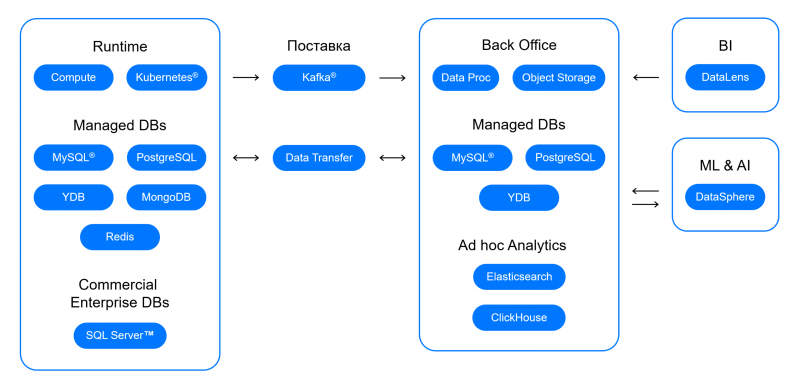
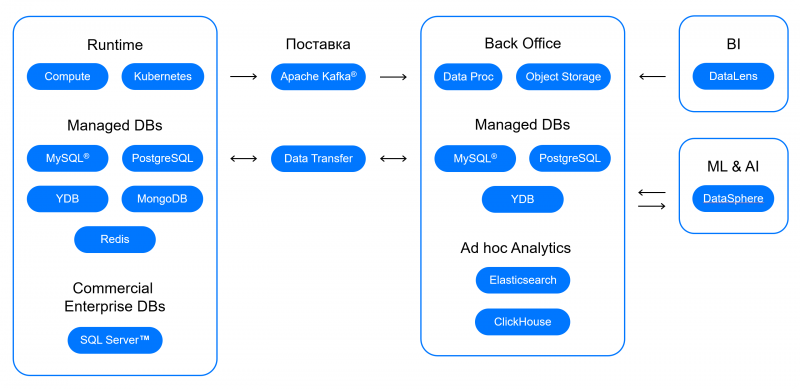
Управляемые базы данных. MongoDB

Компания 10gen начала разрабатывать MongoDB в середине 2007 года в рамках проекта «программная платформа как услуга». Они хотели создать сервер приложений и базу данных, которые служили бы хостингом для веб-приложений, при этом обеспечивая автоматическое масштабирование и управление программной и аппаратной инфраструктурой. В середине 2000-х этот подход не заинтересовал рынок, но зато новая технология баз данных стала очень популярной. Сейчас это один из классических примеров NoSQL-систем.
NoSQL для неструктурированных данных
Чтобы создавать большие масштабируемые системы, разработчики десятилетиями использовали базы данных SQL. Но со временем появилась потребность хранить данные без определенной структуры. Работать с ними в двумерной таблице просто не получалось. Тогда решили использовать нереляционные базы данных, которые назвали NoSQL. Дополнительным преимуществом стало то, что множество типов данных, для моделирования которых раньше применялся реляционный подход, гораздо удобнее представлять и использовать в подходе с NoSQL.
NoSQL позволяет оперировать различными типами данных, реализуя при этом полнотекстовый поиск по базе, в том числе без задания «схемы» данных. Такие базы данных высокодоступны и отказоустойчивы. Между записями нет связи, поэтому данные легко делить на независимые части и шардировать: группировать в секции и размещать на разных, физически и логически независимых серверах базы данных. Так реализуется горизонтальное масштабирование. Этот подход принципиально отличается от вертикального масштабирования. При росте нагрузки и объема данных оно предусматривает наращивание вычислительных возможностей одного сервера баз данных, у которого есть объективные физические пределы: максимальное количество поддерживаемых CPU, объем памяти и т. д.
Еще одна важная особенность NoSQL — множество типов баз данных, разработанных и оптимизированных для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа:
- Document Store: MongoDB, CouchDB, RethinkDB.
- Key-Value Store: DynamoDB.
- Column Store: Cassandra.
- Data-Structures: Redis.
NoSQL больше всего подходит для приложений, которые должны быстро и с низкой задержкой обрабатывать большой объем данных с разной структурой. Проще всего представить сравнение NoSQL и SQL в виде таблицы:
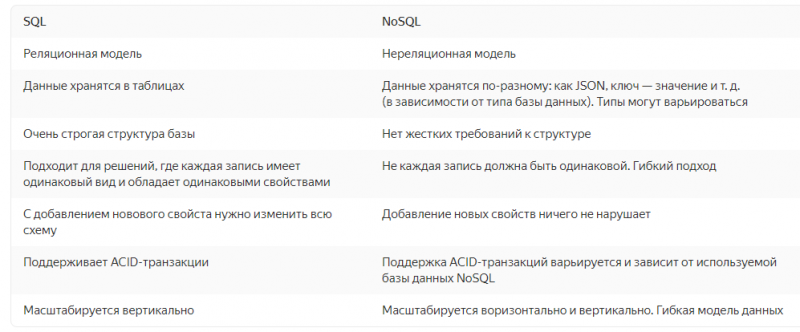
Более того, многие современные базы данных начали объединять концепции SQL и NoSQL. PostgreSQL, например, по-прежнему не умеет горизонтально масштабироваться средствами самой базы данных, но теперь поддерживает не только хранение, но и индексирование данных JSON, как и MongoDB.
MongoDB — база данных для документов
MongoDB — это ориентированная на документы база данных NoSQL с открытым исходным кодом, которая использует для хранения структуру JSON. Модель данных MongoDB позволяет представлять иерархические отношения, проще хранить массивы и другие более сложные структуры.
Вместо таблиц и строк, как в реляционных базах данных, здесь коллекции и документы, которые состоят из пар «ключ — значение»:
{
"someKey": "value",
"best": {
"foo": "baz"
}
}Коллекции содержат наборы документов и функции, которые эквивалентны таблицам реляционной базы данных. Каждый документ может отличаться друг от друга размером, содержанием и количеством полей. В документах MongoDB можно хранить даже бинарные данные: изображения, mp3 и т. д.
Структура документа похожа на то, как разработчики конструируют классы и объекты на языках программирования, а у строк (или документов, вызываемых в MongoDB) необязательно должна быть заранее определенная схема. Можно создавать поля на лету, а также настроить валидацию JSON Schema. Драйверы MongoDB уже из коробки умеют десериализовывать данные из базы в полноценные объекты. Для разработчика это делается прозрачно, а значит, требуется писать меньше кода и возникает меньше багов.
В целом от других документно-ориентированных баз данных NoSQL MongoDB отличается следующими возможностями:
- Хранение почти любых данных: структурированных, частично структурированных или даже полиморфных (различных типов).
- Хранение информации о модели в одном документе.
- Изменение «схемы» базы данных на лету.
- Поддержка стандартных типов запросов: сопоставление (==), сравнение (<,>) или регулярное выражение.
- Поддержка балансировки нагрузки с автоматическим перемещением данных между шардами.
- Автоматическое переключение между серверами при сбое.
- Доступность функции реляционной базы данных (например, индексирование).
На рынке также доступно множество инструментов управления и мониторинга MongoDB. Начиная с бесплатных приложений, которые можно установить только на локальный сервер с базой данных, и заканчивая профессиональными сервисами, которые позволяют управлять NoSQL СУБД в инфраструктурах ЦОД и облачных провайдеров — у нас за это отвечает Yandex Managed Service for MongoDB.
Где применяют MongoDB

База данных NoSQL подходит для большого объема полуструктурированных и неструктурированных данных. Что, впрочем, не мешает ей прекрасно справляться и с обработкой строго типизированной информации, для которой обычно используют SQL-базы. Выбирайте СУБД, учитывая специфику задачи. MongoDB отличается высокой доступностью, горизонтальной масштабируемостью, быстрой работой с данными, возможностями аналитики в реальном времени, высокоскоростным журналированием, кешированием данных и кейсов. Вот для чего MongoDB отлично подходит:
- электронная коммерция, каталоги товаров, соцсети, новостные форумы и другие похожие сценарии, где много контента, в том числе видео и изображений;
- новый проект или стартап, если неизвестна итоговая структура данных или же вы точно знаете, что у вас будут слабо связанные данные без четкой схемы хранения;
- геоаналитика (обработка геопространственных данных — данных на основе местоположения);
- хранение данных с датчиков и устройств, собранных с решений интернета вещей, в том числе промышленных;
- работа с большими данными в машинном обучении;
- исследования в ритейле и других отраслях.
В Yandex.Cloud пользователи применяют сервис управляемой MongoDB для различных задач. Например, Blumenkraft создает event-sourcing архитектуру приложений, CarTaxi хранит и изучает информацию о перемещении водителей, Яндекс.Толока использует СУБД для аналитики (об этом мы рассказывали на митапе о MongoDB).
Сервис управляемой MongoDB в Yandex.Cloud
Платформа Yandex.Cloud — эксклюзивный партнер MongoDB в России. Это означает, что в облаке вы получите все официальные релизы СУБД, на 100% совместимые и протестированные. Благодаря Managed Service for MongoDB установка и первоначальная настройка кластера происходит в несколько кликов. Далее вы просто работаете с базой данных, а сервис создает резервные копии, устанавливает обновления СУБД и операционной системы, а также берет на себя много другой рутинной, но обязательной работы. При этом минорные обновления приходят автоматически, а крупные вы можете контролировать сами, чтобы не нарушить работу своих сервисов в облаке.
Возможности Yandex Managed Service for MongoDB, которые обеспечивают отказоустойчивую и эффективную работу базы данных:
- Развертывание кластера за несколько минут.
- Репликация и высокая доступность. Если в кластере больше одного активного хоста — среди них автоматически выбирается первичная реплика, обрабатывающая запросы на запись.
- Поддержка шардирования. Вы можете включить шардирование, а также добавлять и настраивать шарды, чтобы повысить производительность кластера.
- Инструменты мониторинга. Вы можете запросить детальную информацию о каждом кластере Managed Service for MongoDB.
- Автоматическое и ручное резервное копирование.
- Восстановление на произвольную точку времени. Managed Service for MongoDB позволяет восстановить состояние кластера на любой момент, начиная с самой старой полной резервной копии и заканчивая настоящим временем.
- Горизонтальное масштабирование по клику. Если нагрузка на кластер вырастет, вы за несколько минут добавите серверы в кластер или увеличите их мощность.
- Безопасность данных соответствует требованиями 152-ФЗ, GDPR и индустриальных стандартов ISO. Все соединения с СУБД шифруются при помощи протокола TLS, а резервные копии содержимого баз — технологией GPG.
MongoDB используют GitHub, SourceForge, Foursquare, Bitly, About.me, MTV, CNN, New York Times, Forbes, Disney, EA и многие другие компании.
Попробовать Yandex Managed Service for MongoDB → cloud.yandex.ru/services/managed-mongodb