2 days ago, we got the biggest DDoS
2 days ago, we got the biggest DDoS never received
>1.2Tbps during 2-3 hours.
>1.2Tbps during 2-3 hours.




Это стоит выбрать Private Cloud, когда мы ожидаем, что услуга опередит потребности бизнеса, чтобы быстро освободить необходимые ресурсы и создать возможности. Мы также ценим надежность, масштабируемость и простоту управления инфраструктурой с помощью Private Cloud, особенно в географически распределенных средахMichał Maciejewski, администратор инфраструктуры ИТ для Европы
Одна компания» — Повышенная производительность на всех уровняхMIGR


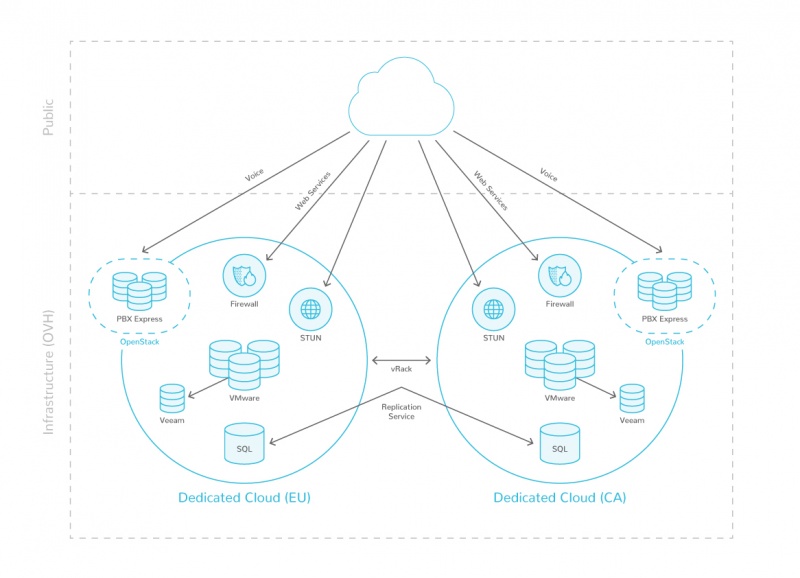
Теперь наша ИТ-команда способна управлять всеми нашими ИТ-услугами по фиксированному бюджету. Когда возникнет такая необходимость, мы можем легко реагировать на растущий спрос и вносить необходимые изменения в любое времяСтефан Вальтер, руководитель службы поддержки и поддержки клиентов
В последние годы спрос на что-либо в облаке, а не только на АТС, быстро растет. Мы увидели это изменение и предсказали, что оно будет применяться к нашей отрасли, и мы ответили соответственно, чтобы обслуживать облачный рынокСтефан Вальтер, руководитель службы поддержки и поддержки клиентов


Я очень доволен нашим решением принять OVH в качестве нашего основного глобального центра обработки данных и сетевой инфраструктуры. Наши первоначальные проекты обеспечили немедленные, измеримые преимущества для нашего основного бизнеса в то время, когда мы быстро выходим на рынок. Это служит хорошим предзнаменованием для будущегоАшока Редди — основатель и генеральный директор wokati Technologies UK
Многие компании вкладывают средства в большие серверы, на которых они могут расти (например, носить мешковатые брюки, когда мы дети!), Но большинство компьютеров работают с пропускной способностью до 30%, а по размеру хранилища они, вероятно, используют только небольшой процент, люди платят за пустое пространство, но с OVH и виртуализацией они не нуждаются в этом, потому что мы заполняем серверы до макс. И благодаря виртуализации у нас есть неотъемлемо зеленая технология, так как она много стоит для работы центра обработки данныхАшока Редди, основатель и генеральный директор wokati Technologies UK
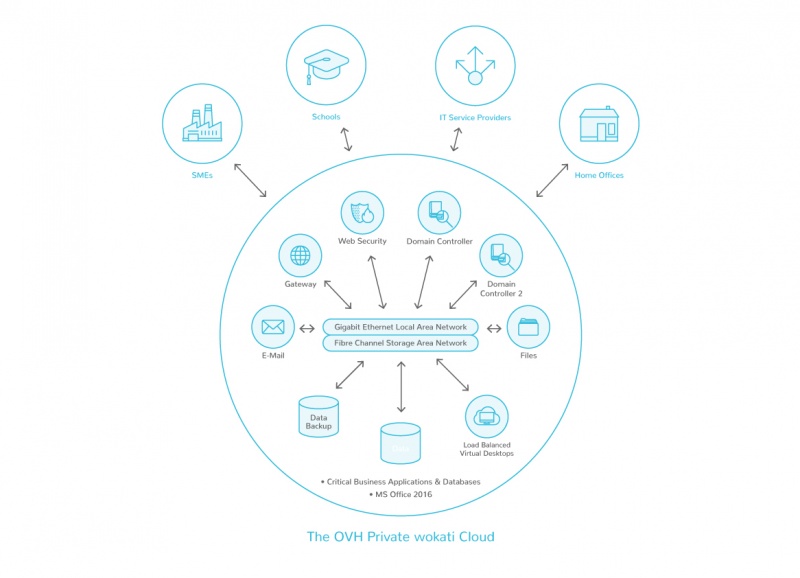
Важно то, что отношения с OVH — наше техническое партнерство на высоком уровне — потому что мы собираемся сделать пожизненную приверженность сейчас. В этой связи я вижу, что наш рост является совокупным ростомАшока Редди, основатель и генеральный директор wokati Technologies UK

Мы видим, что цифровизация и интернационализация являются основными тенденциями, которые должны решать Villeroy & Boch. Все больше и больше людей делают покупки онлайн и используют свои смартфоны для поиска магазинов поблизостиПаскаль Рейнерт, руководитель CIT, Интернета и электронного бизнеса, Villeroy & Boch
Для нас крайне важно оцифровать всю [среду] — систематически продвигать центральные системы с соответствующими данными, продуктами, запасами и заказами… и устанавливать новые каналы продаж, не пренебрегая существующимиПаскаль Рейнерт, руководитель CIT, Интернета и электронного бизнеса, Villeroy & Boch


Каждый вечер более 8500 точек, расположенных по всему миру, подключаются к нашей инфраструктуре для загрузки плейлистов на следующий день, поэтому мы хотели полагаться на сильного партнера для управления инфраструктурой RadioShopТомас Бержерот, соучредитель и главный исполнительный директор, RadioShop
Мы способны синхронизировать разные файлы в разных точках присутствия во всем мире таким образом, чтобы уменьшить задержку и пропускную способностьТомас Бержерот, соучредитель и технический директор, RadioShop


Я считаю, что мы первая компания, которая представила этот технологический канал, от физических измерений животных до предоставления цифровых услуг фермерам. Это, безусловно, цифровой переходЖан-Пьер Лемоннье, президент Medria Technologies
Внешняя инфраструктура с таким провайдером, как OVH, позволила нам воспользоваться дополнительным уровнем безопасности (на уровне сети) и источником питанияСтефан Годин, менеджер по разработке программного обеспечения, Medria Technologies