В пятницу, 27 октября, у нас была возможность принять у себя выпуск «Global Women Startup Weekend» (Париж) в 2019 году. В течение двух с половиной дней около 80 участников с нуля создавали мощные корпоративные проекты в надежде получить одну из премий Corpo Elevator и TechStars. От простого предоставления услуг до чека на 50 000 евро и до инкубации в кластере Евротехнологий вознаграждения, вызванные игрой, вызвали много эмоций у участников, чье участие иногда было близко к 200%.
Прежде всего, что такое Startup Weekend?
Startup Weekend, созданный TechStars, предлагает всего за 54 часа создать жизнеспособный бизнес-проект.
После глобальной презентации организаторов, спонсоры проекта передают первый вечер. Затем все остальные участники, представленные как «участники ресурсов», должны приблизиться к проекту, который их интересует больше всего.

После того, как эти команды собраны, одна миссия: использовать два дня работы, чтобы преуспеть в поиске подходящей бизнес-модели, определить маркетинговые аргументы, которые будут развиваться, исследовать рынок, создать MVP… Цель состоит в том, чтобы представить проект в достаточной мере уместно, чтобы быть замеченным одним из присутствующих инвесторов и / или выиграть приз. И что за вызов!
Согласно TechStars, мы можем определить суть Startup Weekend по 3 глаголам действия:
- Подключайтесь: потому что каждому участнику предлагается общаться, делиться, делиться со всеми вокруг. Startup Weekend — это идеальное место для встречи с вашим будущим соучредителем, другом, наставником или инвестором.
- Обнаружение: связано с соединением (первая точка), обнаружение объясняется рассмотрением различных доступных ресурсов (других участников, но также наставников), которые позволяют всем командам покинуть мероприятие с видимость на их соответствующих дорожных картах.
- Изучение на опыте: это основной элемент задачи. Каждому участнику предлагается попробовать, проверить, повернуть, но особенно учиться у них. Ни одна книга не будет рекомендована, ни один курс не будет обойден: он должен будет окружить себя ключевыми ресурсами и попробовать, искать, тестировать концепции, сравнивать идеи бизнес-планов, и все это до ему удается найти идеальное уравнение, ведущее к «правильному продукту по правильной цене».
Организация, способствующая созданию
TechStars опирается на среды, которые поддерживают идеи и совместное использование. Особое внимание уделено последовательности различных этапов уик-энда, все из которых, так или иначе, будут участвовать в ускорении стартапов. Чтобы иметь положительное влияние, каждое издание предназначено для того, чтобы обеспечить участникам атмосферу обмена, обучения и эффективности.
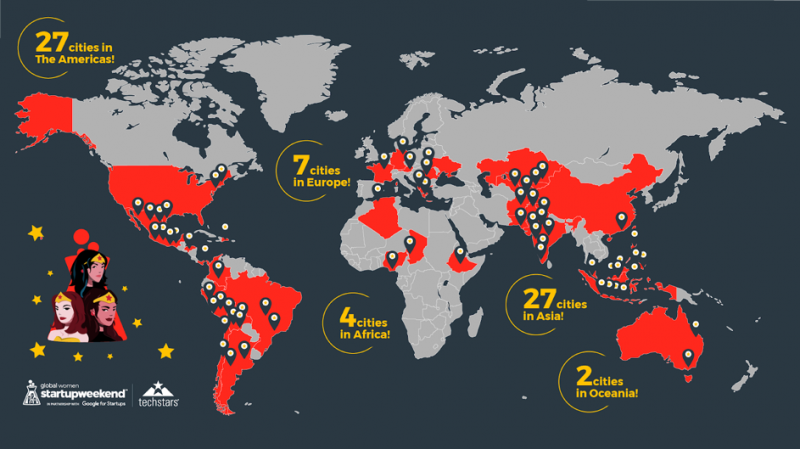
Становясь настоящими институтами в профессиональном мире, и особенно в технологическом секторе, Startup Weekends сегодня имеют более 350 000 участников, 12 000 организаторов и почти в 1300 городах.
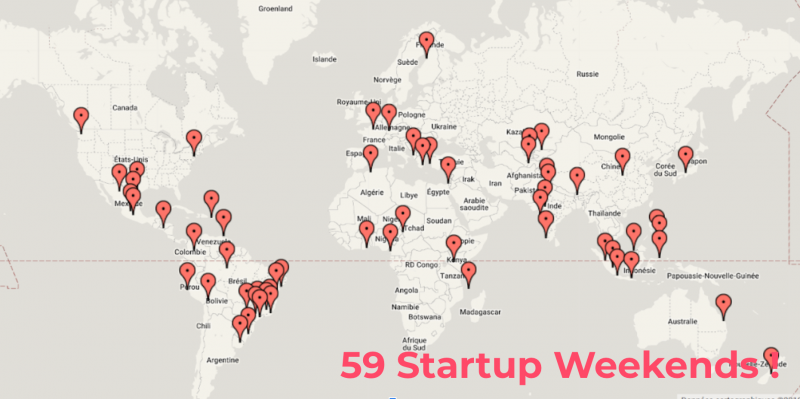
Только в эти выходные по всему миру было организовано 59 Startup Weekends.
 И глобальные женские стартап-выходные во всем этом?
И глобальные женские стартап-выходные во всем этом?
Изначально женские выпуски были частью местной инициативы и теперь считаются частью Startup Weekend.
В настоящее время есть 1500 будущих предпринимателей, которые имели возможность принять участие.
 Причина этого успеха?
Причина этого успеха?
Печальный факт: с 2008 года только 2% операций по сбору средств предназначены для стартапов, основанных женщинами.
Также, по мнению Forbes:
www.forbes.fr/femmes-at-forbes/les-resultats-du-barometre-sur-lentreprenariat-feminin/
В то время как женщины придают большее значение, чем мужчины, быть их собственным боссом (72% против 65%), только 28% хотят стать предпринимателями во Франции. Речь идет о социальных конструкциях, которые замедляют их амбиции, а также о психологических опасениях по поводу рисков, связанных с предпринимательством: 53% француженок считают, что взятые на себя риски не стоят выгоды успеха (против 48% мужчины).
Если новое поколение женщин осмеливается быть смелее, когда 42% женщин в возрасте 20–29 лет хотят попробовать эксперимент, 65% начинающих женщин говорят, что их можно отговорить от превращения в предпринимателей из-за страха неудачи (мужчины не чем 54%, чтобы почувствовать этот страх). Но настоящим сюрпризом является то, что 36% женщин-предпринимателей говорят, что они уже потерпели неудачу в профессиональной деятельности из-за своего пола, особенно во время сбора средств.
Поэтому TechStars показалось очевидным поддерживать эти специальные выпуски, чтобы увидеть рост доли женщин-предпринимателей в мире успешных стартапов.
И вполне естественно, что Scaleway, который хочет более активно участвовать в продвижении женщин в сфере технологий, предложил провести это мероприятие.
Начало выходных: пятница, 18 ч.
Хотя официальное открытие было объявлено в 18:30, за полчаса до этого, пятьдесят участников, более мотивированных, чем другие, ожидают открытия дверей Maison Paris. Когда наступил роковой час, они наконец смогли обнаружить наши оригинальные помещения. Надев тапочки, организация смогла озвучить начало инаугурационного коктейля, и обмены начались.

Мы встретили 4 участников: Юссара, Лора, Юлиана и Жан.
Бывшие начинающие стартапы становятся наставниками
Юссара Нуньес — менеджер по цифровым проектам, BNP Paribas
Бывший участник Jussara уже участвовал в Startup Weekend. Придя без конкретной идеи, она присоединилась к команде, соблазненной подачей, реализованной перевозчиком проекта. Оценка: 3 приза, выигранные из 20.
С этим опытом она не колебалась ни минуты, когда с ней связались, чтобы стать наставником.
Обратившаяся к участию в этих проектах в новой форме, она объясняет свое присутствие интересом к поддержке команд своим опытом и навыками. Она также ценит позитивную энергию и атмосферу совместного конструирования, которая царит на подобных мероприятиях, поэтому вполне естественно, что ей нравится посещать ее.
У некоторых участников больше идей
Laure PEUCELLE — веб-разработчик, Fujitsu Франция
С первым осуществляемым проектом (сообщения активистов носков, чья прибыль передается ассоциациям), для которого она работает с инкубатором Make Sens, этот Startup Weekend является первым, в котором участвует Laure. Полный идей, не компаний, а продуктов, он, тем не менее, питает желание питчер.
Ее основная цель — познакомиться с личностями, с которыми она может обмениваться и строить. Если она присутствует на этих выходных, то это главным образом потому, что она очень хочет присоединиться к команде, чтобы сотрудничать с другими талантами и использовать свои навыки, в том числе технические, для обслуживания проекта, который имеет чувство.
Готовый к успеху Челленджер
Юлиана ПРИНЦИП ПЕСТАНА — продюсер, Мееро
Уверенная в успехе своего стартапа, Джулиана вкладывает все свои средства в свое распоряжение. Например, она выбрала работу на неполный рабочий день, чтобы максимально сосредоточиться на ней. Его бизнес-проект уже соблазнил его соучредителя.
Вот что она представляет:
Мой проект разрушителен, и я хотел бы получить отзывы о нем. Это веганские блюда (чтобы быть как можно более обширными и потому, что я вегетарианец в течение 4 лет) замороженные, сделанные французским шеф-поваром и доступные для заказа из приложения, полностью управляемого данными. Это означает, что на основе собранных данных приложение сможет составлять «здоровые» и персонализированные меню. Упаковка, конечно, будет экологически ответственной.
На выходные Юлиана также хочет познакомиться с другими участниками. Она хотела бы, чтобы ее окружали коммуникаторы, которые, как и она, разделяют амбиции перебалансировать экономику, привлекая больше женской энергии.
Мужчины также мобилизуются для женщин-предпринимателей
Жан Лебрет — Инновация, Bouygues Entreprise (наставник)
Наставник на выходных Startup, Жан была приглашена Кэндис Капелль, генеральным директором Lift Corpo (организатор мероприятия). Увлеченный инновациями, он сделал свою работу и регулярно участвует в Startup Weekends. По его оценкам, на такого рода мероприятиях он получает в 4 раза больше, чем дает:
Я дам, может быть, 20%, но я уверен, что получу 80% в обмен! Это целая жизнь всего за пятьдесят часов, едва!
Очень активная в голубой экономике, это проекты социального воздействия, которые ближе всего к ее сердцу.
Он в основном смотрит на бизнес-модели разных групп.
В конце вечера, когда группы медленно нарастают, мы с большим удовлетворением отмечаем, что многие мужчины пришли, чтобы помочь, приняв участие в этом мероприятии как талантливый ресурс.
Равенство — это дело каждого, и благодаря вовлечению мужчин однажды этот проект равенства может быть реализован.
В течение выходных участники были полностью вовлечены, чтобы увидеть, как их идея была сохранена. Из 5 этажей, составляющих La Maison, 3 были посвящены этому событию, поэтому для выходных Startup Weekend было выделено почти пятнадцать помещений, и каждый квадратный метр использовался с умом.

Keekoffgreen был самым успешным из 12 групп. Команда победила:
2 места в инкубаторе DEMAIN от Prisma Media и бюджетный конверт на 50 000 евро
- 500 евро предлагаются на Scaleway на 4 месяца
- 3 места на Цифровой женский день
- 1 год членства в команде Premium на Crello
- 3 месяца наставничества по взлому роста через Germinal
- 1 интервью в истории стартапов
- 2 бесплатных места для кода bootcamp проекта Hacking
- 1 место для bootync Героина (25% скидка для остальных членов команды)
- 1 пресс-релиз через Kalima PR
- и, конечно же, гордость за то, что справилась с этой невероятной задачей!
День за днем вы можете узнать подробности Глобального женского стартап-уик-энда с тех пор, как они были опубликованы в социальных сетях корпорации Ascenseur.
TechStars — один из самых успешных в мире ускорителей запуска. Имея портфель из более чем 1500 стартапов и оцениваемый в миллиарды долларов, он имеет множество программ, таких как Startup Weekend, Startup Week и Startup Digest.