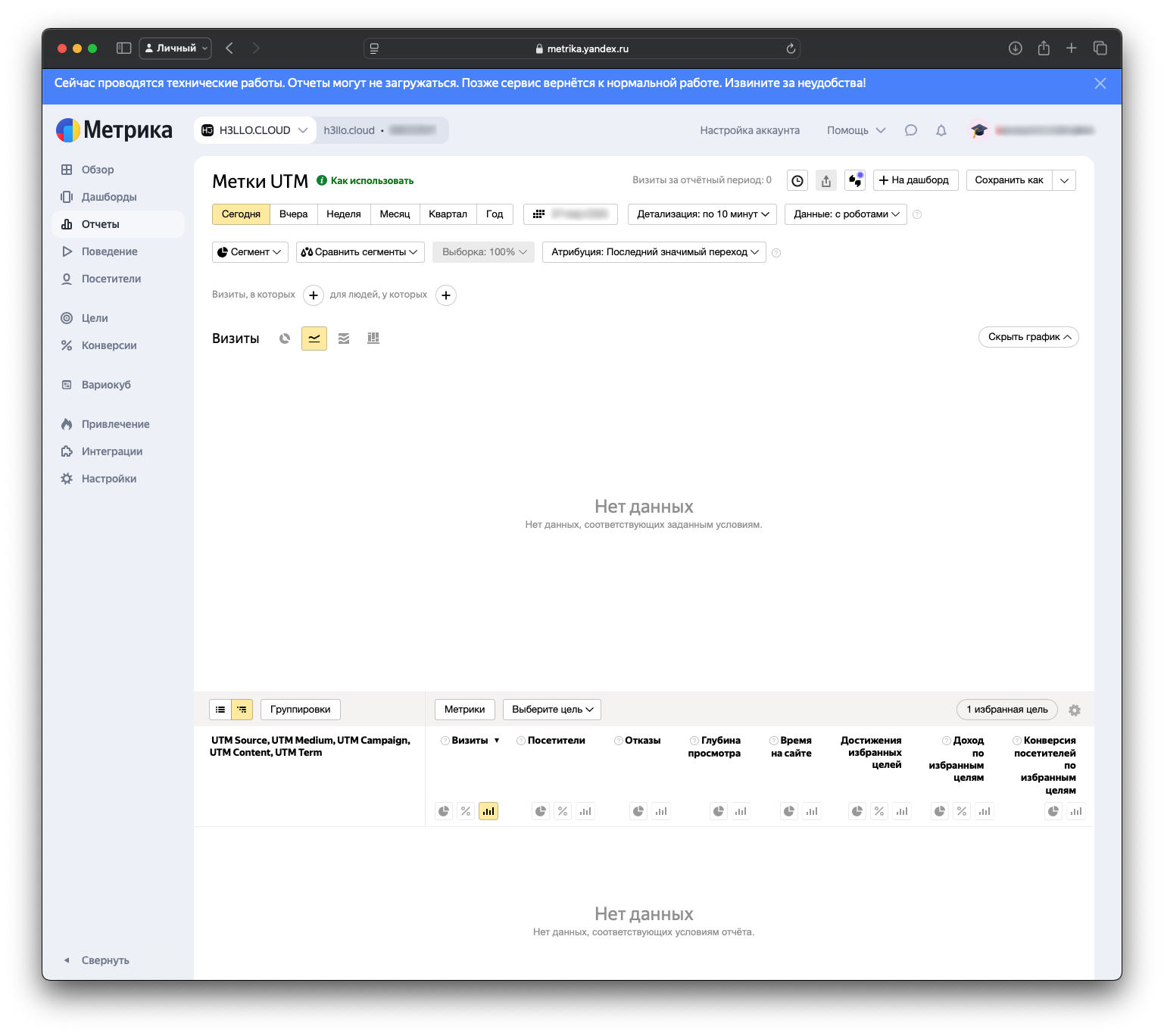
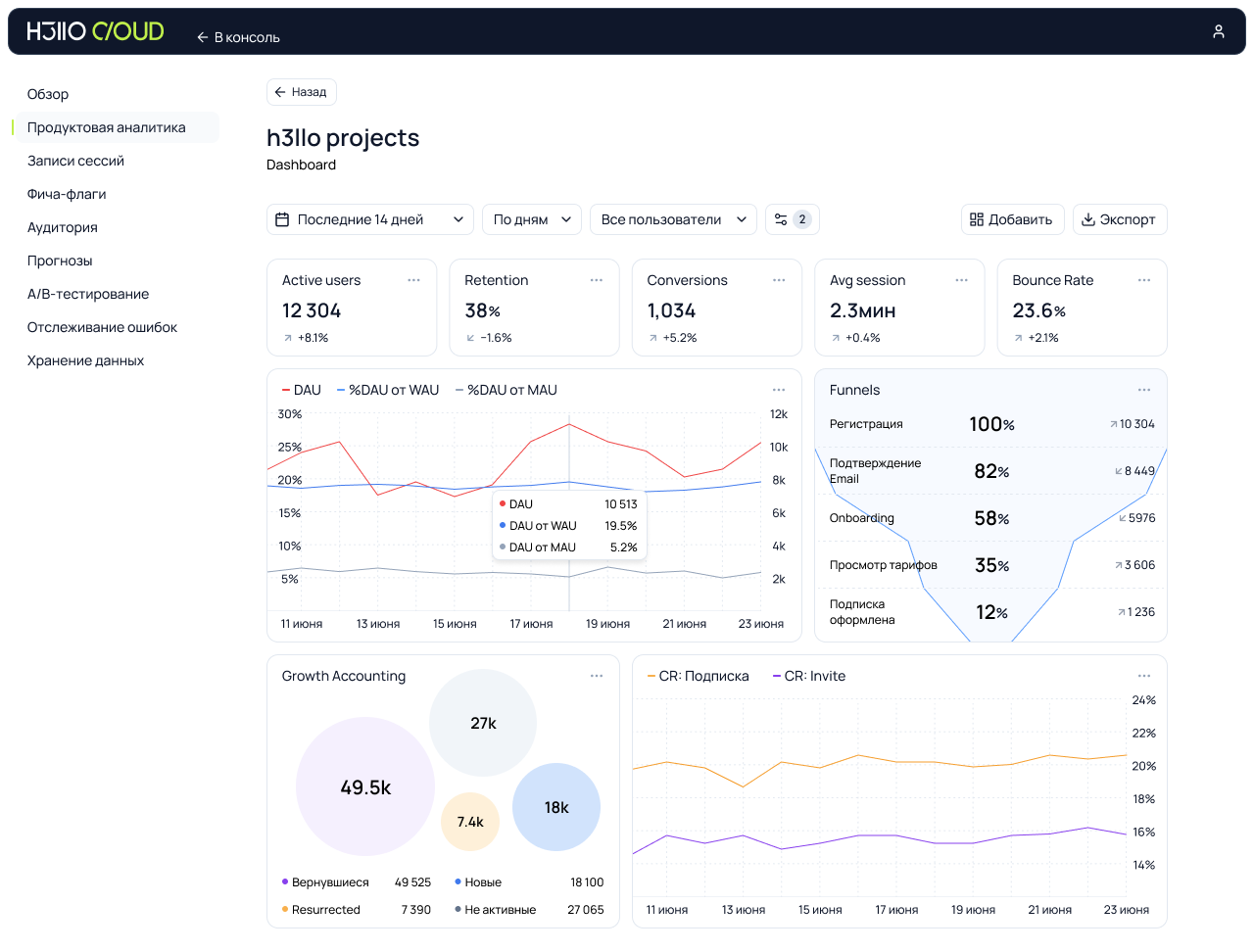
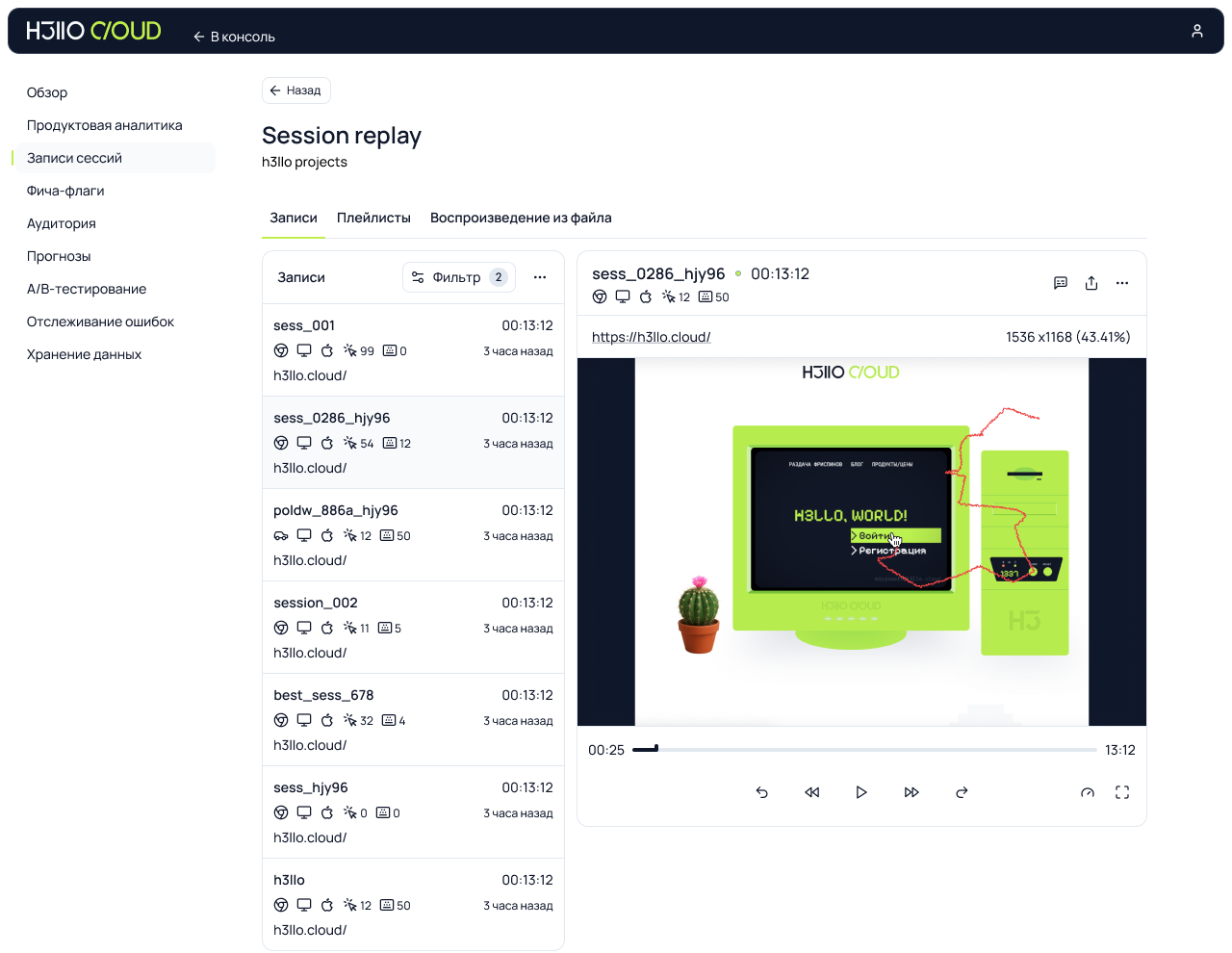
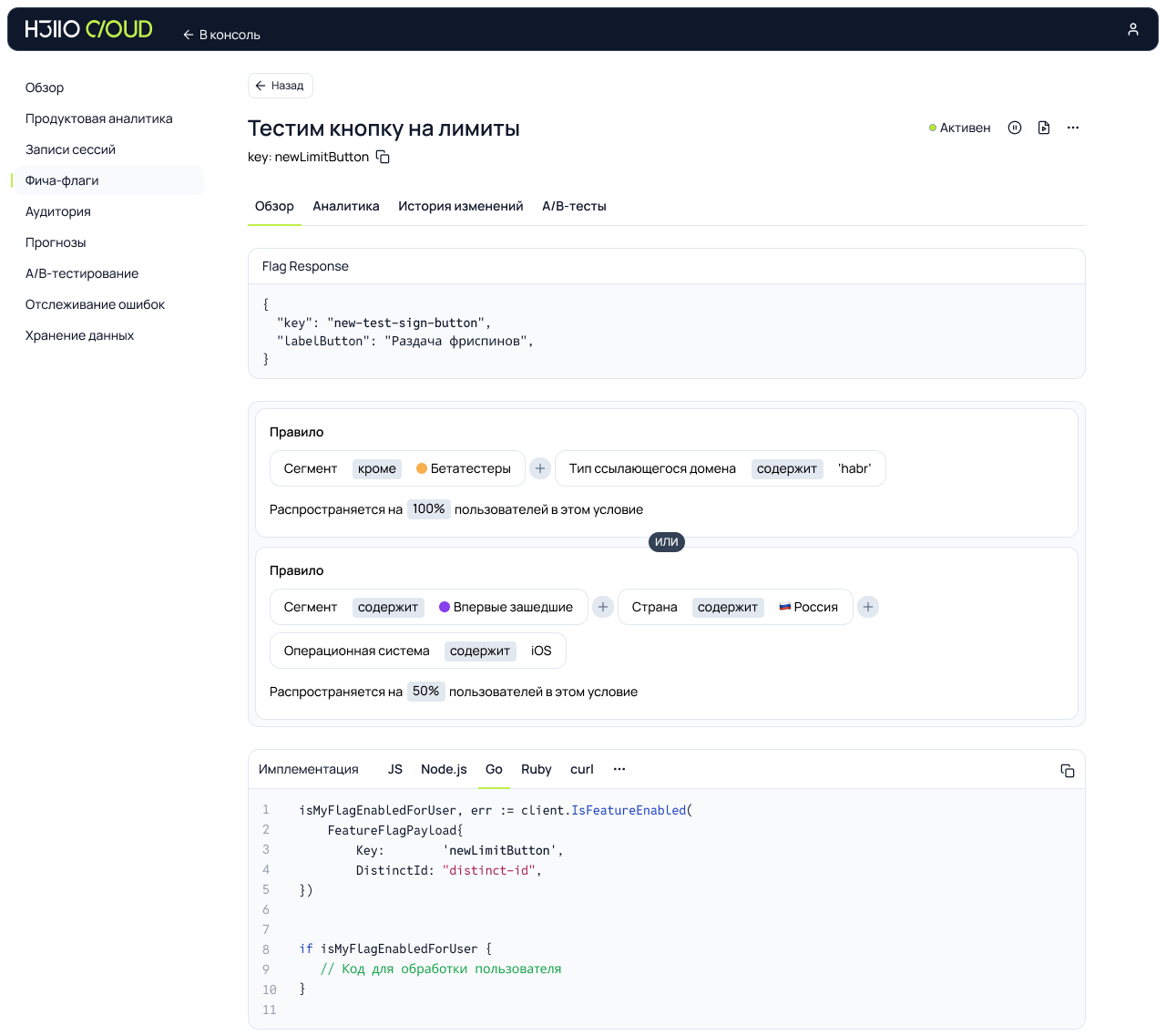
Что было на выставке ЦИПР — парадная сторона и мрачная изнанка



У меня очень странное впечатление. С одной стороны, круто, что конференция есть и всех удалось собрать. С другой — ужасный опыт участия, конские цены и пафосные заголовки пресс-релизов.
Удивительно, но многие узнавали нас по блогу на Хабре.
Участие стоит несколько десятков миллионов рублей за стенд (мы не взяли) — ну или 50 тысяч рублей за самый простой билет и 150 тысяч за VIP. Мы взяли за 150, но сразу скажу, подсыхающие канапе этого не стоили. Но тем не менее оказалось дичайше полезно.
Сейчас расскажу, зачем вообще ездить на такие конференции и какой профит с них можно получить. Потому что может показаться довольно странным ехать на конференцию «Цифровая индустрия промышленной России» не в онлайн.
Вообще-то изначальная задумка была как в анекдоте про то, что когда программисты придут к власти, целые министерства можно будет заменить на один скрипт. Это место, где собираются все ключевые люди, определяющие будущее ИТ России. Чтобы обсудить важные вещи, познакомиться лично и прибухнуть, конечно.
В этом году основной темой были LLM. Их теперь все называют ИИ. Ещё импортозамещение, ИБ, как и что автоматизировать, где брать и как обучать людей и всё такое. Но основной лейтмотив был — хайп на LLM и «внедряй, а то проиграешь».
Почему Нижний — потому что там крупный ИТ-кластер, наука и промышленность. Почти как Екатеринбург, где тоже промышленность и большое население дали отличный старт для роста ИТ в 90-х.
Начну с того, что, конечно, дико жалко денег. Жаба прям давит.

Денег сильно жалко
Когда мы решили ехать, у меня была очень точная коммерческая позиция. В первую очередь, конечно, такая конференция — это поиск заказчиков для нашего облака. Вторая задача из обязательных — было запланировано интервью каналу «Про Бизнес», и нужно было за эти 13 минут тайминга не просто отчитаться, а показать, что мы есть, что мы ездим на такие мероприятия и следим за тенденциями. Коротко, но ёмко рассказать о себе как о компании.
Дальше надо было обойти всех, поменяться контактами и познакомиться, чтобы, если что, писать напрямую, а не через секретарей и продажников. Приезжают чиновники (особенно Минцифры и Минпромторг), госкорпорации типа Сбера и ВТБ, Росатома, Роскосмоса, Ростеха, Ростелекома, РЖД и т.п., крупный бизнес вроде Яндекса, 1С, Позитива, Касперского, потом промышленность — там я мало кого знаю лично, но в целом хотя бы по человеку от всех крупных производств, куча стартаперов (хотя, казалось бы, венчур в России кончился в 2022-м), преподаватели из университетов и дамы разного поведения, которые не могут пропустить такую концентрацию людей с деньгами.
Со всеми, кроме последних, мне как представителю компании, конечно же, интересно познакомиться и пообщаться. В этом разрезе денег за участие уже не жалко, потому что они окупаются.

«Аааа, мы читали вас на Хабре!»
На рынке мы немного нашухерили, сделали с десяток публикаций на Хабре и начали вести телеграм-канал про гомерические особенности российского бизнеса. Но этого, как оказалось, хватило, чтобы нас очень хорошо заметили.
Это я понял почти сразу, в совершенно неожиданный момент.
Дальше прямая речь Антона (коммерческого директора):
Проходя мимо стенда МТС, где я когда-то работал, меня узнали бывшие коллеги. Мы разговорились, и тут их взгляд упал на мой бейдж с нашим логотипом. Реакция была мгновенной: «А-а-ах, вот ты кто! Вот вы кто такие!» Оказывается, по их словам, они за нами следят, читали наши публикации на Хабре и даже было совещание, которое длилось два дня, посвящённое тому, чтобы выяснить, «кто вот такие, откуда вы взялись вообще, чем будете заниматься. Подобные истории я слышал и от коллег из Ростелекома — те тоже говорили, что читали, смотрели, а некоторые даже заходили на наш демостенд и пробовали всё ручками.
Ходили слухи, что в Сбере проводили подобные совещания и даже служба безопасности по своим каналам пробивала информацию о нас.
Так что да, за нами следят и ждут, когда же рванём.
Пользуясь случаем, передаю привет уважаемым коллегам. И напоминаю, что пока вы корпорация, вы двигаетесь раз так в 7–8 медленнее, чем маленькие команды, где нет бюрократов и идиотов. Ну, знаете, как мы. Хотя про идиотов я ещё не до конца уверен, это время покажет. С гранатой за птицами мы уже бегали.
Что было в целом

Основных тем было три. Первая — импортозамещение. Было удивительно приятно видеть столько отечественных производителей, и не только софта, но и железа. Даже мои бывшие коллеги из Росатома, как я узнал, уже начали свои железки делать.


Вторая тема — инфобез. В нескольких сессиях, которые я успел послушать, все телеком-операторы и банкиры наперебой рассказывали, как они борются с мошенниками, которые нам звонят по телефону. По их словам, вроде даже получается. Возможно, скоро вместо мошенников будут звонить лицензированные спамеры, использующие бигдату операторов.
Но главной, просто всепоглощающей темой стал искусственный интеллект, ГИГАЧАТ 2.0. Это они так называют LLM, как уже говорил. А вместе с LLM туда под общий хайп загребли всё: от классификаторов машинного зрения до термоса. В конце концов, он же знает, какую воду хранить — если налить горячую, через час в нём горячая, если холодную — там через час не горячая, а холодная. Для этого нужен серьёзный AI.
Про ИИ говорили абсолютно все, даже те, кто, по моим ощущениям, к нему особого отношения не имеет. Ярчайший пример — тот же МТС. Я до сих пор не понимаю, что они там в искусственном интеллекте делают, кроме как предоставляют в аренду видеокарты, да и то их кластер довольно скромный по сравнению со Сбером. Но на стенде у них была заявлена собственная разработка — МТС GPT. Однако, по инсайдерской информации из достаточно надёжных источников, это не совсем их продукт. Похоже, они через аффилированные маленькие компании получили контракты на доступ к платным версиям зарубежных аналогов, а потом просто сконсолидировали это под собой в одной оболочке и теперь выдают за свой продукт. У них банально не хватит карточек даже для инференса, не говоря уже о том, чтобы что-то своё обучать.
Атмосфера на самой конференции была предсказуемой. Первые два дня — огромное количество народа, не протолкнуться. На третий-четвёртый день народ заметно поуменьшился.
Организация пространства интересная. Внутри выставочного комплекса — закрытое помещение со стендами, условные площадки 5 на 3 метра. Там же был и зарубежный павильон: китайцы, белорусы, иранцы, но всё как-то невизуально, ничего, что заставило бы остановиться.
А вот на площади, в зоне, где, по идее, кормили людей, были отдельные лаундж-зоны. Там можно было поваляться на подушках, посидеть на лавочках с ноутбуком. И вот там, особенно под вечер, собиралось много народа. Погода стояла жаркая, за 30 градусов, и некоторые компании этим отлично пользовались: ITGLOBAL.COM (Айтиград) разливали пиво, Softline готовили коктейли. Я видел, как крупные интеграторы привозили заказчиков, как говорится, культурно на выгул.
Клиента, который сам бы сюда ни за что не приехал, брали под ручки, привозили на комфортном минивэне, селили в номер, а вечером — баня, алкоголь, ресторан. Я не осуждаю, у нас так работает большинство.

Изнанка
У меня был статус VIP за 150 тысяч рублей. И он был вообще ни о чём. Абсолютно пустая трата денег. В теории он давал доступ к контактам, но на письма по этому списку никто не отвечал — вообще мёртвая история. В следующий раз, если поедем, то только как обычные делегаты за 50 тысяч. Мы даже рассматривали вариант со своим стендом, но цена вопроса уходит сильно за новый Майбах и квартиру в Москве. Там спонсорский пакет + проектирование стенда ещё 3–4 миллиона, а строить его можно только силами рекомендованных компаний за отдельные деньги.
Лучше мы за эти деньги купим какой-нибудь новый сервак последнего энтерпрайзного поколения.
Логистика и быт просто ужасны. Интерфейс для покупки билетов как у кривых копий Фаргуса, «озвучено профессиональными программистами». Чтобы попасть на какую-то вечеринку, нужно было регистрироваться за пределами основной системы где-то в third-party софте. Когда нам понадобилось переоформить билет с одного сотрудника на другого, это заняло неделю! А ещё нужно распечатать соглашение, вручную заполнить его, подписать, отсканировать и прислать обратно!
На самой площадке были отвратительный Wi-Fi и мобильная связь, видимо, работали глушилки. Даже передвижная точка от Теле2 не спасала.
Но хуже всего было с едой. За те сумасшедшие деньги, что стоили билеты, нас не кормили. Выдавали какие-то канапе и бутербродики, настолько маленькие, что явно это была ESG-повестка. Ресторан на территории был один, и очередь туда была такая, что точно не все попадают.
В итоге, чтобы пообедать, я брал ребят, с которыми уже пообщался, и предлагал пойти в ближайшую кафешку по супчику.
Проблемы были даже со входом. Бейджи, которые мы заранее распечатали, на второй день, после визита Мишустина, перестали работать. Всем надо было стоять в очереди, чтобы их перепечатать. Естественно, с паспортом, который многие оставляли в номере. Меня вообще не нашли в базе, я прошёл, просто показав паспорт, — сверили имя на бейдже. Зачем тогда была вся эта процедура печати — непонятно.
Ну и вишенка на торте: после регистрации мне до сих пор летит всякий спам и рассылки. Возможно, как раз от других VIP-участников.
Немного публикаций, чтобы вы понимали уровень:
- Хакеры не смогли взломать веб-ресурсы конференции ЦИПР-2025. Это, если что, «…успешно предотвратить множество автоматизированных попыток сканирования веб-ресурсов ЦИПР».
- Достигнем полного импортозамещения к 2030 — это, если что, про IVA.
- Можно было заселяться в отель по биометрии. Терминалов было то ли один, то ли два, в одном отеле, в основном, чтобы сфотографировать. Ладно, это классно, тесты.
- Роскосмос направит нейросеть на МКС — когда был тренд на роботизацию, робота они уже отправили.
- Во всех поездах РЖД введут единый мультимедийный стандарт.
- МТС вложит 22 млрд рублей в модернизацию ИТ-инфраструктуры.
- На ЦИПР-2025 представили российский сервер нового поколения — это не Байкал, если что, это на базе Xeon 6.
Интернет на борту отечественных самолётов может появиться в 2027 году. «Любой винтик, лампочка, модем, который будет установлен на борту воздушного судна, — это лишний вес, лишний объём, и это должно быть подтверждено производителем», — отметил заместитель гендиректора по информационным технологиям и информационной безопасности «Аэрофлота» Антон Мацкевич. «Именно поэтому речь пока идёт о перспективных отечественных самолётах, которые сейчас испытываются».

Итог
Несмотря на всё это, поездка была полезной. Прямых заказчиков найти было сложно — они все прям за ручку ходили со своими менеджерами, которые их не отпускали разговаривать с конкурентами, незнакомцами и вообще взрослыми дядями. Но мне больше дало личное знакомство с коллегами по цеху. Я встретил людей, которых не видел много-много лет. И вот так, слово за слово: «Привет, как дела?», и вдруг: «Слушай, а не хотите поучаствовать с нами в проекте?» Субподряд для Касперского так нащупался, а наш директор по партнёрствам Андрей пообщался со многими топ-менеджерами, например из Positive Technologies, Astra Group, РЕД СОФТ, SberTech, Nexign, NAUMEN, PostgresPro, Directum, Express, Р7, Almi Partner и Цифровыми технологиями Москвы, которые теперь нас знают и готовы вести диалог.

Надеюсь, что-то сработает. Любые конференции дают результат не сразу, а через некоторое время. Горячего заказчика оттуда не уцепишь.
Но зато нас увидели и, возможно, поняли, что мы адекватные. Хотя это неточно.
h3llo.cloud/ru