Мы шутили про эти телефоны, а они пригодились на прошлых выходных. Точнее, пригодилось резервирование телефонии. Не конкретно эти, но похожие)
Вот тут пост про нашу аварию на прошлых выходных. Там всё было по горячим следам, потом я обещал подробнее ответить на вопросы. Отвечаю. Самое главное, пожалуй, что бы я хотел донести, — в комментариях к первому посту было очень много советов, что можно сделать, чтобы избежать такой же аварии. Но большинство из этого мы делать не будем. Потому что это ошибка выжившего: защищаться надо от вероятных рисков, а не от крайне маловероятных, где совпадает сразу пять факторов. Точнее, можно и от них, но есть критерий экономической обоснованности.
Но давайте обо всём по порядку.
Сколько клиентов пострадало?
На три часа и более в одном ЦОДе отключилось 7–10 % из 14 наших, то есть менее 0,5 % от общего числа клиентов хостинга (точнее, хостов). Тем не менее мы очень подробно рассказываем про эту аварию, потому что она вызвала очень много вопросов.
Почему вы занимаетесь ЦОДом, а не встаёте в готовый?
«Прекрасная история, спасибо! Совет автору: ищите компанию, которая занимается ЦОДами давно и профессионально, ну а вам — переориентироваться на продажу сервисов/мощностей в этих ЦОДах...»
Сейчас по миру у нас 14 ЦОДов, где можно разместиться. Один из них, первый в Москве, с которого всё начиналось, — наш. Именно в нём произошла эта авария, и именно поэтому я так подробно всё рассказываю. Естественно, было бы логично уже давно сосредоточиться только на VDS-хостинге, как мы делаем везде по миру, но это наш базовый ЦОД, он для нас дорог. В смысле пока всё же экономически обоснованнее держать его. Плюс у нас на площадке есть аттестация ФСТЭК, что позволяет строить защищённые сегменты. Ну и охрана у него впечатляющая, про это — ниже.
Вообще тут вопрос намного более сложный. RuCloud Королёв — это наш первый ЦОД. Мы его создали сразу после истории с «Караваном», когда «Караван» ушёл в небо. Напомню, что они при срочной необходимости переехать не смогли забрать с собой энергетику и много других вещей, и это стоило им бизнеса. Полностью. Теперь — про экономику ЦОДа: если вы строите свой, то с масштабом снижается доля постоянных издержек. То есть с экономической точки зрения надо строить ЦОД как можно большего размера. А вот с точки зрения ведения ИТ-бизнеса в России — как можно меньшего, потому что, если есть выбор между одним ЦОДом и двумя-тремя, второе намного надёжнее. Но каждый инстанс получается дороже. В итоге мы построили свой ЦОД, подняли в нём аттестованный ФСТЭК сегмент (это своё помещение, защита от прослушивания, защита от лазерного считывания вибраций, сертифицированное оборудование, сертифицированное ПО, аудиты) — такого на общих площадках в принципе не сделать, а некоторым клиентам это важно. В смысле по рекламным проспектам может создаться впечатление, что можно, но нет. Равно как и с PCI DSS в Европе чаще всего — так же. Опять же свои админы, свои правила. Но тут — как с 3F: лучше всё же арендовать.
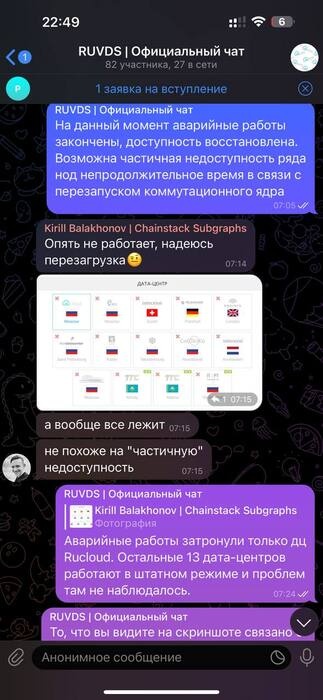
Соответственно, дальше мы раскладывали яйца по разным корзинам. Сейчас их 14. К концу недели будет 15. Можно выбрать любую.
То есть надо читать блог, чтобы понимать некоторые незадокументированные особенности ЦОДов?
Да. Мы же не можем прямо на сайте явно написать про ЦОД в Амстердаме, что там в стране легальны порнография и варез, и поэтому там можно выкладывать свежий фильм Михалкова без юридических проблем. Точно так же мы не можем рассказать про все особенности других ЦОДов. По большому счёту они сводятся к тому, что «по беспределу не заберут сервер», к особенностям охраны, питания, законодательства страны и так далее. Корпоративных клиентов мы консультируем на переговорах, если надо.
Сразу скажу, что даже Tier-IV никак не защищает от аварии. У нас был пример, когда 10 часов не было Интернета в Швейцарии. Они каждые 15 минут писали, что сейчас всё будет, кстати. Молодцы! Хороший статус-апдейт.
Вкратце вот: в ZUR1 (Цюрих) — 2N по питанию и N+1 охлаждения, внутренний стандарт SLA — 99,999 % (это выше, чем в Tier IV по UI). Во Франкфурте (это наш второй Tier IV UI) — N+1, два городских ввода от разных станций. EQUINIX LD8 гарантирует SLA TIER III (99,98 % — те самые 105 минут простоя в год). Питание и охлаждение — N+1, но они очень сильно заморочились на резервирование Интернета, аплинки с нескольких магистралей. Linxdatacenter — питание N+1. Екатеринбург — N+1. AMS9 — N+1. Останкино — четыре независимых ввода, прямое подключение к ТЭЦ-21, N+N.
А вот что мы реальном можем сделать — это написать SLA в каком-то виде на каждом из ЦОДов при выборе места для создания VDS. Это мы сейчас обдумываем, потому что SLA надо считать и фактический, и какой-то ещё прогнозный.
Уложились ли вы в свой SLA?
«Было бы очень интересно послушать про SLA и про то, как оно сейчас реализуется в текущей действительности...»
У нас по этому ЦОДу SLA — с 99,98-процентной доступностью, это 1 час 45 минут возможного простоя в год. Сразу скажу: это только в рекламе, а в документах это никак не регламентировано. Но мы всё равно выплачиваем компенсации.
Напомню, что в этом ЦОДе были клиенты с простоем больше трёх часов (77 % пострадавших), около 10 % — с простоем около 12 часов, и около 1 % — с простоем больше. Естественно, мы сразу же обещали компенсации всем тем, кто попал под этот инцидент. Надо понимать, что речь идёт про оговорённые договором компенсации, то есть если там была трейдерская машина, которая должна была что-то выкупить в нужный момент и клиент от этого потерял или недополучил какую-то сумму, — простите, но по договору мы компенсируем время простоя сервера, а не недополученную прибыль в результате работы ПО. Для критичных случаев как раз используется георезервирование, и именно поэтому нас выбирают: среди российских VDS-провайдеров у нас наиболее широкая география.
Сейчас, возможно, мы ещё выдохнем и будем менять договоры в сторону более явного прописывания SLA. Если бы мы делали это заранее, то ЦОД в Королёве имел бы 99,96 % или 99,9 %, а не 99,98 %. Для примера: фактический аптайм 100 % с 1991 года есть в Останкино.
Собственно, поэтому Королёв и дешевле других ЦОДов по колокации. Мы продаём колокацию во всех точках нашего присутствия, но об этом мало кто знает. У нас много места везде, кроме М9.
Почему ИБП хватает только на одно переключение дизеля?
«Тут много всяких «полезных» решений насоветовали в комментариях, разумеется. Вроде стресс-проверок отключением электроэнергии каждую ночь и покупки ИБП с акумом на сутки работы. Лол».
Похоже, про ИБП всё же надо объяснить. На текущий момент общемировая практика — держать их из расчёта одного набора свинцовых батарей на юнит, что обеспечивает несколько минут работы. За эти несколько минут нужно сделать переключение питания, то есть завести дизель. Заряда хватает обычно и на второе переключение с дизеля на городской ввод. Батареи заряжаются около 9–12 часов минимум. В случае если отключений питания несколько, то с каждым новым разрядом вырастают шансы, что они отключатся вместе с частью стоек. Почему так? Потому что бесконечно копить батареи обычно не имеет смысла. Уже начиная с полуторного запаса начинаются сложности с их размещением (они травят водород, то есть нуждаются в своей вентиляции, им нужен свой климат-контроль, они очень тяжёлые, то есть давят на перекрытия). В ЦОДах высокой ответственности вместо свинцовых батарей используются ДДИБП — огромные волчки, вращающиеся в гелии или вакууме, которые крутят вал генератора. У нас такого в этом ЦОДе, естественно, не было. Если бы было — размещение было бы куда дороже, и логичнее было бы дублировать ЦОД целиком. Что, собственно, у нас сделано 14 раз.
Почему охрана не пускала админов в девять утра в субботу?
Потому что одна из главных фичей Королёва — это та самая охрана режимного объекта, которая не стесняется посылать на три буквы всех, кого нет в списках. То есть они как-то умудрились даже [данные удалены] лицом в пол [данные удалены] приехавших нас аттестовать [данные удалены]. Потому что они размахивали какими-то корочками и хамили.
В Останкино у нас, например, охрана — отдельным батальоном Росгвардии. Поверьте, туда не приедет никакой ретивый сотрудник МВД с документами на следственные действия по виртуальному серверу вынимать физический. А это известный российский риск: если рядом с вами стоят странные персонажи (а на любом крупном VDS-хостинге всегда есть доля таких клиентов, и я про это писал), то может приехать сотрудник и попытаться выдернуть сервер. А железо — оно не такое, что вот на этом сервере добрые, а на этом — злые. Оно общее. Мы по опыту коллег знаем, что самый быстрый возврат сервера по звонку начальника: «Ты что там такое творишь? Верни железку обратно!» — занимает пять часов даунтайма. Спасибо, такого не надо ни нам, ни нашим клиентам.
Поэтому охрана действовала ровно в рамках своих полномочий. Мы находимся на территории стратегического производства. С началом кое-каких событий тут очень поднялся уровень паранойи. Героев, желающих проскочить, потому что внутри что-то срочное, хоть отбавляй. Охрана — в нашем случае внешний периметр Росгвардии — пускает тех, кто есть в списке, и не пускает остальных. Аварийной команды в списке не было, им нужно было получить соответствующий приказ. В лица они нас знают прекрасно, но нет — правила есть правила! Как я уже говорил, они очень юзерфрендли, почти как UNIX. То, что нам надо обсудить, как пускать своих людей во время аварий, — это отдельный вопрос, его сейчас прорабатываем. Возможно, будем страховаться и выписывать дополнительные разовые пропуска каждую смену. Собственно, вы сейчас будете смеяться, но мы так и делали, просто не на всех, а на одного человека дополнительно на всякий случай, и как раз он смог приехать уже к концу инцидента.
Почему патрубок дизеля лопнул? Вы что, его не обслуживали?
Дизель обслуживается каждые полгода. В этот раз срок был даже меньше, потому что зимой мы стояли на дизелях сутки во время прошлого отключения питания от города. Каждый месяц мы проверяем дизели и топливо, но не под боевой нагрузкой из нашего машзала, а под синтетической.
Обычная практика ЦОДов нашего размера — резерв из N+1 дизелей. У нас был 2N, нужен 2N+1.
Как вы видите выше, даже Tier-IV ЦОДы не считают критичным подниматься до 2N+1.
Почему дизель чинили админы?
Потому что не было выбора: дизелист был снаружи. Естественно, админы не должны были этого делать, естественно, большое спасибо, что получилось. Админы — однозначно герои этой истории!
Почему на территории нет моториста постоянно?
Потому что при дублировании вторым вводом из города, дизелем, 2N дизелем и ИБП шанс, что понадобится моторист, исчезающе мал. Для предотвращения маловероятных рисков проще дублировать ЦОД, что, повторюсь, у нас и сделано 14 раз. Вообще каждый раз, когда встаёт вопрос повышения на 0,5 % шанса в случае аварии или при открытии новой площадки начиная с какого-то экономического порога лучше выбирать геораспределённость. Это же ответ про то, готовы ли мы запуститься после пожара топлива: нет, не готовы, мы потушимся штатно, но не перезапустим дизели в разумный срок. А вот что реально стоит пересмотреть — это режим работы вентиляции, нужны отдельные решения под неё.
Теперь — самое интересное. На каждые плановые работы или начало каждой аварии мы тут же зовём профессионалов с дизелем, который арендуем. То есть когда планируются работы на подстанции, у нас резерв 3N по дизелям (наши плюс привезённый мобильный) и мотористы в дежурстве. В данном случае ещё один дизель на 0,5 МВт и команда обслуживания прибыли и смогли попасть на территорию уже после включения луча из города.
Почему админы вручную включали оборудование?
«И «Админы бегали между стойками» — даже после отключения питания машины должны сами подниматься».
Как раз машины не должны сами подниматься. История знает слишком много ситуаций, когда несколько циклов включения-выключения по питанию разваливают рейды и ломается железо. У нас настроено так, что после нештатного отключения питания часть оборудования надо включать вручную осознанно. В обычное время, когда не надо зажимать руками патрубок дизеля, это очень хорошая практика. И нет, мы не собираемся менять её несмотря на произошедшую ситуацию. Это как с ремнём в машине: есть незначительный процент аварий, когда пристёгнутый ремень хуже, чем непристёгнутый. Но статистически верно пристёгиваться, если задача — выжить.
Были ли потери данных?
Нет, рейды не сыпались. Если не считать нештатных перезагрузок и потерь того, что было в оперативной памяти, всё остальное более-менее нормально (насколько мы знаем).
Почему вы не сделали всё, чтобы предотвратить аварию?
На самом деле мы сделали всё, что казалось вероятным и при этом укладывалось в экономическое обоснование. По каждому риску вы делаете следующее: оцениваете его вероятность, а также ущерб от него и решаете, сколько вы готовы потратить на предотвращение. И, соответственно, оцениваете, насколько его можно предотвратить за этот бюджет. Исходя из этой модели очень хорошо закрываются наиболее вероятные риски и куда хуже — маловероятные. К нашествию пришельцев, высаживающихся в ЦОД, мы не готовы. Эта ситуация с цепочкой из пяти совпадений подряд — на самом деле тот же класс риска.
Как я уже говорил, мы исходили из двух неверных допущений в оценке рисков: что резервировать дизели надо по 2N, а не 2N+1 (уже исправили), и что DDoS-защита (за которой был мониторинг серверов) не нуждается в кластере коммутаторов, если есть один надёжный онлайн и один точно такой же в шкафу через 20 метров от стойки. Ну и главный косяк — мониторинг должен быть геораспределён, это мы знали, но не успели сделать.
От каких рисков вы защитились тогда, например?
Мы прекрасно отработали несколько прошлых рисков: и санкционные отключения оплат, и отзыв лицензии у банка с платёжным шлюзом, и крупные атаки прошлого года. У нас нет желания экономить на рисках, но у всего есть разумные пределы.
Например, мы очень долго занимались сетевыми драйверами и писали свои, а затем сертифицировали их в Microsoft (ну с последней версией уже не выйдет, а вот предыдущие сертифицированы и лежат в каталоге ПО гипервизора).
После общения с другими хостинг-провайдерами могу сказать, что ситуация с сетью у нас очень хорошая. Именно в Королёве у нас огромная плотность вычислительных машин — это из-за 30-рублёвых промотарифов. И у нас там порядок в сети. При последней большой DNS-атаке, затронувшей всю страну (привет, домены Битрикса!), пострадали, кажется, вообще все наши знакомые. У нас же только два человека хоть как-то пострадали среди всех клиентов. Два человека, Карл! Мне кажется, что это лучший показатель порядка в сети.
Мы предотвратили очень много инцидентов, направленных не в наш карман, а в сторону клиента, благодаря правильным ACL, драйверам и т. п. У этого есть оборотная сторона: в субботу не могли быстро включить коммутатор на замене вместо выгоревшего. Теперь продумаем и это, скорее всего, построим кластер.
В целом по этой аварии вопрос такой: «Действовал бы я точно так же, если бы мог вернуться в прошлое?» Ответ: «Скорее всего, да». Без проклятия знания все действия ДО были рациональными.
Почему вы пишете про такие вещи?
«Вот за такие триллеры вам можно простить горы проходного шлака, который обычно публикуется в этом блоге. Побольше бы таких историй! ;)»
Мы открыто рассказываем про все ситуации, которые влияют на хостинг. Да, мы прекрасно понимаем, что в России так не принято. Да, мы прекрасно понимаем, что из-за этого открывается много приподзакрытых глаз, не знающих, как всё изнутри. Да, мы понимаем, что другие хостинги, утаивающие детали про то, что у них происходило и происходит, до какого-то момента надёжнее смотрятся со стороны. Тем не менее моё осознанное решение как владельца компании — долговременная репутация. Если уж мы лажаем, то рассказываем об ошибке. Мы тут не на пару дней и вроде до этого момента более-менее успешно избегали серьёзных косяков.
«Захватывающая статья! Очень импонирует то, что вы открыто говорите о своих косяках. Думаю, что даже у недовольных отключением пользователей её прочтение повысит доверие к вам».
Если быть честными, то скорее наоборот. Это вот вторая публикация про менее чем 0,5 % клиентов хостинга, но при этом выглядящая так, как будто всё произошло по всему гриду. Но я очень надеюсь на то, что наши клиенты — всё же рациональные люди.
Как себя чувствуют админы?
С моей точки зрения, они герои той ночи! Но, тем не менее, они довольно сильно подавлены, потому что успели прочитать комментарии и чаты. Каждый раз возникает ощущение, что ты что-то недоработал, и при любой аварии ответственный человек начинает корить себя. Наши админы как раз очень ответственные, и ЦОД — их детище во многом. Естественно, они расстроены. Более того, мы с командой очень долго обсуждали, нужно ли публиковать материал про эту аварию второй раз: это ведь ещё один удар по ним фактически. Представьте себя сейчас на их месте: ощущение будет не из приятных. Полагаю, что девопсы и админы, которые знают, что у них в инфраструктуре что-то ещё неидеально (а это постоянное чувство, и оно сохраняется годами), это поймут.
ruvds.com