Сервис Yandex Managed Service for Apache Kafka становится общедоступным
Мы открыли сервис Yandex Managed Service for Apache Kafka для тестирования по заявкам ещё летом, а на конференции Yandex Scale в сентябре предоставили всем пользователям возможность пользоваться сервисом бесплатно в рамках Preview.
Со 2 ноября сервис переходит в общий доступ. Это значит, что для него теперь действуют соглашение об уровне обслуживания (SLA) и правила тарификации.
Apache Kafka — это распределенная система обмена сообщениями с возможностью горизонтального масштабирования. С помощью Managed Service for Apache Kafka и Data Proc (компонент Apache Spark) вы можете настроить потоковую обработку данных для своего приложения. Управляемые сервисы помогут сэкономить время на создание, обслуживание и управление кластерами, а настроенные в сервисах репликация и система автоматического восстановления будут поддерживать кластеры в рабочем состоянии. Об этом подробно рассказал руководитель разработки сервисов Data Proc и Managed Service for Apache Kafka Михаил Епихин в докладе про сервисы для построения аналитической платформы.
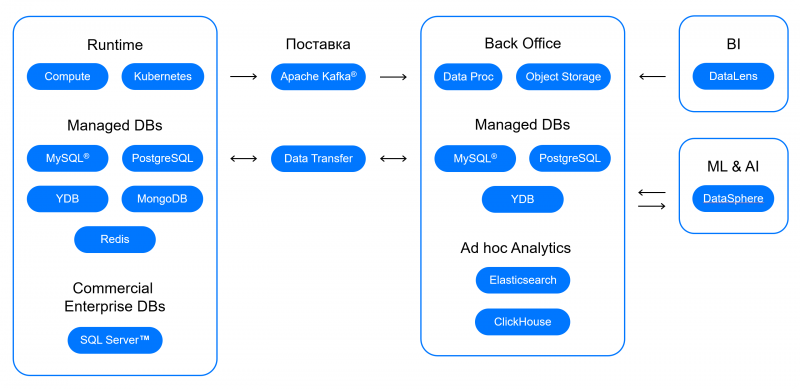
Также с помощью Apache Kafka можно поставлять данные напрямую в базу данных ClickHouse без дополнительной разработки. Подключив сервис Yandex Datalens, вы сможете настроить систему аналитики: ClickHouse отлично справляется с обработкой запросов к большим объёмам данных, а DataLens позволит эти данные визуализировать и построить отчёты. Подробнее об этом сценарии мы рассказали на вебинаре про архитектуру обработки больших данных.
Подробнее о том, как работает сервис, вы можете узнать из:
Со 2 ноября сервис переходит в общий доступ. Это значит, что для него теперь действуют соглашение об уровне обслуживания (SLA) и правила тарификации.
Apache Kafka — это распределенная система обмена сообщениями с возможностью горизонтального масштабирования. С помощью Managed Service for Apache Kafka и Data Proc (компонент Apache Spark) вы можете настроить потоковую обработку данных для своего приложения. Управляемые сервисы помогут сэкономить время на создание, обслуживание и управление кластерами, а настроенные в сервисах репликация и система автоматического восстановления будут поддерживать кластеры в рабочем состоянии. Об этом подробно рассказал руководитель разработки сервисов Data Proc и Managed Service for Apache Kafka Михаил Епихин в докладе про сервисы для построения аналитической платформы.
Также с помощью Apache Kafka можно поставлять данные напрямую в базу данных ClickHouse без дополнительной разработки. Подключив сервис Yandex Datalens, вы сможете настроить систему аналитики: ClickHouse отлично справляется с обработкой запросов к большим объёмам данных, а DataLens позволит эти данные визуализировать и построить отчёты. Подробнее об этом сценарии мы рассказали на вебинаре про архитектуру обработки больших данных.
Подробнее о том, как работает сервис, вы можете узнать из:
0 комментариев
Вставка изображения
Оставить комментарий