Представляем вашему вниманию ежемесячный обзор интересных новостей и полезных советов от Hetzner! Приятного чтения!
Двойная платиновая награда на премии Service Provider Awards
Компания Hetzner была удостоена платиновых наград в двух категориях на церемонии вручения наград Service Provider Awards 2026. Мы заняли первое место в категориях «Супермасштабные решения» и «Центры обработки данных/колокации XXL».
Премия Service Provider Awards — одна из самых авторитетных читательских оценок в ИТ-индустрии. Премия вручается ежегодно на основе опроса читателей отраслевых ИТ-изданий Vogel IT-Medien. Критерии оценки включают качество, надежность и производительность ИТ-услуг и инфраструктуры.
Большое спасибо всем, кто за нас проголосовал!
Благодаря этим двум платиновым наградам компания Hetzner продолжает демонстрировать свои успехи в этом престижном опросе читателей. Награды отражают доверие, которое клиенты и отраслевые эксперты оказывают инфраструктуре Hetzner, и признают постоянное развитие компании в области облачных, хостинговых и дата-центровых услуг.
В этом году церемония вручения наград для поставщиков услуг состоялась в 15-й раз в рамках саммита поставщиков услуг в Петерсберге, недалеко от Бонна, в Германии.
www.hetzner.com/unternehmen/auszeichnungen/
Облачный сервер CPX12 теперь доступен в европейских странах
В связи с многочисленными просьбами, облачный сервер CPX12 с «обычной производительностью» теперь также доступен в наших европейских представительствах (FSN1, HEL1 и NBG1).
Благодаря 1 виртуальному процессору, 2 ГБ оперативной памяти и 40 ГБ SSD-накопителя, CPX12 идеально подходит в качестве экономичного сервера начального уровня для задач с низкими требованиями к ресурсам и специфическим назначением. Типичные сценарии использования включают небольшие веб-сайты, личные блоги, частные VPN и прокси-сервисы, чат-серверы и боты.
CPX12 можно приобрести по цене 0,0192 евро в час или максимум 11,99 евро в месяц.
www.hetzner.com/de/cloud/regular-performance/
ПЕРЕЙДИТЕ НА НОВЫЙ ВЕБ-ХОСТИНГ ПРЯМО СЕЙЧАС
Вы все еще используете пакет веб-хостинга уровня 1, 4, 9 или 19? Легко переходите на наши текущие пакеты веб-хостинга S, M, L или XL прямо сейчас.
В рамках новых тарифных планов вы получите доступ к таким современным функциям, как:
- Кэширование Varnish (Web Hosting S и выше): более быстрая загрузка вашего сайта.
- Redis (веб-хостинг уровня L и выше): объектный кэш для повышения производительности и сокращения времени загрузки.
- Node.js (веб-хостинг L и выше): запускайте собственные проекты и приложения непосредственно в своем аккаунте веб-хостинга.
Все улучшения вы найдете в нашей документации.
docs.hetzner.com/managed/webhosting/difference-between-webhosting-packages
Переход очень прост. Войдите в konsoleH и выберите тарифный план веб-хостинга, на который хотите перейти. Затем в меню перейдите в раздел «Договор»; «Сменить тип учетной записи» и выберите нужный тип учетной записи. После этого следуйте инструкциям на экране. Ваши данные и IP-адрес, разумеется, останутся без изменений.
www.hetzner.com/webhosting
20 ЛЕТ HETZNER @ DE-CIX: ОТ 1 ДО 2800 Гбит/с
Летом 2006 года мы подключились к DE-CIX, что стало важной вехой в развитии нашей сетевой инфраструктуры. Прямое подключение к одной из крупнейших в мире сетей обмена интернет-трафиком заложило основу для снижения задержек, обеспечения высокопроизводительных соединений и эффективного обмена данными с многочисленными национальными и международными партнерскими сетями.
Начав с пропускной способности в 1 гигабит в секунду, мы постоянно расширяли свои возможности на протяжении последних двух десятилетий. Сегодня пропускная способность нашего соединения DE-CIX составляет впечатляющие 2800 гигабит в секунду.
Это развитие отражает не только колоссальный рост объёма передаваемых данных, но и наше стремление к созданию современной, высокопроизводительной и перспективной сетевой инфраструктуры. На сегодняшний день общая пропускная способность нашей сети составляет 48 Тбит/с.
При скорости 48 Тбит/с можно было одновременно транслировать миллионы фильмов в формате 4K — объем данных, который был немыслим всего несколько десятилетий назад.
www.hetzner.com/unternehmen/rechenzentrum/
Премия CloudComputing Insider Award 2026: Ваш голос имеет значение
Мы впервые номинированы на премию CloudComputing-Insider Award 2026 в категории «Суверенное облако».
Если вы считаете, что мы заслужили эту награду, мы будем очень благодарны за ваш голос. В знак благодарности все участники будут включены в розыгрыш беспроводных наушников Bluetooth.
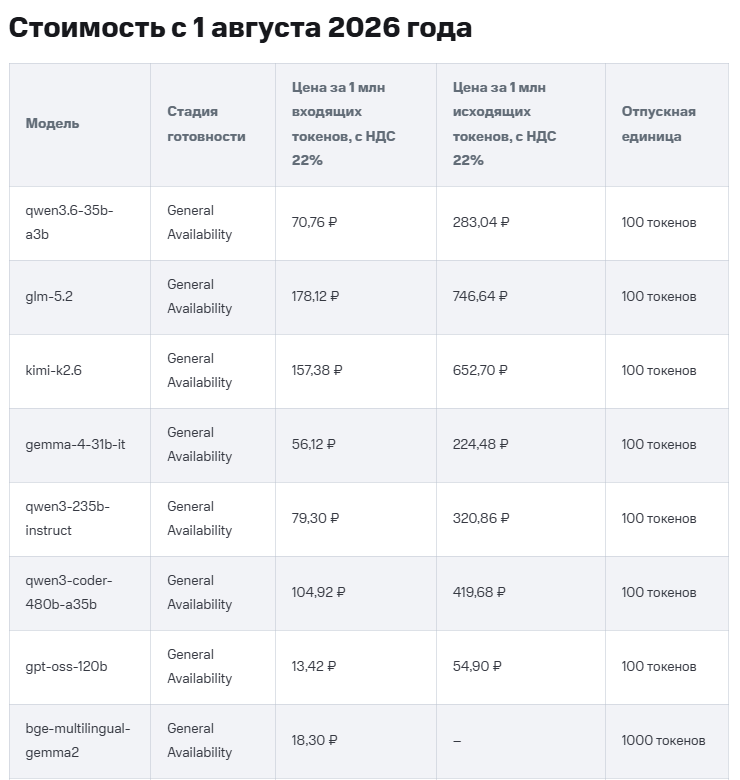
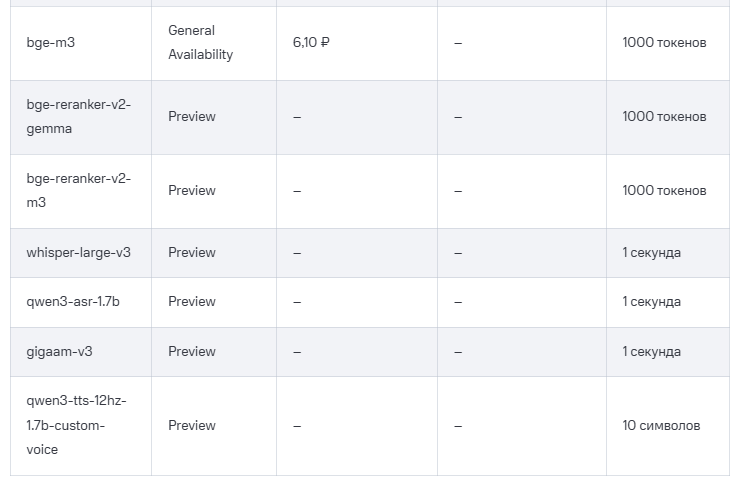
ЭКСПЕРИМЕНТЫ С ИСКУССТВЕННЫМ ИНТЕЛЛЕКТОМ: ПРИСОЕДИНЯЙТЕСЬ К НАМ
Для внутренних задач мы постоянно разрабатываем и тестируем новые и интересные подходы, которыми с удовольствием поделимся с вами. Чтобы предоставить вам доступ к нашим прототипам, идеям и экспериментам, мы запустили платформу Experiments. Приглашаем вас опробовать наши решения, которые размещены на нашем собственном оборудовании в наших центрах обработки данных. Гарантий нет, но и платно.
Теперь мы предлагаем API для вывода результатов, который обеспечивает доступ к LLM Open-Weight через REST API, совместимый с OpenAI. Вы можете использовать API с любой средой разработки, совместимой с OpenAI, и легко интегрировать его в свои проекты. Руководство по настройке для OpenCode можно найти в руководстве сообщества. Предварительно настроенный нами LLM — это Open-Weight. Качество ответов, вероятно, не такое высокое, как у основных поставщиков, но часто достаточное для начальных экспериментов.
Наш второй эксперимент основан на API для вывода результатов; это полностью размещенная у нас версия OpenClaw, включающая наши собственные предварительно настроенные модели. Вы можете настроить свой собственный OpenClaw по своему усмотрению и даже подключиться к другим поставщикам услуг вывода результатов. Попробуйте помощника OpenClaw AI в качестве альтернативы Claude или ChatGPT и сохраните контроль над своими данными.
Несколько слов об OpenClaw в частности и об ИИ в целом: помните о рисках, связанных с предоставлением ваших данных OpenClaw. Мы не влияем на код OpenClaw и не несем ответственности за действия OpenClaw. Наша платформа для экспериментов может стать недоступной или работать с низкой производительностью в периоды высокой нагрузки.
Поскольку мы не создаём резервные копии, вам следует, например, создавать резервные копии ваших конфигураций отдельно и избегать настройки производственных сред на основе Inference API.
Мы надеемся, что платформа «Эксперименты» предоставит нам конкретную обратную связь и информацию, а также различные типы метрик: насколько хорошо масштабируется наш подход? Есть ли потребность и интерес в потенциальном предоставлении Hetzner программного обеспечения как услуги (SaaS)? Какие (дополнительные) функции особенно важны для вас? Вы также можете целенаправленно проверить пределы возможностей в этом эксперименте. Это предоставит нам ценные данные, которые покажут, например, какую нагрузку может выдержать наша система.
Пожалуйста, не стесняйтесь делиться своими отзывами, вопросами или опытом, отправляя запросы в службу поддержки через раздел «Эксперименты», или же обсуждайте их на форуме Hetzner.
experiments.hetzner.com