Yandex.Cloud. Эпизод 1. Скрытые возможности дата-центров
Как устроены дата-центры? Почему мы сами проектируем и собираем стойки? Как мы определяем SLA и принимаем решения, которые непосредственно формируют надёжность и отказоустойчивость облачных сервисов? Открываем серию статей, в которых подробно расскажем о внутреннем устройстве нашей облачной платформы — от ЦОДов до работы технической поддержки, — а вы узнаете какие вопросы нужно задавать и какие меры принимать, чтобы ваша компания всегда была онлайн.

Наши дата-центры: разработаны и построены Яндексом
Компании и люди по всему миру каждый день генерируют терабайты данных, которые как минимум нужно хранить, а как максимум — обрабатывать и анализировать. Для этого по всему миру строятся дата-центры —огромные, специально спроектированные, сложные инженерные сооружение, которые способны обеспечивать непрерывную работу мощных серверов.
Но мало построить ЦОД и наполнить его оборудованием, нужно предусмотреть бесперебойную работу множества главных и вспомогательных систем. В первую очередь это касается электричества и охлаждения. Понимая, что серверные мощности будут расти с каждым годом, ЦОДы уже сейчас строятся рядом с дешёвыми и надежными источниками электроэнергии.
Все современные технологические гиганты, такие, как Google, Facebook, Microsoft и, конечно Яндекс, стремясь добиться максимальной надёжности и энергоэффективности, возводят распределённые сети собственных дата-центров. Именно в них и «живут» облака.
Tier дата-центра: так ли важен этот сертификат?
Главные показатели надёжности любого дата-центра — его отказоустойчивость и количество резервных инженерных систем. Опираясь на эту концепцию, в мире используется международный стандарт TIA-942 и система классификации института Uptime. Согласно нему, все ЦОДы характеризуется уровнем Tier и оценивается по 4-балльной системе:
Проблема с такой классификацией в том, что на всех уровнях учитываются в основном схемотехнические и инженерные особенности. Изначально стандарт создавался для определения отказоустойчивости коммерческих дата-центров. Более того, получение сертификата Tier никак не измеряет реальное значение доступности услуг. Что же остается за кадром? Например:
Очевидно, что можно построить ЦОД, отвечающий самым высоким требованиям по схеме резервирования, который в реальной жизни не будет выдавать заявленные характеристики. Как говорят инженеры, «ток течет не по сертификатам, а по проводам».
Также, в современных реалиях необходимо включить в уравнение надёжность сетевой инфраструктуры и компонентов облачной платформы, используемой провайдером ЦОД.
Новый уровень надёжности — сертификация на операционную устойчивость
Следует заметить, что Uptime Institute учитывает приведенные выше факторы и предлагает коммерческим ЦОД пройти сертификацию на операционную устойчивость. Процедура сертификации сфокусирована не на проектном решении или его реализации, а на том, насколько команда эксплуатации способна профессионально его обслуживать и применять процессы, обеспечивающие максимальную надежность работы оборудования и минимум ошибок при выполнении всех видов обслуживания.
Проанализировав содержание и смысл такой сертификации, команда эксплуатации Яндекса пришла к выводу, что она применима не только для коммерческих, но, с небольшими коррективами, и для корпоративных ЦОД. Как результат, в 2018 году мы в качестве эксперимента прошли сертификацию M& O, убедившись, что принципы, которые мы используем для работы в наших ЦОД полностью соответствуют тем же высоким требованиям, что выдвигаются и к лучшим коммерческим ЦОД. На сегодняшний день в России только три ЦОД прошли такую сертификацию. Сравните эту цифру с полусотней обладателей сертификата Tier: uptimeinstitute.com/uptime-institute-awards/list.
SLA — уровень обслуживания, под которым мы подписались
Вместо подтверждения Tier, на данный момент, Яндекс предлагает соглашение об уровне обслуживания — SLA. Такой договор между клиентом и оператором дата-центра формализует и делает более прозрачным взаимодействие с потребителями услуг, и, конечно, гарантирует высокий уровень надёжности и бесперебойную работу в любых ситуациях. Это достигается за счет использования собственных инженерных решений, о которых будет рассказано ниже, соответствия процессов эксплуатации инженерной инфраструктуры лучшим практикам и применением современных подходов к обеспечению отказоустойчивости на уровне программных решений облачной инфраструктуры и сервисов.
Стоит сразу отметить, что фактические показали непрерывной работы дата-центров, которые использует Yandex.Cloud, за три последних года не опускались ниже 99,9996%, что фактически выше уровня Tier 3.
Мы сами разработали стойки, серверы и системы управления для экономии денег, времени и электричества
Яндекс построил и использует три основных дата-центра: Сасово, Владимир и Мытищи, соединённых между собой оптической кабельной сетью с очень высокой пропускной способностью — несколько терабит в секунду. Они образуют распределенную систему, которая позволяет балансировать нагрузку и резервировать не только отдельные инженерные системы на уровне каждого ЦОД, но и сами ЦОД.

Конечно, основная задача дата-центра — хранение данных и выполнение вычислений. В Яндексе устанавливаются сервера и серверные стойки, произведённые вендорами по нашей спецификации.
До 2011 года оборудование было чужое. Это приводило к тому, что серверы от различных производителей по-разному вели себя под одинаковой нагрузкой. Встречались даже ситуации, когда потребление воздуха у одних было в несколько раз больше, чем у других, и их нельзя было ставить рядом. Сильно потребляющие воздух сервера «отъедали» его у своих соседей, создавая зоны локального разряжения. Это приводило к появлению дисбаланса и необходимости ручного управления, словом, к потере времени, энергии и денег.
В 2011 году мы окончательно поняли, что нам нужны свои серверы и стойки. Под стойкой мы подразумеваем не просто металлический шкаф, в который устанавливаются серверы, а законченный модуль, в котором используются общие блоки питания, общее охлаждение и общее управление. В настоящее время используется уже третья версия стоек, а постоянно изменяющиеся требования заказчиков найдут свое отражение в новых версиях в ближайшее время.
Собирают стойки 3.0 на заводе в Китае, где налажена отдельная производственная линия. Во время сборки в систему управления стойки прошивается разработанное Яндексом программное обеспечение, основанное на проекте OpenBMC. Благодаря этому удалось реализовать алгоритм термостатирования температур процессоров — мы можем задавать их для каждой стойки (и даже для каждого сервера, но в этом обычно нет необходимости) с помощью внешнего интерфейса (API) системы управления.
Электричество в дата-центрах: прямое подключение и генераторы
Качественное железо, уникальные сервисы — всё это может пропасть в один момент, если правильно не спроектировать бесперебойное электроснабжение. Дата-центр может быть автономной структурой, но он всегда подключён к внешней электрической сети, а значит, не застрахован от форсмажоров. Однако, в зависимости от типа подключений и возраста оборудования можно достаточно достоверно спрогнозировать частоту проблем с электропитанием. Поэтому подход, избранный Яндексом — подключение по линиям высокого напряжения (110 кВ и выше) непосредственно к сетям национальных операторов со строительством собственных кабельных линий и подстанций.
Бесперебойность обычно обеспечивает классической схемой — комплексом «ИБП + дизель-генераторная установка (ДГУ)». Это классическая и отработанная годами схема работы для обеспечения бесперебойного питания в ДЦ. Она имеет массу плюсов — относительная простота, высокая надёжность, практически неограниченное время работы на дизелях. Но и свои минусы: как технические — необходимы достаточно большие площади для размещения оборудования, которые нужно обязательно оборудовать системами поддержания заданных климатических параметров, так и финансовые — при больших мощностях это решение получается достаточно дорогим.
В настоящее время Яндекс использует технологию ДРИБП — Дизельных Роторных Источников Бесперебойного Питания (DRUPS — Diesel Rotary Uninterruptible Power Supply). ДРИБП запасает не электрическую, а кинетическую энергию: внешнее электричество питает электромотор, который вращает огромный маховик и через дроссель вырабатывает «очищенное» питание. То есть ДРИБП выполняет функции стабилизатора и фильтра напряжения. Если внешнее напряжение пропадает, мотор превращается в генератор, вращение которого поддерживается вращающимся по инерции маховиком. В это время происходит запуск дизель-генератора.
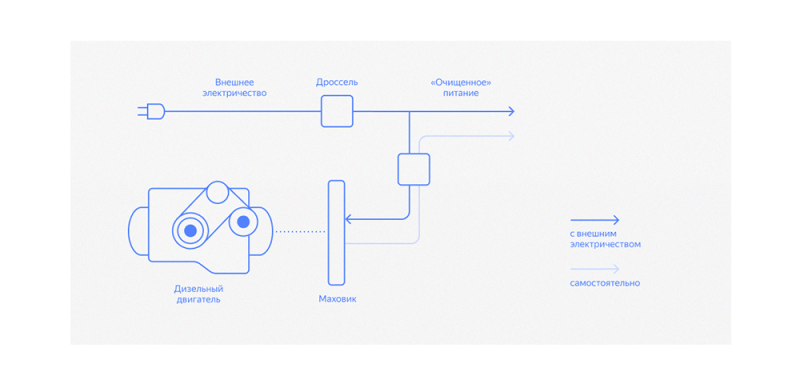
В наших ЦОД используются ДРИБП разных производителей, отличающиеся в деталях реализации. Однако, в целом, такой вид ИБП показал свою жизнеспособность в условиях ЦОД. Конечно, как и всякое оборудование, эти сложные устройства требуют внимания и аккуратности при обслуживании. Поэтому внутри нашей команды эксплуатации организованы специальные группы специалистов по силовому оборудованию, обученные непосредственно производителями и способные решать большинство задач по обслуживанию ИБП без привлечения сторонних организаций.
Охладить и не прогореть. При чем тут фрикулинг?
Другая важнейшая проблема любого ЦОД — отвод тепла от стоек. Однако, в данном случае охлаждение это не просто вопрос количества охлаждающих элементов. Чем сложнее система кондиционирования, тем больше она потребляет электричества и тем чаще возникают различные поломки, которые могут даже останавливать работу всего дата-центра.
В качестве системы охлаждения Яндекс использует концепцию фрикулинга в самом прямом смысле этого слова. Его смысл заключается в том, что разработанное нами серверное оборудование способно работать при достаточно высоких температурах входящего воздуха. Поэтому охлаждать серверные стойки можно самым обычным уличным воздухом и зимой, и летом. Самое важное — специально продуманный дизайн серверного оборудования и всего дата-центра.
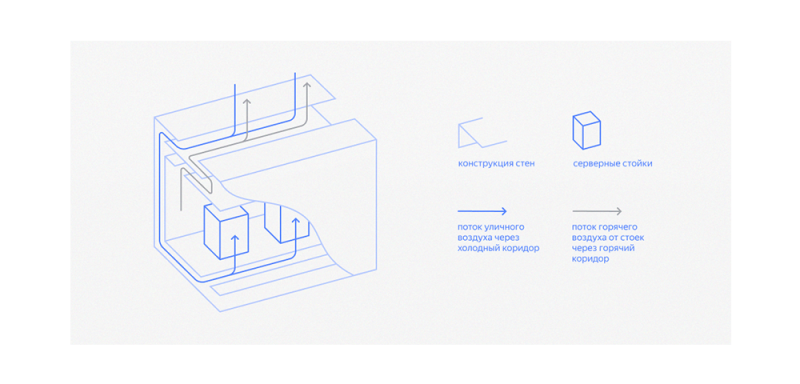
В дата-центре с фрикулингом весь процесс охлаждения устроен примерно так: приточные вентиляторы через фильтры нагнетают уличный воздух в холодный коридор, он проходит через серверные стойки, нагревается, из горячего коридора собирается в коллекторе, а дальше часть удаляется наружу вытяжными вентиляторами, а часть используется для смешивания с поступающим снаружи воздухом, чтобы поддерживать его температуру на стабильном уровне. Если температура на улице выше 20 градусов, то весь горячий воздух выводится наружу. Для того, чтобы воздушные массы двигались только в нужном направлении (холодный коридор, горячий коридор, горячий коллектор), между ними поддерживаются небольшие перепады давления. Это можно сделать, регулируя работу вентиляторов притока и вытяжки и настраивая балансировочные клапаны между горячими коридорами и горячим коллектором.
Главное достоинство такой системы — сравнительно низкое потребление энергии, которая нужна только для работы вентиляторов, и простота — здесь нет громоздкого и сложного холодильного оборудования, которое может сломаться и нарушить стабильность работы. Именно фрикулинг позволяет Яндексу гордиться энергоэффективностью своих дата-центров последнего поколения: в Сасово и Владимире мы добились показателя PUE — эффективности использования энергии — в пределах 1,05-1,07. При этом надежность системы охлаждения возросла, так как количество компонентов в ней существенно снизилось.
9 ответов про дата-центры, которые помогут оценить надёжность облака
Итак, мы разобрались, что в основе надёжности любой облачной платформы лежит дата-центр или система дата-центров. Это значит, что первым делом при выборе «облака» вы должны задать следующие вопросы:
Однако, это далеко не все аспекты надёжности и безопасности облачной платформы, которые должны обеспечить бесперебойную работу вашего бизнеса. В следующей статье мы расскажем, как работаем со сбоями и инцидентами в работе платформы, объясним, чем отличаются эти события и какие меры принимаются Яндексом, чтобы клиенты их практически не замечали.
Наши дата-центры: разработаны и построены Яндексом
Компании и люди по всему миру каждый день генерируют терабайты данных, которые как минимум нужно хранить, а как максимум — обрабатывать и анализировать. Для этого по всему миру строятся дата-центры —огромные, специально спроектированные, сложные инженерные сооружение, которые способны обеспечивать непрерывную работу мощных серверов.
Но мало построить ЦОД и наполнить его оборудованием, нужно предусмотреть бесперебойную работу множества главных и вспомогательных систем. В первую очередь это касается электричества и охлаждения. Понимая, что серверные мощности будут расти с каждым годом, ЦОДы уже сейчас строятся рядом с дешёвыми и надежными источниками электроэнергии.
Все современные технологические гиганты, такие, как Google, Facebook, Microsoft и, конечно Яндекс, стремясь добиться максимальной надёжности и энергоэффективности, возводят распределённые сети собственных дата-центров. Именно в них и «живут» облака.
Tier дата-центра: так ли важен этот сертификат?
Главные показатели надёжности любого дата-центра — его отказоустойчивость и количество резервных инженерных систем. Опираясь на эту концепцию, в мире используется международный стандарт TIA-942 и система классификации института Uptime. Согласно нему, все ЦОДы характеризуется уровнем Tier и оценивается по 4-балльной системе:
- Tier 1 — начальный уровень. В таких ЦОД нет запасных ресурсов и резервирования критически важных элементов. Допустимое время простоя в год — 28,8 часа, и, соответственно, показатель доступности и устойчивости к отказам в процентном соотношении — 99,671%. Выход из строя любой системы приводит к остановке и нарушениям работы всего дата-центра.
- Tier 2 — закладывается резервирование и запасные ресурсы. Устанавливаются современные системы охлаждения и энергосбережения. Ежегодный простой — 22 часа, доступность — 99,7%. При замене неисправного оборудования или во время плановых работ полностью или частично останавливается работа ЦОД.
- Tier 3 — можно ремонтировать и обновлять дата-центр без остановки и прекращения работы. В течение одного года простой ЦОДа третьего уровня составляет всего 1,6 часа, а устойчивость к отказу — 99,9%.
- Tier 4 — сохранность данных и бесперебойная работа даже при поломке конкретного элемента и при возникновении системных сбоев. Полное резервирование всех компонентов. В течение 12 месяцев ЦОД четвёртого уровня может останавливаться только на 0,4 часа, а уровень устойчивости к отказам таких объектов составляет практически 100 процентов.
Проблема с такой классификацией в том, что на всех уровнях учитываются в основном схемотехнические и инженерные особенности. Изначально стандарт создавался для определения отказоустойчивости коммерческих дата-центров. Более того, получение сертификата Tier никак не измеряет реальное значение доступности услуг. Что же остается за кадром? Например:
- Реальная надежность поставщиков электроэнергии.
- Особенности эксплуатации каждого устройства, включая режим, в котором оно будет использоваться, показатели его собственной надежности, условия сопряжения именно этого оборудования с другими элементами системы
- Человеческий фактор.
Очевидно, что можно построить ЦОД, отвечающий самым высоким требованиям по схеме резервирования, который в реальной жизни не будет выдавать заявленные характеристики. Как говорят инженеры, «ток течет не по сертификатам, а по проводам».
Также, в современных реалиях необходимо включить в уравнение надёжность сетевой инфраструктуры и компонентов облачной платформы, используемой провайдером ЦОД.
Новый уровень надёжности — сертификация на операционную устойчивость
Следует заметить, что Uptime Institute учитывает приведенные выше факторы и предлагает коммерческим ЦОД пройти сертификацию на операционную устойчивость. Процедура сертификации сфокусирована не на проектном решении или его реализации, а на том, насколько команда эксплуатации способна профессионально его обслуживать и применять процессы, обеспечивающие максимальную надежность работы оборудования и минимум ошибок при выполнении всех видов обслуживания.
Проанализировав содержание и смысл такой сертификации, команда эксплуатации Яндекса пришла к выводу, что она применима не только для коммерческих, но, с небольшими коррективами, и для корпоративных ЦОД. Как результат, в 2018 году мы в качестве эксперимента прошли сертификацию M& O, убедившись, что принципы, которые мы используем для работы в наших ЦОД полностью соответствуют тем же высоким требованиям, что выдвигаются и к лучшим коммерческим ЦОД. На сегодняшний день в России только три ЦОД прошли такую сертификацию. Сравните эту цифру с полусотней обладателей сертификата Tier: uptimeinstitute.com/uptime-institute-awards/list.
SLA — уровень обслуживания, под которым мы подписались
Вместо подтверждения Tier, на данный момент, Яндекс предлагает соглашение об уровне обслуживания — SLA. Такой договор между клиентом и оператором дата-центра формализует и делает более прозрачным взаимодействие с потребителями услуг, и, конечно, гарантирует высокий уровень надёжности и бесперебойную работу в любых ситуациях. Это достигается за счет использования собственных инженерных решений, о которых будет рассказано ниже, соответствия процессов эксплуатации инженерной инфраструктуры лучшим практикам и применением современных подходов к обеспечению отказоустойчивости на уровне программных решений облачной инфраструктуры и сервисов.
Стоит сразу отметить, что фактические показали непрерывной работы дата-центров, которые использует Yandex.Cloud, за три последних года не опускались ниже 99,9996%, что фактически выше уровня Tier 3.
Мы сами разработали стойки, серверы и системы управления для экономии денег, времени и электричества
Яндекс построил и использует три основных дата-центра: Сасово, Владимир и Мытищи, соединённых между собой оптической кабельной сетью с очень высокой пропускной способностью — несколько терабит в секунду. Они образуют распределенную систему, которая позволяет балансировать нагрузку и резервировать не только отдельные инженерные системы на уровне каждого ЦОД, но и сами ЦОД.
Конечно, основная задача дата-центра — хранение данных и выполнение вычислений. В Яндексе устанавливаются сервера и серверные стойки, произведённые вендорами по нашей спецификации.
До 2011 года оборудование было чужое. Это приводило к тому, что серверы от различных производителей по-разному вели себя под одинаковой нагрузкой. Встречались даже ситуации, когда потребление воздуха у одних было в несколько раз больше, чем у других, и их нельзя было ставить рядом. Сильно потребляющие воздух сервера «отъедали» его у своих соседей, создавая зоны локального разряжения. Это приводило к появлению дисбаланса и необходимости ручного управления, словом, к потере времени, энергии и денег.
В 2011 году мы окончательно поняли, что нам нужны свои серверы и стойки. Под стойкой мы подразумеваем не просто металлический шкаф, в который устанавливаются серверы, а законченный модуль, в котором используются общие блоки питания, общее охлаждение и общее управление. В настоящее время используется уже третья версия стоек, а постоянно изменяющиеся требования заказчиков найдут свое отражение в новых версиях в ближайшее время.
Собирают стойки 3.0 на заводе в Китае, где налажена отдельная производственная линия. Во время сборки в систему управления стойки прошивается разработанное Яндексом программное обеспечение, основанное на проекте OpenBMC. Благодаря этому удалось реализовать алгоритм термостатирования температур процессоров — мы можем задавать их для каждой стойки (и даже для каждого сервера, но в этом обычно нет необходимости) с помощью внешнего интерфейса (API) системы управления.
Электричество в дата-центрах: прямое подключение и генераторы
Качественное железо, уникальные сервисы — всё это может пропасть в один момент, если правильно не спроектировать бесперебойное электроснабжение. Дата-центр может быть автономной структурой, но он всегда подключён к внешней электрической сети, а значит, не застрахован от форсмажоров. Однако, в зависимости от типа подключений и возраста оборудования можно достаточно достоверно спрогнозировать частоту проблем с электропитанием. Поэтому подход, избранный Яндексом — подключение по линиям высокого напряжения (110 кВ и выше) непосредственно к сетям национальных операторов со строительством собственных кабельных линий и подстанций.
Бесперебойность обычно обеспечивает классической схемой — комплексом «ИБП + дизель-генераторная установка (ДГУ)». Это классическая и отработанная годами схема работы для обеспечения бесперебойного питания в ДЦ. Она имеет массу плюсов — относительная простота, высокая надёжность, практически неограниченное время работы на дизелях. Но и свои минусы: как технические — необходимы достаточно большие площади для размещения оборудования, которые нужно обязательно оборудовать системами поддержания заданных климатических параметров, так и финансовые — при больших мощностях это решение получается достаточно дорогим.
В настоящее время Яндекс использует технологию ДРИБП — Дизельных Роторных Источников Бесперебойного Питания (DRUPS — Diesel Rotary Uninterruptible Power Supply). ДРИБП запасает не электрическую, а кинетическую энергию: внешнее электричество питает электромотор, который вращает огромный маховик и через дроссель вырабатывает «очищенное» питание. То есть ДРИБП выполняет функции стабилизатора и фильтра напряжения. Если внешнее напряжение пропадает, мотор превращается в генератор, вращение которого поддерживается вращающимся по инерции маховиком. В это время происходит запуск дизель-генератора.
В наших ЦОД используются ДРИБП разных производителей, отличающиеся в деталях реализации. Однако, в целом, такой вид ИБП показал свою жизнеспособность в условиях ЦОД. Конечно, как и всякое оборудование, эти сложные устройства требуют внимания и аккуратности при обслуживании. Поэтому внутри нашей команды эксплуатации организованы специальные группы специалистов по силовому оборудованию, обученные непосредственно производителями и способные решать большинство задач по обслуживанию ИБП без привлечения сторонних организаций.
Охладить и не прогореть. При чем тут фрикулинг?
Другая важнейшая проблема любого ЦОД — отвод тепла от стоек. Однако, в данном случае охлаждение это не просто вопрос количества охлаждающих элементов. Чем сложнее система кондиционирования, тем больше она потребляет электричества и тем чаще возникают различные поломки, которые могут даже останавливать работу всего дата-центра.
В качестве системы охлаждения Яндекс использует концепцию фрикулинга в самом прямом смысле этого слова. Его смысл заключается в том, что разработанное нами серверное оборудование способно работать при достаточно высоких температурах входящего воздуха. Поэтому охлаждать серверные стойки можно самым обычным уличным воздухом и зимой, и летом. Самое важное — специально продуманный дизайн серверного оборудования и всего дата-центра.
В дата-центре с фрикулингом весь процесс охлаждения устроен примерно так: приточные вентиляторы через фильтры нагнетают уличный воздух в холодный коридор, он проходит через серверные стойки, нагревается, из горячего коридора собирается в коллекторе, а дальше часть удаляется наружу вытяжными вентиляторами, а часть используется для смешивания с поступающим снаружи воздухом, чтобы поддерживать его температуру на стабильном уровне. Если температура на улице выше 20 градусов, то весь горячий воздух выводится наружу. Для того, чтобы воздушные массы двигались только в нужном направлении (холодный коридор, горячий коридор, горячий коллектор), между ними поддерживаются небольшие перепады давления. Это можно сделать, регулируя работу вентиляторов притока и вытяжки и настраивая балансировочные клапаны между горячими коридорами и горячим коллектором.
Главное достоинство такой системы — сравнительно низкое потребление энергии, которая нужна только для работы вентиляторов, и простота — здесь нет громоздкого и сложного холодильного оборудования, которое может сломаться и нарушить стабильность работы. Именно фрикулинг позволяет Яндексу гордиться энергоэффективностью своих дата-центров последнего поколения: в Сасово и Владимире мы добились показателя PUE — эффективности использования энергии — в пределах 1,05-1,07. При этом надежность системы охлаждения возросла, так как количество компонентов в ней существенно снизилось.
9 ответов про дата-центры, которые помогут оценить надёжность облака
Итак, мы разобрались, что в основе надёжности любой облачной платформы лежит дата-центр или система дата-центров. Это значит, что первым делом при выборе «облака» вы должны задать следующие вопросы:
- Сколько дата-центров обслуживает «облако»?
- Где они расположены?
- Как они связаны между собой?
- Как обеспечивается надёжность и отказоустойчивость ЦОДа?
- Достаточно ли компетентна команда эксплуатации выбранного ЦОД?
- Какой уровень SLA предоставляет облачный провайдер на каждый из своих сервисов?
- Какие сервера используются в ЦОД?
- Как они управляются и как быстро могут быть заменены в случае аварии?
- Как обеспечивается безопасность ЦОД? Электричество? Охлаждение?
Однако, это далеко не все аспекты надёжности и безопасности облачной платформы, которые должны обеспечить бесперебойную работу вашего бизнеса. В следующей статье мы расскажем, как работаем со сбоями и инцидентами в работе платформы, объясним, чем отличаются эти события и какие меры принимаются Яндексом, чтобы клиенты их практически не замечали.
0 комментариев
Вставка изображения
Оставить комментарий