SolusIO WHMCS VPS Provisioning module released
Выпущен модуль подготовки SolusIO WHMCS
Мы с гордостью сообщаем, что выпустили модуль SolusIO WHMCS VPS Provisioning. Этот модуль дает вам возможность продавать VPS с предоплатой в традиционном стиле.
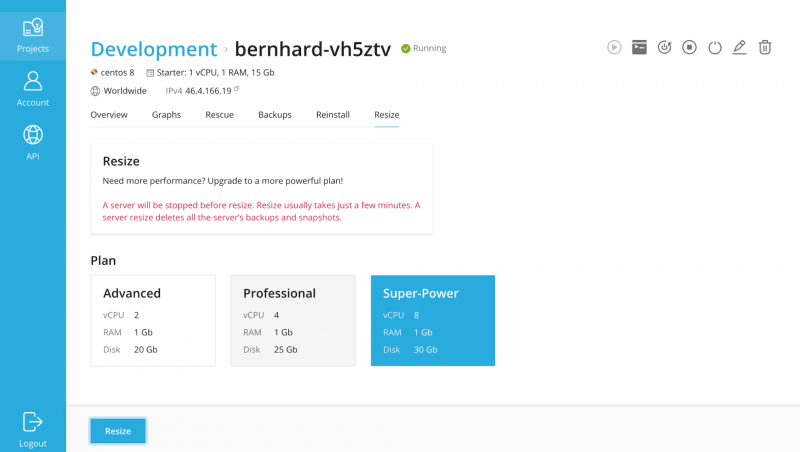
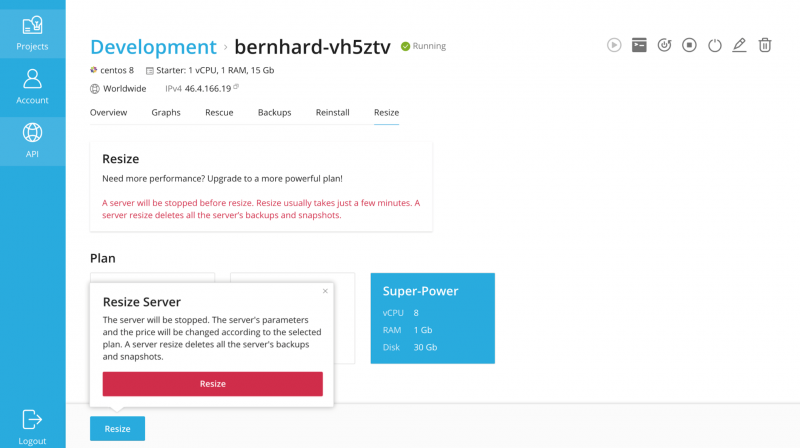
Модуль позволяет выполнять следующие действия виртуального сервера:
- Создайте
- уничтожить
- приостановить
- откладывать
- перезагрузка
- ботинок
- неисправность
- Монтаж
Извлеките содержимое zip-файла в корневой каталог WHMCS.
Конфигурация
Откройте страницу учетной записи в пользовательской области SolusIO, чтобы сгенерировать токен API.
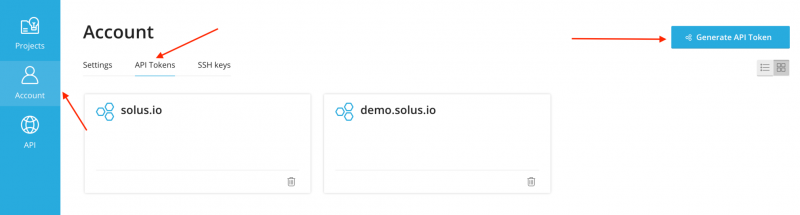
Настройте доступ к SolusIO API, добавив новый сервер в WHMCS. Обязательные поля: Имя хоста и Пароль.
Токен API SolusIO необходимо сохранить в поле пароля.
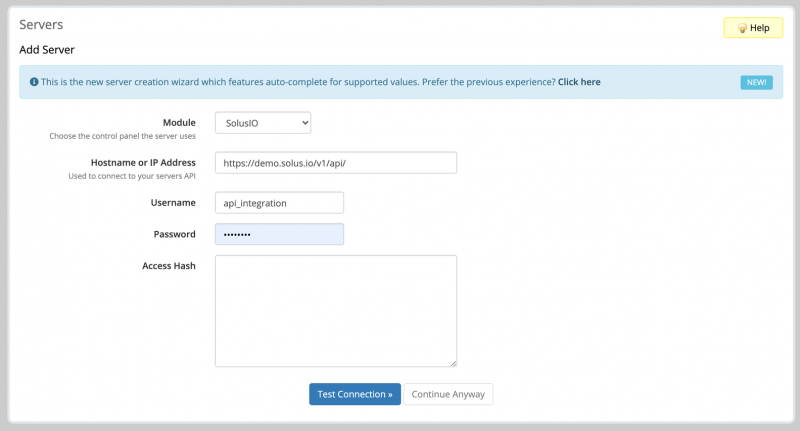
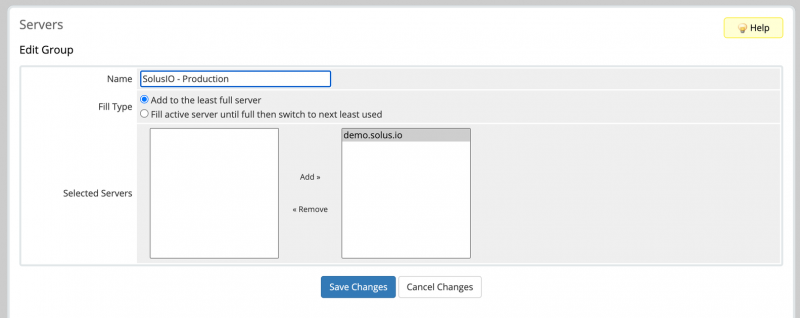
Создайте группу серверов в WHMCS и назначьте сервер, который был создан на предыдущем шаге.
Конфигурация продукта
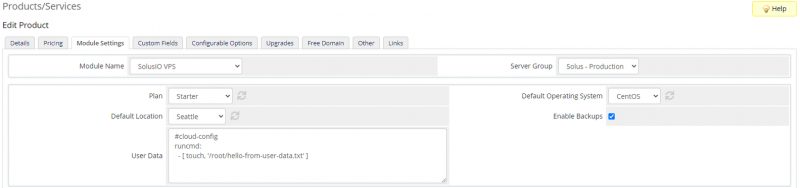
повторно создайте продукт в WHMCS и выберите SolusIO VPS в качестве связанного модуля и группы серверов, которую вы настроили ранее.
Выберите план, местоположение по умолчанию и операционную систему и сохраните изменения.
Дополнительная конфигурация
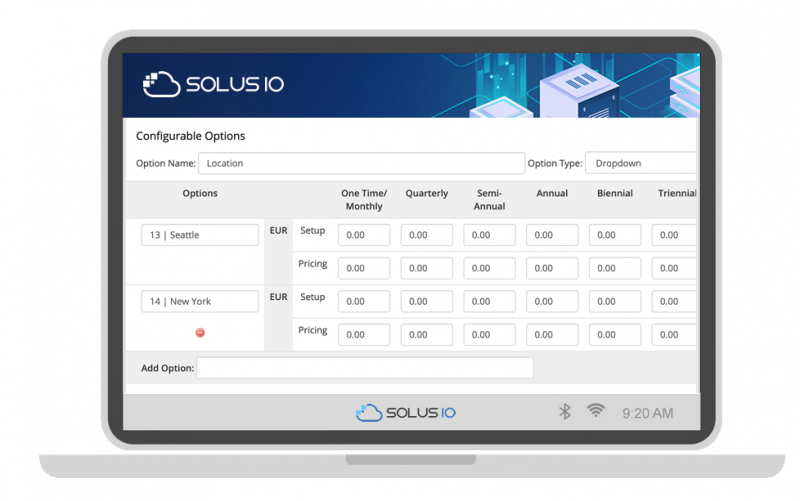
Локации
Модуль дает возможность выбрать конкретное место при заказе товара. Это делается в виде настраиваемых параметров.
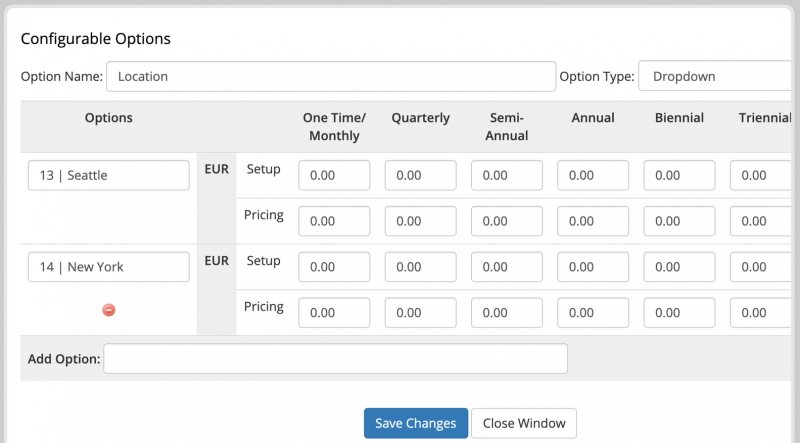
Создайте настраиваемую опцию с именем Location. Добавьте параметры в соответствии со следующим соглашением: locationId | locationName. Это будет иметь приоритет над выбранным местоположением в настройках модуля продукта.
Операционные системы
Модуль дает возможность выбрать конкретную операционную систему при заказе товара. Это делается в виде настраиваемых параметров.
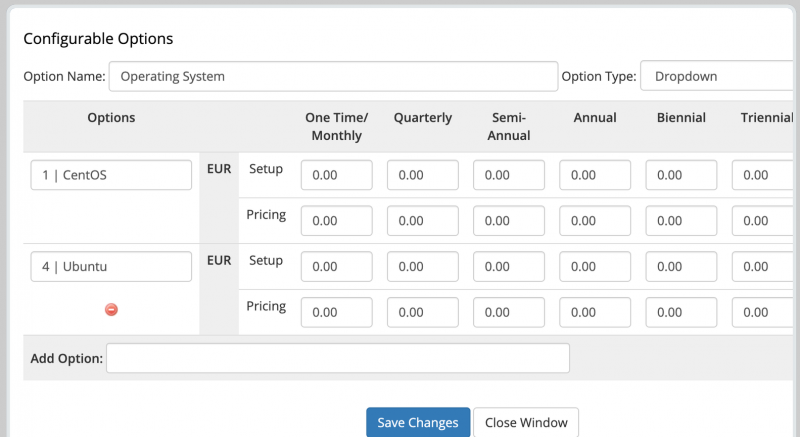
Создайте настраиваемый параметр с именем Операционная система. Добавьте параметры в соответствии со следующим соглашением: osId | osName. Это будет иметь приоритет над операционной системой, выбранной в настройках модуля продукта.
Ключ SSH
Модуль дает возможность указать SSH-ключ при заказе товара. Это делается в форме настраиваемого поля продукта.
Создайте настраиваемое поле с именем SSH Key и введите Text Area.
Да, у нас открытый исходный код
Вы можете легко форкнуть наш проект на Github и создать свой собственный замечательный модуль.
github.com/solusio/solusiovps/tree/v1.0.0