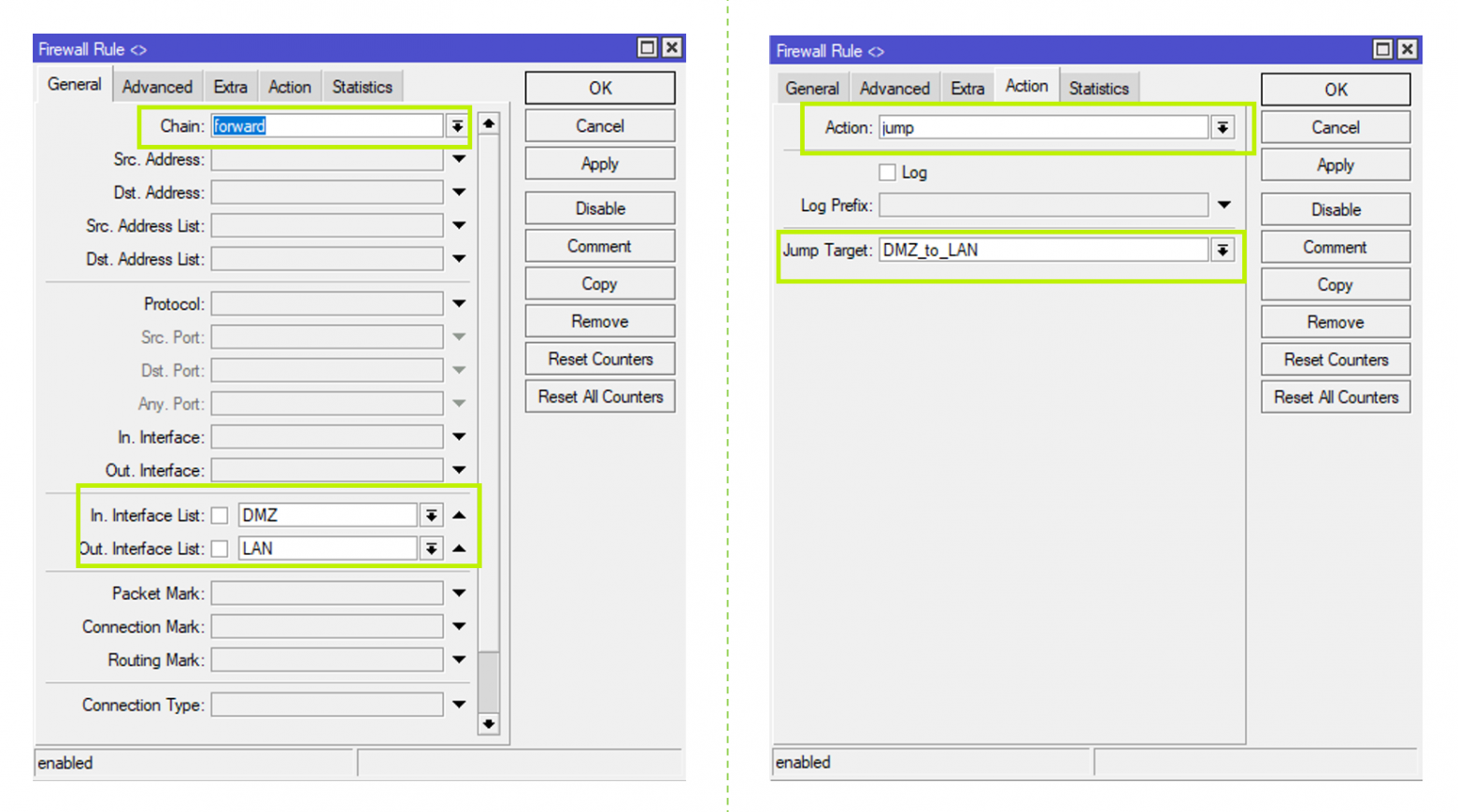
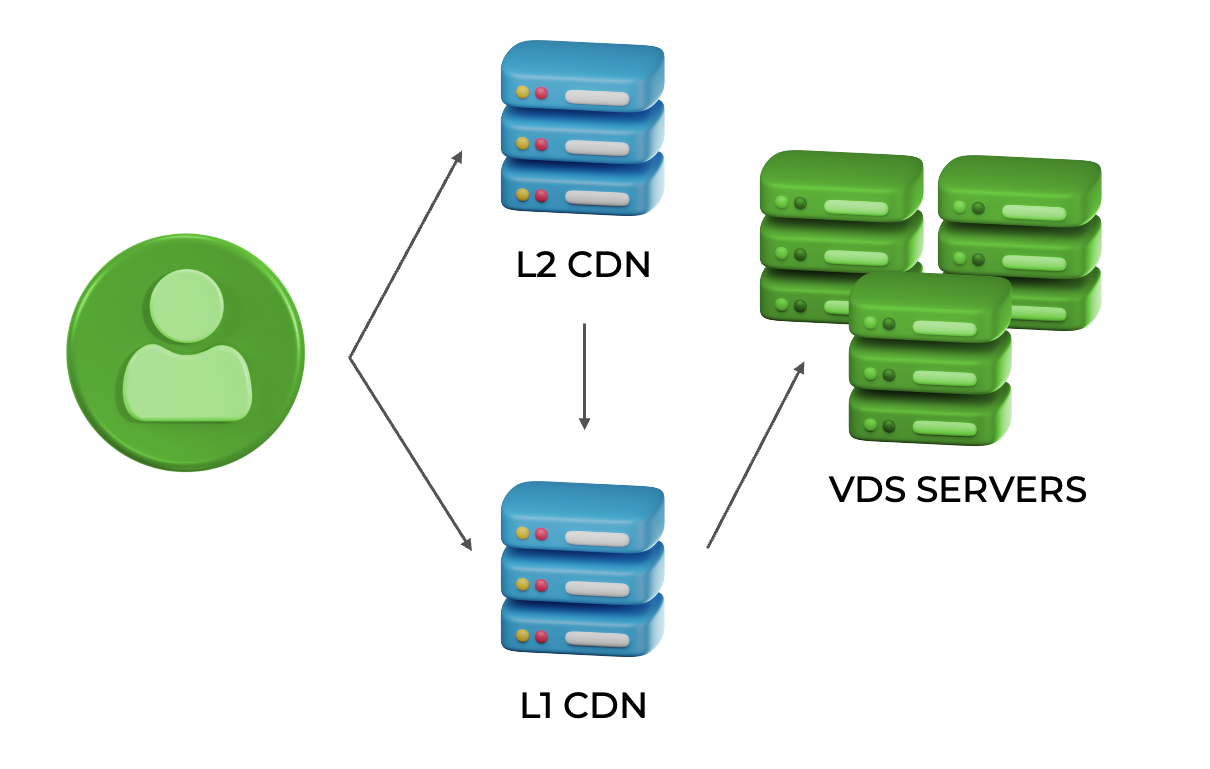
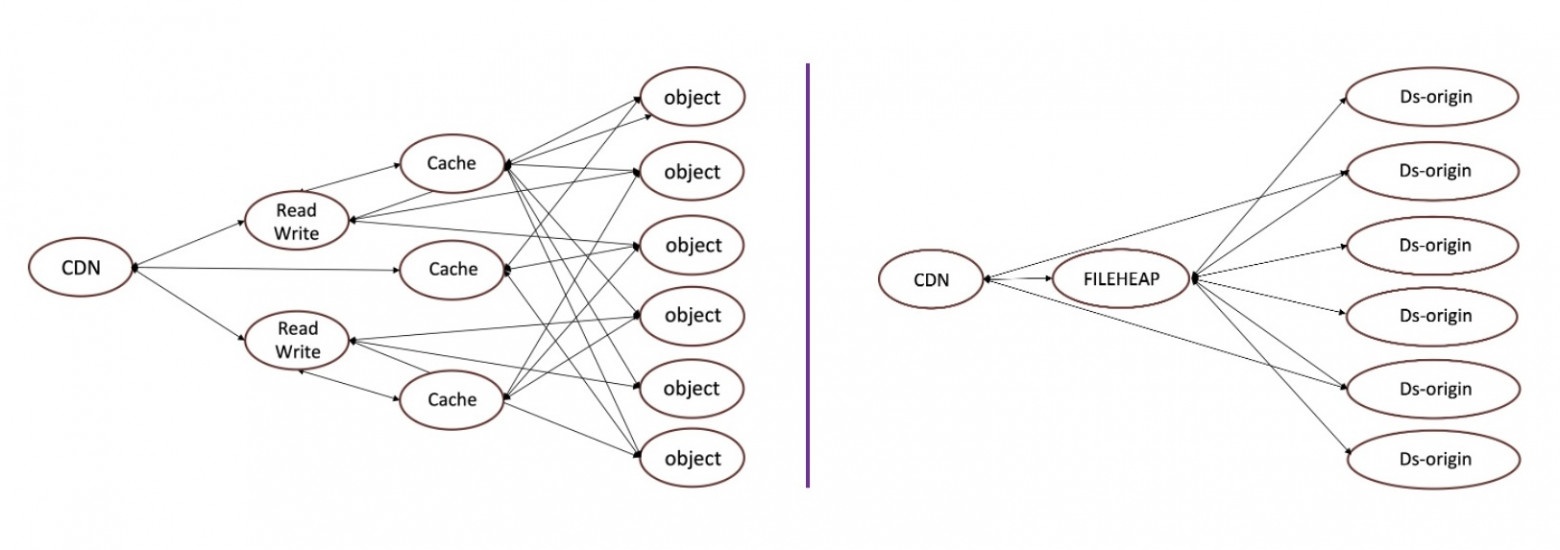
Для эффективного и быстрого доступа к горячему и холодному контенту соответственно выделим в CDN два вида кэша: L1 для холодного и L2 для горячего.
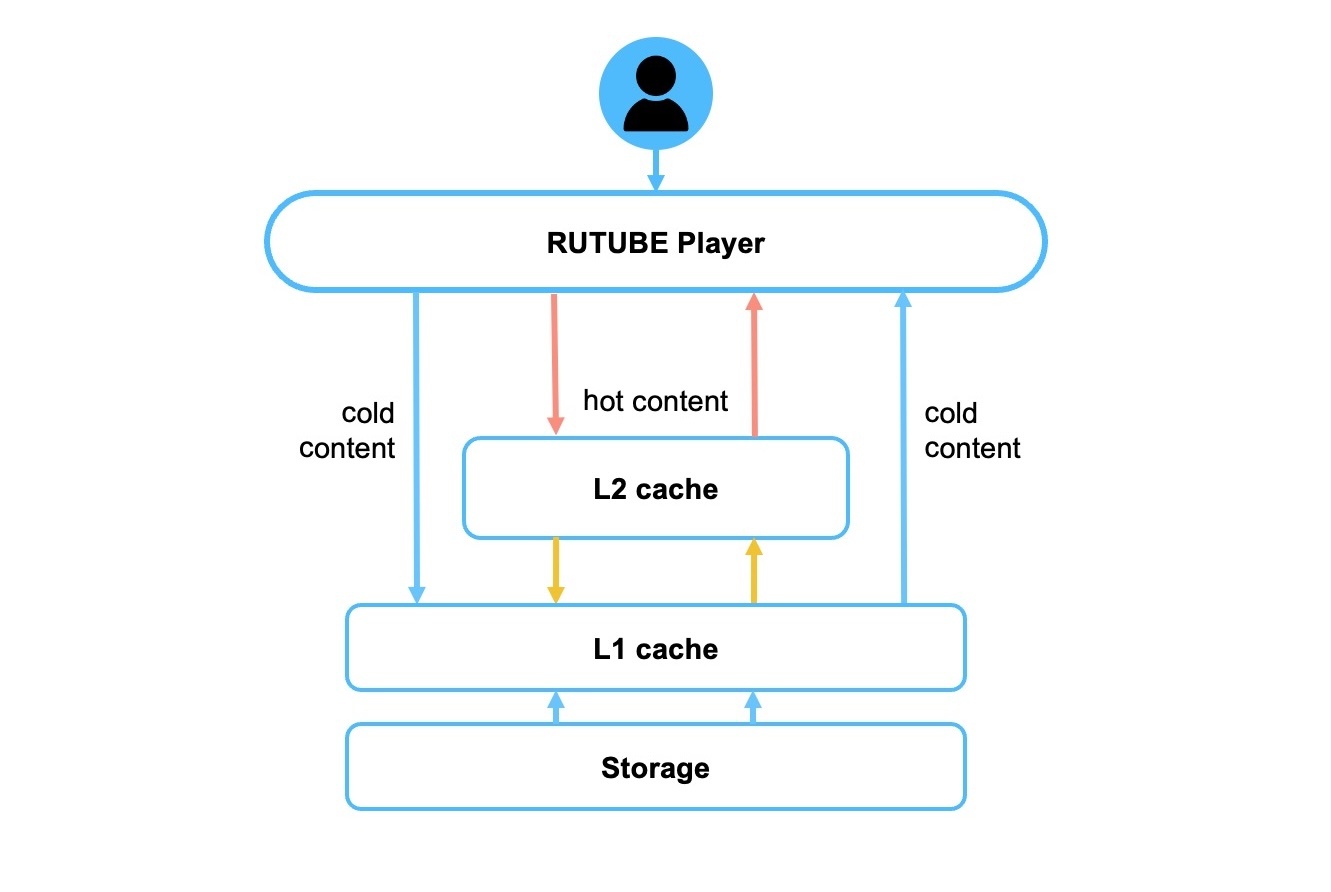
Исходный контент находится в видеохранилище. Далее разместим L1-кэш — уровень, который предназначен для холодного контента, ближе к хранилищу и с прямым доступом к нему. А L2, то есть горячий кэш, расположим как можно ближе к зрителям, в том числе в регионах. При этом, как показано на схеме, у региональных CDN-серверов с горячим контентом нет доступа в основное видеохранилище, вместо этого используется L1 для подкачки на уровень L2.
Тут можно было бы прокинуть VPN с L2 сразу в хранилище или сделать отдельный канал, но это была бы более сложная и дорогая схема. Каждая стрелочка на схеме не бесплатная с точки зрения ресурсов, перемещая контент как можно ближе к зрителю, мы экономим сетевой трафик.
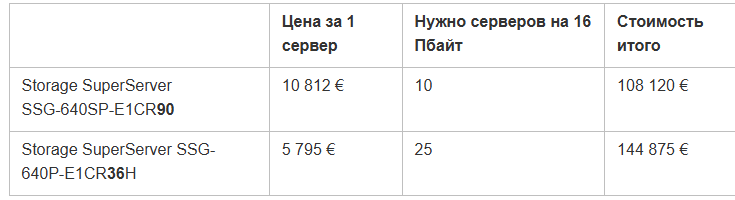
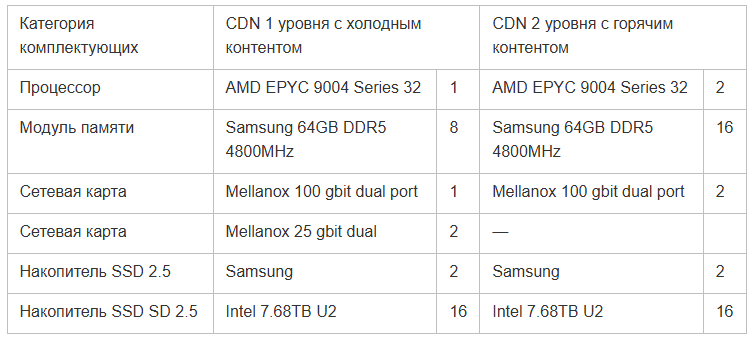
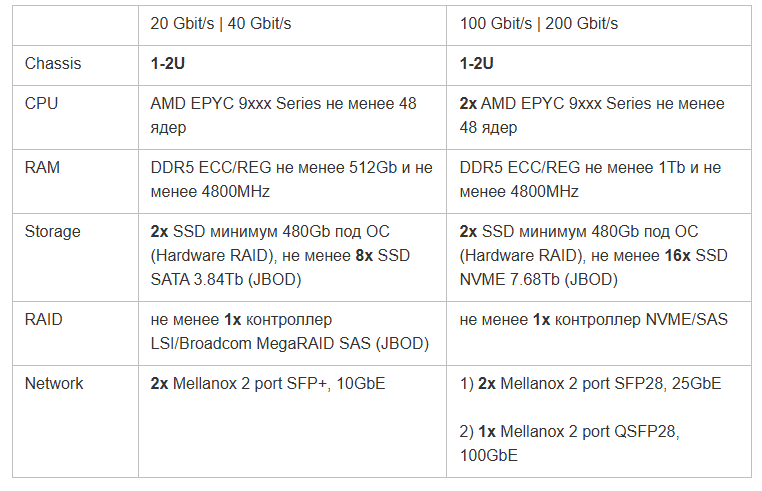
Ниже в таблице характеристики серверов для раздачи горячего и холодного контента. Для горячего L2-кэша в среднем не требуются очень производительные серверы и скорости отдачи в 20-40 ГБит/с обычно достаточно, зато их нужно много. L1 же прокачивает через себя больше контента, так как является промежуточным звеном и обеспечивает доступ к тому самому длинному хвосту из миллионов видео. Поэтому холодные серверы обычно мощнее и оснащены сетевыми картами на 100 или 200 Гбит/с.
При этом скорость раздачи сервера определяется не только сетевой картой, но и нашим договором с оператором связи и тем, сколько местный провайдер может раздавать трафика.
 Как раздать 200 Гбит/с с одного сервера
Как раздать 200 Гбит/с с одного сервера
Если просто взять сервер, вставить в него сетевую карту на 200 Гбит/с, то, к сожалению, без дополнительных усилий скорость отдачи будет намного ниже. Чтобы утилизировать всю пропускную способность сетевой карты, нужно знать, что такое NUMA — Non-Unified Memory Access.
Идея состоит в следующем: когда на сервере несколько процессоров, то скорость их доступа к разным областям памяти отличается. Потому что часть RAM для процессора будет локальной и соответственно более быстрой, а к другой он будет обращаться через шину (это называется interconnect), то есть медленнее. Ниже иллюстрация принципа работы NUMA.
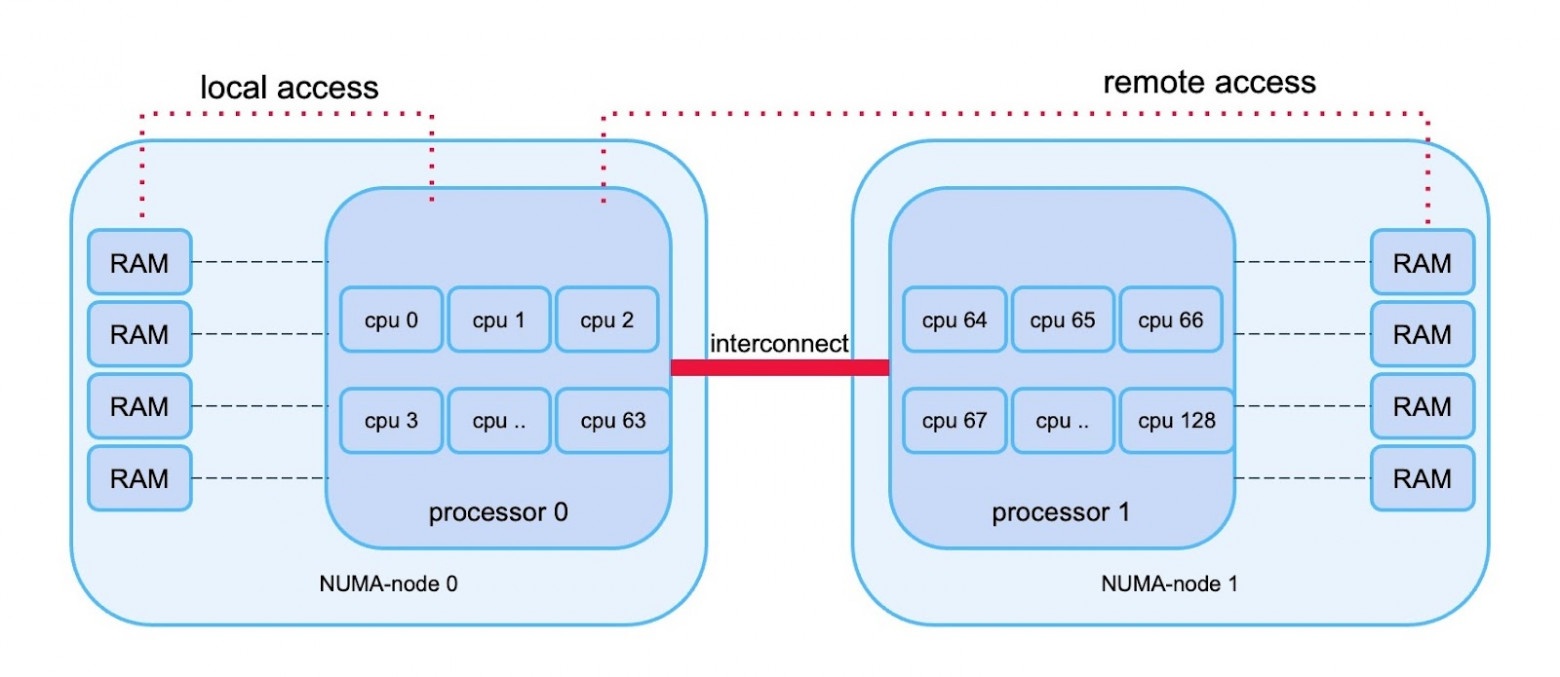
Схема работы с памятью на многопроцессорных серверах
Для того, чтобы раздавать с одного сервера все 200 Гбит/с, нужно привязывать прерывание сетевых карт к ядрам того процессора, который их обрабатывает, чтобы не обращаться к памяти через шину.
К счастью, для сетевых карт Mellanox, которые мы используем, уже есть специальные скрипты, которые позволяют настроить NUMA (см. github.com/Mellanox/mlnx-tools). Скрипты имеют возможность выбора профиля: minimum latency предназначен для оптимизации задержек, а high throughput — для максимальной пропускной способности. Нас в данном случае интересует максимальная пропускная способность.
Кэширование
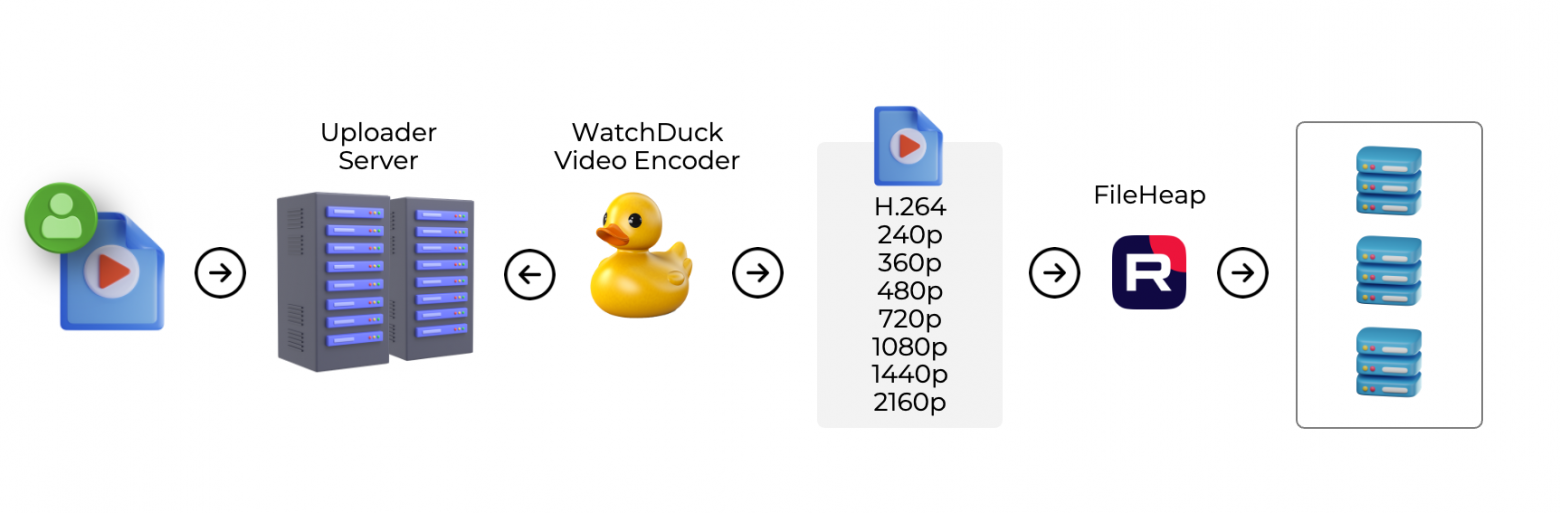
Разберём, как разложить контент по кэширующим серверам. Теоретически можно, например, с помощью rsync копировать видео из хранилища. Это даже будет работать, но придется городить целую схему, чтобы обеспечить эффективность и надёжность. Поэтому у нас кэширование организовано в обратную сторону: вместо того чтобы нам закачивать на CDN-серверы какие-то файлы, CDN сам скачивает нужные данные из хранилища по мере надобности при помощи обратного проксирования.
Мы используем nginx proxy_pass для скачивания и, что логично, делаем и proxy_cache, чтобы сервер складывал то, что скачал, в свой кэш. Также мы разделяем контент на чанки по 4 секунды, то есть скачиваются не сразу гигабайтные видеоролики, а чанки в несколько мегабайт.
Такая схема может генерировать достаточно большую нагрузку на диски, но её можно регулировать с помощью директивы proxy_cache_min_uses.
В зависимости от этого параметра контент будет попадать на диск только после нескольких обращений за ним.
Распределенное кэширование
На CDN-серверы под кэш мы ставим обычно 8-32 диска, но не объединяем их в общий RAID. Потому что, если вдруг RAID развалится, то потребуется долгая процедура rebuild. Вместо этого можно использовать такой трюк:
proxy_cache_path /media/d0 keys_zone=d0:512m levels=2:2:1 use_temp_path=off;
proxy_cache_path /media/d1 keys_zone=d1:512m levels=2:2:1 use_temp_path=off;
proxy_cache_path /media/d2 keys_zone=d2:512m levels=2:2:1 use_temp_path=off;
proxy_cache_path /media/d3 keys_zone=d3:512m levels=2:2:1 use_temp_path=off;
proxy_cache_path /media/d4 keys_zone=d4:512m levels=2:2:1 use_temp_path=off;
proxy_cache_path /media/d5 keys_zone=d5:512m levels=2:2:1 use_temp_path=off;
split_clients $request_uri $disk_cache {
16.66% d0;
16.66% d1;
16.66% d2;
16.66% d3;
16.66% d4;
16.66% d5;
* d0;
}
Здесь на каждый диск, который есть в сервере, определяется своя зона кэширования и через директиву split_clients разделяются запросы, которые приходят за контентом в кэш (подробнее см. документацию). Таким образом мы равномерно размазываем весь контент по всем дискам сервера.
Если какой-то диск выйдет из строя, что на наших масштабах случается регулярно, то достаточно его исключить и пересчитать директиву split_clients, и не нужно будет делать rebuild.
Кроме того, нужно учесть подключение серверов к операторам связи. Чтобы не дублировать контент на одной площадке, то есть не хранить одни и те же видео на серверах, стоящих в одном CDN-узле, но подключенных к разным операторам, у нас организовано распределенное кэширование.
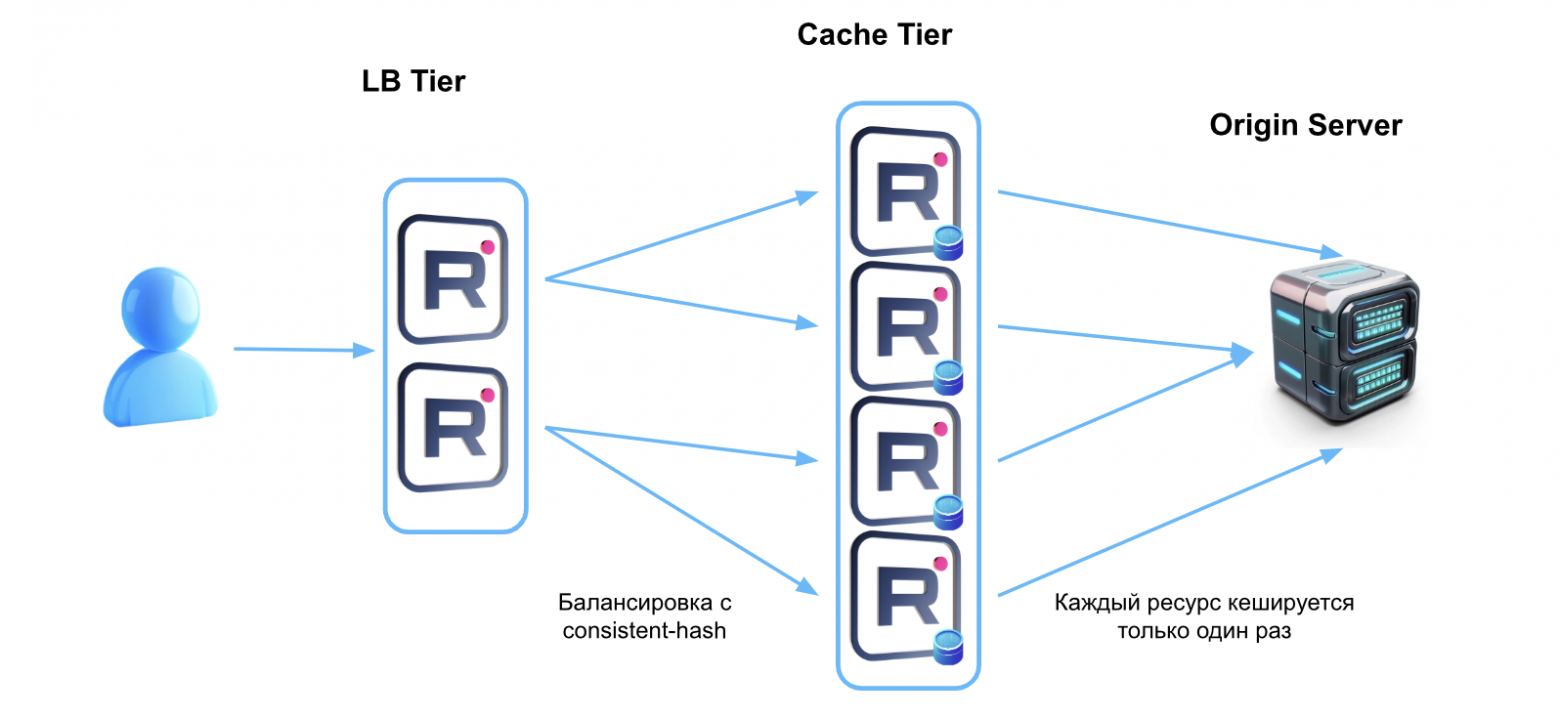
Распределенное кэширование устроено так, что каждый запрос, попадающий в nginx, проходит две стадии:
- балансировка с consistent-hash,
- непосредственно кэширование.
Таким образом, даже если запросы приходят от разных серверов, они попадают всегда на один и тот же кэш-сервер и дублирование не происходит. Сплошное пространство кэширования помогает эффективнее использовать ресурсы и обеспечивать большой объем закэшированного контента. Например, на площадке в Москве мы рассчитываем получить 10 Пбайт кэша.
На самом деле в качестве веб-сервера мы используем не nginx, а Angie — форк nginx от его бывших разработчиков. В Angie из коробки есть полезный нам расширенный мониторинг, а также там уже собраны некоторые сторонние модули, которых нам не хватает для nginx.
Поиск ближайшего сервера
После того, как мы разложили видео по горячим и холодным кэшам, нужно адресовать запрос от пользователя на правильный сервер так, чтобы:
- это был ближайший сервер, то есть чтобы было быстро;
- сбалансировать нагрузку, чтобы это было надёжно;
- и при этом эффективно расходовать сетевые ресурсы.
Для выбора ближайшего сервера существует BGP Anycast.
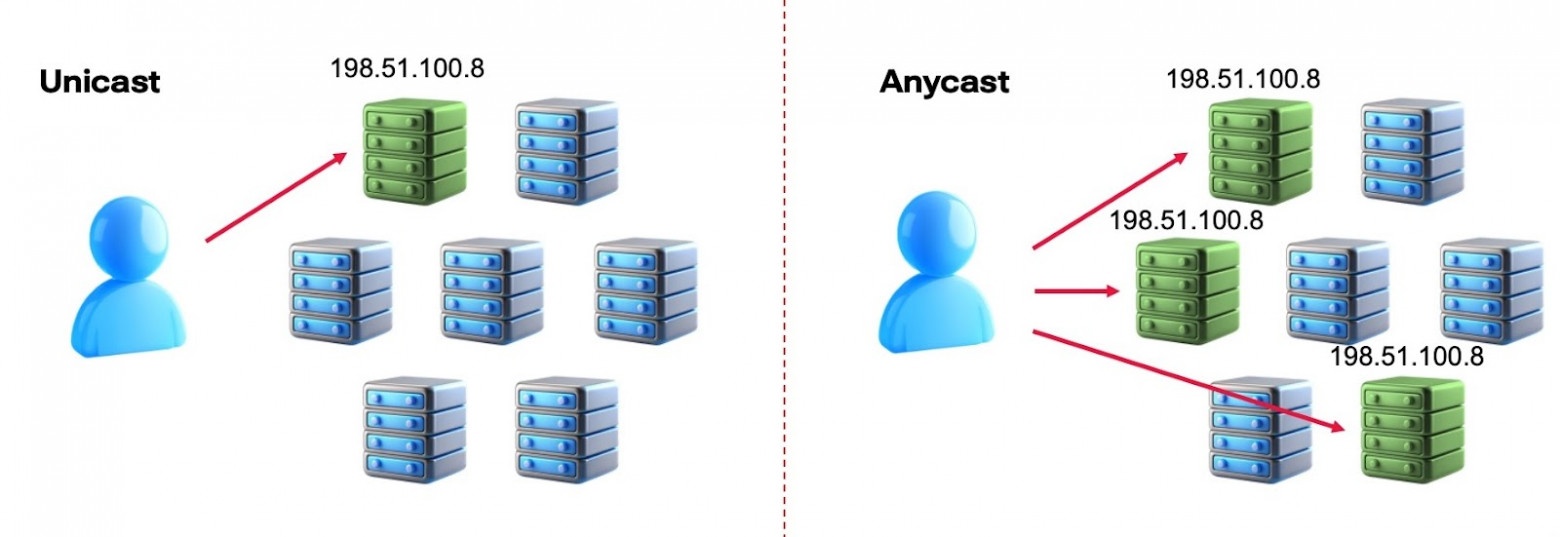
По Anycast один и тот же IP-адрес анонсируется из разных мест. Когда запрос идет по такому адресу, он автоматически попадает на ближайший сервер с точки зрения топологии сети.
Сделать Anycast достаточно несложно, нужно:
- купить сеть, которую мы будем анонсировать;
- поставить на сервер демон маршрутизации, мы используем bird;
- всё, profit.
Это будет работать, но если что-то в сломается, то починить будет трудно, потому что везде транслируется один и тот же IP-адрес, а значит, трудно локализовать проблему.
Кроме проблемы надёжности в нештатных ситуациях, с Anycast есть еще одна проблема: с точки зрения Anycast, ближайший сервер не всегда ближайший с точки зрения географии. Например, из Новосибирска ближайший сервер может оказаться в Санкт-Петербурге.
Чтобы определять ближайший к пользователю сервер с учётом физического расстояния, существует другая технология — GeoIP. GeoIP — это база данных производства компании MaxMind — по сути бинарный файл, который загружается в nginx-модуль. С его помощью в ответ на запрос с IP-адресом nginx возвращает: регион местоположения пользователя, город, а также, возможно, информацию об операторе.
Однако в GeoIP-базе MaxMind есть неточности, причём количество этих неточностей растет, поэтому нам приходится накладывать на неё правки.
Ниже представлен пример корректировки GeoIP-базы:
- заводим список, где пишем IP-адреса и то, к какому региону их нужно относить;
- через директиву geo формируем переменную, которая в ответ на IP-запрос возвращает расположение;
- делаем map на приоритетное использование региона из нашего списка.
# geoip_corrections.conf example
198.51.100.0/24 Moscow; # RFC 5737 TEST-NET-2
# nginx.conf
geo $region_name_from_geo {
# The variable will be empty if IP address does not match.
include geoip_corrections.conf;
}
# Now we combine region names.
map $region_name_from_geo $region_name {
# If there is no correction.
'' $geoip2_region_name;
# And if there is.
default $region_name_from_geo;
}
Это было бы не такой уж большой проблемой, если бы не влияло на пользователей. Но, к сожалению, о необходимости поправок мы обычно узнаём из обращений зрителей. Как это происходит? Неправильный GeoIP приводит к двум нежелательным ситуациям:
- Если определить неправильный регион, то можно направить зрителя не на ближайший сервер. Зритель скорее всего этого не поймёт и не будет жаловаться, но мы же хотели так не делать.
- Если неверно определить страну, то из-за локальных лицензионных ограничений контент может вовсе стать недоступен для пользователя. Тогда, возможно, он обратится в поддержку, мы всё исправим, но зритель на какое-то время останется без любимого шоу и будет расстроен.
Есть другой вариант GeoIP-базы, но с ними тоже есть свои особенности. Во-первых, в базе MaxMind 32 млн записей, а в geoip.noc.gov.ru — 4,5 млн записей. Допустим, это не так страшно, потому что это записи о сетях и они могут быть разного размера. Во-вторых, в базах различаются названия регионов, например, Chuvashia вместо Chuvash Republic. И третье, что нам действительно мешает перейти на эту базу: порядка 5 млн IP-адресов со всей страны в ней приписаны к Москве. То есть она опять не позволит всегда корректно определять ближайшие кэш-серверы, некоторым зрителям из регионов по-прежнему придется ждать лишнее время, чтобы посмотреть видео на RUTUBE.
Балансировка
Все запросы зрителей за видео идут не напрямую к одному из CDN-серверов, с сначала попадают в наше самописное ПО, которое называется видеобалансер.
Видеобалансер:
- определяет, где находится зритель, по GeoIP-базе;
- учитывает оператора, чтобы раздавать контент по возможности минуя меж-операторские стыки;
- считает температуру видео, то есть горячий это контент или холодный;
- мониторит нагрузку на серверы CDN;
- распределяет зрителей на ближайший свободный сервер, где есть нужный контент.
Ниже скриншот из видеобалансера — у него утилитарный инженерный интерфейс, не самый красивый, но рабочий.
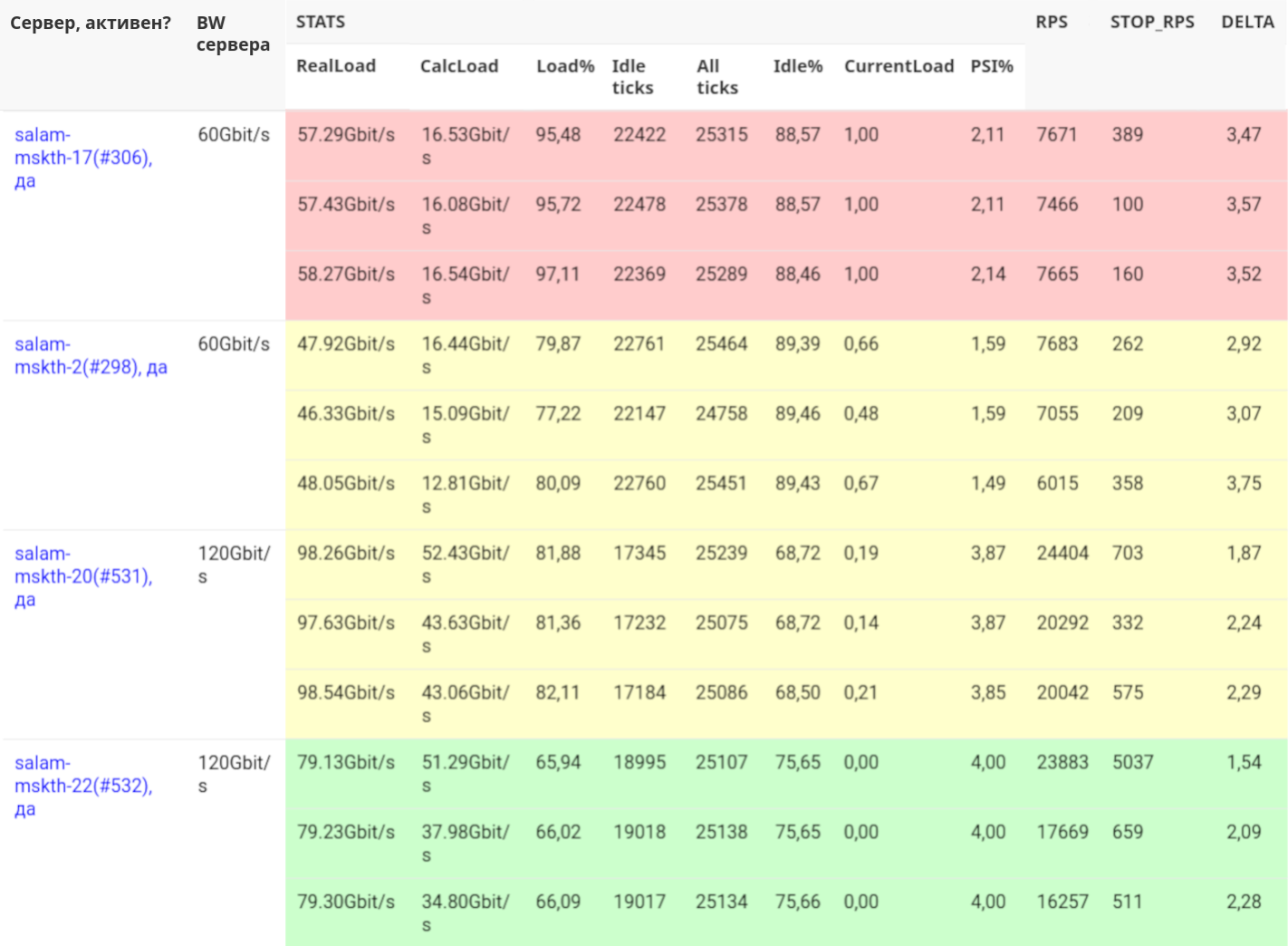
На скриншоте каждому серверу соответствует три строки, потому что балансер развернут в нескольких ЦОДах для отказоустойчивости. Цветами обозначен уровень загрузки: красному серверу уже хватит, жёлтый ещё может выдержать нагрузку, а зеленый явно недогружен.
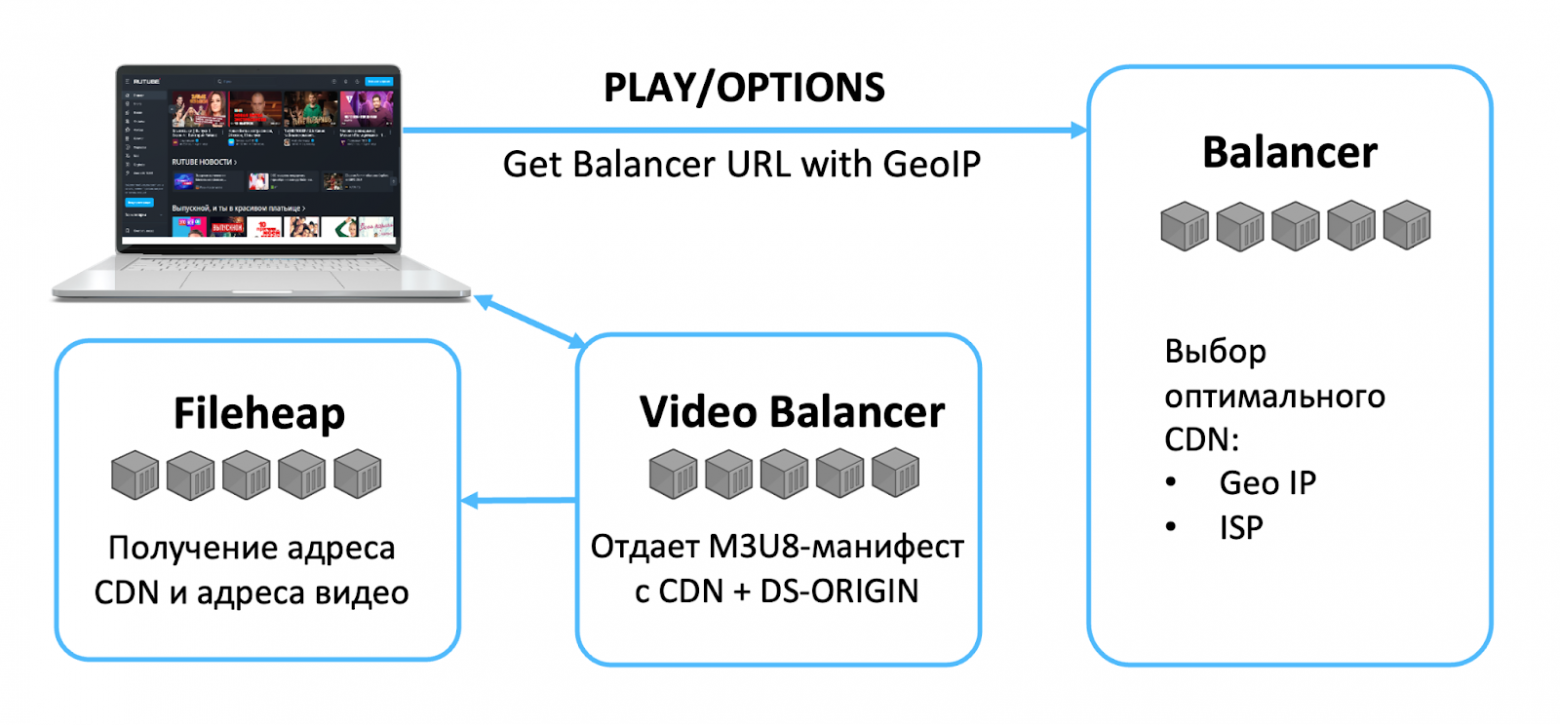
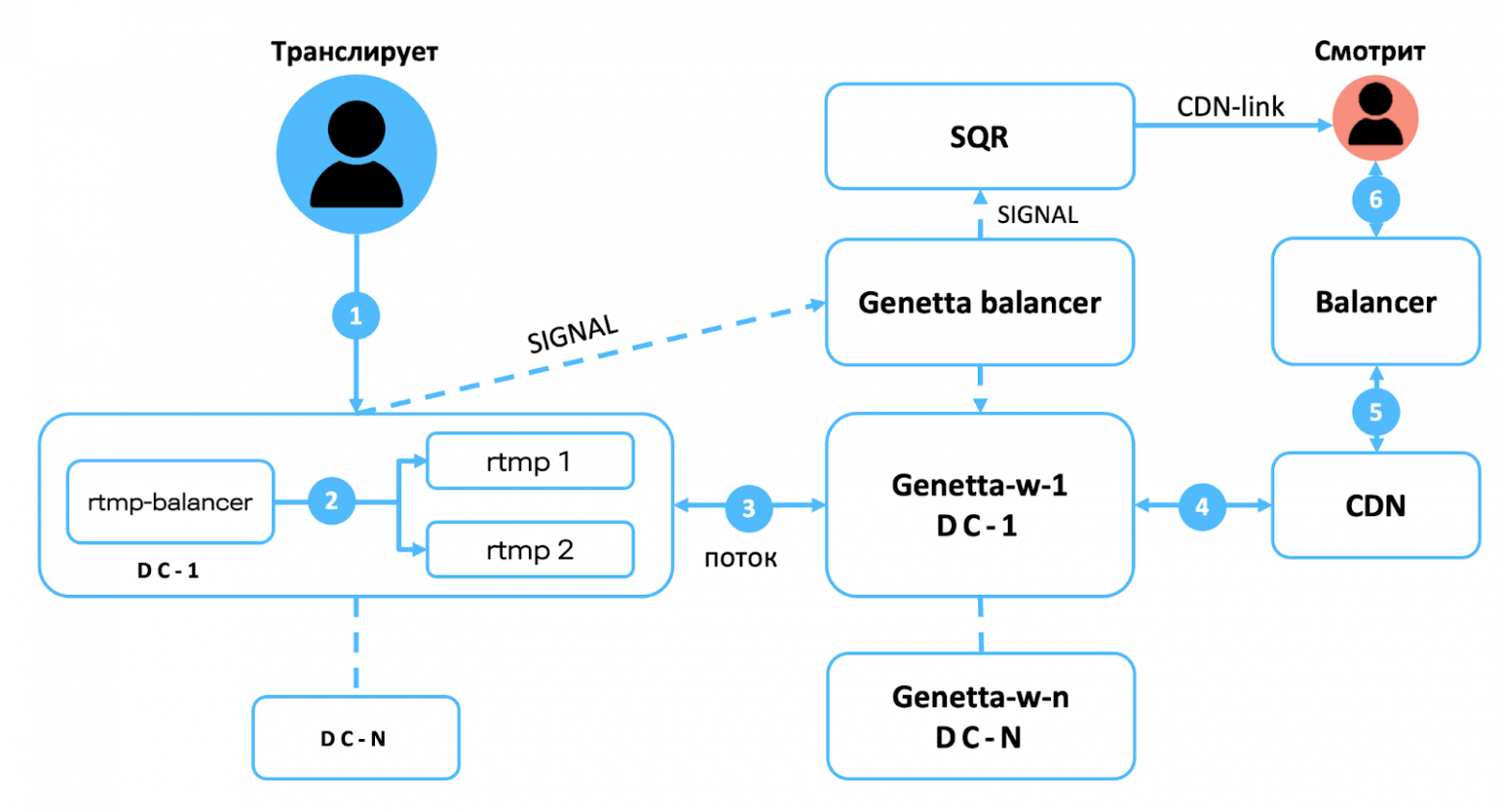
Итоговая схема раздачи приведена на схеме ниже.
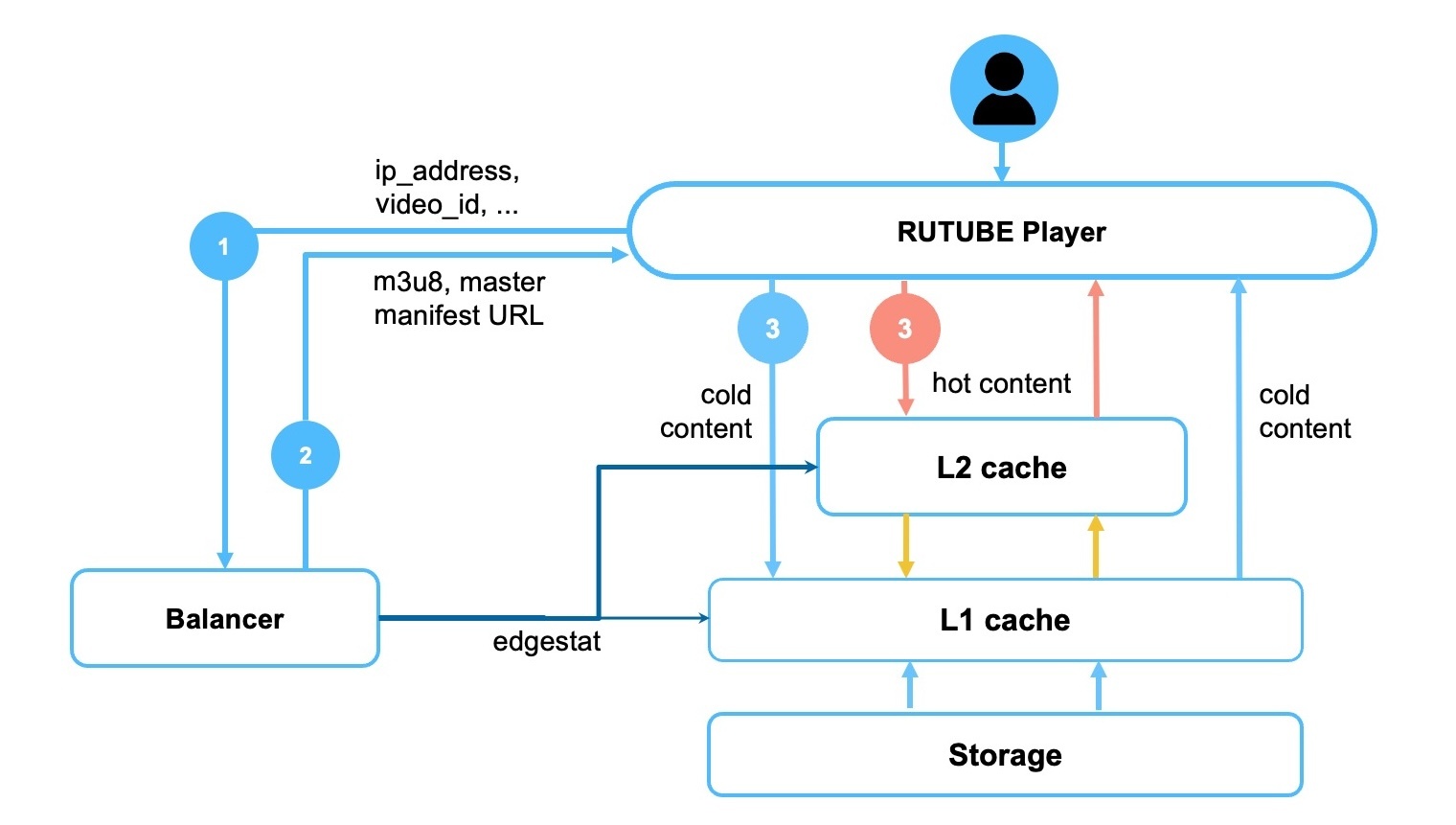
Когда пользователь открывает плеер RUTUBE происходит следующее:
- клиент отправляет запрос за видео в видеобалансер;
- балансер по GeoIP определяет ближайший к пользователю CDN;
- балансер знает температуру запрашиваемого видео, он мониторит CDN-серверы и в соответствие с этими данными возвращает мастер-манифест на клиент со ссылками на плейлисты с чанками запрашиваемого видео;
- по манифесту зритель уже направляется на конкретные CDN-серверы (с учётом всех уровней кэширования, которые мы рассмотрели ранее).
Edgestat на схеме выше — это наш сервис мониторинга, с помощью которого балансер узнаёт о состоянии серверов. Edgestat написан на Go и напрямую из псевдо-файловой системы /proc собирает параметры производительности процессора, сети и пр. Ниже пример файла, который модуль мониторинга возвращает в балансер:
{
"net": {
"tx_bytes": 3070389798640361
},
"cpu": {
"user": 821038789,
"nice": 7206904,
"system": 1068090496,
"idle": 8891017069,
"iowait": 140402173,
"irq": 183963736,
"softirq": 1899188205,
"steal": 0,
"guest": 0,
"guest_nice": 0
},
"tcp": {
"out": 4009339463073,
"retrans": 107337952956
},
"pressure": {
"cpu": 0.42,
"io": 1.77,
"memory": 0.77,
"irq": 1.7
}
}
Разберем подробнее блок «pressure». Pressure Stall Information — подсистема внутри Linux-ядра, которая отслеживает задержки в работе системы, связанные с нехваткой железных ресурсов, таких как CPU, устройств ввода-выводы, память.
По меркам ядра PSI появилась относительно недавно, около 7 лет назад. А также буквально пару лет назад — совсем новинка — в неё добавили отслеживание задержек по обработке прерываний — IRQ (значения в микросекундах).
Мониторить irq особенно полезно на серверах, обрабатывающих много трафика, так как в таких условиях обработка прерываний от сетевой карты уже может вносить существенный вклад в общую производительность.
$ ls /proc/pressure
cpu io irq memory
$ cat /proc/pressure/io
some avg10=2.50 avg60=2.38 avg300=2.34 total=13968383315
full avg10=2.35 avg60=2.22 avg300=2.15 total=12888830571
$ cat /proc/pressure/irq
full avg10=0.64 avg60=0.36 avg300=0.24 total=7294258624
$
На серверах, прокачивающих большой трафик, например, как у нас в Тбит/с, показатель irq pressure часто скачет и сообщает нам, что сервер перегружен, даже если этого не видно по другим характеристикам. Внедрение PSI помогло нам окончательно избавить CDN от тормозов — повысить скорость.
Для обеспечения дополнительной надёжности в схеме раздачи в мастер-манифесте содержится не один, а два CDN-сервера: основной и резервный. Мастер-манифест — это по сути плейлист из плейлистов, выглядит примерно так:
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=478000, FRAME-RATE=25, CODECS="avc1.42c01f, mp4a.40.2", RESOLUTION=256x144
https://cdn-server
#EXT-X-STREAM-INF:PROGRAM-ID=1, BANDWIDTH=478000, FRAME-RATE=25, CODECS="avc1.42c01f, mp4a.40.2", RESOLUTION=256x144
https://backup-cdn
Наличие резервного CDN-сервера в манифесте позволяет клиенту без дополнительных запросов и лишнего ожидания переключиться с одного сервера, с которым по какой-то причине проблемы, на другой. Причём бэкапный сервер определяется по Anycast — то есть мы резервируем ещё и способы определения подходящего CDN-сервера.
Сеть
Работа с сетью — также неотъемлемая часть эффективной реализации CDN, ведь на таких расстояниях и объемах трафика сеть легко может стать узким местом.
Ниже неполный вывод команда ip, который показывает список сетевых интерфейсов одного из наших CDN-серверов.
$ ip -c a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: aggr0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond0 state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:x1 brd ff:ff:ff:ff:ff:ff
3: aggr1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond0 state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:x2 brd ff:ff:ff:ff:ff:ff
4: aggr2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond1 state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:x3 brd ff:ff:ff:ff:ff:ff
5: aggr3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond1 state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:x4 brd ff:ff:ff:ff:ff:ff
6: anycast2: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether xx:xx:xx:xx:xx:xa brd ff:ff:ff:ff:ff:ff
inet 198.51.100.79/24 brd 89.248.230.255 scope global anycast2
valid_lft forever preferred_lft forever
7: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:xb brd ff:ff:ff:ff:ff:ff
inet 192.0.2.1/24 brd 192.0.2.0 scope global bond0
valid_lft forever preferred_lft forever
8: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:xc brd ff:ff:ff:ff:ff:ff
inet 203.0.113.2/24 brd 203.0.113.0 scope global bond1
valid_lft forever preferred_lft forever
$
То есть на каждом из десятков CDN стоят серверы с десятками же сетевых интерфейсов — всем этим нужно эффективно и надёжно управлять. Например, везде должны быть правильные согласованные с операторами настройки. Использовать для этого штатный NetworkManager не очень удобно, поэтому мы перешли на systemd-networkd.
systemd-networkd — это демон для настройки сети. Как и всё в systemd, все настройки в нём хранятся в текстовых файлах, что удобно для автоматизации, например, Ansible.
Ниже пример файла .link, который настраивает физические сетевые устройства. В нём задаётся максимальный размер буферов для эффективной раздачи больших объемов трафика.
# /etc/systemd/network/10-aggr0.link
[Match]
MACAddress=xx:xx:xx:xx:xx:xx
[Link]
Name=aggr0
RxBufferSize=max
TxBufferSize=max
В файле .netdev описываются виртуальные сетевые устройства, например, bond — объединение двух физических сетевых устройств в одно логическое для большей отказоустойчивости или скорости отдачи.
# /etc/systemd/networkd/bond0.netdev
[NetDev]
Name=bond0
Kind=bond
[Bond]
Mode=802.3ad
MIIMonitorSec=100ms
TransmitHashPolicy=layer3+4
Другой пример полезной настройки в .netdev — dummy-интерфейс. По сути это loopback, который мы используем для того, чтобы на него назначать Anycast-адрес. Можно назначить этот Anycast-адрес как второй ip-адрес на сетевой интерфейс, но тогда, если сетевой интерфейс перестанет работать, то и Anycast-адрес перестанет быть доступным.
# /etc/systemd/network/anycast2.netdev
[NetDev]
Name=anycast2
Kind=dummy
Третий вид файлов systemd-networkd это .network. Они описывают стандартные настройки: IP-адреса, gateway, маршруты и т.д.
# /etc/systemd/network/aggr0.network
[Match]
Name=aggr0
[Network]
Bond=bond0
# /etc/systemd/network/bond0.network
[Match]
Name=bond0
[Network]
Address=12.34.56.78/28
Gateway=12.34.56.79
Подключение операторов
Обычно мы стараемся подключать к одному серверу одного оператора. Но в определенный момент наши возможности и потребности по подключению операторов превосходили наличие доступных серверов, и мы стали подключать несколько операторов в один сервер.
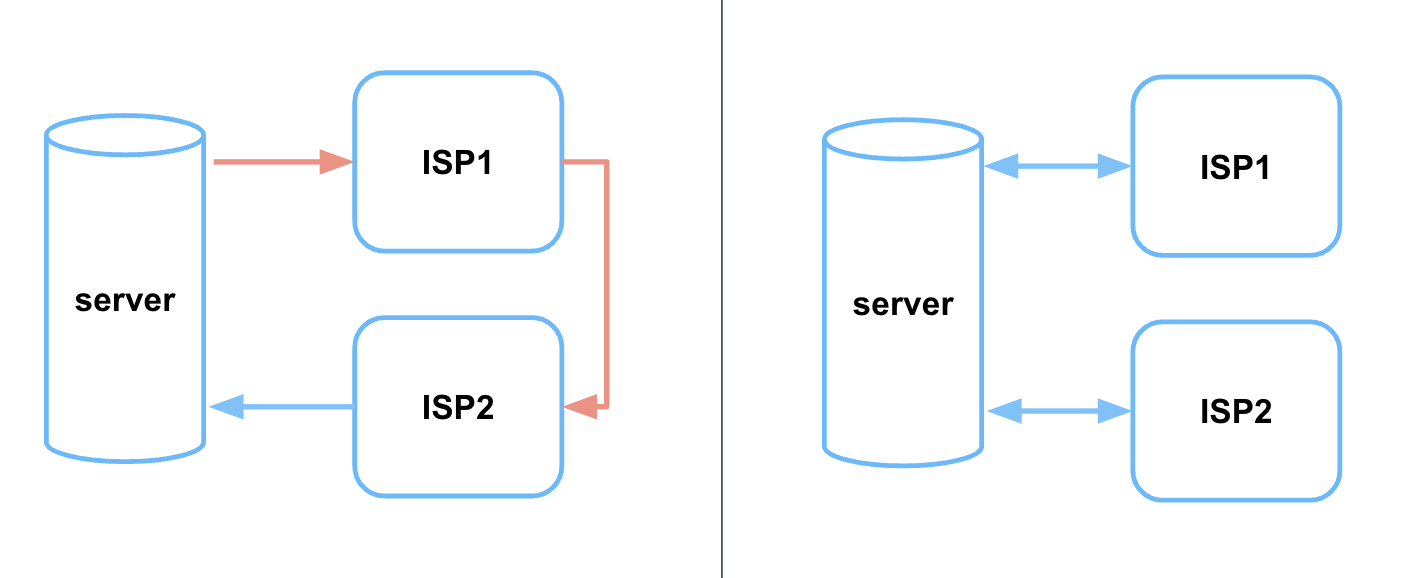
Проблема в том, что при подключении двух операторов к одному серверу «в лоб» получается асимметричная маршрутизация. Её эффект показан на иллюстрации слева:
- на anycast-адрес второго оператора приходит запрос,
- ответ на этот запрос направляется default gateway, который скорее всего будет указывать в первого оператора.
Получится медленнее и менее надёжно из-за сетевых стыков и более длинного маршрута. Очевидно, что схема как на иллюстрации справа лучше.
Как сделать, чтобы ответ на запрос уходил тому же оператору, от которого он пришел? При помощи fwmark — меток сетевых пакетов. Это виртуальные метки, которые ставятся на сетевые пакеты и при этом существуют в рамках одного Linux-хоста. Они позволяют сделать такой трюк:
chain prerouting {
type filter hook prerouting priority mangle; policy accept;
iifname "bond0" ip daddr 198.51.100.0/24 meta mark set 0x00000010 accept comment "isp1 fwmark"
iifname "bond1" ip daddr 198.51.100.0/24 meta mark set 0x00000020 accept comment "isp2 fwmark"
}
Выше представлены правила nftables: на запросы, приходящие через сетевой интерфейс «bond0», ставим на него метку 0x00000010 (неважно какую, важно, что не ноль), а на «bond1» ставим другую метку.
В соответствие с этим прописываем и исходящие правила маршрутизации:
$ ip rule
0: from all lookup local
110: from 198.51.100.0/24 fwmark 0x10 lookup 100 proto static
120: from 198.51.100.0/24 fwmark 0x20 lookup 101 proto static
32766: from all lookup main
32767: from all lookup default
$
Здесь в приоритете 110 написано: если запрос с Anycast-адреса и есть метка 0x10, то нужно посмотреть в таблицу номер 100, где будет default gateway для bond0; а если метка другая — то надо смотреть в другую таблицу, где уже будет default gateway для bond1.
Воедино входящие правила фаервола и исходящие правила маршрутизации связывают несколько sysctl:
net.ipv4.tcp_fwmark_accept=1
net.ipv4.fwmark_reflect=1
net.ipv4.conf.all.src_valid_mark=1
Здесь написано следующее: если на сетевой пакет, который пришел на данный сетевой интерфейс, есть метка, то её нужно скопировать на весь сокет и выставлять на все исходящие пакеты в рамках соединения.
Player events
Мы мониторим состояние серверов, но кроме того, для надёжности, плеер пользователя в случае каких-либо проблем научен отправлять специальные сообщения, которые называются player events. Если на клиенте, в вебе, в мобильном или Smart TV приложении RUTUBE возникнут какие-то проблемы с доступом к CDN, то мы узнаем об это по резервному маршруту. Например, сбои в каком-то сегменте сети, дадут всплеску player events и наш мониторинг тут же отреагирует.
И последняя в этой статье оптимизация: простая, но важная. Мы уже говорили, что используем демон маршрутизации BIRD, чтобы анонсировать Anycast. Логично, что тогда должен быть запущен и nginx, чтобы он что-то раздавал. Если запустить bird, но не запустить nginx (а у нас такое бывало), то зрители придут и попадут в черную дыру. Чтобы такого избежать, можно использовать такой трюк:
# /etc/systemd/system/bird.service.d/requisite_nginx.conf
[Unit]
# If nginx is stopped, bird will be stopped as well.
# If nginx is not running, bird will refuse to start.
# If bird is stopped, nginx is not affected.
# If nginx is restarted, bird is not affected.
Requisite=nginx.service
Главное тут в последней строчке: если nginx запущен, то bird работает; если nginx выключить, то bird погаснет; если nginx не запущен, то и bird не запустится.
Итоги
В этой статье мы рассмотрели архитектуру CDN RUTUBE: как кэшировать, балансировать нагрузку, обеспечивать отказоустойчивость или, в крайнем случае, деградировать незаметно для зрителей. Как сделать CDN, чтобы показывать нашим пользователям видео быстро, надежно и эффективно.
Вот три основных момента, на которые нужно обратить внимание, если вы строите свой CDN:
- Если вы только начинаете строить CDN, то начните с BGP Anycast как наиболее простого варианта. Но не ограничивайтесь им и подключайте узконаправленные средства балансировки, подходящие для вашего профиля трафика и нагрузки.
- Используйте разные источники мониторинга: и изнутри системы, и снаружи.
- Pressure Stall Information — это ваш союзник в борьбе с тормозами.