Открытый исходный код делает LLM (большие языковые модели) доступными каждому. Доступно множество вариантов, особенно для вывода. Вы, наверное, слышали о библиотеке вывода Hugging Face, но есть еще OpenLLM, vLLM и многие другие.
Основная проблема, особенно если вы такая компания, как Mistral AI, создающая новые LLM, заключается в том, что архитектура вашего LLM должна поддерживаться всеми этими решениями. Им нужна возможность общаться с Hugging Face, NVIDIA, OpenLLM и так далее.
Вторая проблема — это стоимость, особенно стоимости инфраструктуры, которая вам понадобится для масштабирования развертывания LLM. Для этого у вас есть разные решения:
Выбор подходящих графических процессоров (ваш LLM должен им соответствовать)
Выбор подходящей техники:
- Квантование, которое предполагает уменьшение количества байтов, используемых переменными, поэтому вы можете разместить более крупные модели в меньших ограничениях памяти. Это компромисс между ними, поскольку это может повлиять на точность вашей модели и результаты ее производительности.
- Методы точной настройки, такие как точная настройка с эффективным использованием параметров ( PEFT ). С помощью методов PEFT вы можете значительно снизить затраты на вычисления и память, настроив лишь небольшое количество (дополнительных) параметров модели вместо всех параметров модели. Вы также можете комбинировать методы PEFT с квантованием.
- Затем вам нужно решить, будете ли вы размещать его самостоятельно; вы используете решение PaaS; или готовые к использованию конечные точки API, как это делает OpenAI.
Выбор правильного графического процессора
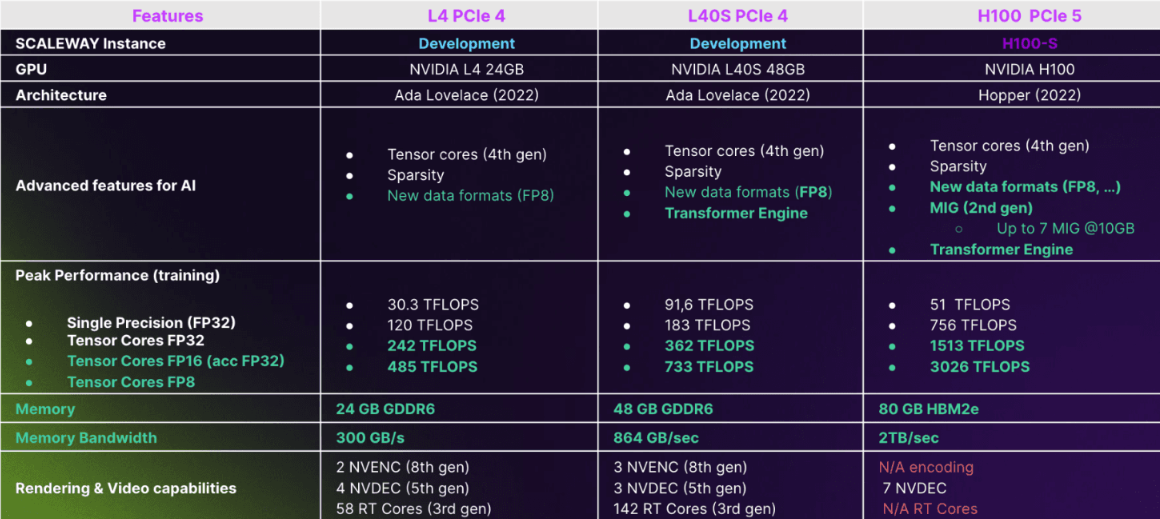
Вышеуказанное является предложением Scaleway, но аналогичные предложения в настоящее время устанавливаются у большинства крупных облачных провайдеров.
- H100 PCIe 5 — флагманский и самый мощный графический процессор NVIDIA. Он имеет интересные функции, такие как Transformer Engine, библиотека для ускорения моделей Transformer на графических процессорах NVIDIA, включая использование 8-битной точности с плавающей запятой (FP8) на графических процессорах Hopper и Ada Lovelace, чтобы обеспечить лучшую производительность при меньшем использовании памяти как при обучении, так и при выводе.. Это ускоряет обучение моделей Transformer, а это означает, что вы можете поместить в память вдвое больше переменных, в 8 бит вместо 16. Кроме того, библиотека NVIDIA помогает упростить эти изменения; плюс большой объем памяти и пропускная способность памяти являются ключевыми моментами, поскольку чем быстрее вы сможете загрузить свою память, тем быстрее будет работать ваш графический процессор.
- L4 PCIe 4 можно рассматривать как современного преемника NVIDIA T4, предназначенного для вывода, но прекрасно способного обучать меньшие модели LLM. Как и H100, он может работать с новыми форматами данных, такими как FP8. У него меньшая пропускная способность памяти, чем у H100, но это может создать некоторые узкие места в определенных случаях использования, например, при обработке больших пакетов изображений для обучения моделей компьютерного зрения. В этих случаях вы можете не увидеть значительного прироста производительности по сравнению, например, с предыдущей архитектурой Ampere. И в отличие от H100, у него есть возможности рендеринга видео и 3D, поэтому, если вы хотите создать синтетический набор данных для компьютерного зрения с помощью Blender, вы можете использовать этот графический процессор.
- L40S PCIe 4 — это то, что NVIDIA считает новым A100. Он имеет в два раза больше памяти, чем L4, но с большей пропускной способностью памяти и более высокой вычислительной производительностью. По словам NVIDIA, для генеративного ИИ, когда вы оптимизируете свой код с помощью FP8 и так далее, DGX с 8x A100 с 40 Гбит NVlink может работать так же хорошо, как 8 L40S PCIe 4 без NVLink, так что это мощный и интересный графический процессор.
Совет по использованию экземпляров графического процессора 1: образы Docker
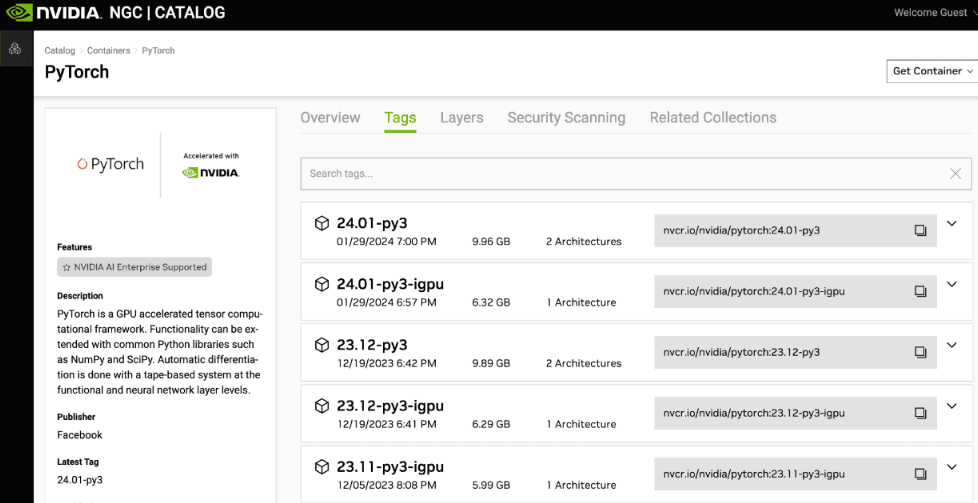
При использовании графических процессоров используйте образы Docker и начните с бесплатных изображений NVIDIA. Таким образом, код становится переносимым, поэтому его можно запускать на вашем ноутбуке, на рабочей станции, на экземпляре графического процессора (независимо от облачного провайдера, поэтому без привязки) или на мощном кластере (либо с SLURM в качестве оркестратора, если вы находитесь в мире HPC/AI или Kubernetes, если вы больше в мире AI/MLOps).
NVIDIA регулярно обновляет эти образы, поэтому вы можете воспользоваться улучшениями производительности и исправлениями ошибок/безопасности. Производительность A100 сейчас значительно лучше, чем при запуске, и то же самое будет относиться к H100, L4 и так далее. Кроме того, существует множество функций, позволяющих экономить время, которые позволят вам быстрее создавать POC, например, фреймворк и такие инструменты, как NeMo, Riva и т. д., которые доступны через каталог NGC (выше).
Это также открывает возможность использовать лицензию AI Enterprise для поддерживаемых конфигураций оборудования (что обычно можно увидеть только в предложениях облачных провайдеров), что обеспечит вам поддержку в случае возникновения ошибок или проблем с производительностью и даже предложит помощь на основе данных NVIDIA. ученых, чтобы помочь вам отладить ваш код и получить максимальную производительность от всех этих программ. И, конечно же, вы можете выбрать свою любимую платформу: PyTorch, TensorFlow, Jupyter Lab и так далее.
Использование экземпляров Scaleway GPU
В ОС Scaleway GPU OS 12 мы уже предустановили Docker, поэтому вы можете использовать его прямо из коробки. Меня часто спрашивают, почему не предустановлены CUDA или Anaconda. Причина в том, что эти программы должны выполняться внутри контейнеров, поскольку не у всех пользователей одинаковые требования. Например, они могут использовать разные версии CUDA, cuDNN или Pytorch, поэтому это действительно зависит от требований пользователя. И использовать контейнер, созданный NVIDIA, проще, чем устанавливать и поддерживать среду искусственного интеллекта Python. Кроме того, это упрощает воспроизведение результатов в рамках ваших тренировок или экспериментов.
Итак, в основном вы делаете это:
## Connect to a GPU instance like H100-1-80G {connect-to-a-gpu-instance-like-h100-1-80g}
ssh root@<replace_with_instance_public_ip>
## Pull the Nvidia Pytorch docker image (or other image, with the software versions you need)
docker pull nvcr.io/nvidia/pytorch:24.01-py3
[...]
## Launch the Pytorch container {launch-the-pytorch-container}
docker run --rm -it --runtime=nvidia \
-p 8888:8888 \
-p 6006:6006 \
-v /root/my-data/:/workspace \
-v /scratch/:/workspace/scratch \
nvcr.io/nvidia/pytorch:24.01-py3
## You can work with Jupyter Lab, Pytorch etc… {you-can-work-with-jupyter-lab-pytorch-etc}
Совет по использованию экземпляров графического процессора 2: MIG
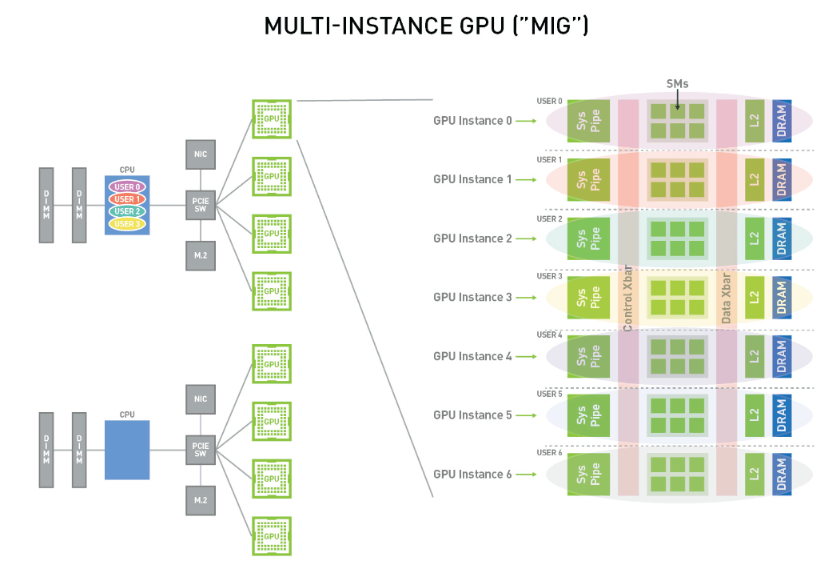
Одной из уникальных особенностей H100 является MIG, или многоэкземплярный графический процессор, который позволяет разделить графический процессор на семь частей. Это действительно полезно, если вы хотите оптимизировать свою рабочую нагрузку. Если у вас есть рабочие нагрузки, которые не полностью нагружают графические процессоры, это хороший способ иметь несколько рабочих нагрузок и максимизировать использование графического процессора. Он работает с автономными виртуальными машинами и очень легко работает в Kubernetes. Вы запрашиваете одну ссылку на графический процессор, соответствующую разделению, которое вы хотите использовать для одного ресурса графического процессора.
В Kubernetes это так же просто, как заменить в файле развертывания классические ограничения ресурсов
nvidia.com/gpu: '1' . по желаемому имени раздела MIG, например, nvidia.com/mig-3g.40gb: 1
docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
Совет по использованию экземпляров графического процессора 3: NVIDIA Transformer Engine и FP8
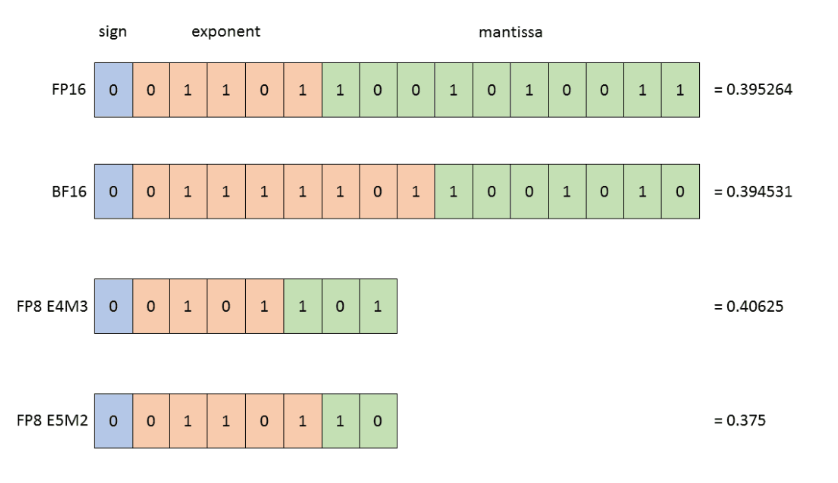
Все графические процессоры последнего поколения (доступные в новейшей архитектуре графических процессоров Nvidia, а именно Hopper и Ada Lovelace) используют NVIDIA Transformer Engine, библиотеку для ускорения моделей Transformer на графических процессорах NVIDIA, включая использование 8-битной точности с плавающей запятой (FP8) в Hopper. и графические процессоры Ada, чтобы обеспечить более высокую производительность при меньшем использовании памяти как при обучении, так и при выводе.
Что касается использования формата данных FP8, то на самом деле существует два типа FP8, которые предлагают компромисс между точностью и динамическим диапазоном чисел, которыми вы можете манипулировать (см. диаграмму). При обучении нейронных сетей можно использовать оба этих типа. Обычно активация и вес вперед требуют большей точности, поэтому тип данных E4M3 лучше всего использовать во время прямого прохода. Однако при обратном проходе градиенты, проходящие через сеть, обычно менее подвержены потере точности, но требуют более высокого динамического диапазона. Поэтому их лучше всего хранить в формате данных E5M2. Этим можно даже управлять автоматически с помощью формата «ГИБРИД» (
подробнее здесь).
Transformer Engine предназначен не только для трансформеров. Поскольку он также может оптимизировать линейные операции, он может принести пользу другим архитектурам моделей, таким как компьютерное зрение (см. пример MNIST). Итак, по сути, вы устанавливаете пакет движка Transformer с помощью «pip», загружаете пакет и просто тестируете или заменяете определенный оперант. модули (из ваших любимых сред глубокого обучения) с помощью модуля, входящего в состав пакета Transformer engine (см. пример
MNIST выше). Если вы хотите потратить немного времени на оптимизацию своего кода, используя Transformer Engine и формат FP8, вы можете это сделать. Здесь полезно оптимизировать, потому что вы будете использовать меньше памяти, использовать больше переменных и ускорять вывод и обучение. Поэтому обязательно оптимизируйте свой код!
Использование LLM в производстве: создание чат-бота с искусственным интеллектом с помощью RAG
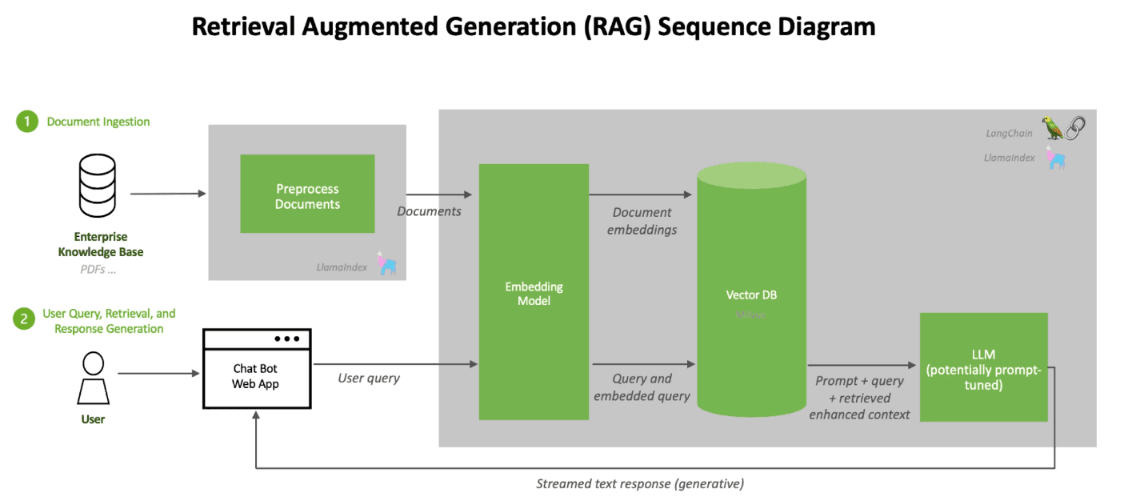
Если вы хотите использовать LLM в производстве, возможно, вам захочется создать чат-бота, и для этого вам, вероятно, понадобится точно настроить модель ваших данных для вашего конкретного случая использования. С библиотекой Transformers Hugging Face это легко с точки зрения кода; но улучшить результаты может быть сложно, поскольку это требует множества проб и ошибок.
Другой метод — взглянуть на RAG, или
Retrival Augmented Generation, который можно выполнить перед тонкой настройкой или вместо нее. Таким образом, риск поломки модели снижается, как и риск тонкой настройки. Кроме того, при использовании RAG не требуется затрат на тонкую настройку, поскольку вы не платите за использование графического процессора при нескольких попытках, необходимых для точной настройки; и вы можете сохранить конфиденциальность своих данных, разместив их локально. Кроме того, вы снижаете риск возникновения галлюцинаций, что всегда плохо, когда вы пытаетесь создать
чат-бота с искусственным интеллектом для своего бизнеса. Поэтому я включил документацию, объясняющую эту систему. У NVIDIA даже есть
проект на GitHub, который позволит вам создать своего первого чат-бота с искусственным интеллектом с помощью RAG всего за пять минут.
Что вам нужно для обучения основам LLM
Во-первых, много денег! В
официальном документе LLaMA говорится, что обучение LLaMa с использованием 2048 графических процессоров A100 емкостью 80 ГБ заняло 21 день. Мы не можем предполагать, сколько это стоит, но кто-то другой написал
здесь (подсказка: это очень много!)
Вам также понадобится команда экспертов… но не обязательно сотни! Mixture от Mistral AI превзошел GPT3.5 (согласно
тесту Mistral AI) при команде численностью менее 20 человек.
Также потребуется много данных: для этого вам, возможно, придется порыться в Интернете или обратиться за помощью к партнерству. Затем данные необходимо будет подготовить, т.е. очистить и дедуплицировать.
Наконец, вам понадобится много вычислительной мощности! Если мы посмотрим на этот график NVIDIA:

… мы видим большой скачок между A100 и H100 (время обучения от одного месяца до одной недели для самых больших моделей).
Как работать с большим количеством данных
Наши клиенты Superpod используют Spark для подготовки данных, который использует ЦП (около 10 000 виртуальных ЦП) и около 100 ТБ блочного хранилища, прежде чем набор данных будет сохранен в объектном хранилище. Кстати, Scaleway в настоящее время работает над предложением управляемого кластера Spark: следите за этим!
NVIDIA также предоставляет такие инструменты, как NeMo data Curator (через NGC/Nvidia AI Enterprise, поэтому мы говорим о контейнерах), который имеет такие функции, как загрузка данных и извлечение текста, переформатирование и очистка текста, фильтрация качества, дедупликация на уровне документа и т.д. многоязычная дезактивация последующих задач и многое другое.
Даже с использованием этих инструментов подготовка данных может занять много времени, но ее необходимо сделать до начала обучения.
Как начать обучение
Чтобы начать обучение, вам понадобится более одного графического процессора, поэтому строительными блоками будут NVIDIA DGX H100 — готовые к использованию компьютеры с установленной максимальной конфигурацией сервера, так что вы получите лучшее из лучшего:
- 8 графических процессоров NVIDIA H100 емкостью 80 ГБ и 640 ГБ общей памяти графического процессора
- 18 подключений NVIDIA NVLink на каждый графический процессор
- 900 гигабайт в секунду двунаправленной пропускной способности между графическими процессорами благодаря NVLink
- 4x NVIDIA NVSwitch™
- 7,2 терабайта в секунду двунаправленной пропускной способности между графическими процессорами
- В 1,5 раза больше, чем предыдущее поколение
- 10 сетевых интерфейсов NVIDIA ConnectX-7, 400 гигабит в секунду
- 1 терабайт в секунду пиковой пропускной способности двунаправленной сети
- Два процессора Intel Xeon Platinum 8480C, всего 112 ядер и системная память объемом 2 ТБ.
- SSD-накопитель NVMe емкостью 30 терабайт — высокоскоростное хранилище для максимальной производительности.
Чтобы построить Superpod, вы берете этот сервер, а затем объединяете 32 из них, ни больше, ни меньше. Это то, что NVIDIA называет масштабируемой единицей. Если вы увеличите четыре масштабируемых устройства, у вас будет 128 узлов, и это будет система SuperPOD H100. Каждый из четырех блоков имеет производительность 1 экзафлопс в формате FP8, что в общей сложности составляет до 4 эксафлопс в формате FP8, а кластер управляется NVIDIA Base Command Manager, поэтому программное обеспечение NVIDIA с оркестратором SLURM позволяет запускать задания на нескольких компьютерах для провести обучение.
Итак, в Scaleway у нас есть два суперкомпьютера:
Jeroboam, уменьшенная версия кластера, предназначенная для обучения написанию кода с несколькими графическими процессорами и несколькими узлами:
- 2 узла NVIDIA DGX H100 (16 графических процессоров Nvidia H100)
- До 63,2 PFLOPS (тензорное ядро FP8)
- 8 графических процессоров Nvidia H100 80 ГБ SXM с NVlink до 900 ГБ/с на узел
- Двойной процессор Intel Xeon Platinum 8480C (всего 112 ядер с частотой 2 ГГц)
- 2 ТБ оперативной памяти
- 2x NVMe по 1,92 ТБ для ОС
- NVMe емкостью 30,72 ТБ для временного хранилища
- Пропускная способность (для 2 DGX): до 40 ГБ/с при чтении и 30 ГБ/с при записи.
- Сеть межсоединений графических процессоров Nvidia Infiniband со скоростью до 400 Гбит/с (на уровне кластера)
- Высокопроизводительное хранилище DDN емкостью 60 ТБ с низкой задержкой.
Nabuchodonosor, «настоящая вещь» для обучения, которая также создана для людей, которые хотят обучать LLM с помощью видео, а не только текста, благодаря большому объему высокопроизводительного хранилища…
- 127 узлов NVIDIA DGX H100 (1016 графических процессоров Nvidia H100)
- До 4 EFLOPS (тензорное ядро FP8)
- 8 графических процессоров Nvidia H100 80 ГБ SXM с NVlink до 900 ГБ/с на узел
- Двойной процессор Intel Xeon Platinum 8480C (всего 112 ядер с частотой 2 ГГц)
- 2 ТБ оперативной памяти
- 2x NVMe по 1,92 ТБ для ОС
- NVMe емкостью 30,72 ТБ для временного хранилища
- Сеть межсоединений графических процессоров Nvidia Infiniband со скоростью до 400 Гбит/с (на уровне кластера)
- 1,8 ПБ высокопроизводительного хранилища DDN с низкой задержкой
- Пропускная способность (для 127 DGX): до 2,7 ТБ/с при чтении и 1,95 ТБ/с при записи.
Обучение LLM
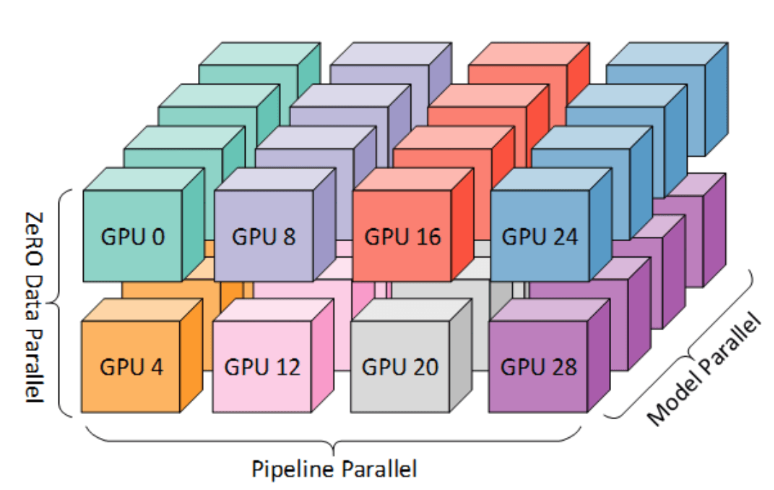
Проблема обучения LLM Nabuchodonosor заключается в том, что это пользовательский опыт HPC, что означает работу SLURM, а не Kubernetes. Однако это по-прежнему контейнеры, которые вы создаете поверх образов контейнеров NVIDIA NGC (Pytorch, Tensorflow, Jax…). Вот почему, когда вы пишете свой код с этими изображениями NGC, даже с одним небольшим графическим процессором, ваш код сможет легче масштабироваться. Одна из лучших практик — если у вас, скажем, 100 узлов, не запускайте задания на всех из них. Сохраните несколько запасных на случай, если один или два графических процессора выйдут из строя (такое случается!) Таким образом, если у вас возникнут какие-либо проблемы, вы сможете перезапустить свою работу, заменив неисправные узлы.
Вам нужно будет писать свой код особым образом, чтобы максимизировать производительность за счет использования параллелизма данных и параллелизма моделей (одновременные вычисления на нескольких графических процессорах); для этого вы можете использовать такие ресурсы, как Deepspeed.
Еще есть комплексная платформа Nvidia NeMo, которая также поможет вам создавать, настраивать и развертывать генеративные модели искусственного интеллекта.

Суперкомпьютеры Scaleway были построены всего за три-семь месяцев, поэтому обеспечить своевременную доставку всех компонентов и их правильное подключение с помощью более чем 5000 кабелей было непростой логистической задачей!
Обеспечение электропитанием также является довольно сложной задачей: энергопотребление системы Nabuchodonosor Superpod составляет 1,2 МВт, а это означает, что мы можем разместить только два блока DGX в каждой стойке, так что это не очень эффективное использование площади центра обработки данных. Еще есть стоимость электроэнергии, которая, например, во Франции в пять раз выше, чем в США. Но поскольку углеродоемкость французской электроэнергии очень низкая, она генерирует примерно в семь раз меньше выбросов, чем, например, в Германии. Более того, поскольку
все машины искусственного интеллекта Scaleway размещены в DC5, который не имеет кондиционера и, следовательно, потребляет на 30–40% меньше энергии, чем стандартные центры обработки данных, мы можем сказать, что это одна из самых устойчивых установок искусственного интеллекта в мире. Подробнее об искусственном интеллекте и устойчивом развитии здесь.
Что дальше?
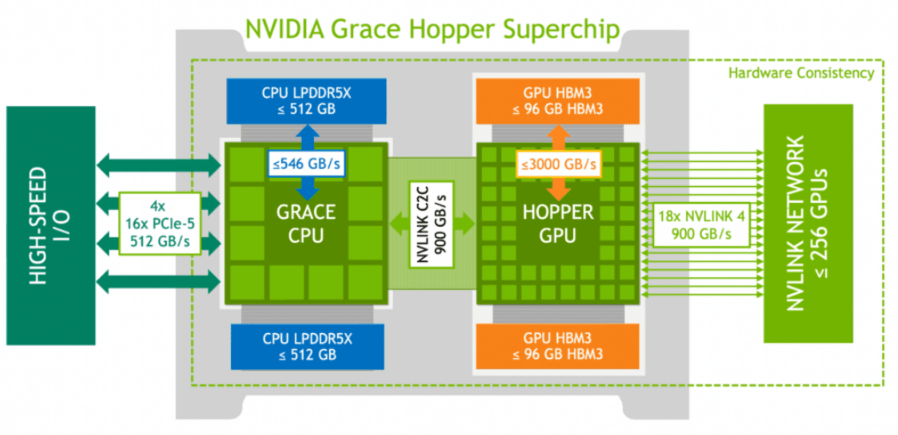
В этом году Scaleway выпустит суперчип
NVIDIA GH200 Grace Hopper, который сочетает в себе процессоры Grace ARM и графические процессоры Hopper в одном устройстве, которые связаны со скоростью 900 ГБ/с. Вы можете соединить 256 таких устройств вместе, что намного больше, чем вы можете подключить в конфигурации DGX, описанной выше (8 графических процессоров, подключенных со скоростью 900 ГБ/с с помощью NVlink в одном серверном узле DGX H100). А если вам нужно больше, вы даже можете подключить несколько ячеек 256 GH200 через Infiniband со скоростью 400 Гбит/с. Так что это действительно для случаев использования, где память является узким местом, поэтому это действительно для HPC и для вывода LLM. Когда они все собраны вместе, это похоже на гигантский графический процессор, предназначенный для самых требовательных случаев использования, например, в здравоохранении и науках о жизни.