TransMachine: сервис компании «Транслинк» на базе Yandex Translate

«Транслинк» входит в топ-5 российских компаний в сфере профессионального перевода. Компания создает цифровые продукты, которые снижают стоимость и увеличивают скорость перевода, что позволяет оставаться одним из лидеров индустрии.
В начале 2020 года компания «Транслинк» запустила новый продукт TransМасhine — сервис на основе технологий машинного перевода от Яндекс.Облака.
Как устроен TransMachine
Сервис использует доменно-адаптивный движок машинного перевода. Он постоянно обучается на текстах выбранной тематики и на памяти переводов (translation memory). TransMachine создан на базе Yandex Translate — облачного сервиса машинного перевода с использованием нейронной сети. Алгоритм Yandex Translate постоянно самообучается на большом количестве параллельных текстов, что повышает качество машинного перевода.
Пользователь также может загрузить в сервис свои глоссарии, чтобы термины и специфичные выражения в переводах конкретной тематики переводились однообразно. Перевод с помощью TransMachine дает более предсказуемый результат, чем перевод с помощью стокового движка машинного перевода. Сервис позволяет переводить сложные отраслевые тексты быстрее, сохраняя качество перевода.
Опыт применения
Одним из первых клиентов сервиса TransМасhine стал крупный холдинг, включающий десятки предприятий с сотнями сотрудников. Компании сотрудничают с зарубежными предприятиями. Количество общения с зарубежными партнерами выросло, что привело к росту объема документов на перевод.
Когда он достиг 500 страниц в месяц, компания столкнулась с выбором: продолжить использовать ручной перевод или попробовать машинный. Ручной перевод — трудоемкий, дорогой и долгий процесс. Было решено попробовать технологии машинного перевода, чтобы сэкономить бюджет и время.
От самостоятельного использования стоковых движков машинного перевода компания-заказчик отказалась почти сразу: из-за отраслевой специфики тексты перевода были очень низкого качества и требовали значительной редактуры.
Решение
Специалисты «ТрансЛинк» оценили эффективность ручного перевода, постредактуры машинного перевода (MT) и постредактуры перевода TransMachine. Они сравнили стоимость, временные затраты и качество результата и подготовили для заказчика следующую таблицу:
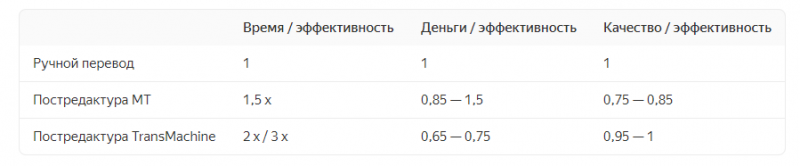
По подсчетам наиболее выгодным вариантом оказался сервис TransMachine: он в 2-3 раза быстрее на 30% дешевле ручного перевода, а качество готового текста примерно такое же.
Процесс
Специалисты «Транслинк» получали сканы документов компании в формате PDF, переводили их в читаемый формат и загружали в CAT-систему с подключенным облачным сервисом машинного перевода (MT).
«Транслинк» выделил под клиента отдельный домен MT, который постоянно дообучивается на текстах готовых переводов. Таким образом, алгоритм постепенно адаптируется под тексты заказчика, время на постредактуру снижается, а сроки сдачи работ сокращаются.
Результаты
Результаты тестового периода показали, что клиент сэкономил 30% бюджета, а скорость перевода выросла в 2 раза. Заказчик получает переведенные документы на 12-24 часов раньше. За счет обучения алгоритма объем перевода с января по март вырос в два раза: с 30 до 60 страниц в день.
Сейчас «Транслинк» работает над улучшением распознавания отсканированных и электронных документов, чтобы ускорить процесс перевода с помощью TransMachine.
Попробовать TransMachine → www.transmachine.ru