Введение DepC: платформа OVH для вычисления QoS

В OVH нашей первой миссией в качестве поставщика облачных услуг является предоставление продуктов с высоким качеством обслуживания (QoS). Наши клиенты ожидают, что наши решения будут иметь безупречное качество обслуживания, будь то выделенные серверы, облачные серверы или хостинговые веб-сайты. И это именно то, что наши команды стремятся предлагать вам ежедневно!
Это сложная миссия. Во многих случаях качество обслуживания может зависеть от нашей инфраструктуры, а также от предполагаемого использования решения. И выявление происхождения любой деградации может потребовать продвинутых диагнозов.
Итак, как мы можем количественно оценить это качество обслуживания? Как мы понимаем качество каждого продукта, каждый день, как можно точнее?
Первым шагом было найти существующие инструменты, но мы быстро поняли, что ни одно решение не отвечает нашим потребностям. Именно из этого наблюдения мы решили разработать собственное решение для вычисления QoS: DepC. Первоначально созданная для команды WebHosting, эта платформа быстро распространилась по всему OVH. В настоящее время он используется внутри десятков команд.
Сначала мы создали DepC для расчета QoS нашей инфраструктуры. Но за эти годы мы обнаружили, что этот инструмент можно использовать для расчета QoS любой сложной системы, включая как инфраструктуры, так и сервисы.
Чтобы быть максимально прозрачными, мы также решили объяснить и обосновать наши методы расчета. Вот почему мы решили сделать DepC открытым исходным кодом. Вы можете найти это на Github.
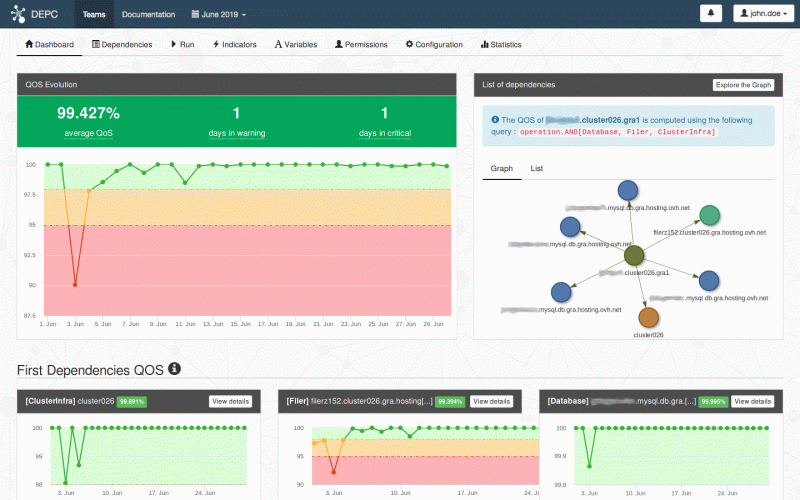
Прежде чем погрузиться в код, давайте взглянем на работу DepC, а также на то, как мы используем ее для расчета качества наших продуктов.

Что такое QoS?
Прежде всего, важно определить точную природу того, что мы хотим вычислить. QoS описывает состояние системы. Это может быть услуга (например, поддержка клиентов, время ожидания в кассе…), эксплуатация продукта (например, жизненный цикл посудомоечной машины) или сложные системы (например, инфраструктура веб-сайта).
Это состояние здоровья очень субъективно и будет варьироваться в каждом конкретном случае, но, как правило, оно будет основываться на вероятности получения пользователем пользы от услуги в хороших условиях. В нашем случае хорошие условия означают как доступность услуги (то есть инфраструктура работает), так и ее общее состояние (то есть инфраструктура реагирует правильно).
QoS выражается в процентах, начиная с 100%, когда сервис полностью достигнут, а затем постепенно уменьшается в случае сбоя. Этот процент должен быть связан с периодом: месяц, день, время и т. Д. Таким образом, услуга может иметь 99,995% QoS в текущий день, тогда как днем ранее она составляла 100%.
Другие концепции также важны:
- SLA (Соглашение об уровне обслуживания): не следует путать с QoS, это контракт между заказчиком и поставщиком, указывающий ожидаемое качество обслуживания. Этот контракт может включать штрафы, назначенные клиенту в случае невыполнения поставленных задач.
- SLO (Цель уровня обслуживания): это относится к цели, которую поставщик услуг хочет достичь с точки зрения QoS.
- SLI (индикатор уровня обслуживания): это мера (время ответа на пинг, код состояния HTTP, задержка в сети…), используемая для оценки качества услуги. SLI лежат в основе DepC, поскольку они позволяют нам преобразовывать необработанные данные в QoS.
Цель достижения
DepC изначально был создан для команды WebHosting. С 5 миллионами веб-сайтов, распределенных по более чем 14 000 серверов, инфраструктура, необходимая для работы веб-сайтов (описанная в этой статье), а также постоянные изменения затрудняли расчет качества обслуживания в режиме реального времени для каждого из наших клиентов., Кроме того, для выявления проблемы в прошлом нам также необходимо было знать, как реконструировать QoS, чтобы отражать состояние инфраструктуры в то время.
Наша цель заключалась в том, чтобы ежедневно показывать эволюцию QoS всем клиентам и выявлять причины любого снижения качества обслуживания.
Но как мы можем измерить состояние здоровья каждого из сайтов наших клиентов? Наша первая идея состояла в том, чтобы запросить их один за другим, проанализировать HTTP-код ответа и на основе этого определить состояние сайта. К сожалению, этот сценарий оказался сложным для реализации по нескольким причинам:
- Команда WebHosting управляет миллионами веб-сайтов, поэтому масштабирование было бы очень сложным.
- Мы не единственные гаранты правильного функционирования сайтов. Это также зависит от клиента, который может (намеренно или нет) генерировать ошибки, которые будут интерпретироваться как ложные срабатывания.
- Даже если бы мы решили предыдущие трудности и можно было рассчитать QoS веб-сайтов, было бы невозможно определить основные причины в случае сбоя.
График зависимостей
Основываясь на этом наблюдении, мы решили обойти эту проблему: если невозможно напрямую рассчитать QoS сайтов наших клиентов, мы будем рассчитывать его косвенно, исходя из их зависимостей.
Чтобы понять это, мы должны помнить, как работает наша инфраструктура. Не вдаваясь в подробности, помните, что каждый веб-сайт работает через набор серверов, взаимодействующих друг с другом. Например, вот две зависимости, которые вы наследуете при заказе решения для веб-хостинга у OVH:
- Исходный код ваших сайтов размещен на серверах хранения (так называемый filerz).
- Базы данных, используемые сайтом, также размещаются на серверах баз данных.
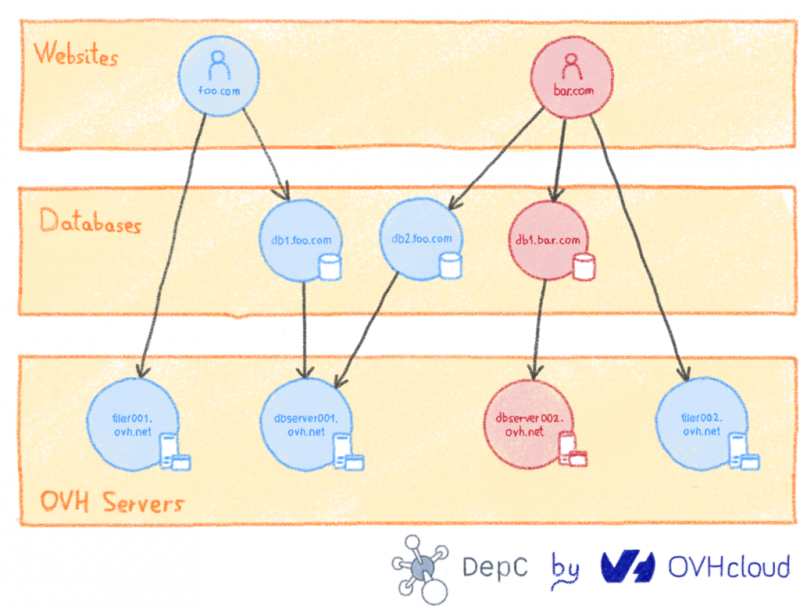
Диаграмма выше показывает, что неисправность сервера базы данных автоматически влияет на все базы данных, которые он содержит, и эффектом домино на все веб-сайты, использующие эти базы данных.
Этот пример намеренно упрощен, поскольку зависимости наших клиентов, конечно, гораздо более многочисленны (веб-серверы, почтовые серверы, балансировщики нагрузки и т. Д.), Даже без учета всех мер безопасности, введенных в действие, чтобы уменьшить эти риски отказа.
Для тех, кто прошел некоторые компьютерные курсы, эти зависимости очень похожи на график. Поэтому мы решили использовать графо-ориентированную базу данных: Neo4j. В дополнение к очень хорошей производительности, язык запросов, Cypher и платформа разработки являются реальными преимуществами.
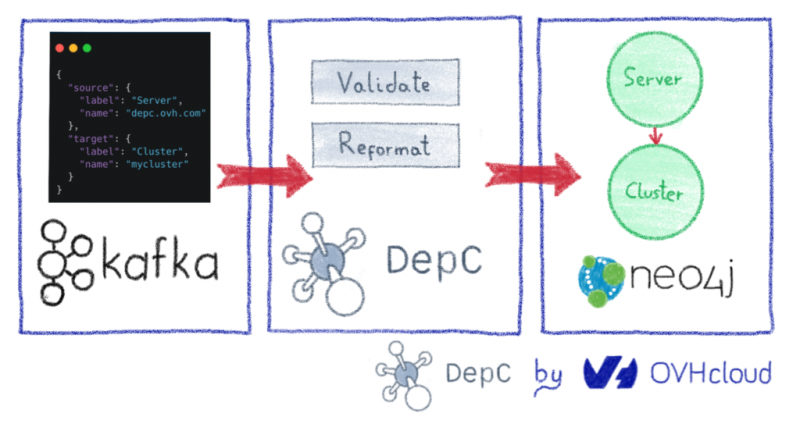
Однако создание дерева зависимостей (узлов и их отношений) не требует от нас знания Neo4j, потому что мы разработали демон, который позволяет нам преобразовывать сообщения JSON в узлы на графике. DepC предоставляет API, так что каждая команда может добавлять новые элементы в свое дерево зависимостей, не изучая Cypher.
Принцип таков:
- Пользователи DepC отправляют JSON-сообщение в потоке данных Kafka. В этом сообщении указываются новые создаваемые узлы, а также их взаимосвязь (например, узел веб-сайта, подключенный к файлу анода). Все узлы и отношения содержат временную информацию, которая помогает поддерживать изменения инфраструктуры с течением времени.
- DepC анализирует эти сообщения и затем обновляет граф зависимостей в режиме реального времени.
ovh.github.io/depc/guides/kafka.html
Расчет QoS
Платформа DepC предлагает API для хранения и запроса дерева зависимостей. Это может показаться тривиальным, но следить за инфраструктурой с течением времени уже является сложной задачей. Это настолько мощно, что некоторые команды используют только эту часть платформы, используя DepC как эквивалент своей CMDB (инвентарь своего технического парка).
Но ценность DepC идет дальше. Большинство наших пользователей рассчитывают качество обслуживания своего узла, но DepC предлагает два метода для разных случаев:
- Узел представляет элемент, контролируемый одним или несколькими зондами.
- Целевой узел не является контролируемым элементом
Контролируемые узлы
Контролируемый узел может быть, например, сервером, службой или частью сетевого оборудования. Его основной характеристикой является то, что зонд отправляет измерения в базу данных временных рядов.
Здесь мы находим концепцию SLI, которую мы видели выше: DepC анализирует необработанные данные, отправленные датчиками, чтобы преобразовать их в QoS.
Принцип очень прост:
- Пользователи объявляют индикаторы в DepC, определяя запрос для получения данных из базы данных временных рядов, а также порог, который подразумевает снижение QoS для этого узла.
- DepC запускает этот запрос для всех узлов, выбранных пользователем, затем анализируется каждый результат, чтобы рассчитать QoS, как только пороговое значение будет превышено. Затем мы получаем QoS данного узла. Обратите внимание, что этот процесс выполняется каждую ночь благодаря инструменту планирования задач Airflow.
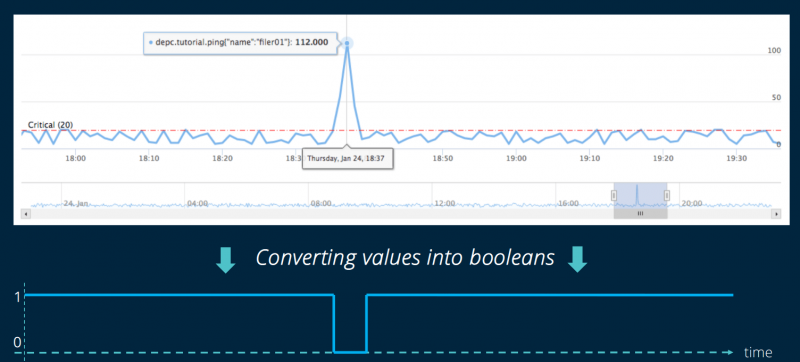
Расчет тогда очень прост: «истинное» значение увеличит QoS, а «ложное» значение уменьшит его. Например, из 100 баллов, при этом 95 баллов ниже порогового значения (это так), QoS будет составлять 95% (DepC начинает этот расчет каждую ночь; количество точек данных на самом деле намного выше).
Обратите внимание, что для завершения этой части DepC в настоящее время поддерживает базы данных временных рядов OpenTSDB и Warp10. Другие базы данных временных рядов будут добавлены в ближайшее время (InfluxDB, Prometheus ...).
Неконтролируемые узлы
Некоторые узлы представляют не контролируемые зондом элементы. В таких случаях их QoS будет рассчитываться на основе QoS их родителей в дереве зависимостей.
Представьте, например, узел, представляющий «клиента» и связанный с несколькими отслеживаемыми узлами типа «сервер». У нас нет данных для анализа для этого клиента. С другой стороны, для «серверных» узлов мы можем рассчитать их QoS благодаря отслеживаемым узлам. Затем мы агрегируем эти показатели QoS, чтобы получить данные «клиентского» узла.
Для достижения этого DepC вычисляет QoS отслеживаемых узлов, получая, таким образом, список логических значений. Затем булева операция И применяется между этими различными списками (по зависимости), чтобы получить уникальный список булевых значений. Этот список затем используется для расчета QoS нашего неконтролируемого узла.
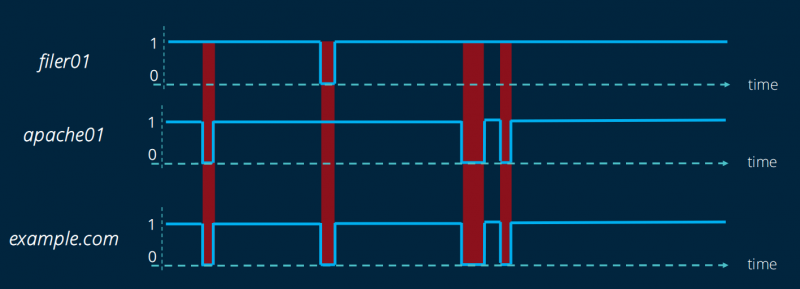
Затем вычисление выполняется так же, как и для отслеживаемых узлов, с учетом количества «истинных» вхождений по отношению к общему количеству точек.
ovh.github.io/depc/guides/queries.html#operation-based-qos
Для этого примера мы использовали только логический оператор. Однако DepC предоставляет несколько типов логических операций для разных приложений:
- И: все зависимости должны работать для предоставления услуги.
- ИЛИ: одной зависимости достаточно для оказания услуги.
- СООТНОШЕНИЕ (N): необходимо, чтобы N% зависимостей работали для предоставления услуги.
- ATLEAST (N): независимо от количества зависимостей, услуга оказывается, если функционирует хотя бы N зависимостей.
Заключение
DepC уже используется десятками команд в OVH. Выбранная архитектура позволяет нам предлагать визуализацию QoS через встроенный веб-интерфейс, с самим DepC или депортировать дисплей в Grafana.
Платформа отлично выполняет свою первоначальную цель — предоставлять отчеты: теперь мы можем визуализировать качество обслуживания, которое мы предлагаем нашим клиентам, изо дня в день, а также увеличивать дерево зависимостей, чтобы обнаружить первопричины любого возможного сбоя.
Наша дорожная карта на следующие несколько месяцев очень занята: всегда рассчитывать больше QoS, вычислять QoS этих узлов в соответствии с оценками других команд и отображать все это простым и понятным для наших клиентов образом…
Наша цель — стать стандартным решением для расчета QoS в OVH. Инструмент находится в производстве уже несколько месяцев, и мы получаем тысячи новых узлов в день. Наша база данных в настоящее время содержит более 10 миллионов, и это только начало.
И, конечно, если вы хотите протестировать или развернуть DepC дома, не стесняйтесь. Это открытый исходный код, и мы останемся в вашем распоряжении, если у вас есть вопросы или идеи по улучшению!
Github: github.com/ovh/depc
Documentation: ovh.github.io/depc/
Presentation FOSDEM 2019 (EN): fosdem.org/2019/schedule/event/python_compute_qos_of_your_infrastructure/
Presentation PyconFR 2018 (FR): pyvideo.org/pycon-fr-2018/calculer-la-qos-de-vos-infrastructures-avec-asyncio.html
















