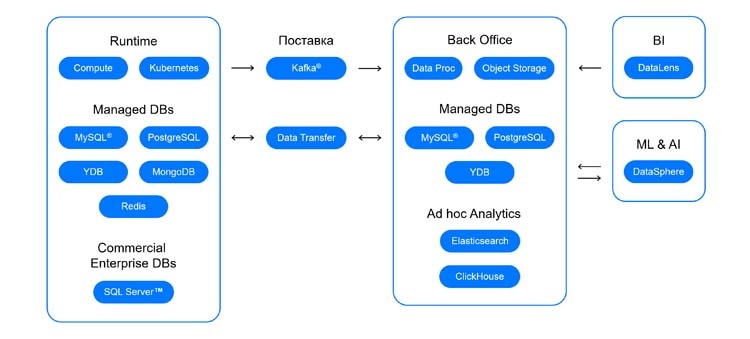
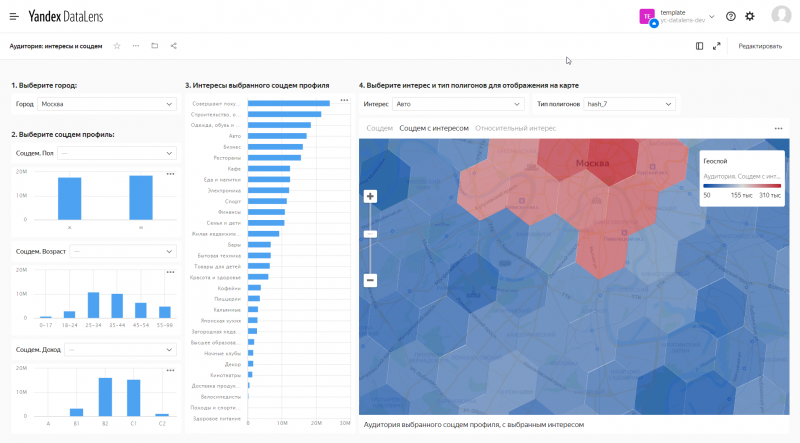
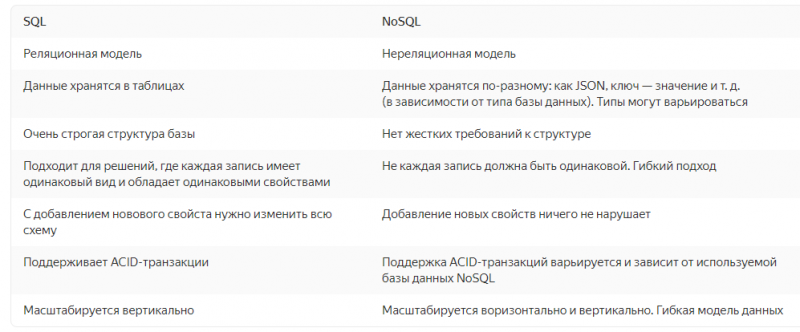
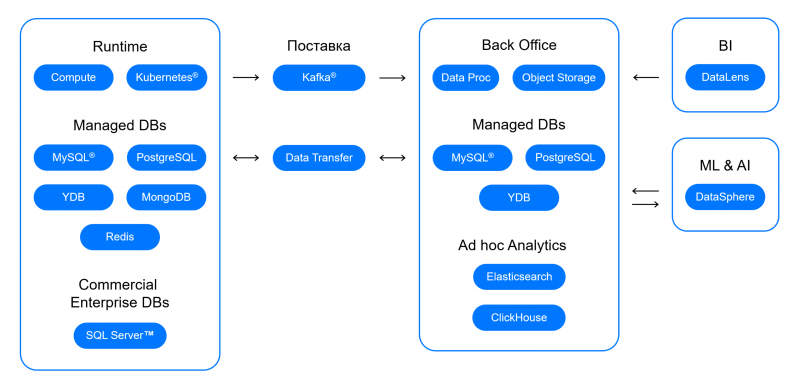
Дайджест новостей за декабрь–январь

Безопасность
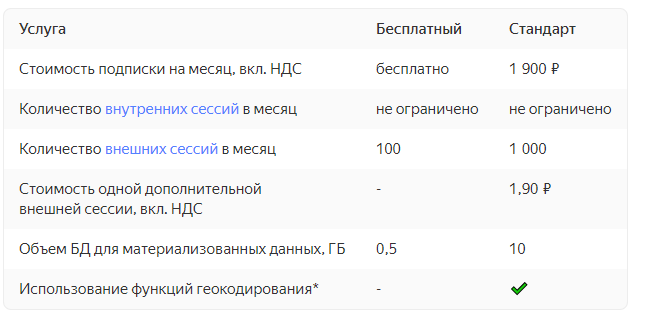
Платформа Yandex.Cloud получила подтверждение соответствия международному стандарту безопасности данных платежных карт PCI DSS (Payment Card Industry Data Security Standard) и высшему уровню защищенности персональных данных УЗ-1. Теперь вы можете хранить и обрабатывать в облаке данные платежных карт, а также медицинские, специальные и биометрические данные.
storage.yandexcloud.net/yc-compliance/conformance_ru_new.pdf
На странице Безопасность мы выложили все подтверждающие документы и описали, как построена архитектура для соответствия PCI DSS в Yandex.Cloud.
cloud.yandex.ru/security
Yandex Certificate Manager
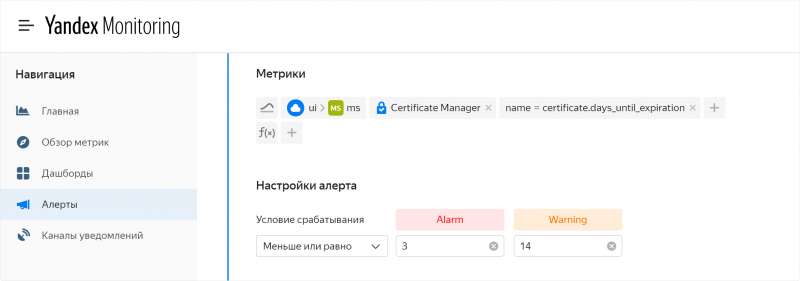
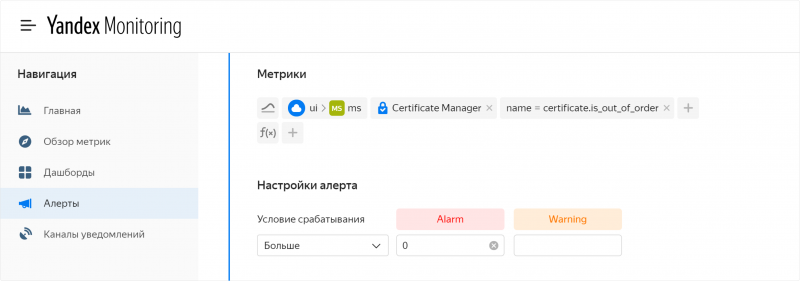
Сервис для управления TLS-сертификатами Yandex Certificate Manager теперь интегрирован с Yandex Monitoring.
Monitoring позволяет отправлять сервису метрики по сертификатам, а также настраивать алерты для этих метрик. Из метрик можно узнать, сколько дней осталось до истечения сертификата, о его неработоспособности и текущее потребление квоты. Вы можете наблюдать за графиками метрик на сервисных или собственных дашбордах и подписываться на оповещения через email или sms.
Yandex Managed Service for MongoDB
Изменились политики резервного копирования в Yandex Managed Service for MongoDB. Для автоматических резервных копий можно выбрать период хранения от 7 до 35 дней, а для ручных копий бессрочно. Функционалность находится на стадии Preview.
Yandex Instance Groups
Обновились стратегии остановки виртуальных машин. Можно выбрать две опции остановки: принудительную (PROACTIVE) или деликатную (OPPORTUNISTIC):
- Если выбрана принудительная стратегия, Instance Groups самостоятельно выбирает, какие виртуальные машины остановить.
- При деликатной стратегии Instance Groups не останавливает виртуальные машины, а ожидает выполнения некоторых условий.
Yandex Object Storage
Теперь вы можете управлять облачных хранилищем из мобильного приложения Yandex.Cloud.
Terraform
Вышло несколько улучшений TerraForm для сервисов управляемых баз данных, Yandex Virtual Private Cloud, Yandex Compute Cloud и Yandex Object Storage.
Новые образы в Marketplace
В Yandex Cloud Marketplace вышли новые образы операционных систем с поддержкой GPU:
- CentOS 7 GPU
- Ubuntu 16.04 LTS GPU
- Ubuntu 18.04 LTS vGPU
- Ubuntu 18.04 LTS GPU
- Debian 10 GPU
- CentOS 8 GPU
- Ubuntu 20.04 LTS GPU
Albato 130+ интеграций
Мероприятия
26 января состоялся вебинар по практическому применению Serverless. Мы показали, как интегрировать сервисы Yandex.Cloud с голосовыми технологиями компании Voximplant, и рассказали, зачем это нужно.
Набираем обороты после большого отдыха. В феврале вас ждут 5 мероприятий, посвященных безопасности, ML-технологиям и речевой аналитике. Регистрация уже открыта.
cloud.yandex.ru/events
Публикации в СМИ
За какими трендами в развитии речевых технологий следить в 2021 году
Менеджер по развитию ML-сервисов Yandex.Cloud Никита Ткачев рассказал о главных трендах в развитии речевых технологий в 2021 году и о том, что дает бизнесу их кастомизация. rb.ru/opinion/rechtehnologij-v-2021/
Как облачные технологии помогают медицине меняться
Руководитель направления по работе с клиентами медицинского сектора платформы Yandex.Cloud Евгений Михайленко рассказал о востребованных направлениях развития облачных технологий в медицине. hightech.fm/2020/12/24/clouds-medicine
Коронакризис гонит финансистов в облака
Руководитель по работе с финансовым сектором Yandex.Cloud Александр Черников рассказал про развитие облачных технологий и их применение в финансовой сфере. nbj.ru/publs/upgrade-modernizatsija-i-razvitie/2020/12/29/koronakrizis-gonit-finansistov-v-oblaka/index.html
Истории успеха
Как сервис Yandex Vision помог роботизировать логистические задачи
С применением робота ElectroNeek Studio и Yandex Vision крупной торгово-промышленной компании удалось существенно ускорить работу с документами на отгрузку. Робот справляется с внесением и проверкой данных в восемь раз быстрее человека — всего за 30 секунд. Ошибок при внесении данных теперь не возникает, и сотрудникам не надо тратить время на проверку и исправления. cloud.yandex.ru/cases/electroneek
Как в МОЭК создали систему для автоматического приема показаний счетчиков по телефону
Команде разработки МОЭК требовалось оптимизировать две внутренние задачи, одна из которых заставляла пользователей тратить много времени на звонки в компанию, а вторая отнимала много времени у сотрудников контакт-центра. Всего за месяц штатными специалистами были разработаны все алгоритмы, и система заработала на производстве. cloud.yandex.ru/cases/moek
Как Авто.ру провел экзамен по ПДД с помощью serverless-технологий
Компания foobar.engineering использовала serverless-технологии от Yandex.Cloud для реализации социального проекта «Большой экзамен ПДД» на сервисе Авто.ру. Благодаря выбору Yandex Cloud Functions и Yandex Database разработчики занимались только кодом, а не переживали за настройку и поддержку серверов с приложением, масштабирование и добавление ресурсов СУБД. cloud.yandex.ru/cases/autoru
Как биоинформатики Genotek разработали сервис генеалогических деревьев
Биоинформатики компании Genotek с помощью Yandex Cloud Functions разработали новый сервис для создания генеалогических деревьев. Применение serverless-подхода позволило биоинформатикам сосредоточиться только на написании или интеграции кода и не задумываться о производительности, обслуживании и масштабировании баз данных. cloud.yandex.ru/cases/genotek-genealogical-tree