Самый длинный простой за нашу историю
Коротко: 17 июня около часа ночи мы потеряли два ввода питания от города из-за аварии на подстанции, затем — один из дизелей, что вызвало «мигание» питания в подземном дата-центре. Итог инцидента — простой около 12 часов примерно 7–10 % машин одного из 14 наших ЦОДов.
Это просто дикая цепочка событий.

Это патрубок дизеля, перевязанный бинтом из админской аптечки. Сейчас расскажу, какую роль он тут сыграл.
Итак, мы потеряли оба городских ввода — всё как в худших домах Парижа. Как мы уже потом узнаем, вроде бы авария была на трансформаторе 110 кВт: при перераспределении мощностей с первого произошло замыкание второго. За полтора года это уже третий раз, когда пропадают оба луча, и вот тут я рассказывал, как мы почти сутки стояли на дизеле. Для клиентов это прошло незаметно (кроме той стойки, где при мигании света сгорел ИБП: там был простой на перезагрузку).
Штатно сработали ИБП, автоматически завелись дизель-генераторы, ЦОД продолжил работу. У нас общая энергосеть с соседним ЦОДом всё в том же подземном бомбоубежище. Общее потребление — 0,5 МВт, дизелей — на 1,05 МВт.
Через два часа, около 3:30 ночи, лопнул патрубок дизеля 0,5 МВт, отчего он внезапно перестал работать. Админы убежища переключили мощности на дизели 2 х 100 КВт и 2 х 200 КВт. В момент переключения нагрузка снова легла на ИБП, а за два часа они не успели восстановиться, и часть оборудования выключилась.
Это запустило целую цепочку последствий, потому что при этом выключении погорела одна из плат коммутатора, обеспечивавшего доступ в нашу сеть управления ЦОДом, то есть все удалённые доступы.
На площадке остались два админа, которым нужно было включить вручную коммутаторы и стойки, починить дизель и понять, что вообще происходит.
Дисклеймер: мы ещё не до конца разобрались с логами и причинно-следственными связями, но сейчас я пишу по горячим следам. Возможно, дальше выяснятся ещё интересные детали. Сейчас мы сосредоточились в основном не на расследовании инцидента, а на устранении последствий. Детальный разбор будет позже.
Что было с городскими вводами
Они пропали. Авария коснулась всего микрорайона. Мы относимся к важным потребителям электроэнергии, поэтому восстановление наших мощностей — первый приоритет для города. У нас не было городского ввода примерно с часа ночи до обеда, около 10 дали первый луч, через пару часов — второй.
Как можно видеть по заявкам в районе, жилые дома восстанавливали позже, то есть устраняли аварию максимально быстро для нас.
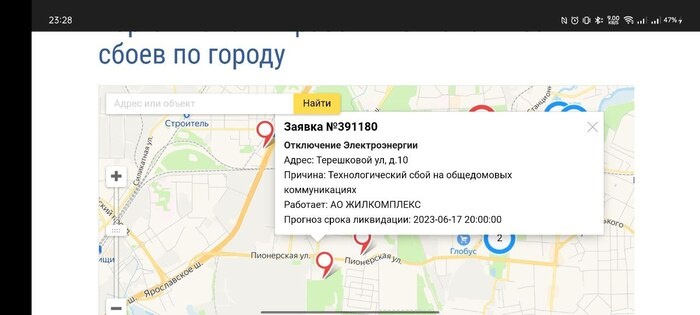
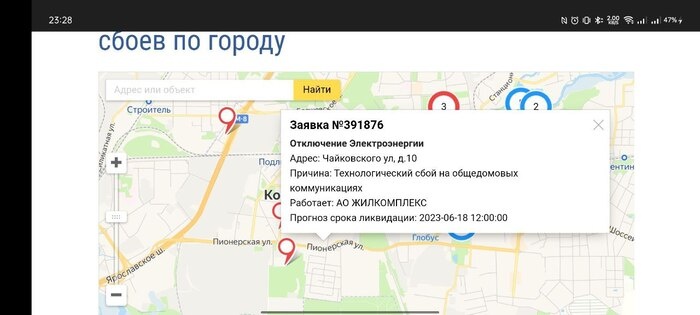
Почему только два админа
Ночь с субботы на воскресенье, особо охраняемая территория. В течение двух часов с начала инцидента всё идёт относительно предсказуемо, и помощь не нужна. Админы работают штатно. Примерно в 3:30 становится понятно, что нужно высылать подкрепление, но в этот момент уже:
Коммутатор защищённого сегмента сети вышел из строя.
Админы разбираются с дизелями и пытаются включить оборудование, то есть ходят от стойки к стойке и определяют, что случилось с каждой машиной.
Четыре других дизеля перегреваются и собираются отключиться.
Самое печальное — коммутатор защищённого сегмента, который включился, но работал неправильно. Это сегмент, в котором стоит DDoS-защита, то есть через него подключено около 7 % IP-адресов ЦОДа. Коммутатор зарезервирован по принципу HOT SWAP, то есть точно такой же лежит в коробке в шкафу в админской. Мы не думали строить кластер из двух коммутаторов, потому что не похоже, что DDoS-защита относится к критичным сегментам: при выходе её из строя примерно на 5–20 минут (время физической замены коммутатора) возможны DDoS.
То есть центральный коммутатор у нас нормально в кластере, а один из листов, относительно небольшая и относительно нетребовательная к непрерывности подсеть, на хотсвапе. Это была ошибка, и здесь мы здорово облажались.
Во-первых, оказывается, что тяжело менять коммутатор, когда ты держишь руками патрубок дизеля. Кроме физической замены, там нужно импортировать правила и ACL.
Во-вторых, на то, чтобы понять, что с ним что-то не так, тоже ушло время. Он не сгорел полностью, а включился и вроде бы начал работать. После его включения полетела часть ACL, и он отрезал нам управляющие сервера от сети.
В этот момент около 3:30 мы остались без сервисдеска, мониторинга, корпоративного мессенджера и одной из реплик сайта. Мессенджер тут же деградировал до «Телеграма», веб-сервер сайта автоматически поднялся в другом ЦОДе, а вот от мониторинга и сервисдеска такой подставы мы не ждали.
На мониторинг, в частности, было завязано определение оставшегося свободного места в ЦОДах, а оставшееся свободное место в ЦОДе определяет возможность создавать в нём новую виртуальную машину.
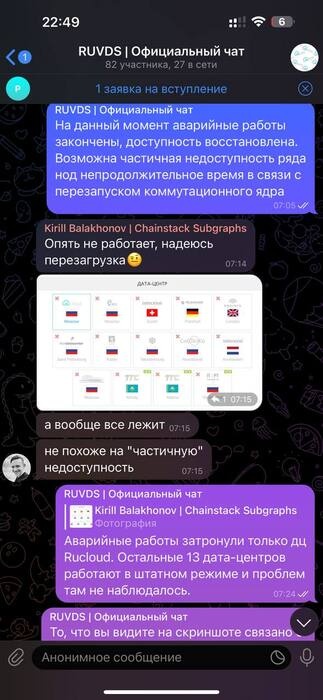
Это означало, что автоматика не видит свободного места, потому что источник данных для панели управления находился именно в глючившем защищённом сегменте. А потому система не даёт возможности создать новые ВМ в каждом из ЦОДов сети.
Выглядело это как крестик на создание ВМ на каждом из ЦОДов нашей сети, что начало вызывать панику в чате клиентов хостинга:
Это уже семь утра, когда существенная часть клиентов проснулась. До семи утра было ещё два отключения питания и перехода на уже истощённые ИБП. Перегрелся и начал нестабильно работать один из малых дизелей, а большой ещё не успели перебинтовать. И вообще, админы не очень хорошо ремонтируют дизели: это немного не их профиль работы.
Соответственно, клиенты пытались перенести свои ВМ в другие ЦОДы по миру, но из-за сбоя мониторинга не могли этого сделать: система не давала создать новые ВМ.
Начиная с шести утра мы пытались ответить клиентам, что происходит, но сами не до конца понимали масштаб проблемы из-за отвалившегося мониторинга.
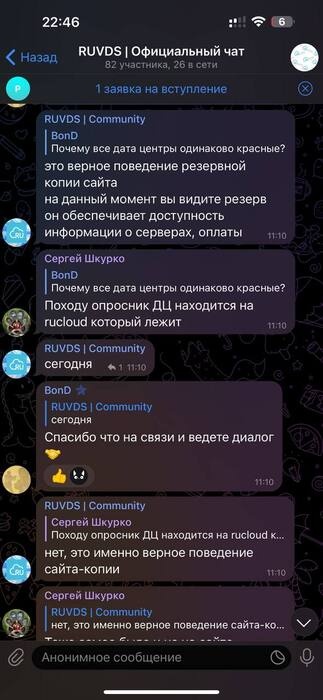
Админы были отрезаны от мира
Я неслучайно сказал, что это ночь с субботы на воскресенье на особо охраняемой территории. Дело в том, что после начала всем известных событий территория стала просто параноидально охраняемой.
Среди всего прочего в рамках общей параноизации нам отозвали все постоянные пропуска и заменили их на систему одноразовых пропусков персонала посменно. То есть около 3:40 ночи, когда уже стало понятно, что в ЦОДе не помешают лишние руки, никого отправить туда мы не могли, потому что люди встали бы на проходной.
Бюро пропусков по ночам не работает, по воскресеньям — тоже.
Это значит, что мы не можем отправить ещё админов и не можем отправить дизель. Дизель на 0,5 МВт у нас под рукой был после прошлого инцидента, и мы подтащили его к территории около девяти утра, но попасть внутрь не могли.
Охрана понимала всю серьёзность ситуации (насколько могла) и очень хотела помочь, но ровно в рамках своих полномочий: им нужно было разбудить своего начальника, чтобы он разрешил нештатную ситуацию. Попасть на территорию получилось только около 13:00.
До этого момента в ЦОДе было две пары рук.
До кучи около семи часов дышать в админской стало довольно тяжело: из-за погоды и перепада давления при открытии гермозоны (вентиляция работала только в вычислительном сегменте) внутрь засасывало выхлоп дизелей с улицы, который в обычное время просто улетал бы в окружающее пространство.
Админы разрывались между попытками ремонта дизеля, жонглированием мощностями, включением стоек и сетевого оборудования и попытками понять, что происходит с защищённым сегментом. Плюс время от времени им было нужно подниматься на воздух, чтобы не разболелась голова.
Восстановление
Когда приехал резервный дизель, всё встало на свои места.
Мы восстановили питание и более-менее последовательно разобрались, что происходит. Стало понятно, что с коммутатором, поменяли его, подняли защищённый сегмент. Там подцепился мониторинг, который нарисовал нам всю картину ночи. В этот же момент на нас упали все тикеты, которые клиенты хостинга поставили за ночь, потому что заработала очередь.

Последние сервера поднялись около 16 часов: это когда мы подключили в бой тот самый защищённый сегмент, стоявший за частично погоревшим коммутатором.
Клиенты, естественно, были не очень довольны:
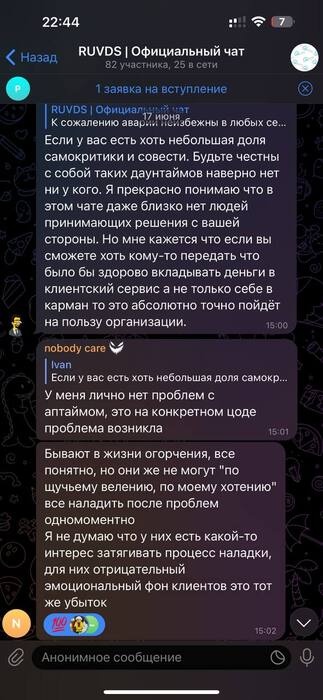
Интересно, что больше всего тикетов с паникой было у пользователей наиболее экономичных тарифов. То есть те, у кого был действительно критичный проект, развернули его на нескольких геоплощадках. Бывалые админы достаточно спокойно наблюдали за паникой людей в чате:


Общий итог такой:
Сколько/чего выключилось:
Разбор ошибок
Из того, на что мы могли повлиять:
Я пережил несколько очень неприятных моментов этой ночью и понял, что нам нужен публичный мониторинг.
С моей точки зрения ситуация выглядела так: ужасно усталый я пришёл домой вечером, бросил телефон с 3 % заряда на столик и вырубился. Около шести часов я проснулся, решил, что быстро не засну, включил телефон почитать Хабр и сорвал джекпот в виде лавины уведомлений. Технический директор хостинга ночью тоже спал. Но он никогда не отключает телефоны, и звонки админов у него всегда дают громкий сигнал. Он разруливал ситуацию с часа ночи. Хорошо, что телефония в ЦОДе у нас как раз была зарезервирована правильно.
Фактически утром я не мог точно понять, что произошло (как и все мы: для полноты картины нужно было бы дозвониться до админов и поговорить с ними больше 20 минут).
В итоге я и ещё несколько человек пытались отвечать клиентам в чате. Дежурная смена отвечала официальным фразами, а я пытался дать больше информации.
Мы рассылали вот такое письмо:
В телеграм-канале был сущий кошмар. Дело в том, что в России уже было два случая, когда хостинг внезапно отключался целиком, а потом больше никогда не включался. И среди наших клиентов были админы, повидавшие некоторое дерьмо и знающие особенности ИТ-бизнеса в этой стране. Поэтому они, естественно, волновались. Мне очень нужно было объяснить, что происходит, но я никак не мог сам собрать информацию рано утром.
Никто не верил, что в одном из 14 ЦОДов был сбой, который затронул до 10 % железа. Отдельно меня обижали фразы вроде: «Чего вы хотите за такие деньги?» Аварии бывают и там, где на порядок дороже. У нас нет умышленной ставки на некачественные услуги. Неважно, сколько заплатить: зарезервироваться на 100 % не получится. Самое обидное в этой истории, что раздолбаями на этот раз оказались не мы. Точнее, мы тоже, но, трезво оценивая ситуацию, мы всё же в меньшей степени.
Вторая особенность была в том, что шквал звонков снёс поддержку нам и всем соседям, потому что люди звонили по всем телефонам и нам, и им.
Более-менее связную картину произошедшего мы получили только около восьми утра.
В целом это, наверное, — самый тяжёлый наш кризис, потому что мы его переживали при 100-процентно заполненном машзале. Когда гермозона стоит полупустой, есть резерв по мощности: формируется тот самый 2N + 1, а не просто 2N. У нас такой роскоши не было. В целом мы сейчас переберём архитектуру сети, но куда важнее, что мы в Москве принципиально делаем ставку на развитие Останкино (вот пост про него) — ЦОДа повышенной ответственности. И в убежище, и в М9 гермозоны уже заполнены полностью, и новых стоек просто нет. В случае М9, где мы делим площадку с другими компаниями, нет места даже в стойках соседей.
Итог: нам нужен сервис публичного мониторинга доступности нод. Обычный хостинг такого делать не будет, потому что инциденты принято скрывать. Особенно если они затронули не очень большую часть клиентов. Просто телеграм-канала, Хабра и поддержки не хватает. Нужна система, которая сама обновляется и показывает объективные данные всё время, даже если это не очень удобно для нас в моменте.
В процессе слова поддержки от вас были очень приятны. Благодарности в конце тоже очень грели. Спасибо! Это было очень тяжело, но то, что вы с пониманием отнеслись, — это очень приятно.
ruvds.com
Это просто дикая цепочка событий.
Это патрубок дизеля, перевязанный бинтом из админской аптечки. Сейчас расскажу, какую роль он тут сыграл.
Итак, мы потеряли оба городских ввода — всё как в худших домах Парижа. Как мы уже потом узнаем, вроде бы авария была на трансформаторе 110 кВт: при перераспределении мощностей с первого произошло замыкание второго. За полтора года это уже третий раз, когда пропадают оба луча, и вот тут я рассказывал, как мы почти сутки стояли на дизеле. Для клиентов это прошло незаметно (кроме той стойки, где при мигании света сгорел ИБП: там был простой на перезагрузку).
Штатно сработали ИБП, автоматически завелись дизель-генераторы, ЦОД продолжил работу. У нас общая энергосеть с соседним ЦОДом всё в том же подземном бомбоубежище. Общее потребление — 0,5 МВт, дизелей — на 1,05 МВт.
Через два часа, около 3:30 ночи, лопнул патрубок дизеля 0,5 МВт, отчего он внезапно перестал работать. Админы убежища переключили мощности на дизели 2 х 100 КВт и 2 х 200 КВт. В момент переключения нагрузка снова легла на ИБП, а за два часа они не успели восстановиться, и часть оборудования выключилась.
Это запустило целую цепочку последствий, потому что при этом выключении погорела одна из плат коммутатора, обеспечивавшего доступ в нашу сеть управления ЦОДом, то есть все удалённые доступы.
На площадке остались два админа, которым нужно было включить вручную коммутаторы и стойки, починить дизель и понять, что вообще происходит.
Дисклеймер: мы ещё не до конца разобрались с логами и причинно-следственными связями, но сейчас я пишу по горячим следам. Возможно, дальше выяснятся ещё интересные детали. Сейчас мы сосредоточились в основном не на расследовании инцидента, а на устранении последствий. Детальный разбор будет позже.
Что было с городскими вводами
Они пропали. Авария коснулась всего микрорайона. Мы относимся к важным потребителям электроэнергии, поэтому восстановление наших мощностей — первый приоритет для города. У нас не было городского ввода примерно с часа ночи до обеда, около 10 дали первый луч, через пару часов — второй.
Как можно видеть по заявкам в районе, жилые дома восстанавливали позже, то есть устраняли аварию максимально быстро для нас.
Почему только два админа
Ночь с субботы на воскресенье, особо охраняемая территория. В течение двух часов с начала инцидента всё идёт относительно предсказуемо, и помощь не нужна. Админы работают штатно. Примерно в 3:30 становится понятно, что нужно высылать подкрепление, но в этот момент уже:
Коммутатор защищённого сегмента сети вышел из строя.
Админы разбираются с дизелями и пытаются включить оборудование, то есть ходят от стойки к стойке и определяют, что случилось с каждой машиной.
Четыре других дизеля перегреваются и собираются отключиться.
Самое печальное — коммутатор защищённого сегмента, который включился, но работал неправильно. Это сегмент, в котором стоит DDoS-защита, то есть через него подключено около 7 % IP-адресов ЦОДа. Коммутатор зарезервирован по принципу HOT SWAP, то есть точно такой же лежит в коробке в шкафу в админской. Мы не думали строить кластер из двух коммутаторов, потому что не похоже, что DDoS-защита относится к критичным сегментам: при выходе её из строя примерно на 5–20 минут (время физической замены коммутатора) возможны DDoS.
То есть центральный коммутатор у нас нормально в кластере, а один из листов, относительно небольшая и относительно нетребовательная к непрерывности подсеть, на хотсвапе. Это была ошибка, и здесь мы здорово облажались.
Во-первых, оказывается, что тяжело менять коммутатор, когда ты держишь руками патрубок дизеля. Кроме физической замены, там нужно импортировать правила и ACL.
Во-вторых, на то, чтобы понять, что с ним что-то не так, тоже ушло время. Он не сгорел полностью, а включился и вроде бы начал работать. После его включения полетела часть ACL, и он отрезал нам управляющие сервера от сети.
В этот момент около 3:30 мы остались без сервисдеска, мониторинга, корпоративного мессенджера и одной из реплик сайта. Мессенджер тут же деградировал до «Телеграма», веб-сервер сайта автоматически поднялся в другом ЦОДе, а вот от мониторинга и сервисдеска такой подставы мы не ждали.
На мониторинг, в частности, было завязано определение оставшегося свободного места в ЦОДах, а оставшееся свободное место в ЦОДе определяет возможность создавать в нём новую виртуальную машину.
Это означало, что автоматика не видит свободного места, потому что источник данных для панели управления находился именно в глючившем защищённом сегменте. А потому система не даёт возможности создать новые ВМ в каждом из ЦОДов сети.
Выглядело это как крестик на создание ВМ на каждом из ЦОДов нашей сети, что начало вызывать панику в чате клиентов хостинга:
Это уже семь утра, когда существенная часть клиентов проснулась. До семи утра было ещё два отключения питания и перехода на уже истощённые ИБП. Перегрелся и начал нестабильно работать один из малых дизелей, а большой ещё не успели перебинтовать. И вообще, админы не очень хорошо ремонтируют дизели: это немного не их профиль работы.
Соответственно, клиенты пытались перенести свои ВМ в другие ЦОДы по миру, но из-за сбоя мониторинга не могли этого сделать: система не давала создать новые ВМ.
Начиная с шести утра мы пытались ответить клиентам, что происходит, но сами не до конца понимали масштаб проблемы из-за отвалившегося мониторинга.
Админы были отрезаны от мира
Я неслучайно сказал, что это ночь с субботы на воскресенье на особо охраняемой территории. Дело в том, что после начала всем известных событий территория стала просто параноидально охраняемой.
Среди всего прочего в рамках общей параноизации нам отозвали все постоянные пропуска и заменили их на систему одноразовых пропусков персонала посменно. То есть около 3:40 ночи, когда уже стало понятно, что в ЦОДе не помешают лишние руки, никого отправить туда мы не могли, потому что люди встали бы на проходной.
Бюро пропусков по ночам не работает, по воскресеньям — тоже.
Это значит, что мы не можем отправить ещё админов и не можем отправить дизель. Дизель на 0,5 МВт у нас под рукой был после прошлого инцидента, и мы подтащили его к территории около девяти утра, но попасть внутрь не могли.
Охрана понимала всю серьёзность ситуации (насколько могла) и очень хотела помочь, но ровно в рамках своих полномочий: им нужно было разбудить своего начальника, чтобы он разрешил нештатную ситуацию. Попасть на территорию получилось только около 13:00.
До этого момента в ЦОДе было две пары рук.
До кучи около семи часов дышать в админской стало довольно тяжело: из-за погоды и перепада давления при открытии гермозоны (вентиляция работала только в вычислительном сегменте) внутрь засасывало выхлоп дизелей с улицы, который в обычное время просто улетал бы в окружающее пространство.
Админы разрывались между попытками ремонта дизеля, жонглированием мощностями, включением стоек и сетевого оборудования и попытками понять, что происходит с защищённым сегментом. Плюс время от времени им было нужно подниматься на воздух, чтобы не разболелась голова.
Восстановление
Когда приехал резервный дизель, всё встало на свои места.
Мы восстановили питание и более-менее последовательно разобрались, что происходит. Стало понятно, что с коммутатором, поменяли его, подняли защищённый сегмент. Там подцепился мониторинг, который нарисовал нам всю картину ночи. В этот же момент на нас упали все тикеты, которые клиенты хостинга поставили за ночь, потому что заработала очередь.
Последние сервера поднялись около 16 часов: это когда мы подключили в бой тот самый защищённый сегмент, стоявший за частично погоревшим коммутатором.
Клиенты, естественно, были не очень довольны:
Интересно, что больше всего тикетов с паникой было у пользователей наиболее экономичных тарифов. То есть те, у кого был действительно критичный проект, развернули его на нескольких геоплощадках. Бывалые админы достаточно спокойно наблюдали за паникой людей в чате:
Общий итог такой:
- 23% клиентов ДЦ вообще ничего не заметили, остальные могли ощутить даунтайм до 120 минут.
- 7-8 % виртуальных машин было недоступно более трёх часов. Мы не можем сказать точнее: верхняя оценка — 10 %, но мы знаем, что часть машин в рассыпавшемся сегменте отвечала, по косвенным данным, что это было всё же 7 %. Максимальный даунтайм на отдельных серверах из 7-8% составлял 16 часов.
- Всё 13 остальных ЦОДов работали штатно, но отсутствие мониторинга не давало создавать на них новые ВМ.
- Всё решилась после прибытия подмоги, то есть с 13:00 до 15:00. К 16:30-17:00 доступность была 100% восстановлена.
- В нашем ЦОДе не работало, по верхней оценке, 10 % оборудования. У соседей же была настоящая паника: у них пострадало до 75 % оборудования (судя по их письму клиентам).
Сколько/чего выключилось:
- Количество НОД перезагрузившихся из-за перепада/отсутствия питания в ночь аварии — 68 %: 24 % в 3:30, 26 % в 4:50 и 18 % в 6:00.
- Количество НОД дц Rucloud, которых не затронула авария — 23 %.
- Количество НОД дц Rucloud, которые стали доступны после решения проблемы с коммутатором (самое большое время простоя) — 8 %.
- Количество НОД дц Rucloud, которые были перезагружены 18-19 июня в результате выявленных последствий аварии — 1 %.
Разбор ошибок
Из того, на что мы могли повлиять:
- Нужен не двойной запас по дизелям, а больший: ночь показала, что двух недостаточно, нужно 2N + 1 минимум. Поскольку в кризисы мы объединяем энергосеть с соседями, договорились, что введем в эксплуатацию (дизель уже куплен, ожидаем к нему кожух) вместе ещё один 0,5 МВт ДГУ и разместим на территории.
- Коммутатор защищённого сегмента должен был быть задублирован в кластере. Как только мы разместили за DDoS-защитой мониторинг, сеть стала критичной, но мы этот момент упустили и оставили узкое место с ручной заменой железяки. Оказалось, что у неё есть не только бинарные состояния «однозначно работает» и «однозначно не работает», но и промежуточные.
- Тот факт, что мониторинг и тикет-система не были зарезервированы в другом ЦОДе, — это пощёчина нашему достоинству. Мы чёртовы параноики из финансов, и именно мы остались без мониторинга. Дублирование было в разработке и намечалось на конец июля. Немного не успели. Исторически эти системы размещались в первом нашем ЦОДе, теперь нужно распределять их по гриду, чтобы даже масштабный сбой никак не влиял на возможность заказывать виртуалки и обращаться в поддержку в других ЦОДах.
Я пережил несколько очень неприятных моментов этой ночью и понял, что нам нужен публичный мониторинг.
С моей точки зрения ситуация выглядела так: ужасно усталый я пришёл домой вечером, бросил телефон с 3 % заряда на столик и вырубился. Около шести часов я проснулся, решил, что быстро не засну, включил телефон почитать Хабр и сорвал джекпот в виде лавины уведомлений. Технический директор хостинга ночью тоже спал. Но он никогда не отключает телефоны, и звонки админов у него всегда дают громкий сигнал. Он разруливал ситуацию с часа ночи. Хорошо, что телефония в ЦОДе у нас как раз была зарезервирована правильно.
Фактически утром я не мог точно понять, что произошло (как и все мы: для полноты картины нужно было бы дозвониться до админов и поговорить с ними больше 20 минут).
В итоге я и ещё несколько человек пытались отвечать клиентам в чате. Дежурная смена отвечала официальным фразами, а я пытался дать больше информации.
Мы рассылали вот такое письмо:
Всем привет!
В районе 3:00 по МСК произошла авария на подстанции, в результате чего в дата-центре Rucloud (г. Королёв) были нарушены оба ввода электроснабжения. Проблема повлекла за собой перезапуск коммутационного ядра и длительный период восстановления. На момент аварии оборудование дата-центра работало на аварийных дизель-генераторах, но сейчас проблема устранена, и доступность всех нод уже восстановлена. Специалисты работают над восстановлением доступа к единичным оставшимся оффлайн виртуальным машинам, и в ближайшее время доступ должен полностью восстановиться.
По предварительным данным, аварийные работы затронули не более 10 % серверного оборудования в дц Rucloud. Остальные 13 дата-центров работают в штатном режиме, и проблем там не наблюдалось.
Если ваша виртуальная машина была среди тех, что затронула сегодняшняя авария, обязательно свяжитесь с нами по почте support@ruvds.com. Каждый случай простоя будем решать индивидуально и начислять компенсации за простой.
Подробный отчёт по аварии ждите в нашем блоге на Хабре в ближайшие дни.
Приносим свои извинения за доставленные неудобства!
В телеграм-канале был сущий кошмар. Дело в том, что в России уже было два случая, когда хостинг внезапно отключался целиком, а потом больше никогда не включался. И среди наших клиентов были админы, повидавшие некоторое дерьмо и знающие особенности ИТ-бизнеса в этой стране. Поэтому они, естественно, волновались. Мне очень нужно было объяснить, что происходит, но я никак не мог сам собрать информацию рано утром.
Никто не верил, что в одном из 14 ЦОДов был сбой, который затронул до 10 % железа. Отдельно меня обижали фразы вроде: «Чего вы хотите за такие деньги?» Аварии бывают и там, где на порядок дороже. У нас нет умышленной ставки на некачественные услуги. Неважно, сколько заплатить: зарезервироваться на 100 % не получится. Самое обидное в этой истории, что раздолбаями на этот раз оказались не мы. Точнее, мы тоже, но, трезво оценивая ситуацию, мы всё же в меньшей степени.
Вторая особенность была в том, что шквал звонков снёс поддержку нам и всем соседям, потому что люди звонили по всем телефонам и нам, и им.
Более-менее связную картину произошедшего мы получили только около восьми утра.
В целом это, наверное, — самый тяжёлый наш кризис, потому что мы его переживали при 100-процентно заполненном машзале. Когда гермозона стоит полупустой, есть резерв по мощности: формируется тот самый 2N + 1, а не просто 2N. У нас такой роскоши не было. В целом мы сейчас переберём архитектуру сети, но куда важнее, что мы в Москве принципиально делаем ставку на развитие Останкино (вот пост про него) — ЦОДа повышенной ответственности. И в убежище, и в М9 гермозоны уже заполнены полностью, и новых стоек просто нет. В случае М9, где мы делим площадку с другими компаниями, нет места даже в стойках соседей.
Итог: нам нужен сервис публичного мониторинга доступности нод. Обычный хостинг такого делать не будет, потому что инциденты принято скрывать. Особенно если они затронули не очень большую часть клиентов. Просто телеграм-канала, Хабра и поддержки не хватает. Нужна система, которая сама обновляется и показывает объективные данные всё время, даже если это не очень удобно для нас в моменте.
В процессе слова поддержки от вас были очень приятны. Благодарности в конце тоже очень грели. Спасибо! Это было очень тяжело, но то, что вы с пониманием отнеслись, — это очень приятно.
ruvds.com
0 комментариев
Вставка изображения
Оставить комментарий