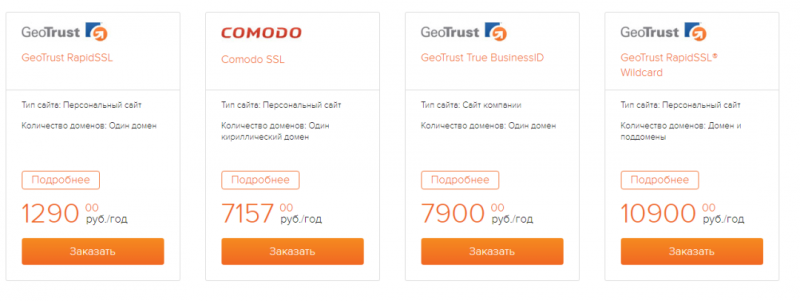
Благодаря особым технологиям шифрования, SSL-сертификаты не позволяют получить злоумышленникам доступ к информации, которую посетители оставляют на сайте. Мы предлагаем разные типы сертификатов в зависимости от поставленных задач.
Теперь купить SSL-сертификат можно прямо у нас на сайте. Просто выбирайте параметры и опции, кликайте на нужные и система сама предложит подходящий SSL-сертификат.
Среди опций можно выбрать Зеленую строку браузера, типы сайтов и количество доменов. Останется только авторизоваться, оплатить и установить сертификат на сервер!
Не уверены, что вашему сайту нужен SSL–сертификат?
Отвечаем на ваши основные вопросы:
Что именно защищает SSL–сертификат?
Данные, передаваемые между вашим сервером и браузером посетителя. Это: логины, пароли, номера пластиковых карт, электронных кошельков. Без должной защиты вся эта информация может быть украдена злоумышленниками.
Повысит ли SSL-сертификат доверие к моему сайту?
Посетители доверяют сайтам с SSL- сертификатами, ведь протокол SSL обеспечивает безопасность обмена данными. Также Вы будете иметь преимущество в поисковой выдаче перед другими сайтами, на сервере которых не установлен SSL-сертификат, так как с начала 2017 года браузер Chrome отмечает небезопасными страницы сайтов без SSL сертификатов.
Домен, для которого я хочу заказать SSL, зарегистрирован на другое лицо. Могу я приобрести SSL-сертификат?
Да, но только в случае заказа сертификата с проверкой домена. Если Вы заказали сертификат с проверкой организации или зеленой строкой в браузере, то вендор должен убедиться в том, что заявитель имеет исключительное право на использование домена, указанного в сертификате, поэтому заказ на разные юридические лица невозможен.
Что мне даст SSL–сертификат с расширенной проверкой организации?
Во-первых, защиту, которую видно сразу всем посетителям Вашего сайта! Адресная строка браузера подсвечивается зелёным цветом, в которой указано наименование компании, которая его получила. Во- вторых, благодаря расширенной проверке юридического существования организации у посетителей Вашего сайта не останется сомнений, что Вы надёжный партнер, поставщик или продавец. Ваш сайт будет выгодно выделяться на фоне конкурентов!
Если я получил SSL–сертификат, значит ли это, что он автоматически будет установлен на сервер?
Заключительным этапом активации защищенного соединения является установка SSL-сертификата на сервер. В том случае, если хостинг сайта предоставляет наша компания, рекомендуем обратиться в техническую поддержку за получением подробной консультации. Если домен привязан к хостингу стороннего провайдера, обратитесь в службу поддержки вашего хостинг-провайдера.
www.activecloud.ru/ru-by/services/ssl/