Drilling down into Stackdriver Service Monitoring
Если вы несете ответственность за производительность и доступность приложений, вы знаете, как трудно это увидеть глазами ваших клиентов и конечных пользователей. Мы думаем, что это действительно изменится после внедрения на прошлой неделе Stackdriver Service Monitoring, нового инструмента для мониторинга того, как ваши клиенты воспринимают ваши приложения, а затем позволяет вам перейти к базовой инфраструктуре, когда есть проблема.
Большинство инструментов ИТ-операций занимают мало внимания в отношении ИТ-систем: они смотрят на вычисления, хранилища и сетевые показатели, чтобы выявить опыт работы с клиентами. Средства управления эффективностью приложений (APM), такие как системы трассировки, отладчики и профилировщики, рассматривают приложение с уровня кода, но упускают из виду базовую инфраструктуру. Иногда решение аналитики журналов может обеспечить клей между этими двумя слоями, но часто с большими усилиями и расходами.
У ИТ-операторов отсутствует экономичный и простой в использовании инструмент общего назначения для мониторинга поведения своих приложений, ориентированного на клиента. Трудно понять, как конечные пользователи испытывают ваше программное обеспечение, и сложно стандартизовать службы и приложения. Персонал Ops рискует выгорать из всех ложных предупреждений. Результатом всего этого является то, что среднее время-разрешение (MTTR) больше, чем необходимо, и удовлетворенность клиентов ниже желаемого. Ситуация усугубляется с помощью микросервисных архитектур, где само приложение разбито на множество мелких кусочков, что затрудняет понимание того, как все части подходят друг другу и где начать расследование, когда есть проблема.
Все это происходит с выпуском Stackdriver Service Monitoring. Мониторинг сервисов использует сервисную, «укомплектованную» инфраструктуру, поэтому вы можете отслеживать, как конечные пользователи воспринимают ваши системы, позволяя вам, когда это необходимо, перейти на уровень инфраструктуры. Первоначально мы поддерживаем эту функциональность для Google App Engine и сервисов Istio, работающих в Google Kubernetes Engine. С течением времени мы будем расширяться до большего количества платформ.
С помощью Stackdriver Service Monitoring вы получаете ответы на следующие вопросы:
Анатомия мониторинга службы стоп-приводов
Сервисный мониторинг состоит из трех частей: графика обслуживания, целей уровня обслуживания (SLO) и панелей мониторинга с несколькими сигналами. Вместе они дают вам список ваших услуг, визуально отображают зависимости между ними, позволяют устанавливать и оценивать возможности доступности и производительности, помогать вам устранять проблемы приложений, чтобы быстро найти основную причину и, наконец, помочь вам быстрее отлаживать сломанные услуги чем когда-либо. Давайте посмотрим на каждую часть по очереди.
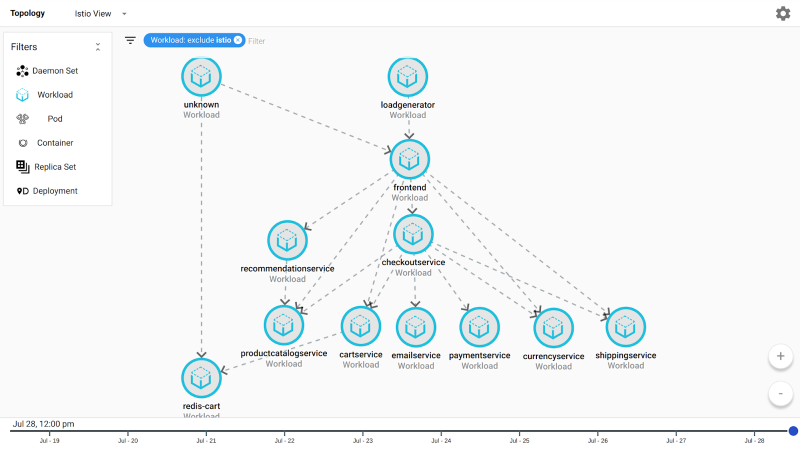
Сервисный график: это представление о вашей инфраструктуре, относящееся к услугам. Он начинается с отображения верхнего уровня в реальном времени всех сервисов в сервисной сетке Istio и связей между ними. При выборе одной услуги отображаются графики с коэффициентами ошибок и метриками задержки. Двойной щелчок по сервису позволяет развернуть свою базовую инфраструктуру Kubernetes, обеспечивая длинную неуловимую связь между поведением приложения и инфраструктурой. Существует также ползунок времени, который позволяет вам видеть график в предыдущие моменты времени. Используя сервисный график, вы можете увидеть свою архитектуру приложения для справочных целей или для сортировки проблем. Вы можете изучить показатели поведения службы и определить, вызывает ли восходящий сервис проблемы с последующей службой. Наконец, вы можете сравнить график обслуживания в разные моменты времени, чтобы определить, было ли значительное архитектурное изменение прямо перед сообщением проблемы. Существует не более быстрый способ начать изучение и понимание сложных мультисервисных приложений.
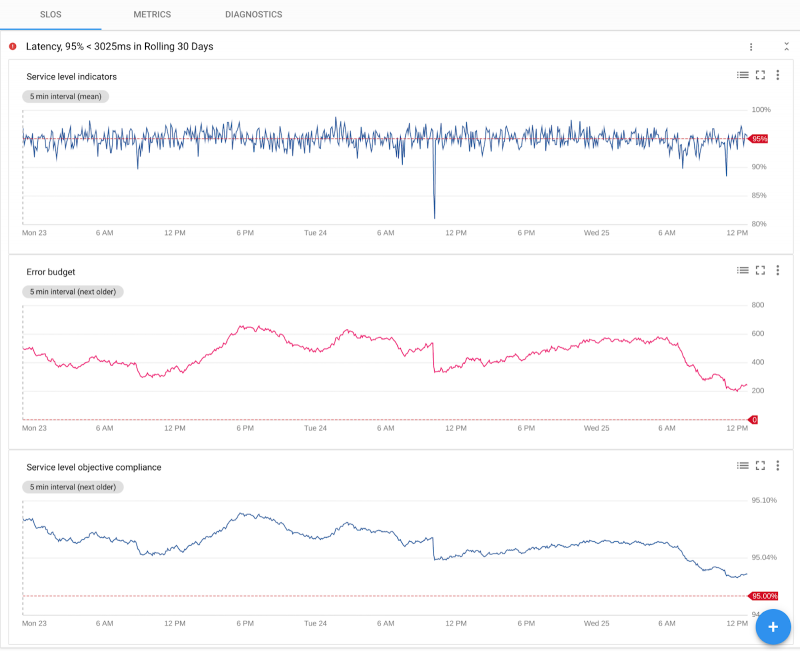
SLO: внутренне в Google наша команда инженеров по надежности сайта (SRE) только предупреждает себя о проблемах, связанных с клиентами, и не во всех потенциальных причинах. Это лучше согласовывает их с интересами клиентов, снижает их трудность, освобождает их, чтобы делать надёжную инженерию с добавленной стоимостью и повышает удовлетворенность работой. Stackdriver Service Monitoring позволяет вам устанавливать, контролировать и предупреждать о SLO. Поскольку Istio и App Engine имеют укрупненный способ, мы точно знаем, что подсчет транзакций, количество ошибок и распределение задержек находятся между службами. Все, что вам нужно сделать, — установить целевые показатели доступности и производительности, и мы автоматически генерируем графики для индикаторов уровня обслуживания (SLI), соответствия вашим целям с течением времени и вашего оставшегося бюджета ошибок. Вы можете настроить максимально допустимую скорость снижения для бюджета ошибок; если эта ставка превышена, мы уведомляем вас и создаем инцидент, чтобы вы могли принять меры. Чтобы узнать больше о концепциях SLO, включая бюджет ошибок, мы рекомендуем вам прочитать главу SLO в книге SRE.
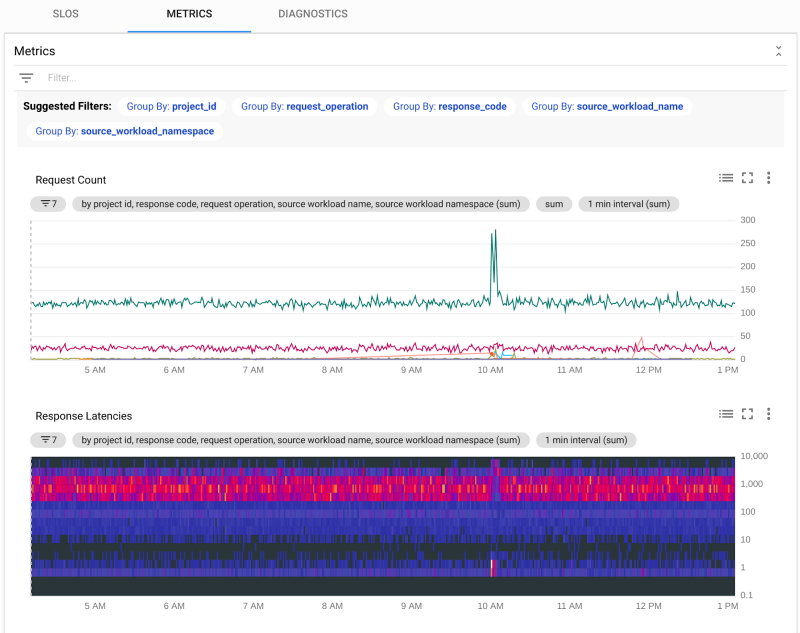
Service Dashboard: В какой-то момент вам нужно будет углубиться в сигналы службы. Возможно, вы получили оповещение SLO, и нет очевидной причины восходящего потока. Возможно, услуга связана с графиком обслуживания как возможная причина для оповещения SLO другого сервиса. Возможно, у вас есть жалоба клиента за пределами предупреждения SLO, которое вам нужно изучить. Или, может быть, вы хотите увидеть, как происходит развертывание новой версии кода.
Панель управления сервисов обеспечивает единый когерентный вывод всех сигналов для конкретной службы, причем все они привязаны к одному и тому же таймфрейму с одним элементом управления, предоставляя вам самый быстрый способ преодолеть проблему с вашим сервисом. Мониторинг сервиса позволяет вам глубоко погрузиться в поведение службы по всем сигналам, не отрываясь от разных продуктов, инструментов или веб-страниц для показателей, журналов и трасс. Панель управления дает вам представление о SLO на одной вкладке, показатели обслуживания (скорости транзакций, частоты ошибок и задержки) на второй вкладке, а также диагностику (трассировки, отчеты об ошибках и журналы) на третьей вкладке.
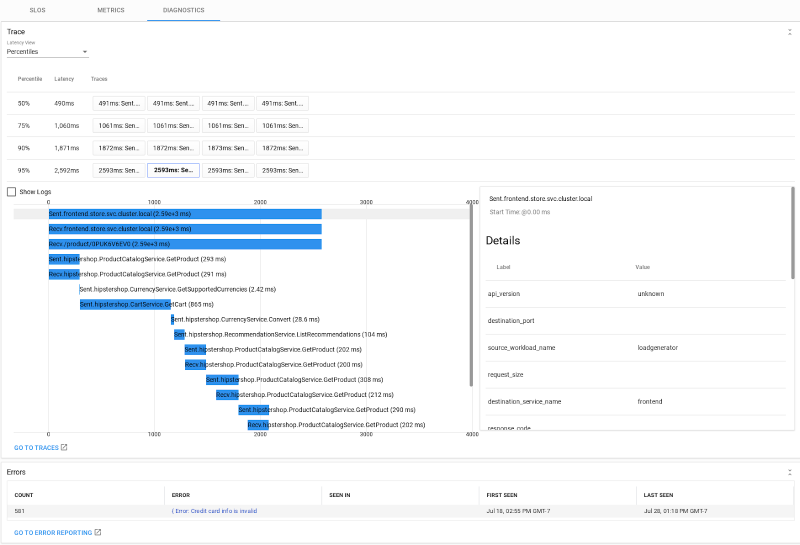
После того, как вы проверили отклонение бюджета на первой вкладке и изолированный аномальный трафик во второй вкладке, вы можете продолжить дальше на вкладке диагностики. Для проблем с производительностью вы можете развернуть длинные хвостовые следы, а оттуда легко попасть в Stackdriver Profiler, если ваше приложение приспособлено для этого. Для проблем с доступностью вы можете просматривать журналы и отчеты об ошибках, проверять трассировки стека и открывать отладчик Stackdriver, если приложение предназначено для этого.
Мониторинг служб Stackdriver дает вам совершенно новый способ просмотра архитектуры приложения, причины его поведения, ориентированного на клиента, и вникать в корень любых возникающих проблем. Он использует преимущества усовершенствования программного обеспечения в области инфраструктуры, которые Google отстаивает в мире с открытым исходным кодом, и использует трудно завоеванные знания наших команд SRE. Мы считаем, что это в корне преобразует опыт работы с операционными командами разработчиков облачных вычислений и микросервисов. Чтобы узнать больше, ознакомьтесь с презентацией и демонстрацией с Лабораториями Декарта на GCP. На прошлой неделе. Мы надеемся, что вы подпишетесь, чтобы попробовать и поделиться своими отзывами.
Большинство инструментов ИТ-операций занимают мало внимания в отношении ИТ-систем: они смотрят на вычисления, хранилища и сетевые показатели, чтобы выявить опыт работы с клиентами. Средства управления эффективностью приложений (APM), такие как системы трассировки, отладчики и профилировщики, рассматривают приложение с уровня кода, но упускают из виду базовую инфраструктуру. Иногда решение аналитики журналов может обеспечить клей между этими двумя слоями, но часто с большими усилиями и расходами.
У ИТ-операторов отсутствует экономичный и простой в использовании инструмент общего назначения для мониторинга поведения своих приложений, ориентированного на клиента. Трудно понять, как конечные пользователи испытывают ваше программное обеспечение, и сложно стандартизовать службы и приложения. Персонал Ops рискует выгорать из всех ложных предупреждений. Результатом всего этого является то, что среднее время-разрешение (MTTR) больше, чем необходимо, и удовлетворенность клиентов ниже желаемого. Ситуация усугубляется с помощью микросервисных архитектур, где само приложение разбито на множество мелких кусочков, что затрудняет понимание того, как все части подходят друг другу и где начать расследование, когда есть проблема.
Все это происходит с выпуском Stackdriver Service Monitoring. Мониторинг сервисов использует сервисную, «укомплектованную» инфраструктуру, поэтому вы можете отслеживать, как конечные пользователи воспринимают ваши системы, позволяя вам, когда это необходимо, перейти на уровень инфраструктуры. Первоначально мы поддерживаем эту функциональность для Google App Engine и сервисов Istio, работающих в Google Kubernetes Engine. С течением времени мы будем расширяться до большего количества платформ.
С помощью Stackdriver Service Monitoring вы получаете ответы на следующие вопросы:
- Каковы ваши услуги? Какую функциональность предоставляют эти услуги для внутренних и внешних клиентов?
- Каковы ваши обещания и обязательства относительно доступности и эффективности этих услуг, а также ваши услуги, связанные с ними?
- Что такое межсервисные зависимости для приложений на основе микросервисов? Как вы можете использовать эти знания для двойной проверки новых версий кода и проблем с сортировкой в случае ухудшения обслуживания?
- Можете ли вы посмотреть на все сигналы мониторинга для целостного сервиса, чтобы уменьшить MTTR?
Анатомия мониторинга службы стоп-приводов
Сервисный мониторинг состоит из трех частей: графика обслуживания, целей уровня обслуживания (SLO) и панелей мониторинга с несколькими сигналами. Вместе они дают вам список ваших услуг, визуально отображают зависимости между ними, позволяют устанавливать и оценивать возможности доступности и производительности, помогать вам устранять проблемы приложений, чтобы быстро найти основную причину и, наконец, помочь вам быстрее отлаживать сломанные услуги чем когда-либо. Давайте посмотрим на каждую часть по очереди.
Сервисный график: это представление о вашей инфраструктуре, относящееся к услугам. Он начинается с отображения верхнего уровня в реальном времени всех сервисов в сервисной сетке Istio и связей между ними. При выборе одной услуги отображаются графики с коэффициентами ошибок и метриками задержки. Двойной щелчок по сервису позволяет развернуть свою базовую инфраструктуру Kubernetes, обеспечивая длинную неуловимую связь между поведением приложения и инфраструктурой. Существует также ползунок времени, который позволяет вам видеть график в предыдущие моменты времени. Используя сервисный график, вы можете увидеть свою архитектуру приложения для справочных целей или для сортировки проблем. Вы можете изучить показатели поведения службы и определить, вызывает ли восходящий сервис проблемы с последующей службой. Наконец, вы можете сравнить график обслуживания в разные моменты времени, чтобы определить, было ли значительное архитектурное изменение прямо перед сообщением проблемы. Существует не более быстрый способ начать изучение и понимание сложных мультисервисных приложений.
SLO: внутренне в Google наша команда инженеров по надежности сайта (SRE) только предупреждает себя о проблемах, связанных с клиентами, и не во всех потенциальных причинах. Это лучше согласовывает их с интересами клиентов, снижает их трудность, освобождает их, чтобы делать надёжную инженерию с добавленной стоимостью и повышает удовлетворенность работой. Stackdriver Service Monitoring позволяет вам устанавливать, контролировать и предупреждать о SLO. Поскольку Istio и App Engine имеют укрупненный способ, мы точно знаем, что подсчет транзакций, количество ошибок и распределение задержек находятся между службами. Все, что вам нужно сделать, — установить целевые показатели доступности и производительности, и мы автоматически генерируем графики для индикаторов уровня обслуживания (SLI), соответствия вашим целям с течением времени и вашего оставшегося бюджета ошибок. Вы можете настроить максимально допустимую скорость снижения для бюджета ошибок; если эта ставка превышена, мы уведомляем вас и создаем инцидент, чтобы вы могли принять меры. Чтобы узнать больше о концепциях SLO, включая бюджет ошибок, мы рекомендуем вам прочитать главу SLO в книге SRE.
Service Dashboard: В какой-то момент вам нужно будет углубиться в сигналы службы. Возможно, вы получили оповещение SLO, и нет очевидной причины восходящего потока. Возможно, услуга связана с графиком обслуживания как возможная причина для оповещения SLO другого сервиса. Возможно, у вас есть жалоба клиента за пределами предупреждения SLO, которое вам нужно изучить. Или, может быть, вы хотите увидеть, как происходит развертывание новой версии кода.
Панель управления сервисов обеспечивает единый когерентный вывод всех сигналов для конкретной службы, причем все они привязаны к одному и тому же таймфрейму с одним элементом управления, предоставляя вам самый быстрый способ преодолеть проблему с вашим сервисом. Мониторинг сервиса позволяет вам глубоко погрузиться в поведение службы по всем сигналам, не отрываясь от разных продуктов, инструментов или веб-страниц для показателей, журналов и трасс. Панель управления дает вам представление о SLO на одной вкладке, показатели обслуживания (скорости транзакций, частоты ошибок и задержки) на второй вкладке, а также диагностику (трассировки, отчеты об ошибках и журналы) на третьей вкладке.
После того, как вы проверили отклонение бюджета на первой вкладке и изолированный аномальный трафик во второй вкладке, вы можете продолжить дальше на вкладке диагностики. Для проблем с производительностью вы можете развернуть длинные хвостовые следы, а оттуда легко попасть в Stackdriver Profiler, если ваше приложение приспособлено для этого. Для проблем с доступностью вы можете просматривать журналы и отчеты об ошибках, проверять трассировки стека и открывать отладчик Stackdriver, если приложение предназначено для этого.
Мониторинг служб Stackdriver дает вам совершенно новый способ просмотра архитектуры приложения, причины его поведения, ориентированного на клиента, и вникать в корень любых возникающих проблем. Он использует преимущества усовершенствования программного обеспечения в области инфраструктуры, которые Google отстаивает в мире с открытым исходным кодом, и использует трудно завоеванные знания наших команд SRE. Мы считаем, что это в корне преобразует опыт работы с операционными командами разработчиков облачных вычислений и микросервисов. Чтобы узнать больше, ознакомьтесь с презентацией и демонстрацией с Лабораториями Декарта на GCP. На прошлой неделе. Мы надеемся, что вы подпишетесь, чтобы попробовать и поделиться своими отзывами.
0 комментариев
Вставка изображения
Оставить комментарий