





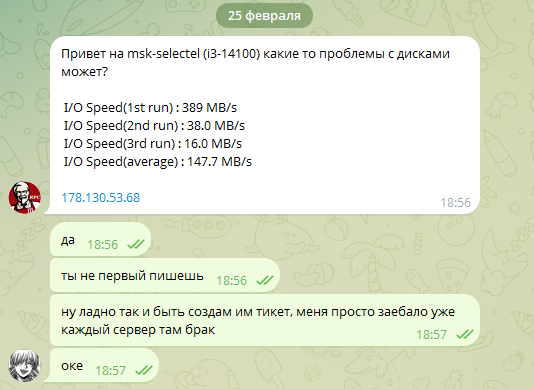
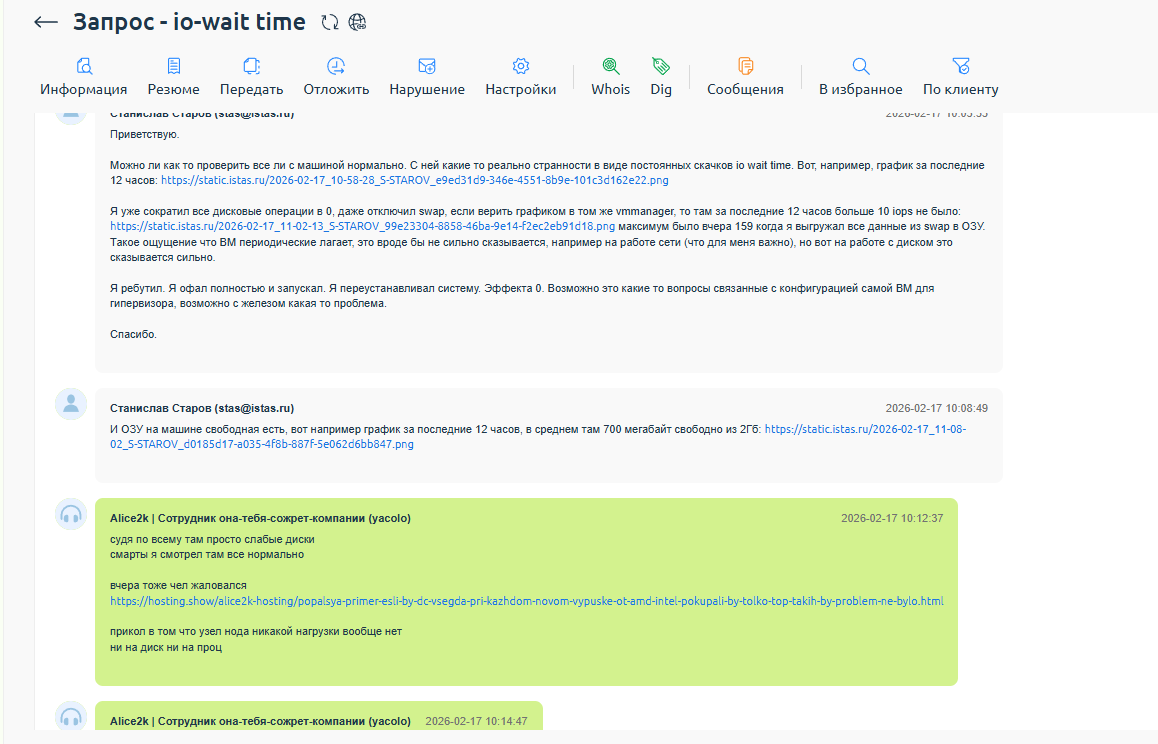
Видимо 450 480 512 диски SSD реально пиздец столетние 10 летней давности, пусть и новые лежащие на складах.
Изначально я сделал 9950x в Селектеле как боевое решение.
А lowcost микро вдс решил делать на всяких 32 озу серверах селектела.
И блин постоянно жалобы что там все тормозит.
Если бы они покупали только топ железо,
такого бы не случилось.
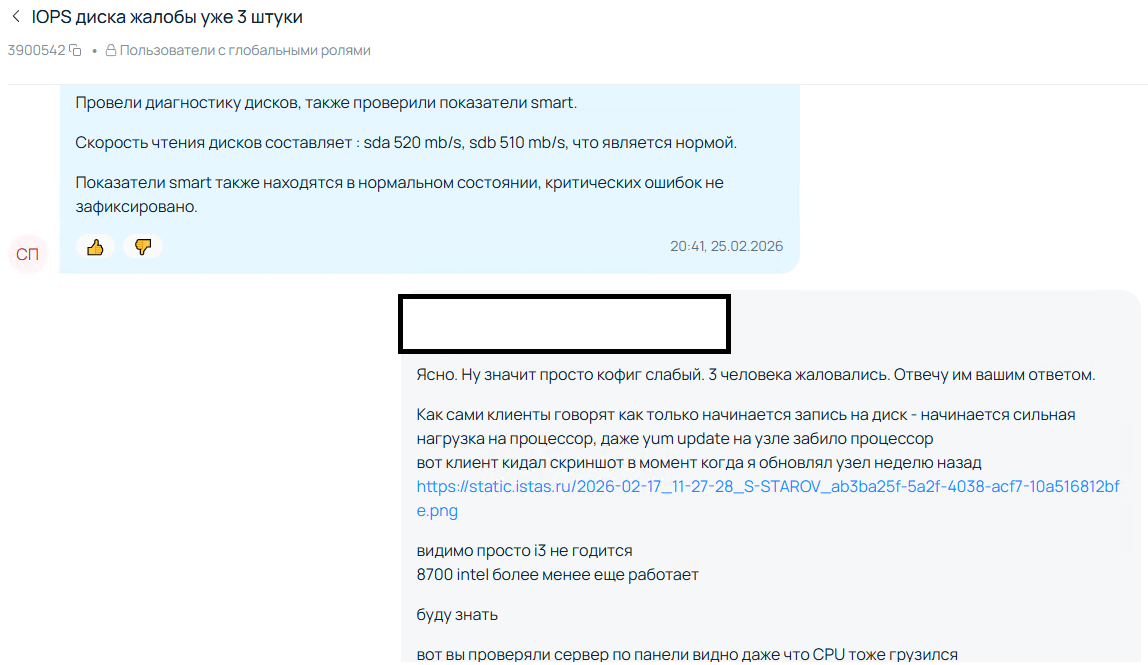
- В итоге я включил калькулятор
- Подумал над жадностью и сказал, ладно, мне не жалко.
- Технически можно сделать микро тариф даже из 7950x/128 по 19000р
- И не меняя lowcost цены сделать такой же микро тариф на нормальном 2 ТБ современном диске NVME с большими IOPS
 И встречаем
И встречаем
- RU-Москва, 7950x (4,5 ГГц) [1 vCore] / 1 DDR5 / 25 ГБ NVME — 350р
- RU-Москва, 7950x (4,5 ГГц) [2 vCore] / 2 DDR5 / 50 ГБ NVME — 500р
- RU-Москва, 7950x (4,5 ГГц) [3 vCore] / 4 DDR5 / 100 ГБ NVME — 800р
- RU-Москва, 7950x (4,5 ГГц) [4 vCore] / 6 DDR5 / 150 ГБ NVME — 1100р
- RU-Москва, 7950x (4,5 ГГц) [8 vCore] / 8 DDR5 / 200 ГБ NVME — 1400р
Никаких
ALL Core, исключительно микро тарифы с микро ядрами.
RU-Москва, i7-8700 (3,2 ГГц) [1 vCore] / 1 DDR4 / 25 ГБ SSD 350р
RU-Москва, i7-8700 (3,2 ГГц) [2 vCore] / 2 DDR4 / 50 ГБ SSD 500р
RU-Москва, i7-8700 (3,2 ГГц) [3 vCore] / 4 DDR4 / 100 ГБ SSD 800р
RU-Москва, i7-8700 (3,2 ГГц) [4 vCore] / 6 DDR4 / 150 ГБ SSD 1100р
RU-Москва, i7-8700 (3,2 ГГц) [6 vCore] / 8 DDR4 / 200 ГБ SSD 1400р
Заказать
bill.yacolo.net/billmgr
Если биллинг у вас не доступен используйте
a-panel-to-register-and-purchase-due-to-stupid-legislation.ru/billmgr

