40% доменов и 20% размещённых сайтов в .RU: новые вершины REG.RU на рынке хостинга и доменов
Представляем обзор рынка хостинг-услуг и регистрации доменов: рейтинг провайдеров и регистраторов в зоне .RU, скорость, аптайм и другие показатели. По ключевым метрикам REG.RU удерживает позиции и наращивает показатели.
Лидеры хостинга
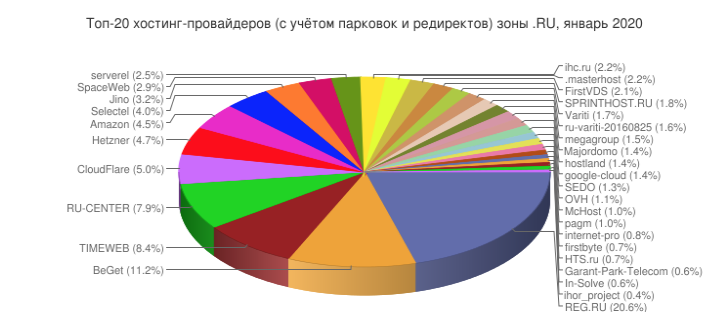
По данным аналитического ресурса StatOnline.ru, REG.RU продолжает занимать первую позицию среди хостинг-провайдеров зоны .RU, увеличив за 2019 год долю размещаемых сайтов до 20%. На втором месте компания Beget с долей 11%. Timeweb занимает третью позицию с 8,40%. Замыкают пятёрку Ru-Center (8%) и SEDO (5,4%).
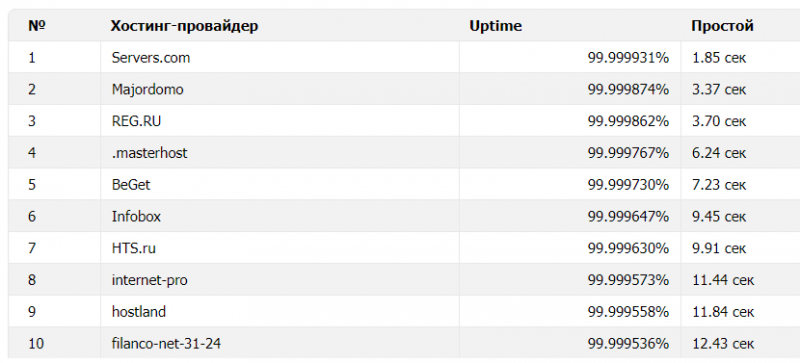
Стоит рассмотреть и несколько других метрик. По показателю uptime (время непрерывной работы услуги, общепринятая оценка надёжности сервиса хостинга) первое место у Servers.com — 1,85 секунды, а второе с результатом 3,37 секунды у Majordomo. На третьем месте REG.RU — 3,70 секунды. Сразу за ним компания .masterhost у которой 6,24 секунды.
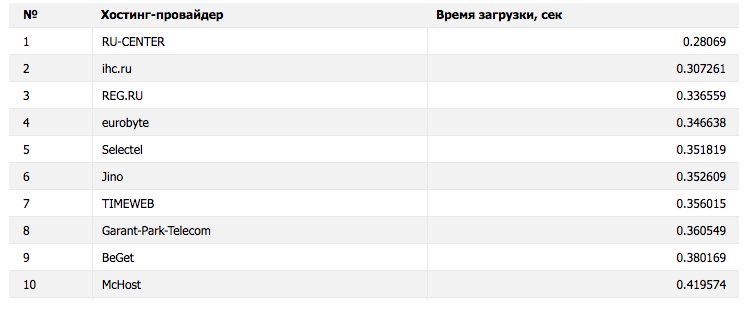
По скорости загрузки клиентских сайтов лидирует Ru-Center: у него 0,28 секунды. На втором месте ihcru — 0,30 секунды. Незначительное отличие у REG.RU — 0,33 секунды. Четвёртое и пятое место занимают Eurobyte и Selectel.
Лидеры регистрации доменов
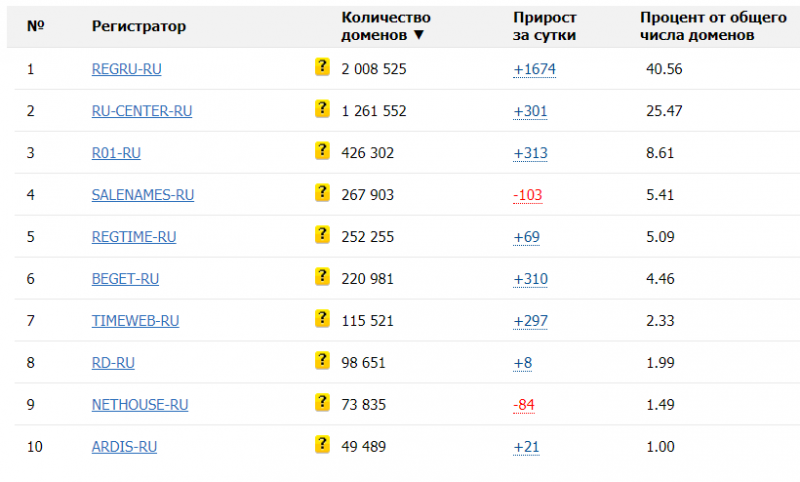
В рейтинге регистраторов доменов в зоне .RU, по данным StatOnline.ru, лидирующая позиция у REG.RU — 40%. За год цифра выросла почти на 2%. На второй позиции Ru-Center c долей 25,5%, которая за 12 месяцев, напротив, снизилась на 1,5%. Третье место у R01-RU с 8,61%. На четвёртой позиции — Salenames.ru (5,41%), на пятой — Webnames (Regtime.ru) — 5,09%.
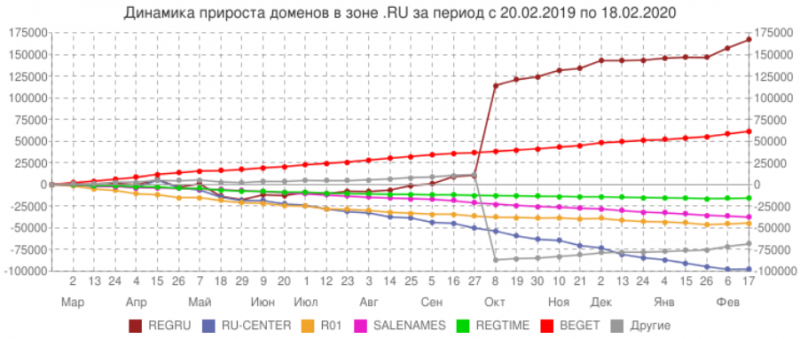
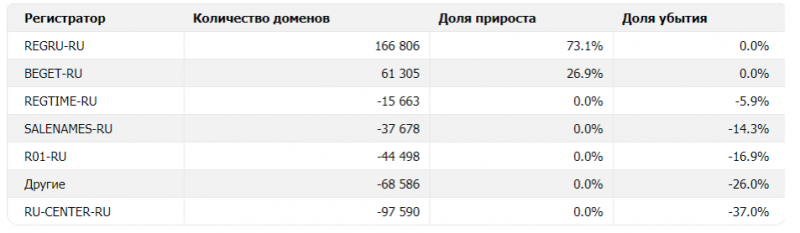
По динамике прироста доменов лидерство у REG.RU: доля компании за год составила 73% (167 тысяч доменов). Более скромные показатели у Beget — 26,9% (61 тысяча доменов) и Webnames (Regtime.ru) — 0% (-15 тысяч доменов).
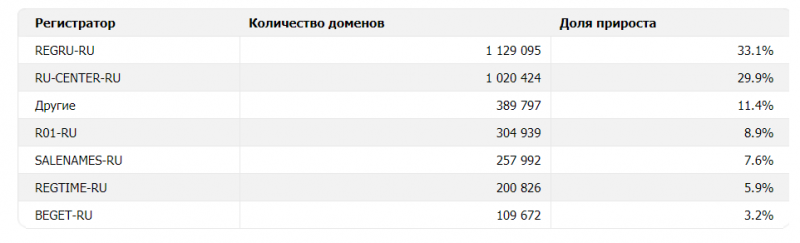
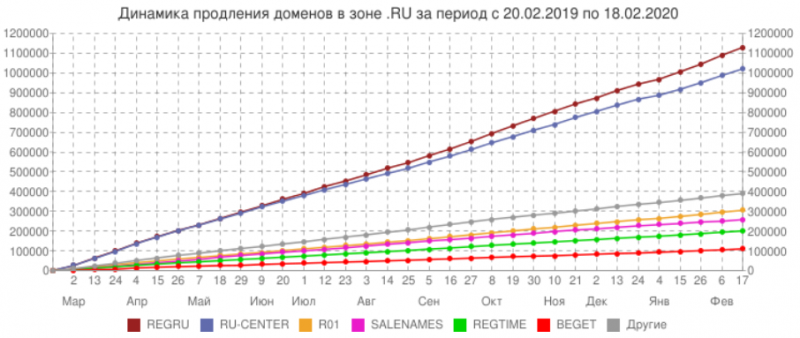
По динамике продления доменов первое место также у REG.RU с долей 33%.
Лидеры хостинга
По данным аналитического ресурса StatOnline.ru, REG.RU продолжает занимать первую позицию среди хостинг-провайдеров зоны .RU, увеличив за 2019 год долю размещаемых сайтов до 20%. На втором месте компания Beget с долей 11%. Timeweb занимает третью позицию с 8,40%. Замыкают пятёрку Ru-Center (8%) и SEDO (5,4%).
Стоит рассмотреть и несколько других метрик. По показателю uptime (время непрерывной работы услуги, общепринятая оценка надёжности сервиса хостинга) первое место у Servers.com — 1,85 секунды, а второе с результатом 3,37 секунды у Majordomo. На третьем месте REG.RU — 3,70 секунды. Сразу за ним компания .masterhost у которой 6,24 секунды.
По скорости загрузки клиентских сайтов лидирует Ru-Center: у него 0,28 секунды. На втором месте ihcru — 0,30 секунды. Незначительное отличие у REG.RU — 0,33 секунды. Четвёртое и пятое место занимают Eurobyte и Selectel.
Лидеры регистрации доменов
В рейтинге регистраторов доменов в зоне .RU, по данным StatOnline.ru, лидирующая позиция у REG.RU — 40%. За год цифра выросла почти на 2%. На второй позиции Ru-Center c долей 25,5%, которая за 12 месяцев, напротив, снизилась на 1,5%. Третье место у R01-RU с 8,61%. На четвёртой позиции — Salenames.ru (5,41%), на пятой — Webnames (Regtime.ru) — 5,09%.
По динамике прироста доменов лидерство у REG.RU: доля компании за год составила 73% (167 тысяч доменов). Более скромные показатели у Beget — 26,9% (61 тысяча доменов) и Webnames (Regtime.ru) — 0% (-15 тысяч доменов).
По динамике продления доменов первое место также у REG.RU с долей 33%.
Сегодня в числе аккредитованных регистраторов доменов .RU и.РФ — 52 компании. А работающих на российском рынке хостинг-провайдеров — ещё больше. Конкуренция — стимул повышать собственную планку, развивать продукты и сервис, прислушиваться к клиенту и делать всё для его комфорта. Одним из таких шагов с нашей стороны стал пересмотр тарифов и снижение цен на shared-хостинг. Кроме того, именно с целью повышения качества сервиса хостинг-услуг мы дополнили аналитический ресурс StatOnline.ru метриками аптайм и скорость, которые позволяют пользователям выбирать самых надёжных провайдеровкомментирует генеральный директор REG.RU Алексей Королюк.