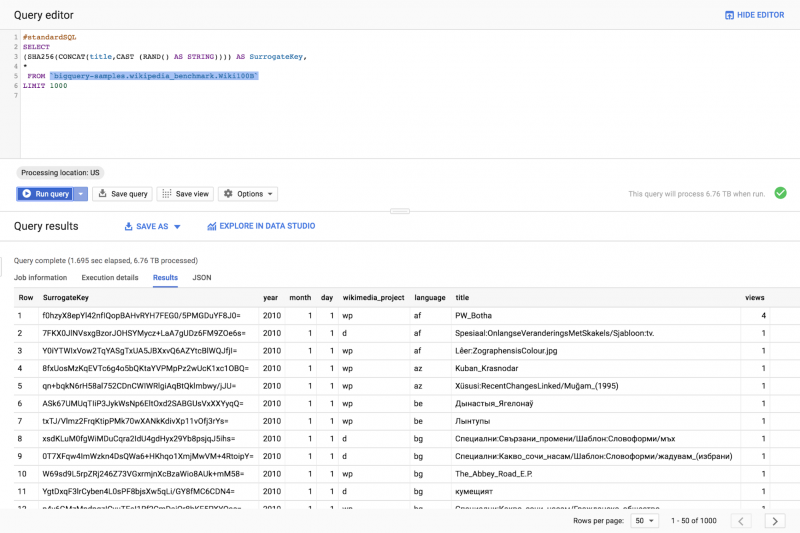
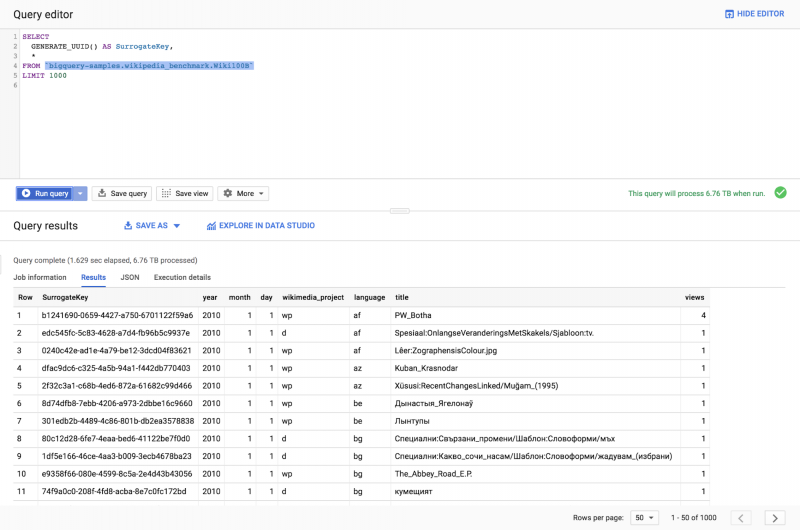
Новая облачная платформа Google в Цюрихе для развития нашей поддержки швейцарских и европейских компаний.
Наш регион Цюрихской облачной платформы (GCP) теперь открыт и доступен. Являясь шестым по величине регионом в Европе и девятнадцатым в мире, этот новый регион предлагает компаниям, работающим в Швейцарии, новые возможности, предоставляя им доступ к данным и рабочим нагрузкам с уменьшенной задержкой.

Облако «сделано в Швейцарии»
Предназначенный для поддержки швейцарских и европейских клиентов, регион GCP Цюриха (европа-запад6) предлагает три зоны доступности, обеспечивающие рабочие нагрузки высокой доступности. Компании с гибридным облаком могут беспрепятственно интегрировать свои новые развертывания с существующими с помощью нашей региональной партнерской экосистемы и через две выделенные точки присутствия Interconnect.
cloud.google.com/about/locations/zurich/
Запуск Цюрихского региона привел к снижению задержек для продуктов и услуг GCP для компаний, работающих в Швейцарии. Размещение приложений в этом новом регионе может сэкономить до 10 мс времени для латвийских конечных пользователей. Задержка в регионе Цюриха, независимо от вашего местоположения, видна и доступна на GCPing.com.
www.gcping.com
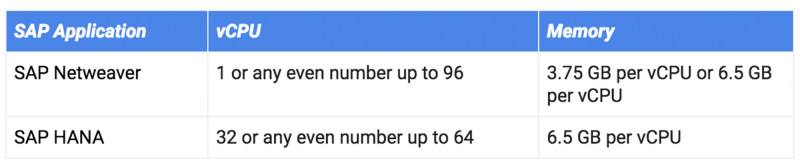
Регион Цюриха открывается стандартным пакетом наших продуктов, включая Compute Engine, Google Kubernetes Engine, Cloud Bigtable, Cloud Spanner и BigQuery.

Чтобы воспользоваться многими услугами GCP, вы должны сначала перенести свои данные в облако. Transfer Appliance — это сервер большой емкости, который позволяет быстро и безопасно передавать большие объемы данных в GCP. Он будет доступен на швейцарском рынке. Мы рекомендуем использовать Transfer Appliance для перемещения больших объемов данных, загрузка которых может занять более недели. Чтобы сделать запрос, вы можете перейти на эту страницу.

В этом регионе интегрирована Cloud Interconnect, наша частная программно-определяемая сеть, которая обеспечивает быструю и надежную связь между всеми регионами мира. Вы можете использовать службы, которые в настоящее время недоступны в Цюрихском регионе через сеть Google, и комбинировать их с другими службами GCP, развернутыми по всему миру. Это позволяет быстро развертывать и расширять свою деятельность в разных регионах с помощью продуктов, предназначенных для глобального бизнеса.
Праздник с нашими швейцарскими клиентами
Мы запустили этот новый Цюрихский регион с событием, которое привлекло более 800 лиц, принимающих решения, и разработчиков. Урс Хёльцле, Техническая инфраструктура СВП, официально открыл регион. Клиенты из швейцарского и европейского фармацевтического, промышленного и финансового секторов смогли углубить свои знания о GCP и понять, как их деятельность в облаке может извлечь выгоду из этого нового региона.





Следующие шаги
Для получения дополнительной информации об этом регионе, не стесняйтесь посетить веб-страницу региона Цюриха, где вы можете получить доступ к бесплатным ресурсам, техническим документам, видео в облачном эфире по запросу. и многое другое. Если вы новичок в GCP, посетите страницы «Советы и рекомендации по выбору региона Compute Engine», чтобы начать работу сегодня.
В течение года мы будем открывать новые районы и районы GCP, начиная с Осаки. Наша страница, представляющая наши облачные географические зоны, регулярно обновляется с появлением наших новых услуг и дополнительных регионов.
Облако «сделано в Швейцарии»
Предназначенный для поддержки швейцарских и европейских клиентов, регион GCP Цюриха (европа-запад6) предлагает три зоны доступности, обеспечивающие рабочие нагрузки высокой доступности. Компании с гибридным облаком могут беспрепятственно интегрировать свои новые развертывания с существующими с помощью нашей региональной партнерской экосистемы и через две выделенные точки присутствия Interconnect.
cloud.google.com/about/locations/zurich/
Запуск Цюрихского региона привел к снижению задержек для продуктов и услуг GCP для компаний, работающих в Швейцарии. Размещение приложений в этом новом регионе может сэкономить до 10 мс времени для латвийских конечных пользователей. Задержка в регионе Цюриха, независимо от вашего местоположения, видна и доступна на GCPing.com.
www.gcping.com
Регион Цюриха открывается стандартным пакетом наших продуктов, включая Compute Engine, Google Kubernetes Engine, Cloud Bigtable, Cloud Spanner и BigQuery.
Чтобы воспользоваться многими услугами GCP, вы должны сначала перенести свои данные в облако. Transfer Appliance — это сервер большой емкости, который позволяет быстро и безопасно передавать большие объемы данных в GCP. Он будет доступен на швейцарском рынке. Мы рекомендуем использовать Transfer Appliance для перемещения больших объемов данных, загрузка которых может занять более недели. Чтобы сделать запрос, вы можете перейти на эту страницу.
В этом регионе интегрирована Cloud Interconnect, наша частная программно-определяемая сеть, которая обеспечивает быструю и надежную связь между всеми регионами мира. Вы можете использовать службы, которые в настоящее время недоступны в Цюрихском регионе через сеть Google, и комбинировать их с другими службами GCP, развернутыми по всему миру. Это позволяет быстро развертывать и расширять свою деятельность в разных регионах с помощью продуктов, предназначенных для глобального бизнеса.
Праздник с нашими швейцарскими клиентами
Мы запустили этот новый Цюрихский регион с событием, которое привлекло более 800 лиц, принимающих решения, и разработчиков. Урс Хёльцле, Техническая инфраструктура СВП, официально открыл регион. Клиенты из швейцарского и европейского фармацевтического, промышленного и финансового секторов смогли углубить свои знания о GCP и понять, как их деятельность в облаке может извлечь выгоду из этого нового региона.
Деятельность Swiss-AS направлена на поддержку AMOS, программного обеспечения для авиационной техники и технического обслуживания. Сегодня облачная платформа Google позволяет нам предоставлять наш облачный сервис AMOS в специальной облачной среде по всему миру. Благодаря локальному представительству GCP в Цюрихе, мы можем предложить наши услуги еще более тесно нашим клиентам AMOS в немецкоязычных странах— Алексис Рапиор, хостинговая команда, Swiss AviationSoftware ltd.
Этот новый швейцарский регион открывает новые и захватывающие возможности для сектора здравоохранения. Это позволит университетской больнице Балгрист предлагать новые технологии обработки в реальном времени. Сотрудничество в области медицинских исследований и разработок также будет проще и эффективнее— Томас Хагглер, исполнительный директор Университетской клиники Балгрист
Мы приветствуем появление облачной платформы Google в Швейцарии с энтузиазмом. С помощью Google Cloud мы можем сосредоточить наши усилия на разработке новых функций программного обеспечения для наших клиентов. Это дает нам возможность получить новую среду в считанные секунды— Марк Лоосли, главный инноватор, NeXora AG (подразделение группы Quickline)
Belimo является ведущим производителем приводов, клапанов и датчиков для систем отопления, вентиляции и кондиционирования воздуха (HVAC) по всему миру. Недавно технологии IoT позволили нам предлагать системы HVAC, управляемые устройствами, подключенными к облаку, что обеспечивает больший комфорт, энергоэффективность, безопасность, простоту установки и обслуживания. Компания Belimo выбрала GCP, потому что мы зависим от высокой доступности, надежности, производительности и масштабируемости наших глобальных облачных сервисов. Передовые технологии и инструменты GCP помогают нашим командам сосредоточиться на самых важных вещах— Питер Шмидлин, директор по инновациям, Belimo Automation AG
Вабион особенно доволен появлением Google Cloud в Швейцарии. Я искренне считаю, что это было лучшее, что могло произойти на швейцарском облачном рынке. У нас есть клиенты, которые очень заинтересованы в инновациях Google и до сих пор не мигрировали из-за отсутствия швейцарского хаба. Новый район Цюриха заполняет этот пробел и открывает перед Wabion огромные возможности для поддержки клиентов по мере их развития с помощью Google Cloud— Майкл Гомес, Со-менеджер, Wabion
Следующие шаги
Для получения дополнительной информации об этом регионе, не стесняйтесь посетить веб-страницу региона Цюриха, где вы можете получить доступ к бесплатным ресурсам, техническим документам, видео в облачном эфире по запросу. и многое другое. Если вы новичок в GCP, посетите страницы «Советы и рекомендации по выбору региона Compute Engine», чтобы начать работу сегодня.
В течение года мы будем открывать новые районы и районы GCP, начиная с Осаки. Наша страница, представляющая наши облачные географические зоны, регулярно обновляется с появлением наших новых услуг и дополнительных регионов.