Защита от уязвимостей Meltdown и Spectre и лимиты на пропускную способность сетевых дисков

В сентябре прошлого года мы ввели лимиты на количество операций чтения и записи (input/output operations per second, IOPS) и на пропускную способность (bandwidth) сетевых SSD-дисков. Чтобы гарантировать производительность и безопасность при работе с виртуальными машинами и дисками в Облаке, мы переходим к следующим шагам.
Приводим фактические лимиты в соответствие с документацией
Мы старались, чтобы процесс ввода лимитов был плавным для тех пользователей, которые на тот момент использовали диски сверх ограничений. Поэтому фактические лимиты на пропускную способность сейчас выше, чем указано в документации.
С 12 мая 2020 года мы фиксируем лимиты на блоки размещения (allocation unit) для дисков:
- SSD, пропускная способность на чтение: 15 МБ/с на блок размещения (32 ГБ).
- SSD, пропускная способность на запись: 15 МБ/с на блок размещения (32 ГБ).
- HDD, пропускная способность на чтение: 30 МБ/с на блок размещения (256 ГБ).
- HDD, пропускная способность на запись: 30 МБ/с на блок размещения (256 ГБ).
- Чтение с SSD-диска размером менее 1 ТБ;
- Запись на SSD-диск размером менее 320 ГБ;
- Чтение с HDD-диска размером менее 2 ТБ;
- Запись на HDD-диск размером менее 1,25 ТБ.
Вводим ограничения на количество vCPU
Это ограничение связано с аппаратными уязвимостями Meltdown и Spectre, затрагивающими микропроцессоры Intel. Из-за этих уязвимостей вредоносный код может получить несанкционированный доступ на чтение к памяти других виртуальных машин на сервере. Поэтому использование виртуальных машин с определённым количеством ядер — 1, 18, 22, 26, 30 — мы считаем потенциально небезопасным и будем планово вводить ограничения на работу с такими конфигурациями. Ограничения будут применены не только к консоли управления, но и к интерфейсу командной строки CLI, API, SDK и Terraform.
Конфигурации с большим числом ядер менее востребованы, в то время как ВМ с 1 vCPU популярны за счёт низкой цены. Вводимые ограничения в первую очередь затронут вычислительные ресурсы с 1 vCPU на платформе Intel Broadwell (standard-v1).
Отказ от создания конфигураций с 1 vCPU
Управляемые базы данных
В первую очередь мы отказались от использования хостов с 1 vCPU на платформе Intel Broadwell в сервисах управляемых баз данных:
- Managed Service for PostgreSQL
- Managed Service for ClickHouse
- Managed Service for MongoDB
- Managed Service for MySQL
- Managed Service for Redis
- Data Proc (кластеры Apache Hadoop)
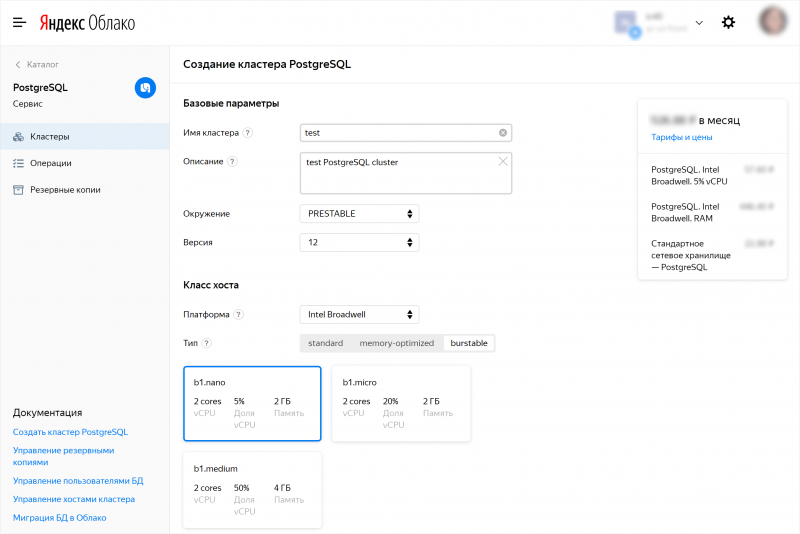
Все запущенные кластеры БД с конфигурациями с 1 vCPU продолжат работать. Добавить новые хосты в такие кластеры невозможно, пока не будут изменены хосты с 1 vCPU. Вы сможете изменить конфигурацию хостов самостоятельно до 1 июля 2020 года, затем они будут изменены на стороне сервиса.
Yandex Managed Service for Kubernetes
С 1 июля 2020 года при создании группы узлов кластера Managed Service for Kubernetes нельзя будет выбрать 1 vCPU на платформе Intel Broadwell (standard-v1) в блоке Вычислительные ресурсы для группы узлов.
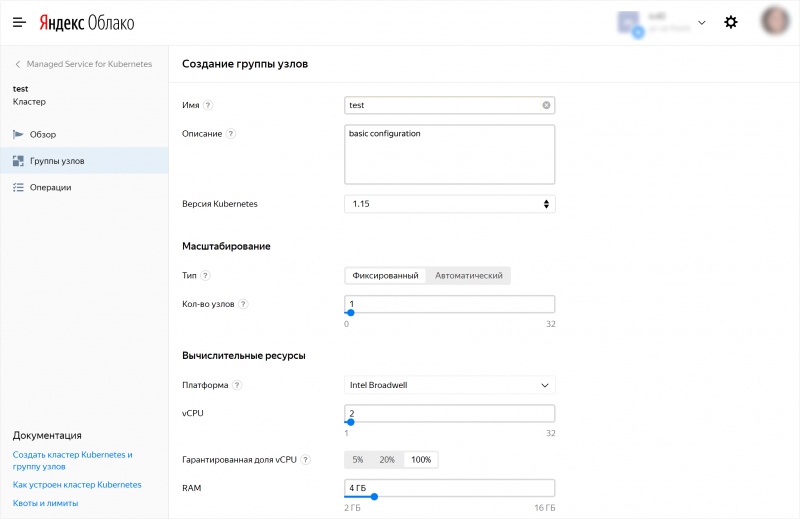
С этого момента перестанет работать автоматическое масштабирование и нельзя будет внести изменения в группу узлов. Группу узлов необходимо будет обновить с новой конфигурацией CPU/RAM со сменой платформы на Intel Cascade Lake (standard-v2).
Yandex Instance Groups
С 1 июля 2020 года вы не сможете выбрать шаблон виртуальной машины с 1 vCPU на платформе Intel Broadwell (standard-v1) при создании групп виртуальных машин в Instance Groups.
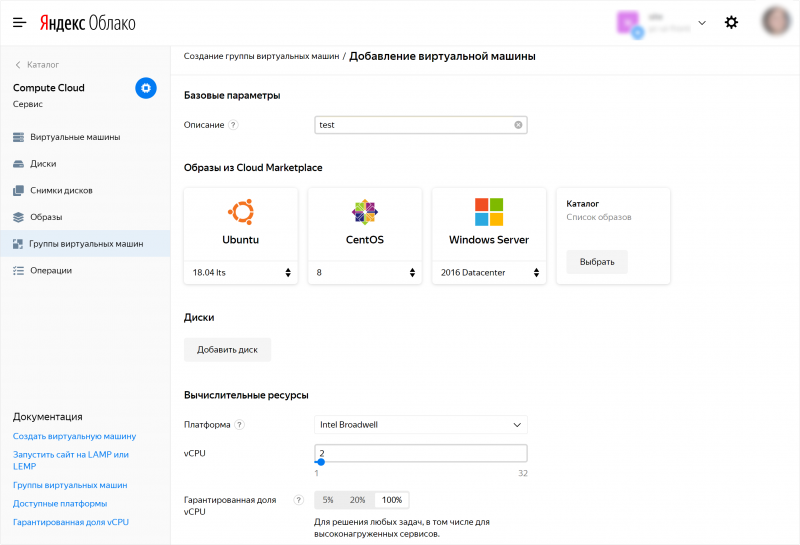
Для групп виртуальных машин, уже созданных на Intel Broadwell (standard-v1) с 1 vCPU, будет недоступно ручное и автоматическое масштабирование и автоматическое восстановление. Группу виртуальных машин необходимо будет обновить с новой конфигурацией CPU/RAM со сменой платформы на Intel Cascade Lake (standard-v2).
Совет
Если у вас в настоящее время используются виртуальные машины с 1, 18, 22, 26, 30 vCPU на платформе Intel Broadwell (standard-v1), мы рекомендуем до 1 июля 2020 года запланировать переход на конфигурацию с 2 vCPU или на платформу Intel Cascade Lake (standard-v2).
Ограничение на количество vCPU в Yandex Compute Cloud
С 1 июля 2020 года в сервисе Compute Cloud вы не сможете выбрать 1, 18, 22, 26, 30 vCPU при создании новых и изменении существующих виртуальных машин. Это ограничение будет применено ко всем инструментам в Облаке — консоли управления, интерфейсу командной строки CLI, API, SDK и Terraform. При этом вы сможете остановить, изменить и запустить существующие ВМ таких конфигураций.
Дальнейшие действия
До 1 июля 2020 года мы свяжемся с пользователями, использующими виртуальные машины с 1, 18, 22, 26, 30 vCPU в сервисах управляемых баз данных, Instance Groups и Managed Service for Kubernetes.
После 1 июля 2020 года такие ВМ будут принудительно остановлены и изменены одним из способов:
будет изменено количество vCPU:
- с 1 на 2,
- с 18 на 20,
- с 22 на 24,
- с 26 на 28,
- с 30 на 32;
О конфигурациях, которые будут использоваться при переходе, мы сообщим заранее. Виртуальные машины с 1, 18, 22, 26, 30 vCPU, созданные в сервисе Compute Cloud, будут изменены в последнюю очередь. О точной дате мы сообщим в отдельном посте.
0 комментариев
Вставка изображения
Оставить комментарий