

Важные обновления о вашей учетной записи продаж Leaseweb Нидерланды B.V.

В рамках нашего стремления постоянно улучшать качество обслуживания клиентов и уровень предоставляемых нами услуг, мы обновляем наши системы до новой и усовершенствованной коммерческой системы. Это позволит нам обеспечить вам бесперебойный процесс заказа, единый на нашем веб-сайте, клиентском портале Leaseweb, а также поддержку со стороны наших отделов продаж. Чтобы вы могли использовать эту расширенную систему, мы продолжим административные изменения вашей существующей учетной записи для этой новой системы Commerce.
С 17 июня 2024 г. вы заметите некоторые изменения в своей учетной записи Leaseweb Нидерланды BV.
КАКИЕ ИЗМЕНЕНИЯ?
Вы можете быть уверены, что это административное изменение в нашей новой системе не окажет никакого влияния на ваши Услуги. Вы заметите только следующие изменения в вашей существующей учетной записи:
Номер заказа/идентификатор услуги: существующие номера заказа/идентификаторы услуги изменятся. Это будет видно на Портале для клиентов, в ваших предстоящих счетах и в наших сообщениях.
Это изменение применимо только к вашей учетной записи Leaseweb Нидерланды BV. Если у вас есть договор(ы) купли-продажи с другими торговыми организациями Leaseweb, вы будете уведомлены отдельно, как только такое изменение будет реализовано в других ваших учетных записях.
Обратите внимание, что с 12 июня 17:00 (CEST) по 17 июня 08:00 (CEST) 2024 г. вы не сможете вносить какие-либо изменения в свой контракт Leaseweb Нидерланды BV через клиентский портал Leaseweb. В течение этого времени вы также не сможете размещать новые заказы на нашем веб-сайте/портале для клиентов.
Новые планы Hetzner Cloud уже здесь


Информационный бюллетень HETZNER
Мы рады сообщить вам о наших новых продуктах и новостях компании.
Наслаждайся чтением!
ПОЛУЧИТЕ ВАУ-ЭФФЕКТ: НОВЫЕ ОБЛАЧНЫЕ ПЛАНЫ ЗДЕСЬ
Всего за несколько секунд вы сможете развернуть один из наших четырех новых планов общего облака виртуальных ЦП. Они основаны на процессорах Intel, и их высокая производительность впечатляет вас почти так же, как и их привлекательная цена.
Самый маленький план, CX22, включает в себя 2 виртуальных ЦП, 4 ГБ ОЗУ и 40 ГБ дискового пространства, и все это по непревзойденной цене всего 3,79 евро в месяц или 0,0060 евро в час. Далее идет CX32 с 4 виртуальными ЦП, 8 ГБ ОЗУ и 80 ГБ дискового пространства всего за 6,80 евро в месяц (0,0113 евро в час).
Далее следует CX42 с 8 виртуальными ЦП, 16 ГБ ОЗУ и 160 ГБ дискового пространства за 16,40 евро в месяц (0,0273 евро в час).
И последнее, но не менее важное: CX52 с 16 виртуальными ЦП, 32 ГБ ОЗУ и 320 ГБ дискового пространства по потрясающей цене всего 32,40 евро в месяц (0,0540 евро в час). Кроме того, все эти планы включают 20 ТБ трафика и 1 IPv4-адрес.
Поскольку эти планы общего облака распределяют ресурсы ЦП, они идеально подходят для сред разработки и тестирования, блогов, форумов, CMS, небольших баз данных и VPN-серверов. А если ваши требования изменятся в будущем, вы можете просто масштабировать свой сервер вверх или вниз и даже автоматизировать масштабирование с помощью нашего API.
Оплата также является гибкой. Все наши облачные планы не предусматривают минимального срока действия контракта. В зависимости от того, как долго вы используете сервер, вы можете платить почасово или помесячно. Мы всегда взимаем с вас меньшую сумму из этих двух вариантов.
Используя отмеченный наградами, удобный и интуитивно понятный дизайн Hetzner Cloud, вы сможете воплотить свои мечты в реальность, быстро и легко реализуя свои проекты. И вы можете быть спокойны, зная, что новые планы, размещенные в центрах обработки данных Hetzner в Германии и Финляндии, соответствуют Общему регламенту ЕС по защите данных, GDPR.
www.hetzner.com/cloud/
ВЫ ЗНАЛИ? Жесткий диск емкостью 22 ТБ ДОПОЛНИТЕЛЬНО ДЛЯ ВЫДЕЛЕННЫХ СЕРВЕРОВ AX И EX-LINE
Теперь у вас есть возможность добавить жесткий диск SATA Enterprise емкостью 22 ТБ к любому выделенному серверу AX и EX. Вы можете получить все это дополнительное пространство всего за 27,00 евро в месяц или 0,0433 евро в час.

ОБНОВЛЕНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ УПРАВЛЯЕМЫХ СЕРВЕРОВ И СЧЕТЫ ВЕБ-ХОСТИНГА
Ваши файлы, приложения и службы остаются доступными только до тех пор, пока ваш сервер работает стабильно, безопасно и надежно. Чтобы обеспечить бесперебойную работу всех наших управляемых серверов и учетных записей веб-хостинга, мы будем регулярно обновлять их программное обеспечение до новой версии Debian 12 Bookworm.
Затронутые клиенты заранее получат электронное письмо с дополнительной информацией. Все новые заказы будут автоматически поступать с новым выпуском Debian 12 Bookworm.

ПОГОВОРИТЕ С НАМИ НА ВСЕМИРНОМ КОНГРЕССЕ «МЫ РАЗРАБОТЧИКИ»
Всемирный конгресс WeAreDevelopers — одно из главных событий для программистов на планете.
Более 15 000 разработчиков программного обеспечения, DevOps-инженеров, владельцев продуктов и архитекторов программного обеспечения соберутся в Берлине 17-19 июля 2024 года, чтобы узнать больше и обсудить текущие разработки и будущие тенденции в динамичном мире разработки программного обеспечения.
Мы будем там в качестве экспонента и будем рады интересным беседам с вами на нашем стенде (номер 2_47).
www.wearedevelopers.com/world-congress
ОБУЧЕНИЕ: НАСТРОЙКА КЛАСТЕРА KUBERNETES ДЛЯ ОБЛАКА HETZNER С ПОМОЩЬЮ TERRAFORM
В этом руководстве вы узнаете, как настроить собственный масштабируемый кластер Kubernetes с помощью поставщика Terraform для Hetzner Cloud. В руководстве подробно рассматриваются настройка, масштабирование и доступ к кластеру.
Кроме того, здесь объясняется, как рассчитать стоимость кластера и оптимизировать его работу, чтобы можно было эффективно использовать ресурсы.
Поставщик Terraform для Hetzner Cloud находится в репозитории Hetzner Cloud на GitHub и регулярно обновляется.
community.hetzner.com/tutorials/setup-your-own-scalable-kubernetes-cluster
github.com/hetznercloud/terraform-provider-hcloud
Сотрудничество с La Strada Moldova: PQ.Hosting создаёт безопасное онлайн-пространство

Мы рады объявить о партнерстве с международным центром «La Strada Moldova» в борьбе с сексуальным насилием над детьми в онлайн-пространстве. Подписав соглашение о сотрудничестве, мы присоединяемся к важной миссии создания безопасной виртуальной среды для наших детей.
Республика Молдова занимает топ-10 стран, в которых размещаются материалы ненадлежащего характера. Команда PQ.Hosting стремится к изменениям и выражает надежду, что наше участие заразит другие компании проявить социальную ответственность и присоединиться к этой важной работе.
Сайт siguronline.md предоставляет платформу для анонимной и конфиденциальной подачи сообщений о материалах о сексуальном насилии над детьми. Ресурсы, предоставляемые интернетом, могут использоваться для благих целей, и мы поощряем сообщество к активному участию в этом процессе.
Наше партнерство с «La Strada Moldova» и участие в глобальной сети INHOPE — International Association of Internet Hotlines открывает новые возможности для совместного преодоления проблемы сексуального насилия над детьми в онлайн-пространстве. Мы гордимся своим вкладом в создание безопасного интернета для будущих поколений.
pq.hosting
Новая Панель управления 1cloud
В мае мы провели масштабное обновление Панели управления 1cloud. Над этим редизайном мы трудились с прошлого года, и наконец-то вы можете оценить результат проделанной работы.
Ниже мы подробно расскажем о самых важных изменениях, но сначала перейдите в новую версию по кнопке «Новая панель» в правом верхнем углу личного кабинета.

Дашборд с виджетами на главной странице
Теперь в Панели управления есть полноценная главная страница, где расположен дашборд с виджетами. Виджет содержит основную информацию по каждой услуге, его можно перемещать по странице и скрывать, если вы не пользуетесь конкретной услугой. Кроме этого, через виджет вы можете перейти на страницу заказа некоторых услуг — добавить новый виртуальный сервер или ЦОД, выбрать и зарегистрировать домен, настроить диск для хранения данных. Удобно следить за балансом всего проекта и расходом ресурсов по каждой активной услуге.

Персонализировать дашборд можно как в разных проектах, так и в одном проекте под каждого пользователя. Скрывать и добавлять виджеты можно не только по иконке зачеркнутого глаза в самом виджете, но и через раскрывающийся список по кнопке в правом верхнем углу «Настроить дашборд». Так открывается полный список всех услуг, которые можно добавить в дашборд или убрать.
Ниже виджетов расположен блок с нашими рекомендациями по дополнительным настройкам профиля, полный список доступных для заказа услуг, полезный статьи из FAQ и последние новости 1cloud. Кстати, рекомендуем следить за нашими новостями, чтобы не упустить новый промокод.
Новый дизайн Панели управления
Полностью обновленный дизайн сделал Панель управления более современной и интуитивно понятной. Все элементы стали аккуратнее, а их расположение более оптимальным.
Документация и заказные работы. Разделы «Заказные работы», «Документация», «FAQ» теперь вынесены в боковое меню. Если раньше попасть в документацию или заказать работы можно было только через раздел «Поддержка», то теперь это делается по одному клику. Боковое меню, кстати, можно свернуть.
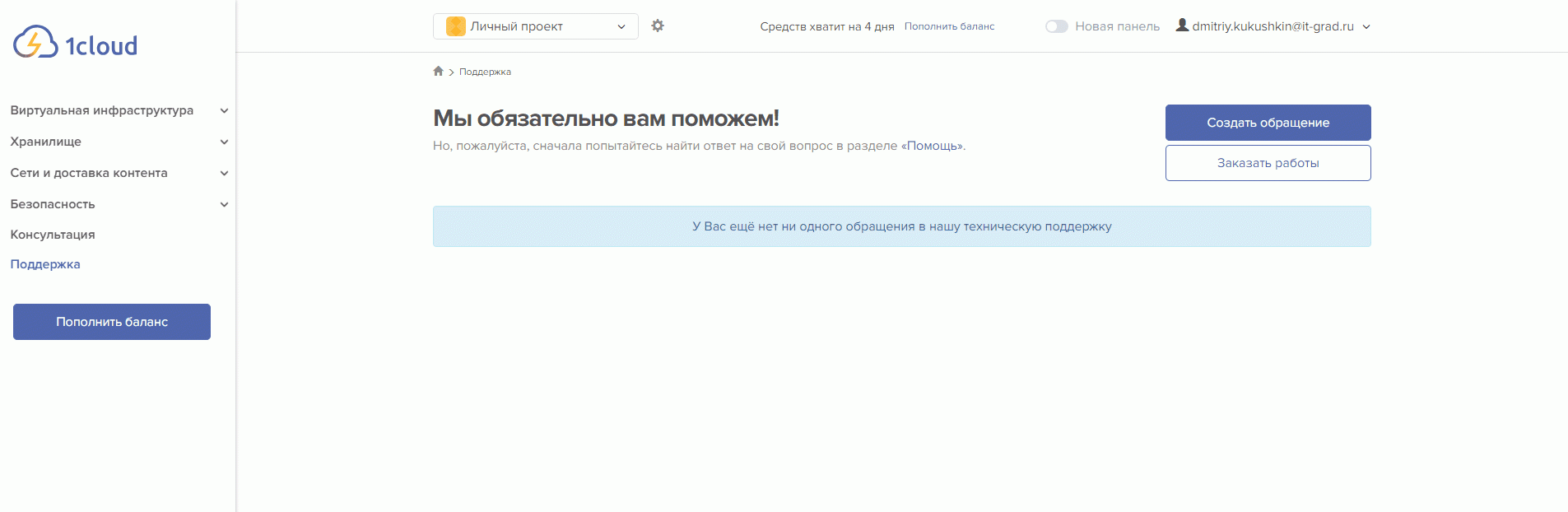
Страница баланса. Разбивка по счетам стала информативней, можно одной кнопкой подключить автоплатеж или перейти на страницу сайта с детальными условиями оплаты. История по операциям доступна за 3 месяца, год или за все время работы в 1cloud.
1cloud.ru
Ниже мы подробно расскажем о самых важных изменениях, но сначала перейдите в новую версию по кнопке «Новая панель» в правом верхнем углу личного кабинета.
Дашборд с виджетами на главной странице
Теперь в Панели управления есть полноценная главная страница, где расположен дашборд с виджетами. Виджет содержит основную информацию по каждой услуге, его можно перемещать по странице и скрывать, если вы не пользуетесь конкретной услугой. Кроме этого, через виджет вы можете перейти на страницу заказа некоторых услуг — добавить новый виртуальный сервер или ЦОД, выбрать и зарегистрировать домен, настроить диск для хранения данных. Удобно следить за балансом всего проекта и расходом ресурсов по каждой активной услуге.
Персонализировать дашборд можно как в разных проектах, так и в одном проекте под каждого пользователя. Скрывать и добавлять виджеты можно не только по иконке зачеркнутого глаза в самом виджете, но и через раскрывающийся список по кнопке в правом верхнем углу «Настроить дашборд». Так открывается полный список всех услуг, которые можно добавить в дашборд или убрать.
Ниже виджетов расположен блок с нашими рекомендациями по дополнительным настройкам профиля, полный список доступных для заказа услуг, полезный статьи из FAQ и последние новости 1cloud. Кстати, рекомендуем следить за нашими новостями, чтобы не упустить новый промокод.
Новый дизайн Панели управления
Полностью обновленный дизайн сделал Панель управления более современной и интуитивно понятной. Все элементы стали аккуратнее, а их расположение более оптимальным.
Документация и заказные работы. Разделы «Заказные работы», «Документация», «FAQ» теперь вынесены в боковое меню. Если раньше попасть в документацию или заказать работы можно было только через раздел «Поддержка», то теперь это делается по одному клику. Боковое меню, кстати, можно свернуть.
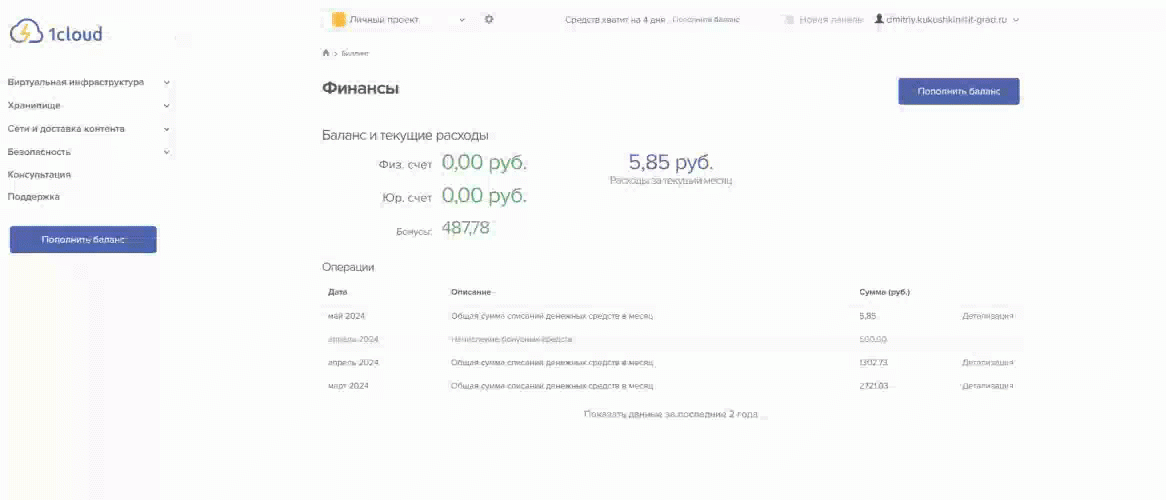
Страница баланса. Разбивка по счетам стала информативней, можно одной кнопкой подключить автоплатеж или перейти на страницу сайта с детальными условиями оплаты. История по операциям доступна за 3 месяца, год или за все время работы в 1cloud.
1cloud.ru
Масштабируемые и мощные серверы по цене от 18,08 долларов США в месяц

Если вы пропустили наше предыдущее письмо, теперь вы можете получить SC2 со значительной скидкой и другие предстоящие предложения в июне. Мега распродажа будет доступна в течение ограниченного времени или до тех пор, пока не закончатся запасы.
Предложение MCS24-SC2-1
4 ядра виртуального ЦП
8 ГБ выделенной оперативной памяти
220 ГБ чистого твердотельного накопителя
В хранилище RAID-10
Пропускная способность 6 ТБ/мес при скорости 1 Гбит/с
1x IPv4 и 3x IPv6
Лос-Анджелес, США
Пожизненное повторяющееся предложение
$18,08/месяц
app.cloudcone.com/compute/1438/create?token=mcs24-sc2-1
Опробуйте предложение SC2 — Scalable Cloud Computes. Наш Premium SC2 построен на базе процессоров Intel и твердотельного накопителя с улучшенной оптимизацией; эти планы также включают круглосуточную полностью управляемую облачную поддержку, моментальные снимки, автоматическое резервное копирование и множество других функций по сравнению с нашей аналогичной линейкой продуктов «Бюджетный VPS».
hello.cloudcone.com/clearance-sale-sc2-2024/
Leaseweb объявляет о проекте европейского облачного кампуса, который будет способствовать развитию европейской суверенной облачной инфраструктуры

Амстердам, Нидерланды, 5 июня 2024 г. – Leaseweb, ведущий поставщик облачных услуг и инфраструктуры как услуги (IaaS), объявляет о запуске инициативы European Cloud Campus. Эта инициатива реализуется в рамках программы «Важные проекты, представляющие общеевропейский интерес в области облачной инфраструктуры и услуг следующего поколения» (IPCEI CIS), и призвана стимулировать развитие европейского суверенного облака.
Отмечая свой 27-летний опыт работы в отрасли, голландские корни и штаб-квартиру, компания Leaseweb гордится тем, что играет значительную роль в крупнейшем на сегодняшний день европейском проекте облачной инфраструктуры. В рамках IPCEI CIS 100 европейских компаний из 12 государств-членов создадут общую облачную и периферийную инфраструктуру для Европы. Инициатива European Cloud Campus знаменует собой существенный шаг вперед на пути Leaseweb к созданию настоящего европейского суверенного облака. Это предоставит компаниям возможность использовать эту технологию для создания инновационных приложений, уделяя приоритетное внимание постоянному местонахождению данных и более простому соблюдению европейских правил.
Европейский облачный кампус очень хорошо вписывается в существующие разработки Leaseweb. Целью компании является предоставление услуг, которые являются хорошо масштабируемыми, энергоэффективными, автоматизированными, вертикально интегрированными и способны обеспечить эффективную мультиарендность. Это создаст процветающую экосистему для развития технологий в Европе. Это также обещает положительное экономическое и социальное воздействие в Европе. Благодаря сотрудничеству с неправительственными организациями, программам обучения для новых экспертов по облачным технологиям и партнерству с университетами эта инициатива направлена на создание рабочих мест и инвестиции в развитие квалифицированных специалистов, стимулируя инновации и предпринимательство.
Для нас очень важно стать лидером в создании европейского облака с помощью инициативы European Cloud Campus, Это демонстрирует нашу приверженность инновациям и нашу приверженность работе с партнерами и проектами с открытым исходным кодом. Благодаря этой инфраструктуре компании могут разрабатывать приложения искусственного интеллекта и облачные технологии прямо здесь, в Европе, соблюдая правила и продвигая инновации. Это важная веха для нас и захватывающее событие. возможность для роста и изменений в мире облачной инфраструктуры. Нам не терпится увидеть, как все будет развиватьсяговорит Роберт ван дер Меулен, директор по стратегии продуктов в Leaseweb
Чтобы узнать больше об этой инициативе www.leaseweb.com/about/european-cloud-campus
О Лизвебе
Leaseweb — ведущий поставщик инфраструктуры как услуги (IaaS), обслуживающий 20 000 клиентов по всему миру, от предприятий малого и среднего бизнеса до предприятий. Услуги включают в себя публичное облако, частное облако, выделенные серверы, колокейшн, сеть доставки контента и услуги кибербезопасности, поддерживаемые исключительным обслуживанием клиентов и технической поддержкой. Имея более 80 000 серверов, Leaseweb с 1997 года предоставляет инфраструктуру для критически важных веб-сайтов, интернет-приложений, серверов электронной почты, служб безопасности и хранения данных. Компания управляет 25 центрами обработки данных в Европе, Азии, Австралии и Северной Америке. из которых поддерживается превосходной всемирной сетью с общей пропускной способностью более 10 Тбит/с.
Leaseweb предлагает услуги через свои различные торговые организации Leaseweb, которыми являются Leaseweb Нидерланды B.V., Leaseweb USA, Inc., Leaseweb Singapore PTE. LTD, Leaseweb Deutschland GmbH, Leaseweb Australia Ltd., Leaseweb UK Ltd, Leaseweb Japan KK, Leaseweb Hong Kong LTD и Leaseweb Canada Inc.
Зарабатывайте баллы за отзывы — оплачивайте сервер со скидкой!

Зарабатывайте баллы за отзывы — оплачивайте сервер со скидкой!
Мы ценим ваше мнение и хотим узнать, как мы можем сделать услуги PQ.Hosting еще лучше. По вашим отзывам вы добавили баллы, которые можно обменять на скидки!
Вот как это работает:
1. Делитесь своим опытом:
Напишите подробный отзыв о наших сервисах и услугах: 1 балл.
otzovik.com/reviews/pq_hosting-nedorogie_virtualnie_servera_zagranicey/
ru.hostings.info/pq-hosting.html
ru.hostadvice.com/hosting-company/pq-hosting-srl-reviews/#main-info
www.trustpilot.com/review/pq.hosting
ru.tophosts.net/companies/pqhosting
hosting101.ru/pq.hosting
vpsradar.ru/pq.hosting
www.serverhunter.com/company/pq-hosting/
hostinghub.ru/pqhosting
maps.app.goo.gl/CghmzdSmHNhvdvMYA
www.softwaresuggest.com/pqhosting
startpack.ru/account/developer/application/2482
Загрузите наше приложение: 0,5 баллов
play.google.com/store/apps/details?id=com.pq.hosting
Оставьте отзыв в Google Play и поставьте оценку приложению: 1 балл
Пост с отзывом в ваших социальных сетях: 1 балл (не удаляйте, пожалуйста, до окончания акции), а если вы сделаете репост на свою последнюю страницу новости из нашего сообщества, то мы добавим вам ещё 0,5 балла!
— ВКонтакте: vk.com/pqhosting
— Facebook: www.facebook.com/pqhosting1
— Twitter: twitter.com/HostingPq
— Telegram: t.me/pq_hosting
— Инстаграм: www.instagram.com/pq.hosting/
Напишите статью на вашем сайте или в вашем блоге о PQ.Hosting (от 2 000 знаков с пробелами): 2 балла
Установить логотип PQ.Hosting с активной ссылкой на ваш сайт *: 1 балл
*За готовыми баннерами вы можете обратиться через тикет-систему в отдел продаж.
2. Накапливайте баллы: чем более уникальные отзывы вы сохраняете, тем больше баллов постоянно!
3. Получите скидку:
Накопленные баллы* можно использовать для оплаты услуг PQ.Hosting!
*1 балл = 1 евро
Присоединяйтесь к нашей программе отзывов и получите скидку уже сегодня!
Важно:
Отзывы должны быть солидными и проявлять модерацию.
Нам потребуется время на проверку отзывов и пользователей.
Мы принимаем отзывы только от новых и действующих клиентов PQ.Hosting.
Поделитесь своим опытом и получите преимущества от услуг PQ.Hosting!
PS Следите за нашими новостями – совсем скоро у каждого клиента PQ.Hosting будет возможность получить бесплатный сервер!
Шум волн, холодный лимонад и приятное ощущение от скидки

Со всей этой летней акцией сразу как-то резко захотелось отпуска. Желательно на каком-нибудь безлюдном острове, чтобы только море, белый песок и тёплый ветер в лицо. И главное — чтобы никаких рабочих задач, разрывающихся чатов, и созвонов.
Надеемся, что вам очень скоро удастся осуществить свои отпускные мечты!
А пока вы не отправились отдыхать, спешим напомнить, что при заказе VDS можно сэкономить 20% по промокоду ENJOYSUMMER. Скидка применится на любой срок аренды сервера при единовременной оплате за этот период (1, 3, 6 или 12 месяцев).
Целый остров на это, конечно, не купишь, но на лимонад со льдом и аренду тихого бунгало должно хватить :)
Промокод будет активен до 10 июня 23:59 мск.
https://firstvds.ru
Обновление тарифов на VPS в России
2 июня обновили тарифы на SSD KVM VPS в России.
