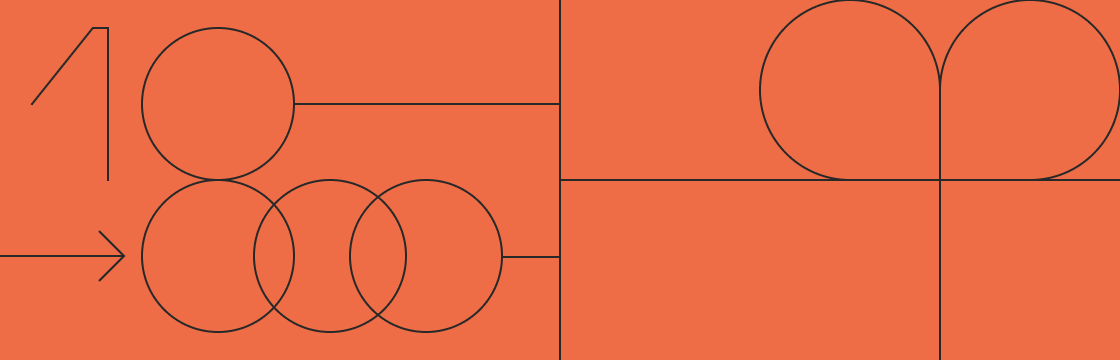
Хотя праздничный сезон, возможно, не всегда связан с числами — а скорее с тем, чтобы не думать о них некоторое время — они все еще всплывают здесь и там. Будь то мощность GPU, которую вы планируете на следующий год, или сколько миллиардов параметров вы будете использовать в своей следующей модели, числа ведут нас в 2025 год. Вот некоторые цифры, над которыми мы размышляем в эти дни — сохраняя при этом чувство веселья.
Наш недавний инвестиционный раунд указывает путь к светлому будущему, и мы рады приветствовать в составе нашей компании в качестве новых акционеров нескольких престижных инвесторов.

Эти 700 миллионов долларов пополнят наши собственные сбережения и дадут нам больше возможностей для инвестиций в создание инфраструктуры ИИ по всему миру…

…при этом никогда не забывая о своих корнях. Первый центр обработки данных Nebius в Финляндии, наша домашняя база, был полностью построен нами самостоятельно, с тщательным вниманием к конструкции здания, адаптацией его к нашим внутренним серверам и конструкциям стоек. И мы структурировали его не только для экономической эффективности, но и в очень финском стиле — с сауной на месте.

Это может показаться довольно горячим — надо признать, что большинство сотрудников предпочитают температуру ближе к 80–100 °C.
Говоря о тепле, мы используем избыточное тепло от наших серверов с пользой, перенаправляя его в близлежащий город Мянтсяля.

Трубы, по которым поступает тепло, конечно, не единственная часть коммуникаций центра обработки данных. Для поддержки многохостового обучения для наших клиентов мы полагаемся на InfiniBand. Фактически, общая длина оптических кабелей, установленных в наших центрах обработки данных, охватывает все расстояние от нашей штаб-квартиры в Амстердаме до Рима.

Конечно, мы посетили Рим в 2024 году, чтобы продвигать Nebius – вместе с 26 другими городами в Соединенных Штатах, Европе, Азиатско-Тихоокеанском регионе и за его пределами. Вы найдете нас на конференциях по ИИ по всему миру, готовых поддержать участников, где бы они ни находились.

Поддержка означает не только предоставление инфраструктуры GPU, но и заботу о людях в теплой и вдумчивой манере. Если количество ваших носков нечетное, ну… это, конечно, то, чего никогда не случалось с нами.

Посещение конференций по всему миру не означает, что у нас нет ключевых достопримечательностей. Наши рекламные щиты в районе залива привлекли много внимания — именно то, чего мы хотели.

Если мы так смелы в маркетинге, насколько сильны наши технологические основы? Один из способов измерить это — через портфель патентов. Эти цифры показывают, что мы не просто строим инфраструктуру ИИ, как другие, кто был до нас. Вместо этого мы продвигаем технологии, чтобы продвигать отрасль вперед.

Nebius привносит дополнительную технологическую ценность в эту область. Как еще можно описать платформу облачных вычислений, переписанную с нуля менее чем за год? Мы владеем каждой частью технологического стека Nebius, и каждая строка кода — наша собственная. Мы считаем, что это делает Nebius по-настоящему уникальным в мире облаков.

Помимо облака мы также запустили Nebius AI Studio, которая предоставляет разработчикам приложений GenAI конечные точки для десятков самых популярных моделей с открытым исходным кодом, а также некоторые более специализированные предложения. Они не ограничиваются LLM, но также включают модели машинного зрения. AI Studio уже производит фурор на рынке вывода.

Расширение нашего портфолио такими технологическими продуктами требует тесного сотрудничества между командами, особенно при росте в нескольких странах. Чтобы оставаться на связи, мы полагаемся на Zoom для трансграничной командной работы.

После продуктивных мозговых штурмов, как онлайн, так и офлайн, о том, как сделать жизнь разработчиков ИИ еще проще, мы прилагаем все усилия, чтобы восстановить связь с нашими семьями. Экологичный способ добираться на работу — велосипед — очень амстердамское занятие.

Вот и все наши цифры на 2024 год! Теперь пора подумать о том, как достичь еще более впечатляющих показателей в 2025 году. Если покорение мира ИИ также входит в ваши планы на следующий год, вы знаете, где найти инфраструктуру. И носки.
nebius.com
studio.nebius.ai/playground
console.eu.nebius.com