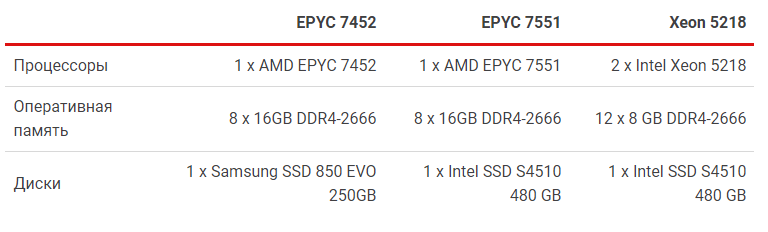
Из Неаполя в Рим: новые CPU AMD EPYC

Седьмого августа был объявлен мировой старт продаж второго поколения линейки AMD EPYC. Новые процессоры базируются на микроархитектуре Zen 2 и построены по 7-нм технологическому процессу.
Особенности

«Встречают по одежке, провожают по уму», — гласит народная мудрость. Вот и мы начнем с «одежки» нового поколения. Маркировка процессоров претерпела незначительные изменения: четвертая цифра, обозначающая поколение, сменилась с 1 на 2. Первая цифра, как и ранее, обозначает серию, а вторая и третья — модель. AMD не отказались от процессоров с индексом P, которые не поддерживают работу в многосокетных системах.
Второе поколение унаследовало сокет SP3 от первого поколения без изменений, что позволяет использовать новые процессоры без обновления материнской платы, но это не сможет полностью раскрыть их потенциал. Достижение полной производительности возможно с использованием новых материнских плат, поддерживающих частоты 3200 МГц для памяти DDR4.
«Начинка» процессора преобразилась до неузнаваемости: изменился технологический процесс, была применена новая микроархитектура Zen 2 и появился новый высокоскоростной контроллер оперативной памяти.
Производительность
Переход на 7-нм технологический процесс привел к уплотнению кристалла и увеличению количества ядер до 64, что вдвое выше по сравнению с первым поколением. Базовая частота процессоров второго поколения находится в диапазоне от 2.00 до 2.90 ГГц. Для сравнения, базовая первого поколения не превышала 2.30 ГГц. Увеличение количества ядер и базовой частоты процессора стали причиной повышения тепловыделения до 120 Ватт в бюджетных версиях и до 225 Ватт в топовых.
Улучшение технологического процесса не единственное нововведение. Новая микроархитектура под названием Zen 2 внесла свою «лепту» в улучшение технических характеристик процессора. Улучшения нацелены на взаимодействие с кэшами: вдвое увеличилась скорость обмена данными с L1, увеличена скорость передачи данных между кэшами, увеличен размер L3-кэша.
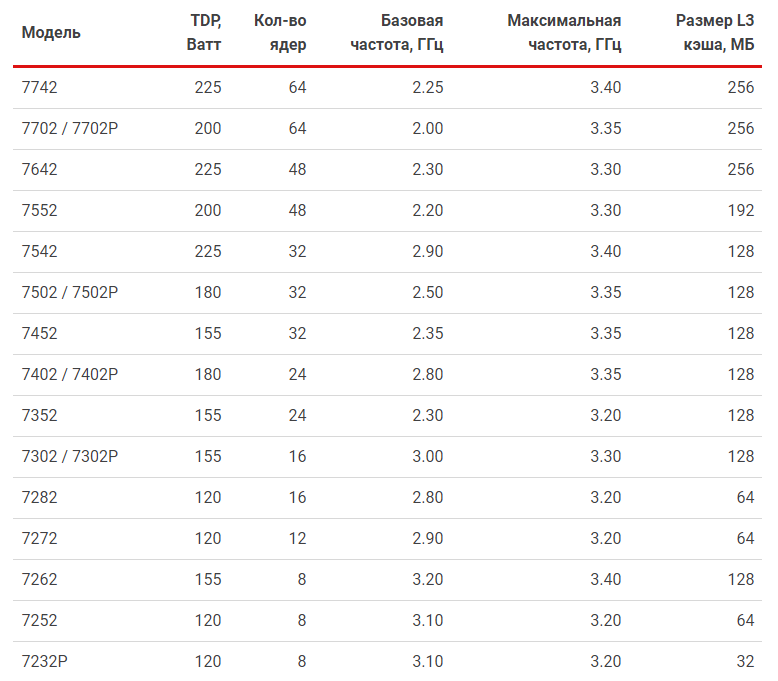
Подробные технические характеристики линейки представлены в таблице.
Rome может похвастаться улучшением работы с внешними устройствами: впервые появилась возможность работать с контроллером внешних прерываний x2APIC, а также заявлена поддержка DDR4-3200 и 128-ми линий PCIe. В новом поколении процессоров появилась поддержка технологии Virtualized IOMMU, с помощью которой виртуальные машины получают прямой доступ к физическим периферийным устройствам.
Наращивание мощностей и улучшение условий для виртуализации приводит к увеличению количества одновременно запущенных приложений. Приложения работают с конфиденциальными данными, которые нуждаются в повышенной защите.
Безопасность
В обновленной линейке процессоров не последнее место уделили вопросам безопасности. Внутри системы на кристалле установлен процессор под названием AMD Secure Processor на базе ARM Cortex A5, который хранит ключи и шифрует содержимое оперативной памяти по алгоритму AES-128.
AMD Secure Processor предлагает два вида шифрования памяти (для работы данных методов требуется поддержка со стороны ОС):
- SME (Secure Memory Encryption);
- SME шифрует память одним ключом и защищает от физических атак, таких как Cold boot attack. Использование данного типа шифрования не требует изменения пользовательских приложений: ОС отмечает страницы памяти, которые необходимо зашифровать.
- SEV (Secure Encrypted Virtualization).
- SEV разработан для обеспечения безопасности при работе с виртуальными машинами (ВМ). Память, используемая гипервизором и каждой из ВМ, шифруется собственным ключом. Такой подход криптографически изолирует гипервизор и ВМ друг от друга.
Тестовые серверы
Теперь, когда известна теория о новинке, проведем практические испытания. Представителем второго поколения выступит AMD EPYC 7452. Оппонентом из первого поколения выбран AMD EPYC 7551. Противник из «синего» лагеря — Intel Xeon Gold 5218 в составе двухсокетной системы. Выбор этих систем обоснован схожестью их технических характеристик.
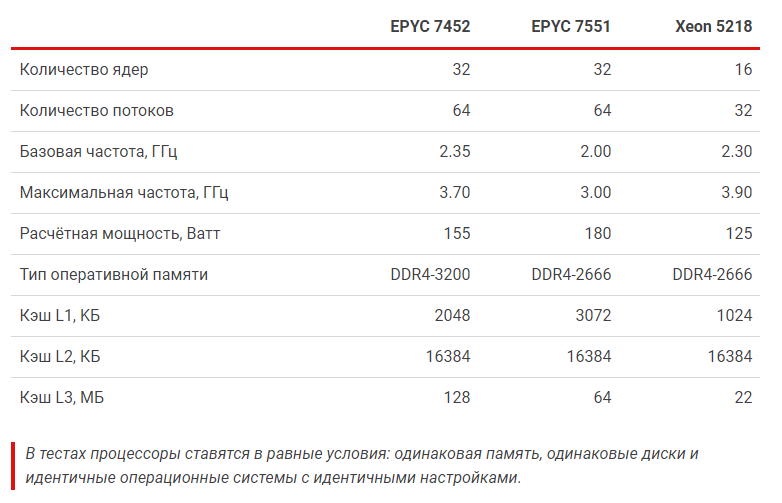
Для достижения максимальной производительности все каналы контроллера памяти процессора должны быть задействованы. Процессоры Intel располагают шестью каналами, а процессоры AMD — восьмью. При таком различии сложно создать идентичные условия, поэтому был найден компромисс: в системы с процессорами AMD установлены 8 модулей по 16 ГБ каждая, а в двухсокетную систему с Intel Xeon установлены 12 модулей по 8 ГБ. Все модули оперативной памяти работают на частоте 2666 МГц.
Операционная система (ОС) размещается на SSD-дисках, чтобы уменьшить влияние дисковой подсистемы на испытания. Все тесты были проведены на CentOS версии 7.
Тесты
Тестирование должно быть максимально объективным, тем более что речь идет о сравнении процессоров Intel и AMD. Поэтому мы не будем использовать оптимизирующих компиляторов для сборки тестов, которые поставляются в виде исходных кодов.
GeekBench 4
GeekBench — популярный кроссплатформенный тест производительности процессора с собственной онлайн-базой результатов. Тест поставляется в виде готовых исполняемых файлов, из-за чего оптимизация под конкретные процессоры не предусмотрена.
Для нас важны общие метрики групп GeekBench:
- Crypto Score;
- Integer Score;
- Floating Point Score;
- Memory Score.
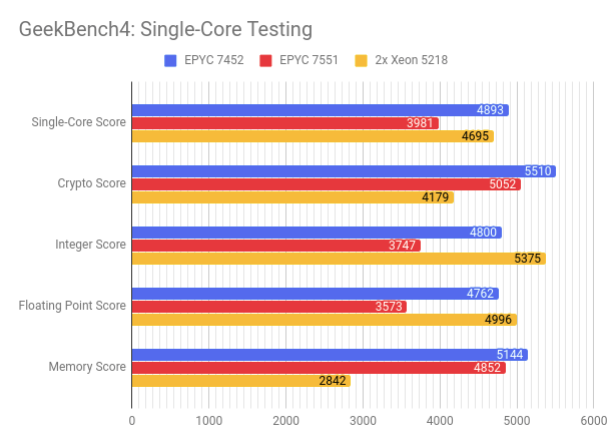
Основная борьба разворачивается между AMD EPYC 7452 и Intel Xeon Gold 5218, в то время как первое поколение EPYC во всех тестах уступает второму.
Рассмотрим однопоточные тесты. Rome показывает превосходный результат при работе с криптографическими задачами и памятью, но проигрывает при выполнении целочисленных вычислений. Как результат — второе поколение EPYC набирает 4893 балла и становится победителем в номинации Single-Core. Второе и третье место занимают Xeon и EPYC первого поколения с 4695 и 3981 баллами соответственно.
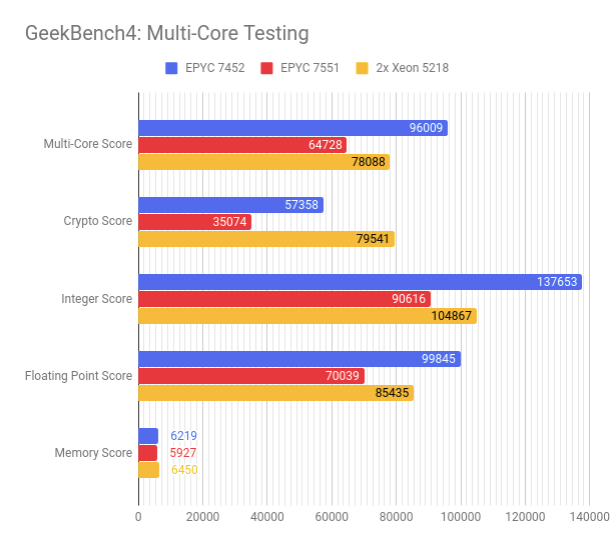
В многопоточных тестах расклад сил значительно меняется. EPYC 7452 отлично справляется с вычислениями, но сдает позиции в криптографических задачах и работе с памятью, что не мешает ему стать лидером с 96009 баллами в номинации Multi-Core.
SPEC CPU 2017
SPEC CPU 2017 — признанный производителями процессоров набор тестов производительности. Тесты данного набора распространяются в виде исходных кодов, что позволяет оптимизировать их под конкретное оборудование на конкретной операционной системе.
SPEC CPU состоит из четырех наборов тестов:
- int_rate;
- int_speed;
- fp_rate;
- fp_speed.
Мы провели все четыре набора тестов. Тесты собраны на третьем уровне оптимизаций с помощью набора компиляторов GNU версии 4.8.5. Многоядерные тесты запускались в 64 потока, а одноядерные тесты запускались в 32 копии.
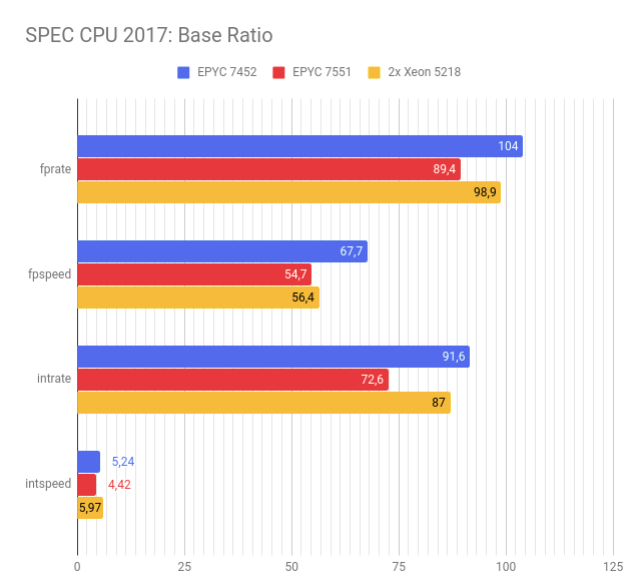
Тесты, собранные с оптимизациями, показывают противоречивые с GeekBench результаты. Второе поколение AMD EPYC превосходит двухсокетную систему с процессорами Intel во всех тестах, кроме intspeed, но с значительно меньшим отрывом, чем в GeekBench.
Phoronix Test Suite
Phoronix Test Suite (PTS) — программное обеспечение, позволяющее запускать тесты из большой базы пользовательских тестов производительности. Данное решение позволяет автоматизировано запускать желаемые тесты на нескольких подопытных серверах одновременно с агрегацией результатов на мастер-сервере.
Мы разработали собственный набор из 21 теста, среди которых:
- тестирование пропускной способности кэшей (CacheBench);
- тестирование пропускной способности оперативной памяти (RAMspeed, Stream, MBW);
- решение криптографических задач (Botan, OpenSSL, John the Ripper);
- рендеринг изображений методом трассировки лучей (C-Ray, POV-Ray, Smallpt);
- эмуляция работы сервера NGINX под нагрузкой;
- конвертирование аудио/видео.
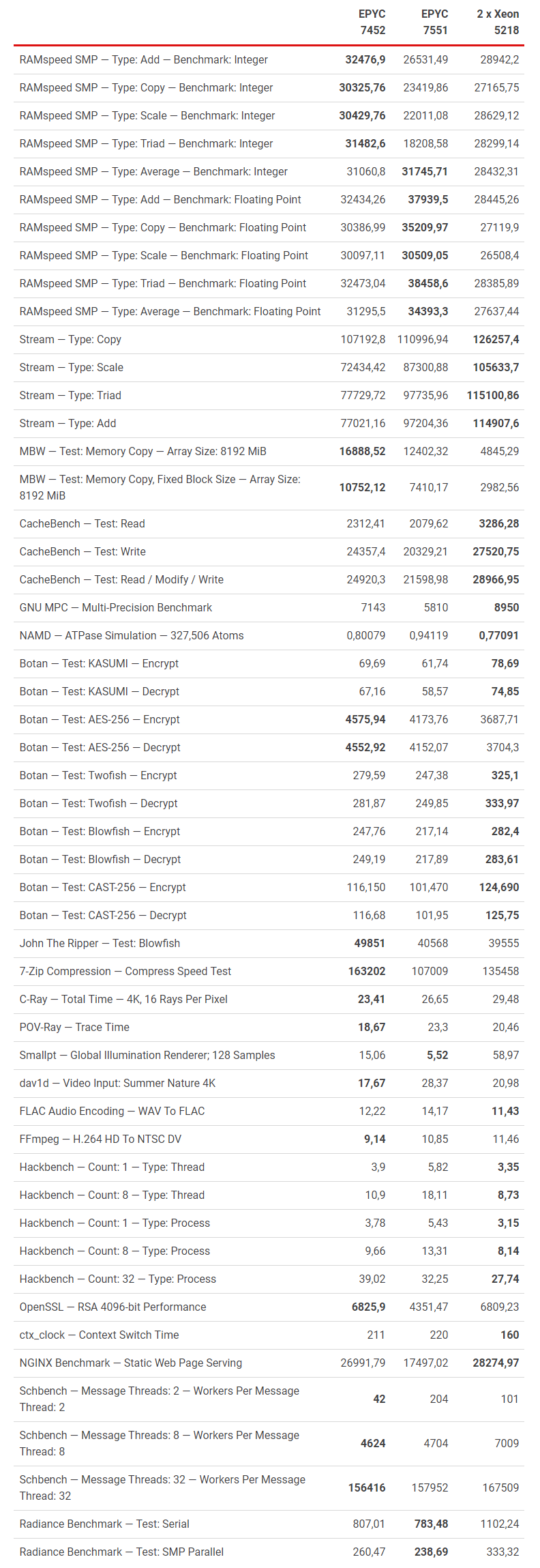
Впервые в тестах AMD EPYC 7551 выходит на первое место. Процессоры AMD вне зависимости от поколения лучше справляются в однопоточной работе с памятью, рендеринге и перекодировании видео. Процессоры Intel, в свою очередь, лучше справляются с криптографическими задачами и многопоточной работой с памятью, как и было выявлено ранее в тестах GeekBench.
Выводы
Несмотря на многообразие тестов, выбор между первым и вторым поколением AMD EPYC очевиден: Rome превосходит своего предшественника в подавляющем большинстве тестов. Тем не менее, первое поколение не сдает позиции в работе с памятью и рендеринге.
Сравнение процессоров Intel и AMD — настоящая битва титанов, требующая детального рассмотрения. Устанавливаемые программные решения в среднем выполняются лучше на втором поколении AMD EPYC. В частности, Rome показывает превосходные результаты в многопоточных вычислениях и однопоточных криптографических задачах. При работе с программным обеспечением, которое компилируется из исходных кодов, предпочтение отдается процессорам нового поколения EPYC, которые лидируют в тестах с плавающей запятой и лишь незначительно отстают в многопоточных целочисленных вычислениях.
Intel Xeon Gold, в свою очередь, показывает хорошие результаты в многопоточной криптографии, перекодировании аудио и работе с памятью. Двухсокетная система с процессорами Intel Xeon показала хороший результат при обработке запросов веб-серверов.
Подводя итог, следует отметить, что проведенные тесты являются синтетическими и результаты на реальных задачах могут отличаться. Для получения точных результатов на конкретных задачах необходимо дополнительное тестирование. Теперь буквально пару слов о стоимости. Рекомендованная цена AMD EPYC 7452 составляет $2025, для Intel Xeon Gold 5218 — $1250, то есть $2500 для организации двухсокетной системы.
Новый AMD EPYC 7452 скоро появится в нашей лаборатории Selectel Lab.
selectel.ru/promo/amd-servers/